Att använda Galera-kluster är ett utmärkt sätt att bygga en mycket tillgänglig miljö för MySQL eller MariaDB. Det är en delad-ingenting-klustermiljö som kan skalas även bortom 12-15 noder. Galera har dock vissa begränsningar. Den lyser i miljöer med låg latens och även om den kan användas över WAN, begränsas prestandan av nätverkslatens. Galeras prestanda kan också påverkas om en av noderna börjar bete sig felaktigt. Till exempel kan överdriven belastning på en av noderna sakta ner den, vilket resulterar i långsammare hantering av skrivningarna och det kommer att påverka alla andra noder i klustret. Å andra sidan är det ganska omöjligt att driva ett företag utan att analysera din data. Sådan analys kräver vanligtvis att du kör tunga frågor, vilket skiljer sig ganska mycket från en OLTP-arbetsbelastning. I det här blogginlägget kommer vi att diskutera ett enkelt sätt att köra analytiska frågor för data lagrade i Galera Cluster för MySQL eller MariaDB, på ett sätt så att det inte påverkar prestanda för kärnklustret.
Hur kör man analytiska frågor på Galera Cluster?
Som vi sa är det möjligt att köra långa frågor direkt på ett Galera-kluster, men kanske inte så bra. Hårdvaruberoende kan detta vara en acceptabel lösning (om du använder stark hårdvara och du inte kommer att köra en flertrådig analytisk arbetsbelastning) men även om CPU-användning inte kommer att vara ett problem, kommer det faktum att en av noderna har blandad arbetsbelastning ( OLTP och OLAP) kommer bara att innebära vissa prestandautmaningar. OLAP-frågor tar bort data som krävs för din OLTP-arbetsbelastning från buffertpoolen, och detta kommer att sakta ner dina OLTP-frågor. Lyckligtvis finns det ett enkelt men effektivt sätt att separera analytisk arbetsbelastning från vanliga frågor - en asynkron replikeringsslav.
Replikeringsslav är en mycket enkel lösning - allt du behöver är bara en annan värd som kan tillhandahållas och asynkron replikering måste konfigureras från Galera Cluster till den noden. Med asynkron replikering kommer slaven inte att påverka resten av klustret på något sätt. Oavsett om den är hårt belastad, använder annan (mindre kraftfull) hårdvara, kommer den bara att fortsätta replikera från kärnklustret. Det värsta scenariot är att replikeringsslaven börjar släpa efter, men sedan är det upp till dig att implementera flertrådsreplikering eller, så småningom, att skala upp replikeringsslaven.
När replikeringsslaven är igång bör du köra de tyngre frågorna på den och ladda ner Galera-klustret. Detta kan göras på flera sätt, beroende på din inställning och miljö. Om du använder ProxySQL kan du enkelt rikta frågor till den analytiska slaven baserat på källvärden, användaren, schemat eller till och med själva frågan. Annars är det upp till din applikation att skicka analytiska frågor till rätt värd.
Att sätta upp en replikeringsslav är inte särskilt komplicerat men det kan fortfarande vara knepigt om du inte är skicklig med MySQL och verktyg som xtrabackup. Hela processen skulle bestå av att sätta upp förvaret på en ny server och installera MySQL-databasen. Sedan måste du tillhandahålla den värden med hjälp av data från Galera-klustret. Du kan använda xtrabackup för det men andra verktyg som mydumper/myloader eller till och med mysqldump fungerar lika bra (så länge du kör dem korrekt). När data finns där måste du ställa in replikeringen mellan en master Galera-nod och replikeringsslaven. Slutligen måste du konfigurera om ditt proxylager för att inkludera den nya slaven och dirigera trafiken mot den eller göra justeringar i hur din applikation ansluter till databasen för att omdirigera en del av belastningen till replikeringsslaven.
