På Stack Overflow har vi några tabeller som använder klustrade columnstore-index, och dessa fungerar utmärkt för större delen av vår arbetsbelastning. Men vi stötte nyligen på en situation där "perfekta stormar" - flera processer som alla försöker ta bort från samma CCI - skulle överväldiga CPU:n eftersom de alla gick parallellt och kämpade för att slutföra sin operation. Så här såg det ut i SolarWinds SQL Sentry:
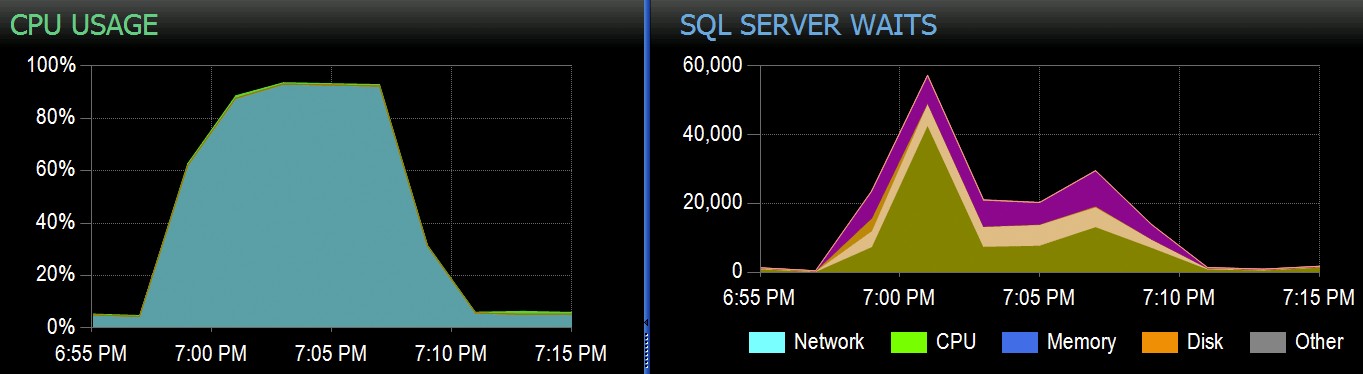
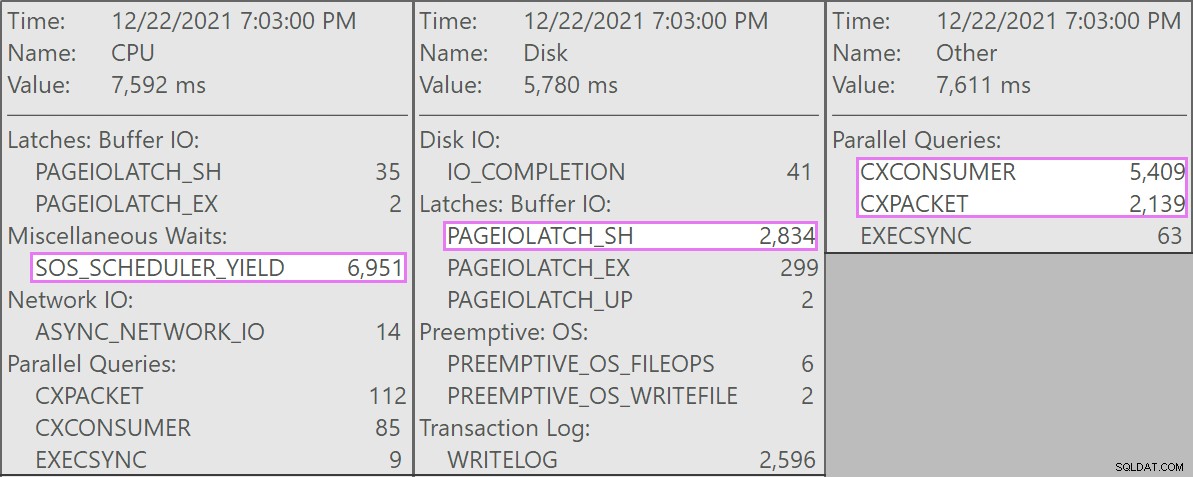
Och här är de intressanta väntetiderna i samband med dessa frågor:
Frågorna som konkurrerade var alla av denna form:
DELETE dbo.LargeColumnstoreTable WHERE col1 =@p1 AND col2 =@p2;
Planen såg ut så här:

Och varningen på skanningen informerade oss om några ganska extrema kvarvarande I/O:

Tabellen har 1,9 miljarder rader men är bara 32 GB (tack, kolumnär lagring!). Ändå skulle dessa raderingar på en rad ta 10–15 sekunder vardera, och den mesta tiden spenderas på SOS_SCHEDULER_YIELD .
