Min vän Peter Larsson skickade mig en T-SQL-utmaning som gick ut på att matcha utbud med efterfrågan. När det gäller utmaningar är det en formidabel sådan. Det är ett ganska vanligt behov i verkliga livet; det är enkelt att beskriva och det är ganska enkelt att lösa med rimlig prestanda med en markörbaserad lösning. Det knepiga är att lösa det med en effektiv set-baserad lösning.
När Peter skickar ett pussel till mig svarar jag vanligtvis med ett förslag på lösning, och han brukar komma på en bättre presterande, lysande lösning. Jag misstänker ibland att han skickar pussel till mig för att motivera sig själv att komma på en bra lösning.
Eftersom uppgiften representerar ett vanligt behov och är så intressant frågade jag Peter om han skulle ha något emot om jag delade den och hans lösningar med sqlperformance.com-läsarna, och han lät mig gärna.
Den här månaden kommer jag att presentera utmaningen och den klassiska markörbaserade lösningen. I efterföljande artiklar kommer jag att presentera uppsättningsbaserade lösningar – inklusive de som Peter och jag arbetade med.
Utmaningen
Utmaningen innebär att fråga efter en tabell som heter Auktioner, som du skapar med hjälp av följande kod:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Den här tabellen innehåller efterfråge- och utbudsposter. Efterfrågeposter är markerade med koden D och utbudsposter med S. Din uppgift är att matcha utbuds- och efterfråganskvantiteter baserat på ID-beställning, skriva resultatet i en tillfällig tabell. Posterna kan representera köp- och säljorder för kryptovaluta som BTC/USD, aktieköp- och säljorder som MSFT/USD, eller någon annan vara eller vara där du behöver matcha utbud med efterfrågan. Observera att auktionsbidragen saknar ett prisattribut. Som nämnts bör du matcha utbud och efterfrågan kvantiteter baserat på ID-beställning. Denna ordning kunde ha härletts från pris (stigande för utbudsposter och fallande för efterfrågeposter) eller andra relevanta kriterier. I den här utmaningen var tanken att hålla saker och ting enkla och anta att ID:t redan representerar den relevanta ordningen för matchning.
Som ett exempel, använd följande kod för att fylla auktionstabellen med en liten uppsättning exempeldata:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Du ska matcha utbuds- och efterfråganskvantiteterna så här:
- En kvantitet på 5,0 matchas för efterfrågan 1 och utbud 1000, vilket minskar krav 1 och lämnar 3,0 av utbud 1000
- En kvantitet på 3,0 matchas för efterfrågan 2 och utbud 1000, vilket tar bort både efterfrågan 2 och utbud 1000
- En kvantitet på 6,0 matchas för Demand 3 och Supply 2000, vilket lämnar 2,0 av Demand 3 och minskar utbudet 2000
- En kvantitet på 2,0 matchas för efterfrågan 3 och utbud 3000, vilket tar bort både efterfrågan 3 och utbud 3000
- En kvantitet på 2,0 matchas för efterfrågan 5 och utbud 4000, vilket tar bort både efterfrågan 5 och utbud 4000
- En kvantitet på 4,0 matchas för efterfrågan 6 och utbud 5000, vilket lämnar 4,0 av efterfrågan 6 och minskar utbudet 5000
- En kvantitet på 3,0 matchas för efterfrågan 6 och utbud 6000, vilket lämnar 1,0 av efterfrågan 6 och minskar utbudet 6000
- En kvantitet på 1,0 matchas för efterfrågan 6 och utbud 7000, vilket minskar krav 6 och lämnar 1,0 av utbud 7000
- En kvantitet på 1,0 matchas för krav 7 och utbud 7000, vilket lämnar 3,0 av krav 7 och utarmar utbud 7000; Efterfrågan 8 matchas inte med några leveransposter och lämnas därför med hela kvantiteten 2.0
Din lösning är tänkt att skriva följande data i den resulterande temporära tabellen:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Stor uppsättning exempeldata
För att testa lösningarnas prestanda behöver du en större uppsättning exempeldata. För att hjälpa till med detta kan du använda funktionen GetNums, som du skapar genom att köra följande kod:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Denna funktion returnerar en sekvens av heltal i det begärda intervallet.
Med den här funktionen på plats kan du använda följande kod från Peter för att fylla i auktionstabellen med exempeldata och anpassa indata efter behov:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Som du kan se kan du anpassa antalet köpare och säljare samt minsta och maximala köpar- och säljarkvantiteter. Ovanstående kod specificerar 200 000 köpare och 200 000 säljare, vilket resulterar i totalt 400 000 rader i auktionstabellen. Den sista frågan berättar hur många efterfråge- (D) och utbud (S) poster som skrevs till tabellen. Den returnerar följande utdata för de tidigare nämnda ingångarna:
Code Items ---- ----------- D 200000 S 200000
Jag ska testa prestanda för olika lösningar med ovanstående kod och ställa in antalet köpare och säljare var och en till följande:50 000, 100 000, 150 000 och 200 000. Det betyder att jag får följande totala antal rader i tabellen:100 000, 200 000, 300 000 och 400 000. Naturligtvis kan du anpassa ingångarna som du vill för att testa prestanda för dina lösningar.
Markörbaserad lösning
Peter tillhandahöll den markörbaserade lösningen. Det är ganska grundläggande, vilket är en av dess viktiga fördelar. Det kommer att användas som ett riktmärke.