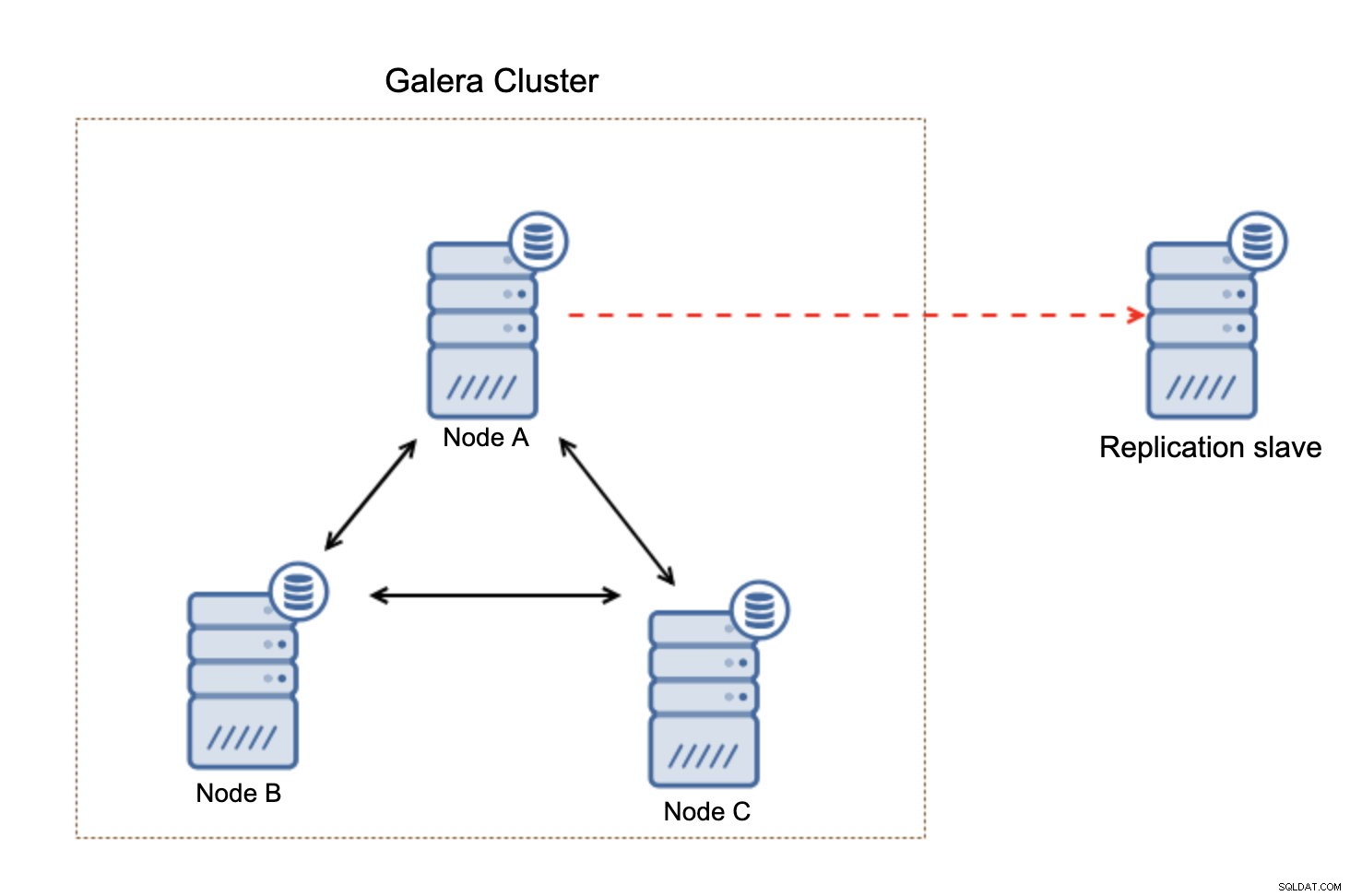
Vad som är viktigt att tänka på är att den här installationen inte är motståndskraftig. Om "master" Galera-noden skulle gå ner kommer replikeringslänken att brytas och den kommer att vidta en manuell åtgärd för att slav repliken från en annan masternod i Galera-klustret.
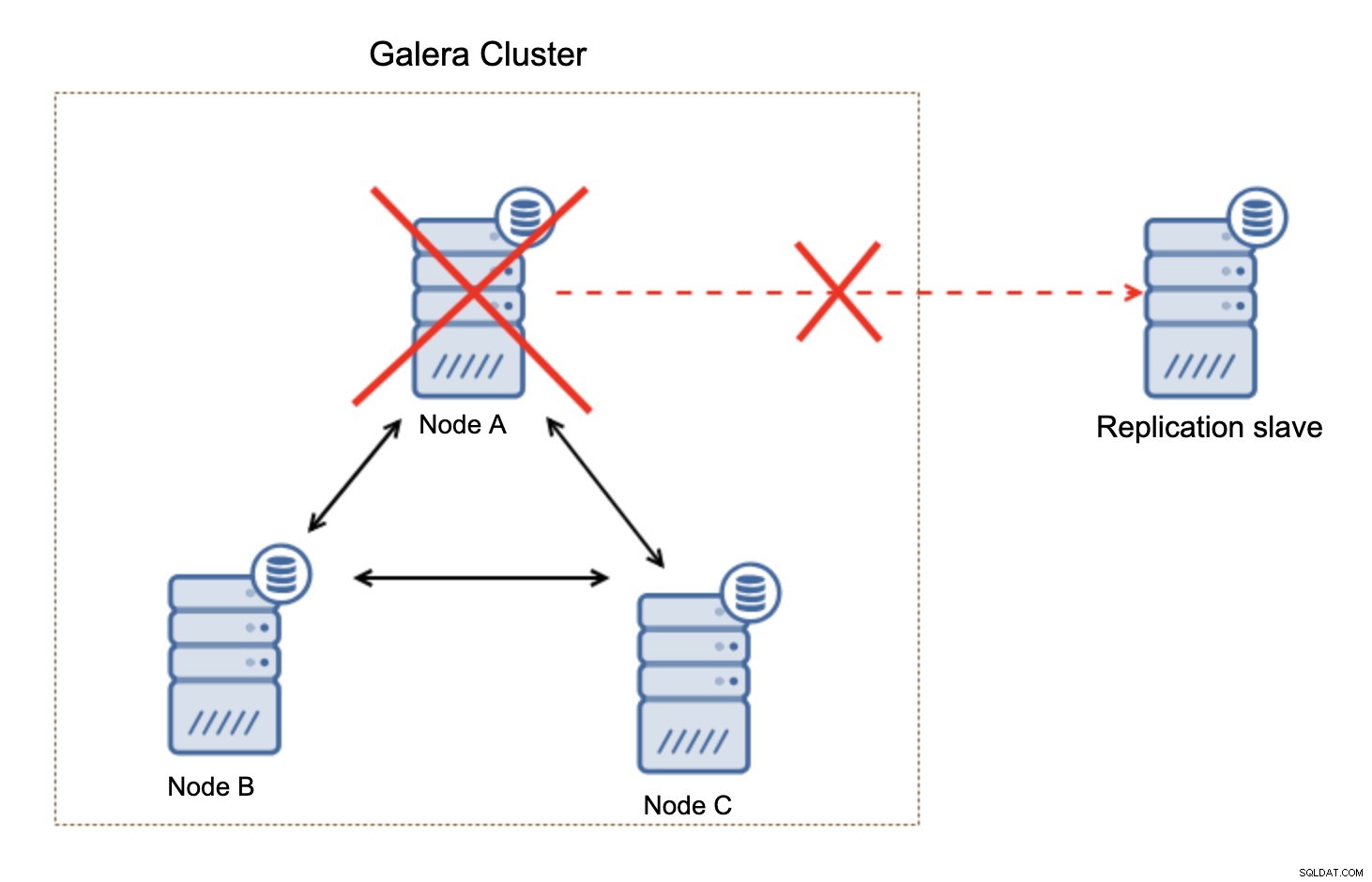
Detta är ingen stor sak, särskilt om du använder replikering med GTID (Global Transaction ID) men du måste identifiera att replikeringen är trasig och sedan vidta den manuella åtgärden.
Hur ställer man in den asynkrona slaven till Galera Cluster med ClusterControl?