Tack och lov, eftersom borttagningsoperationen i detta scenario kunde vara asynkron, kunde vi lösa problemet med två ändringar (även om jag förenklar kraftigt här):
- Vi begränsade
MAXDOPpå databasnivå så dessa borttagningar kan inte gå så parallellt - Vi förbättrade serialiseringen av processerna som kommer från applikationen (i grund och botten köade vi borttagningar genom en enda avsändare)
Som DBA kan vi enkelt styra MAXDOP , såvida det inte åsidosätts på frågenivå (ett annat kaninhål för en annan dag). Vi kan inte nödvändigtvis kontrollera applikationen i denna utsträckning, särskilt om den är distribuerad eller inte vår. Hur kan vi serialisera skrivningarna i det här fallet utan att drastiskt ändra applikationslogiken?
En mock installation
Jag tänker inte försöka skapa en tabell med två miljarder rader lokalt – strunt i den exakta tabellen – men vi kan approximera något i mindre skala och försöka återskapa samma problem.
Låt oss låtsas att det här är SuggestedEdits bord (i verkligheten är det inte). Men det är ett enkelt exempel att använda eftersom vi kan hämta schemat från Stack Exchange Data Explorer. Med hjälp av detta som bas kan vi skapa en likvärdig tabell (med några mindre ändringar för att göra det lättare att fylla i) och lägga ett klustrat kolumnlagerindex på den:
CREATE TABLE dbo.FakeSuggestedEdits( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Kommentar nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), NULL 0 nvarchar NOT DEFAULT NEWID(), Taggar nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE);