Lösningen använder två markörer:en för efterfrågeposter sorterade efter ID och den andra för utbudsposter sorterade efter ID. För att undvika en fullständig genomsökning och sortering per markör, skapa följande index:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Här är den fullständiga lösningens kod:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Som du kan se börjar koden med att skapa en tillfällig tabell. Den deklarerar sedan de två markörerna och hämtar en rad från varje, och skriver den aktuella efterfrågan kvantitet till variabeln @DemandQuantity och den aktuella leverans kvantiteten till @SupplyQuantity. Den bearbetar sedan posterna i en loop så länge som den senaste hämtningen lyckades. Koden tillämpar följande logik i slingans kropp:
Om den aktuella efterfrågan är mindre än eller lika med den aktuella leveranskvantiteten, gör koden följande:
- Skriver en rad i den tillfälliga tabellen med den aktuella parningen, med efterfrågan kvantitet (@DemandQuantity) som matchad kvantitet
- Subtraherar den aktuella efterfrågekvantiteten från den aktuella leveranskvantiteten (@SupplyQuantity)
- Hämtar nästa rad från efterfrågemarkören
Annars gör koden följande:
- Kontrollerar om den aktuella leveransmängden är större än noll, och i så fall gör den följande:
- Skriver en rad i temptabellen med den aktuella parningen, med leveranskvantiteten som matchad kvantitet
- Subtraherar den aktuella utbudskvantiteten från den aktuella efterfrågan
- Hämtar nästa rad från utbudsmarkören
När slingan är klar finns det inga fler par att matcha, så koden rengör bara markörresurserna.
Ur prestandasynpunkt får du den typiska overheaden för markörhämtning och looping. Återigen gör den här lösningen en enda beställd pass över efterfrågedata och en enda beställd passering över utbudsdata, var och en med hjälp av en sök- och intervallskanning i indexet du skapade tidigare. Planerna för markörfrågorna visas i figur 1.

Figur 1:Planer för markörfrågor
Eftersom planen utför en sök- och beställningsavsökning av var och en av delarna (efterfrågan och utbud) utan någon sortering inblandad, har den linjär skalning. Detta bekräftades av prestandasiffrorna jag fick när jag testade den, som visas i figur 2.
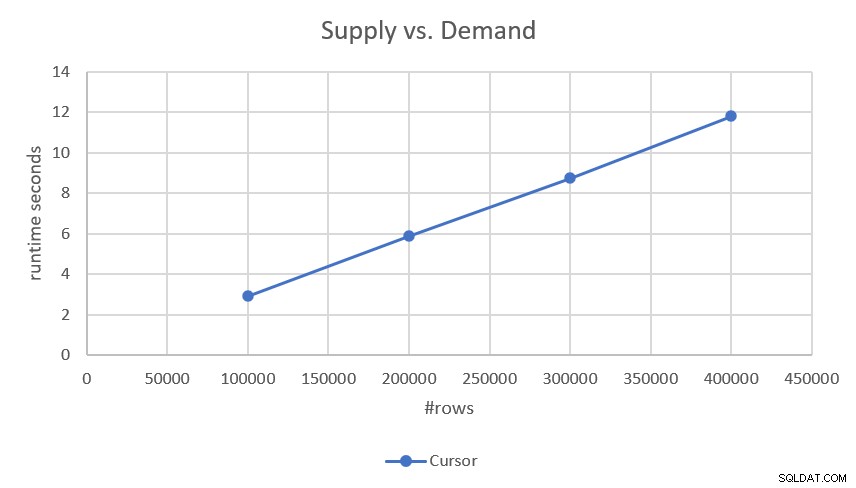
Figur 2:Prestanda för markörbaserad lösning
Om du är intresserad av mer exakta körtider, här är de:
- 100 000 rader (50 000 krav och 50 000 förbrukningsmaterial):2,93 sekunder
- 200 000 rader:5,89 sekunder
- 300 000 rader:8,75 sekunder
- 400 000 rader:11,81 sekunder
Med tanke på att lösningen har linjär skalning kan du enkelt förutsäga körtiden med andra skalor. Till exempel, med en miljon rader (säg 500 000 krav och 500 000 leveranser) bör det ta cirka 29,5 sekunder att köra.
Utmaningen är på gång
Den markörbaserade lösningen har linjär skalning och som sådan är den inte dålig. Men det ådrar sig den typiska markörhämtningen och looping overhead. Självklart kan du minska denna omkostnad genom att implementera samma algoritm med en CLR-baserad lösning. Frågan är, kan du komma på en välpresterande uppsättningsbaserad lösning för denna uppgift?
Som nämnts kommer jag att utforska uppsättningsbaserade lösningar – både dåliga och välpresterande – från och med nästa månad. Under tiden, om du klarar utmaningen, se om du kan komma med egna uppsättningsbaserade lösningar.
För att verifiera riktigheten av din lösning, jämför först dess resultat med det som visas här för den lilla uppsättningen exempeldata. Du kan också kontrollera giltigheten av din lösnings resultat med en stor uppsättning exempeldata genom att verifiera att den symmetriska skillnaden mellan markörlösningens resultat och ditt är tom. Förutsatt att markörens resultat lagras i en temptabell som heter #PairingsCursor och ditt i en temptabell som heter #MyPairings, kan du använda följande kod för att uppnå detta:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Resultatet ska vara tomt.
Lycka till!
[ Hoppa till lösningar:Del 1 | Del 2 | Del 3 ]