Lyckligtvis, om du använder ClusterControl, kan hela processen automatiseras och det kräver bara en handfull klick. Det initiala tillståndet har redan ställts in med ClusterControl - ett Galera-kluster med 3 noder med 2 ProxySQL-noder och 2 Keepalive-noder för hög tillgänglighet för både databas och proxylager.
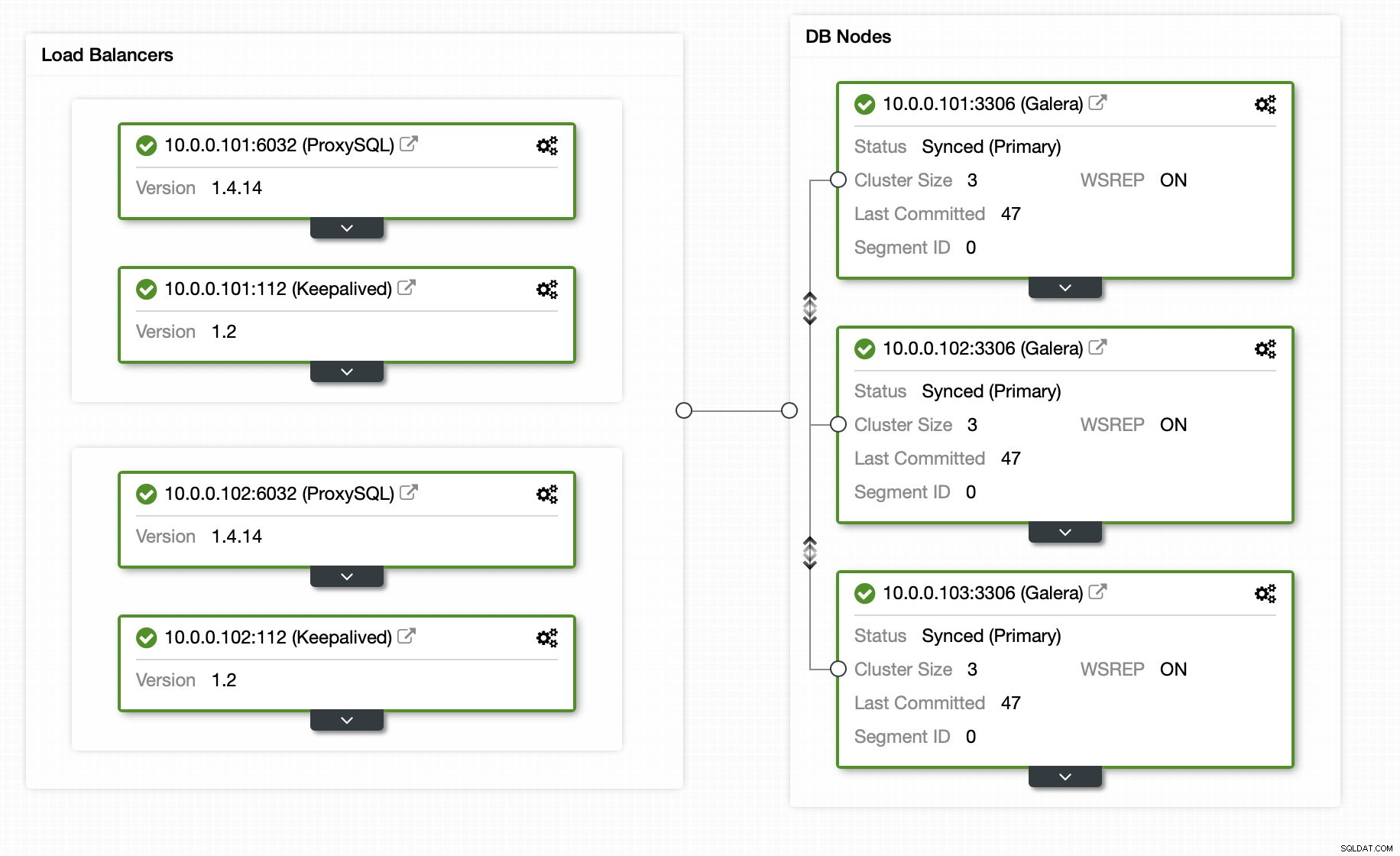
Att lägga till replikeringsslaven är bara ett klick bort:
Replikering kräver naturligtvis att binära loggar är aktiverade. Om du inte har binlogs aktiverade på dina Galera-noder kan du