För att fylla den med 100 miljoner rader kan vi korsansluta sys.all_objects och sys.all_columns fem gånger (på mitt system kommer detta att producera 2,68 miljoner rader varje gång, men YMMV):
-- 2680350 * 5 ~ 3 minuter INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c;GO 5>Sedan kan vi kontrollera utrymmet:
EXEC sys.sp_spaceused @objname =N'dbo.FakeSuggestedEdits';Det är bara 1,3 GB, men det här borde vara tillräckligt:
Hämtar radering av vår Clustered Columnstore
Här är en enkel fråga som ungefär matchar vad vår applikation gjorde med bordet:
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;DELETE dbo.FakeSuggestedEdits WHERE Id =@p1 AND OwnerUserId =@p2;Planen är dock inte riktigt en perfekt match:
För att få det att gå parallellt och producera liknande påståenden på min magra bärbara dator, var jag tvungen att tvinga optimeraren lite med denna ledtråd:
ALTERNATIV (QUERYTRACEON 8649);Nu ser det rätt ut:
Återskapa problemet
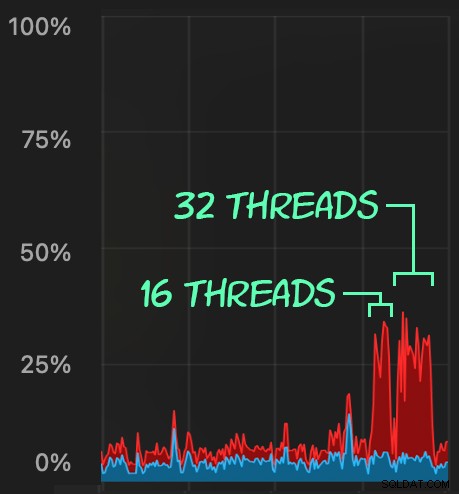
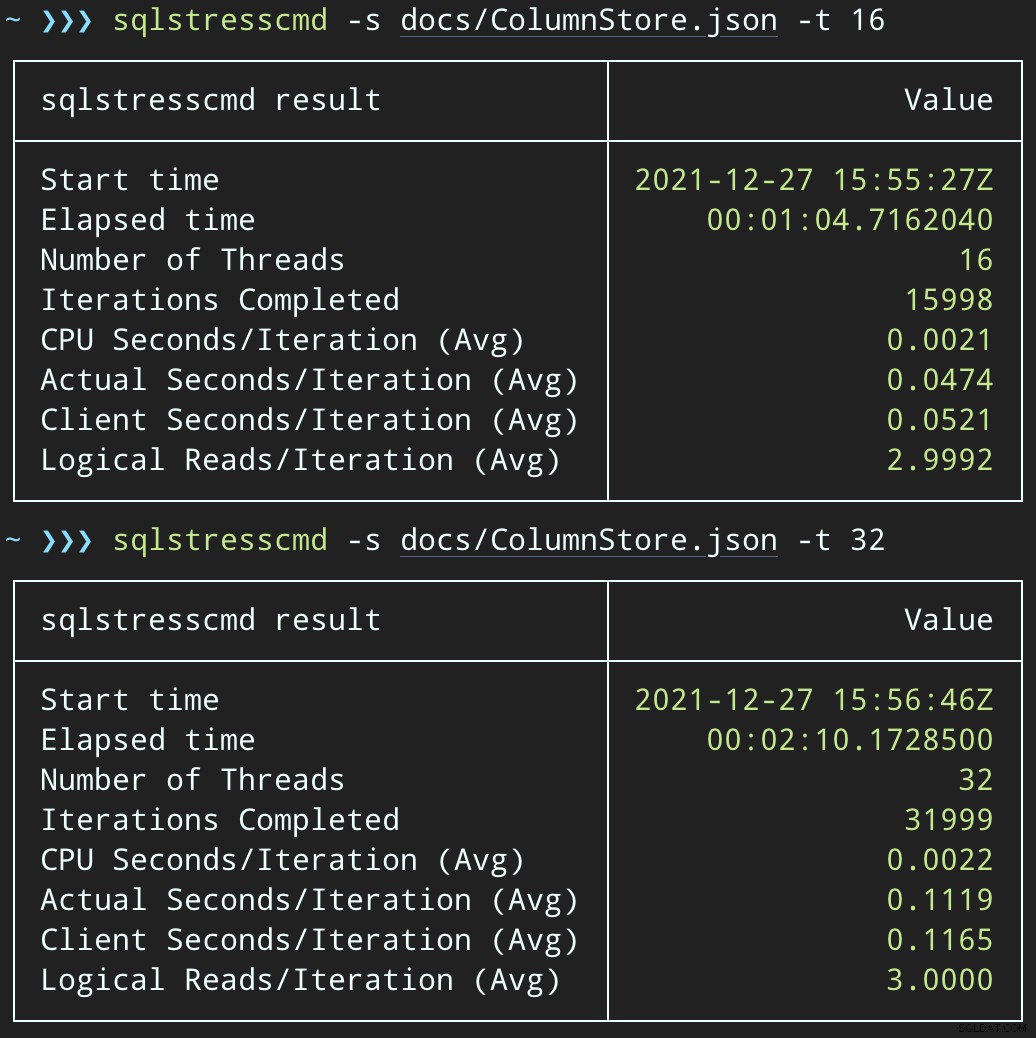
Sedan kan vi skapa en ökning av samtidig raderingsaktivitet med SqlStressCmd för att ta bort 1 000 slumpmässiga rader med 16 och 32 trådar:
sqlstresscmd -s docs/ColumnStore.json -t 16sqlstresscmd -s docs/ColumnStore.json -t 32Vi kan observera den påfrestning som detta sätter på CPU:
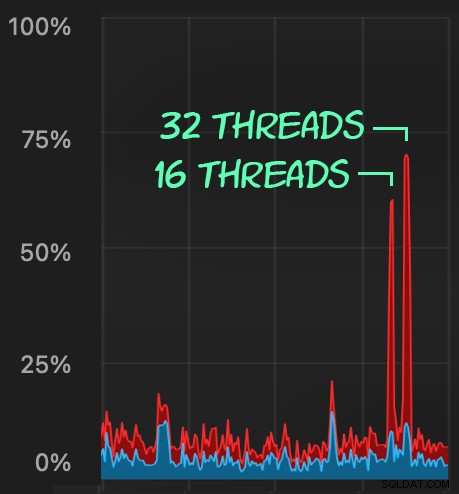
Påfrestningen på processorn varar under batcherna på cirka 64 respektive 130 sekunder:
Obs! Utdata från SQLQueryStress är ibland lite avvikande på iterationer, men jag har bekräftat att arbetet du ber den att göra görs exakt.