också göra det från ClusterControl. Tänk på att aktivering av binära loggar kräver en omstart av noden för att tillämpa konfigurationsändringarna.
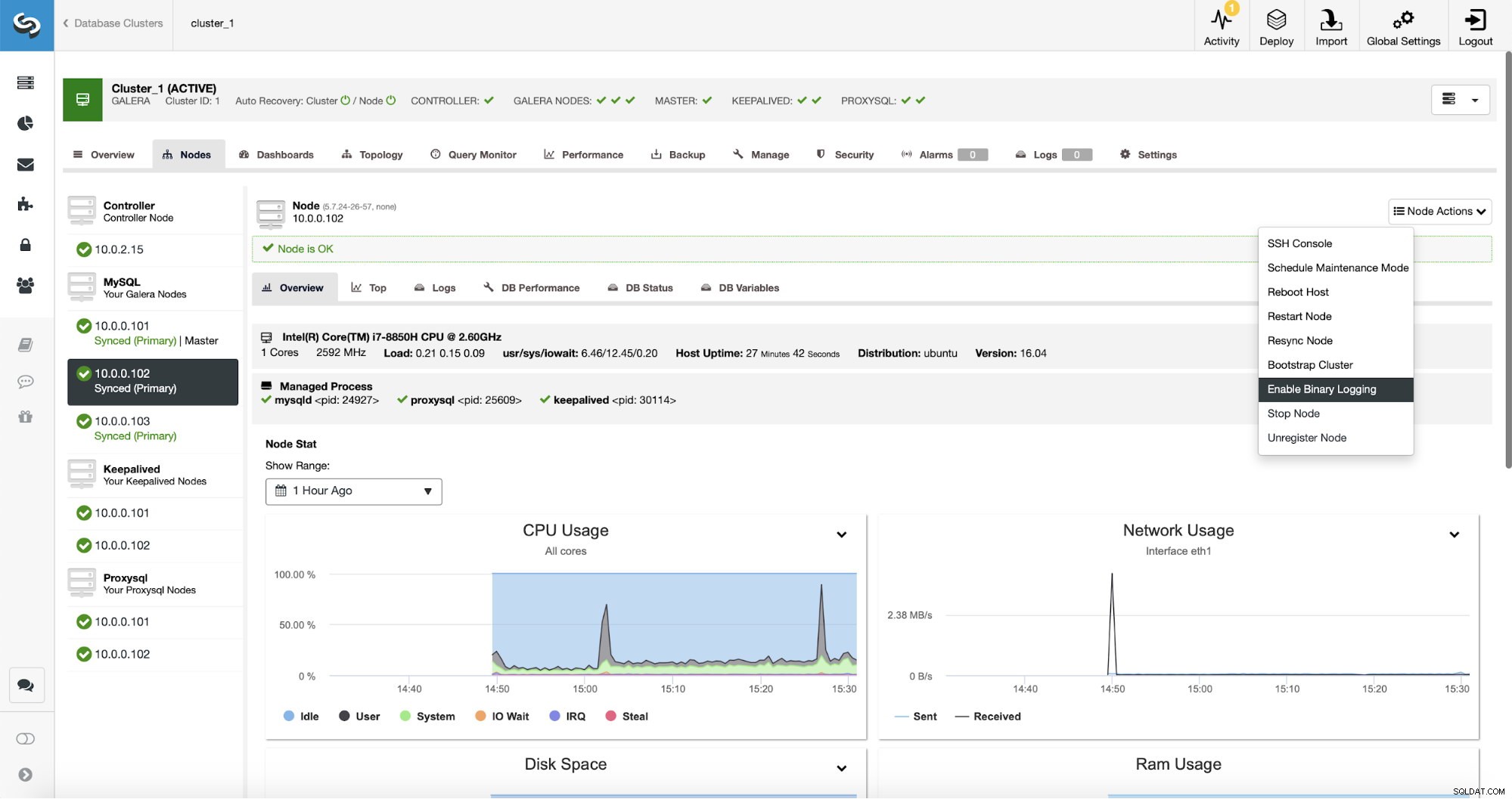
Även om en nod i klustret har binära loggar aktiverade (markerade som "Master" på skärmdumpen ovan), är det fortfarande bra att aktivera binär loggar på minst en nod till. ClusterControl kan automatiskt failover replikeringsslaven efter att den upptäcker att huvudnoden Galera kraschade, men för det krävs en annan masternod med binära loggar aktiverade, annars har den inget att misslyckas med.
Som vi nämnde kräver aktivering av binära loggar omstart. Du kan antingen utföra det direkt, eller bara göra konfigurationsändringarna och utföra omstarten vid något annat tillfälle.
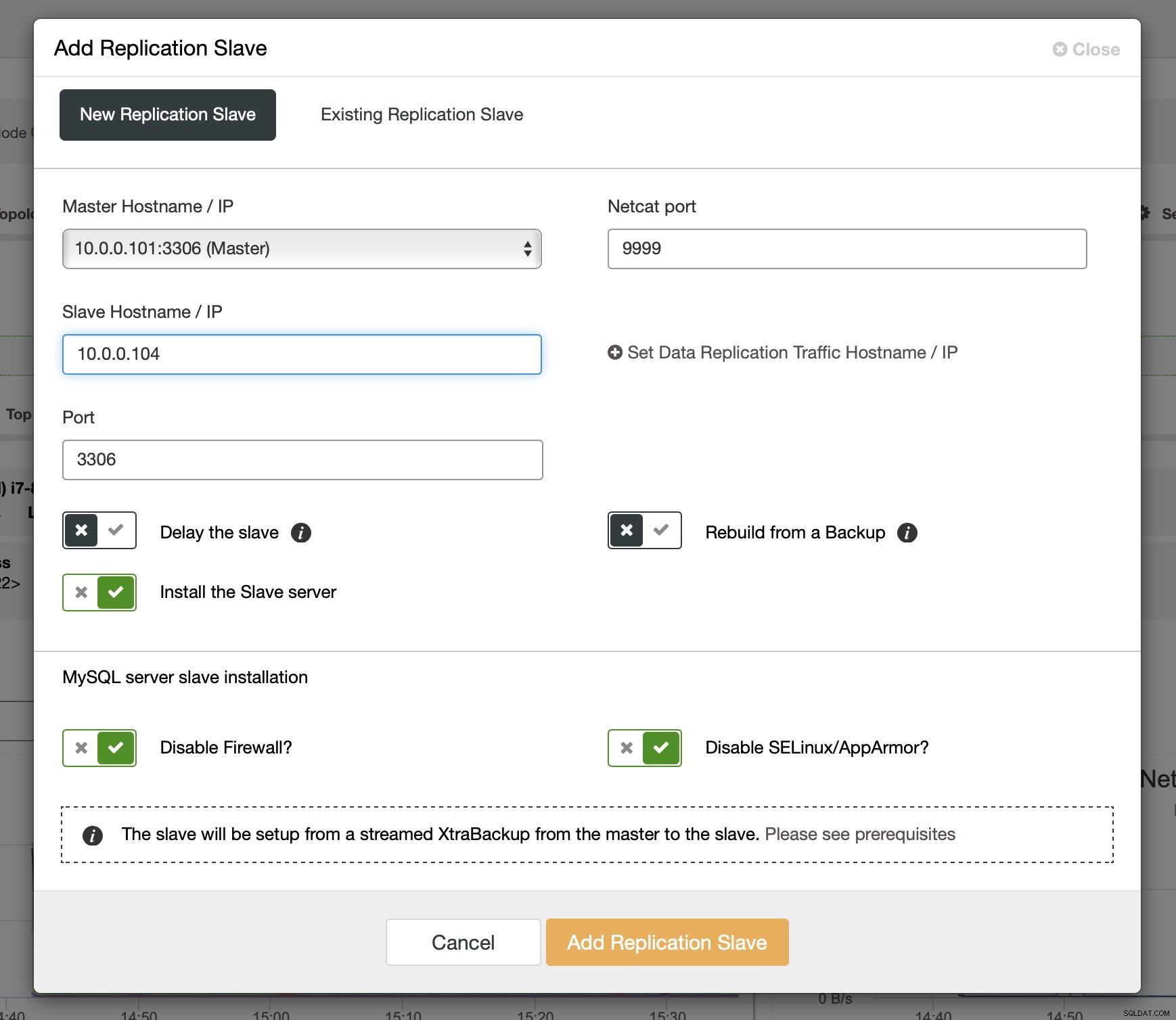
Efter att binloggar har aktiverats på några av Galera-noderna kan du fortsätta med att lägga till replikeringsslaven. I dialogrutan måste du välja mastervärden, skicka värdnamnet eller IP-adressen för slaven. Om du har nya säkerhetskopior till hands (vilket du bör göra), kan du använda en för att tillhandahålla slaven. I annat fall kommer ClusterControl att tillhandahålla det med hjälp av xtrabackup - all senaste huvuddata kommer att strömmas till slaven och sedan kommer replikeringen att konfigureras.