En möjlig lösning:En raderingskö
Till en början tänkte jag införa en kötabell i databasen, som vi kunde använda för att ladda bort raderingsaktivitet:
CREATE TABLE dbo.SuggestedEditDeleteQueue( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerpreUserId in);Allt vi behöver är en ISTÄLLET FÖR trigger för att fånga upp dessa oseriösa raderingar som kommer från applikationen och placera dem i kön för bakgrundsbearbetning. Tyvärr kan du inte skapa en utlösare i en tabell med ett klustrat kolumnlagerindex:
Msg 35358, Level 16, State 1
CREATE TRIGGER på tabellen 'dbo.FakeSuggestedEdits' misslyckades eftersom du inte kan skapa en utlösare i en tabell med ett klustrat kolumnlagerindex. Överväg att genomdriva triggerns logik på något annat sätt, eller om du måste använda en trigger, använd ett heap- eller B-tree-index istället.Vi behöver en minimal ändring av applikationskoden, så att den anropar en lagrad procedur för att hantera raderingen:
SKAPA PROCEDUR dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN STÄLL IN NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id =@Id OCH OwnerUserId =@OwnerUserId;ENDDetta är inte ett permanent tillstånd; detta är bara för att hålla beteendet oförändrat samtidigt som du bara ändrar en sak i appen. När appen har ändrats och framgångsrikt anropar den här lagrade proceduren istället för att skicka ad hoc-raderingsförfrågningar, kan den lagrade proceduren ändras:
SKAPA PROCEDUR dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN STÄLL IN NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId;ENDTesta effekten av kön
Om vi nu ändrar SqlQueryStress för att anropa den lagrade proceduren istället:
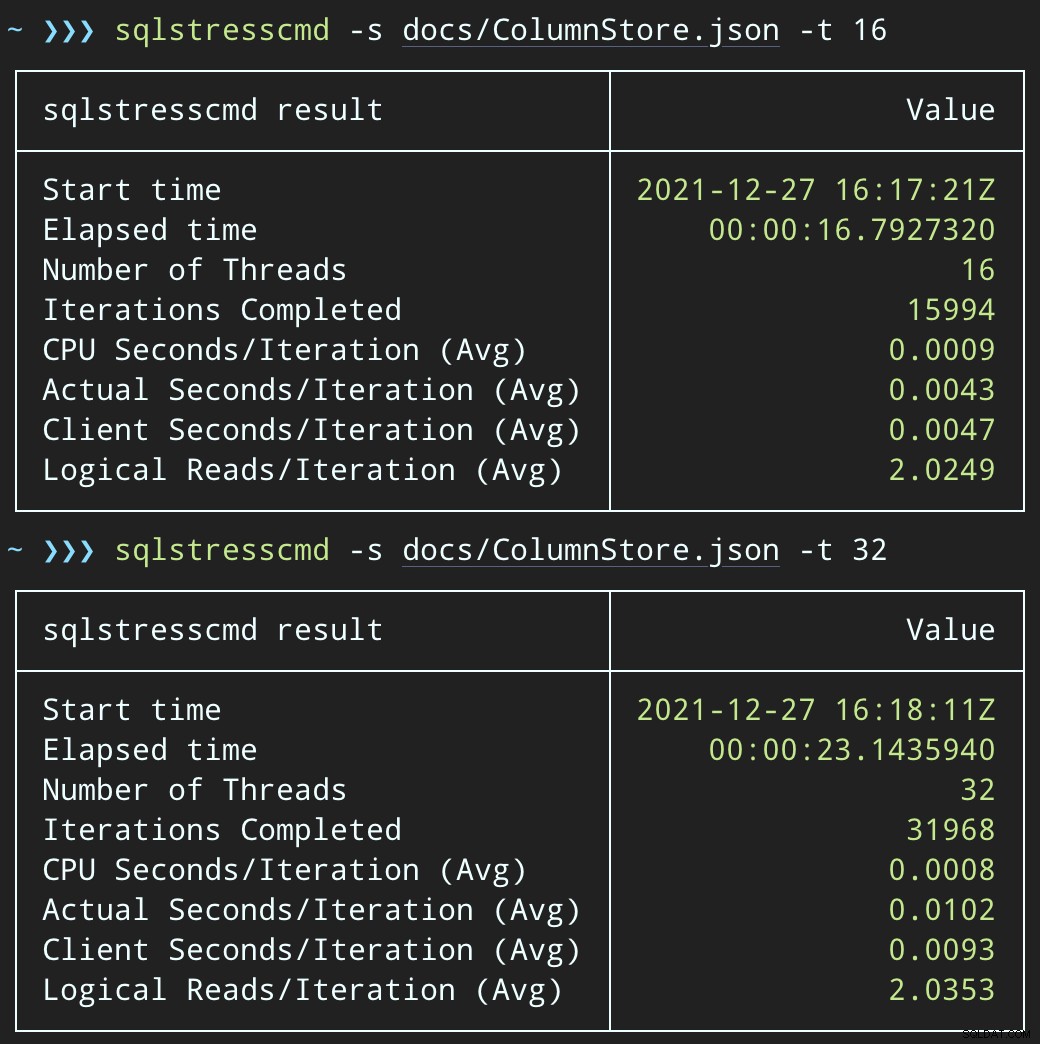
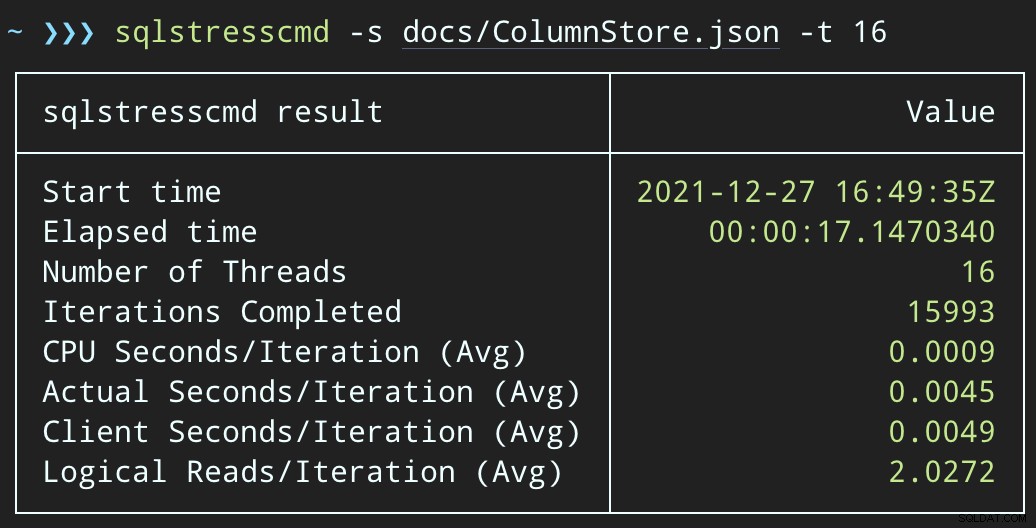
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;EXEC dbo.DeleteSuggestedEdit @Id =@p1, @OwnerUserId =@p2;Och skicka in liknande partier (placera 16 000 eller 32 000 rader i kön):
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;EXEC dbo.@Id =@p1 AND OwnerUserId =@p2;CPU-effekten är något högre:
Men arbetsbelastningen slutar mycket snabbare — 16 respektive 23 sekunder:
Detta är en betydande minskning av smärtan som applikationerna kommer att känna när de hamnar i perioder med hög samtidighet.
Vi måste fortfarande utföra raderingen, men
Vi måste fortfarande bearbeta dessa borttagningar i bakgrunden, men vi kan nu införa batchning och ha full kontroll över hastigheten och eventuella förseningar vi vill injicera mellan operationerna. Här är den mycket grundläggande strukturen för en lagrad procedur för att bearbeta kön (visserligen utan fullständig transaktionskontroll, felhantering eller rensning av kötabeller):
SKAPA PROCEDUR dbo.ProcessSuggestedEditQueue @JobSize int =10000, @BatchSize int =100, @DelayInSeconds int =2 -- måste vara mellan 1 och 59ASBEGIN SET NOCOUNT ON; DECLARE @d TABLE(Id int, OwnerUserId int); DECLARE @rc int =1, @jc int =0, @wf nvarchar(100) =N'WAITFOR DELAY ' + CHAR(39) + '00:00:' + RIGHT('0' + CONVERT(varchar(2) , @DelayInSeconds), 2) + CHAR(39); MEDAN @rc> 0 OCH @jc <@JobSize BÖRJA DELETE @d; UPPDATERA TOP (@BatchSize) q SET ProcessedDate =sysdatetime() OUTPUT inserted.Id, inserted.OwnerUserId INTO @d FRÅN dbo.SuggestedEditDeleteQueue SOM q WITH (UPDLOCK, READPAST) WHERE NUELLedDate; SET @rc =@@ROWCOUNT; OM @rc =0 BREAK; DELETE fse FRÅN dbo.FakeSuggestedEdits AS fse INNER JOIN @d AS d PÅ fse.Id =d.Id OCH fse.OwnerUserId =d.OwnerUserId; SET @jc +=@rc; IF @jc> @JobSize BREAK; EXEC sys.sp_executesql @wf; END RAISERROR('Raderade %d rader.', 0, 1, @jc) MED NUWAIT;SLUTNu kommer det att ta längre tid att ta bort rader – genomsnittet för 10 000 rader är 223 sekunder, varav ~100 är avsiktlig fördröjning. Men ingen