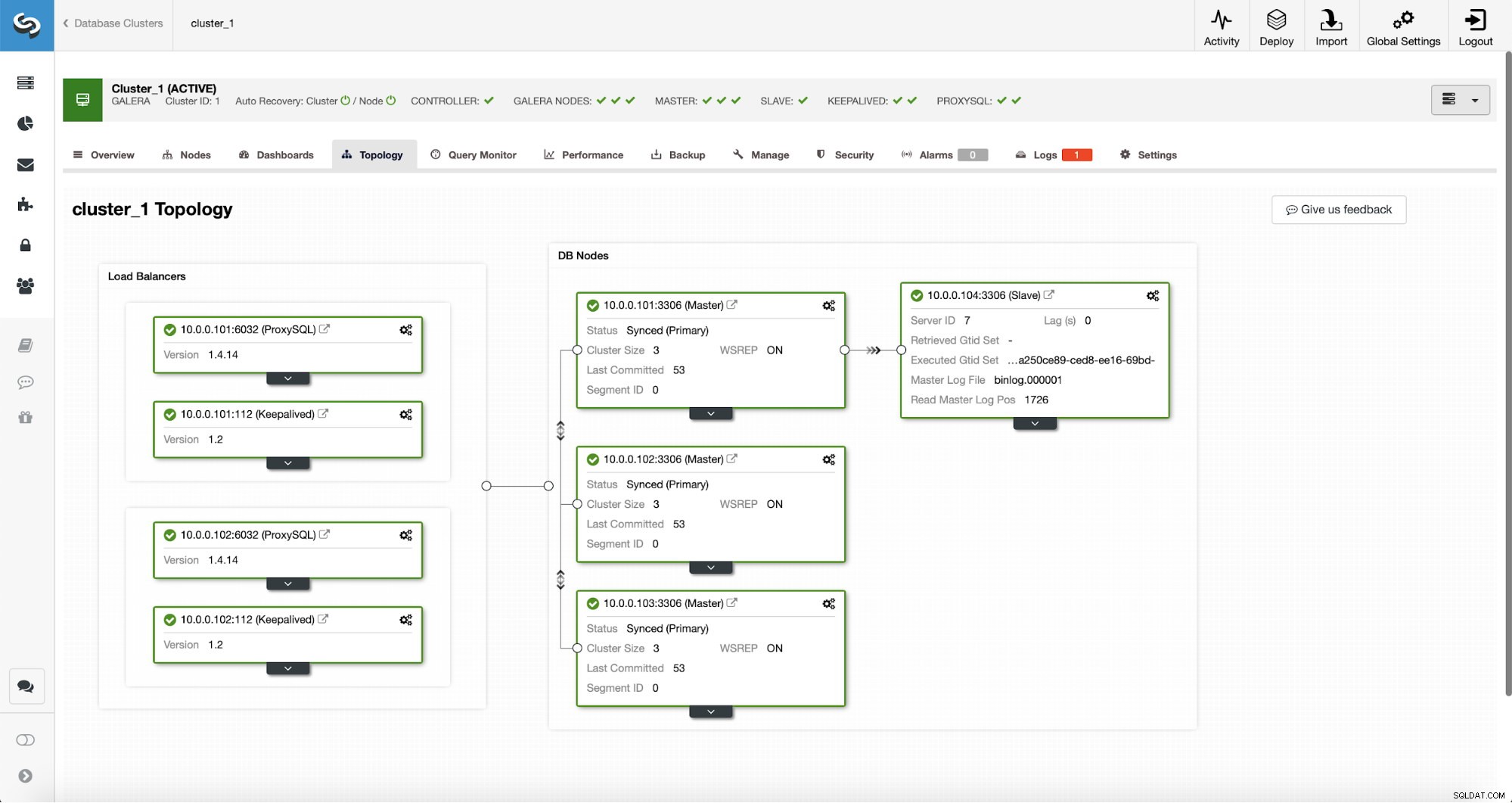
Efter att jobbet har slutförts har en replikeringsslav lagts till i klustret. Som nämnts tidigare, om 10.0.0.101 skulle dö, kommer en annan värd i Galera-klustret att väljas som master och ClusterControl kommer automatiskt att slave 10.0.0.104 från en annan nod.
När vi använder ProxySQL måste vi konfigurera det. Vi lägger till en ny server i ProxySQL.
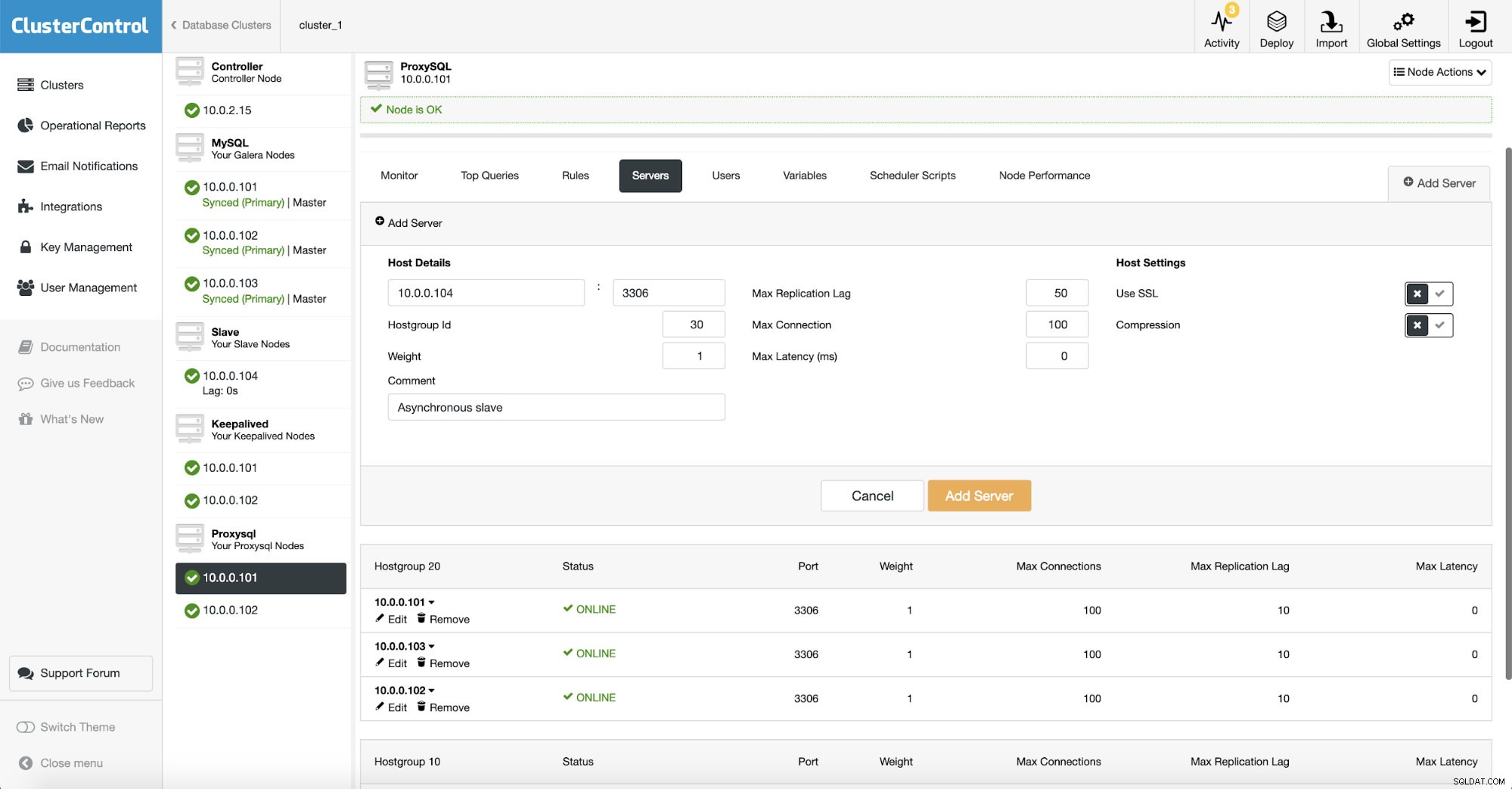
Vi skapade en annan värdgrupp (30) där vi placerade vår asynkrona slav. Vi ökade också "Max Replication Lag" till 50 sekunder från standard 10. Det är upp till ditt företags krav hur mycket analysslaven kan släpa innan det blir ett problem.