användare väntar, så vem bryr sig? CPU-profilen är nästan noll, och appen kan fortsätta att lägga till objekt i kön så mycket samtidigt som den vill, med nästan noll konflikt med bakgrundsjobbet. Medan jag bearbetade 10 000 rader lade jag till ytterligare 16 000 rader i kön, och den använde samma CPU som tidigare – det tog bara en sekund längre än när jobbet inte kördes:
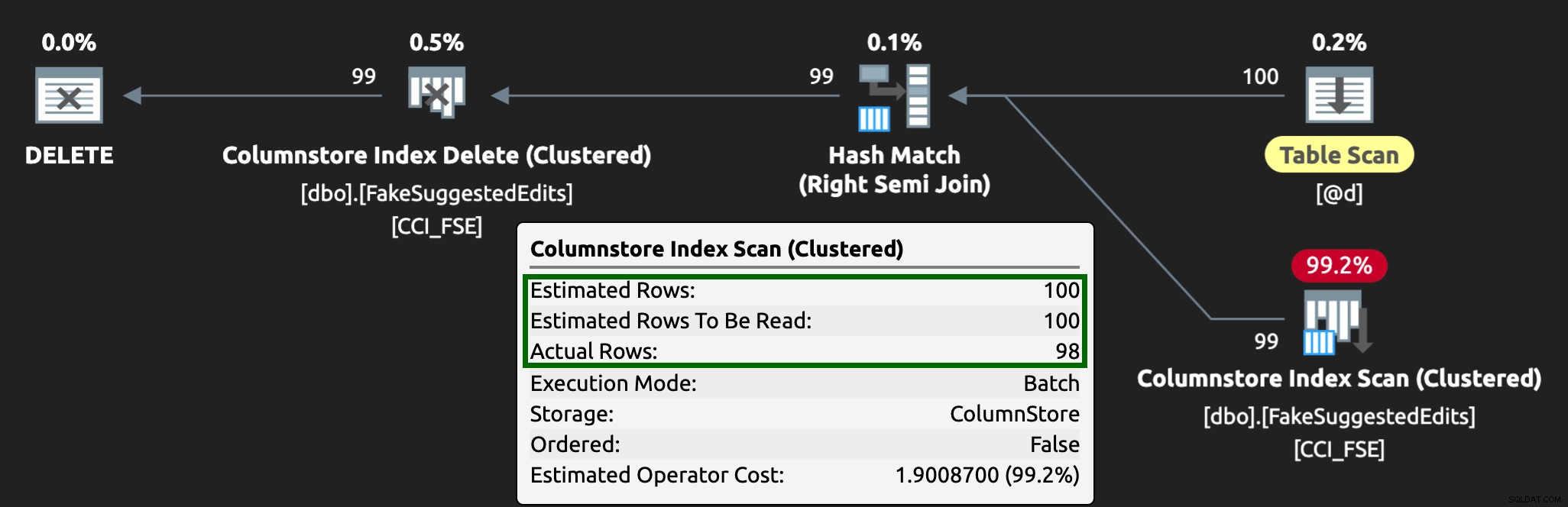
Och planen ser nu ut så här, med mycket bättre uppskattade / faktiska rader:
Jag kan se att denna kötabellsmetod är ett effektivt sätt att hantera hög DML samtidighet, men det kräver åtminstone lite flexibilitet med de applikationer som skickar DML – detta är en anledning till att jag verkligen gillar att applikationer anropar lagrade procedurer, eftersom de ge oss mycket mer kontroll närmare data.
Andra alternativ
Om du inte har möjlighet att ändra raderingsfrågorna som kommer från programmet – eller om du inte kan skjuta upp borttagningarna till en bakgrundsprocess – kan du överväga andra alternativ för att minska effekten av borttagningarna:

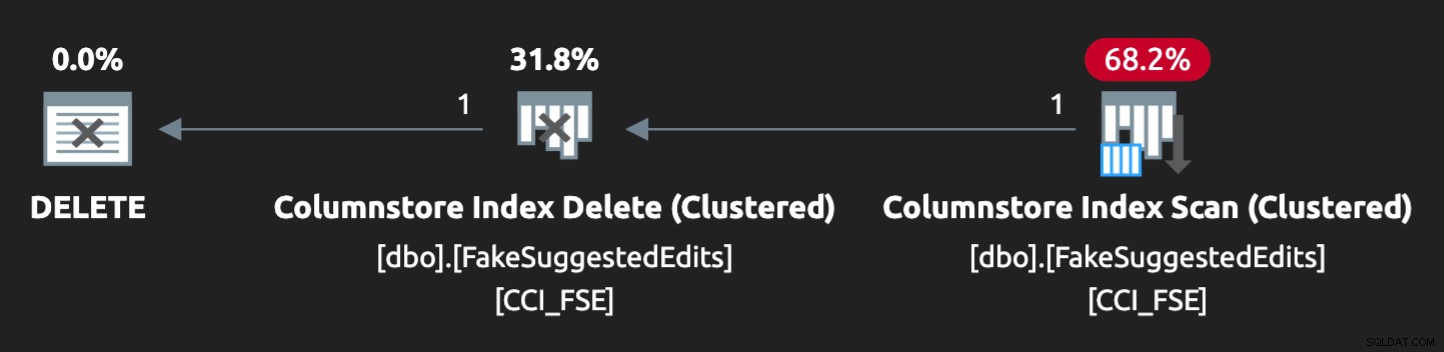

- Ett icke-klustrat index på predikatkolumnerna för att stödja punktuppslagningar (vi kan göra detta isolerat utan att ändra applikationen)
- Enbart användning av mjuka borttagningar (kräver fortfarande ändringar av programmet)
Det ska bli intressant att se om dessa alternativ erbjuder liknande fördelar, men jag sparar dem för ett framtida inlägg.