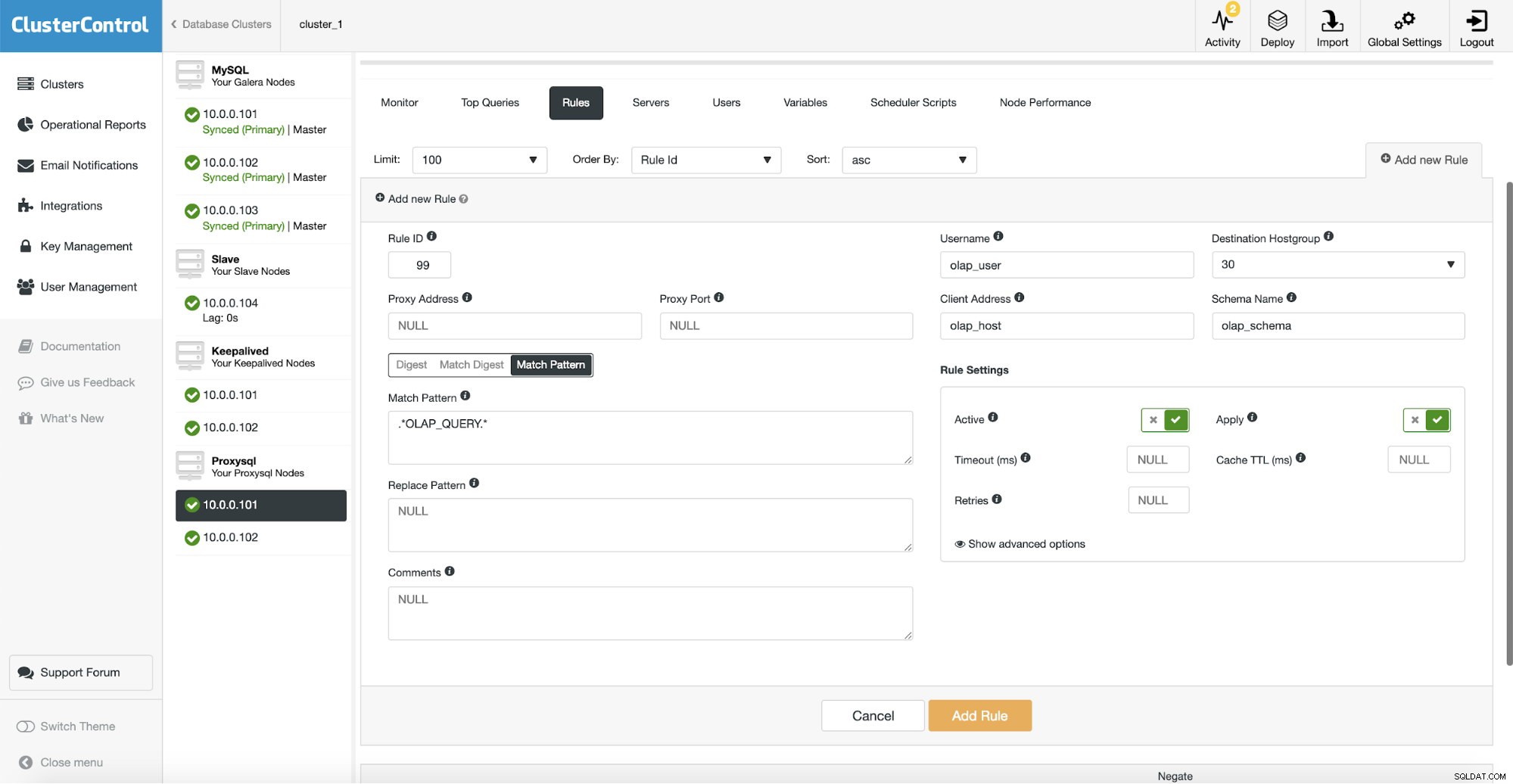
Efter det måste vi konfigurera en frågeregel som matchar vår OLAP-trafik och dirigerar den till OLAP-värdgruppen (30). På skärmdumpen ovan fyllde vi i flera fält - detta är inte obligatoriskt. Vanligtvis behöver du använda en, högst två av dem. Ovanstående skärmdump fungerar som ett exempel så att vi enkelt kan se att du kan matcha frågor med hjälp av schema (om du har ett separat schema med analytiska data), värdnamn/IP (om OLAP-förfrågningar exekveras från en viss värd), användare (om applikationen använder viss användare för analytiska frågor. Du kan också matcha frågor direkt genom att antingen skicka en fullständig fråga eller genom att markera dem med SQL-kommentarer och låta ProxySQL dirigera alla frågor med en "OLAP_QUERY"-sträng till vår analytiska värdgrupp.
Som du kan se, tack vare ClusterControl kunde vi distribuera en replikeringsslav till Galera Cluster med bara ett par klick. Vissa kanske hävdar att MySQL inte är den mest lämpliga databasen för analytisk arbetsbelastning och vi tenderar att hålla med. Du kan enkelt utöka denna inställning med ClickHouse och genom att ställa in en replikering från asynkron slav till ClickHouse kolumnära datalager för mycket bättre prestanda för analytiska frågor. Vi beskrev den här inställningen i ett av de tidigare blogginläggen.