Oavsett vilken sida av ekvationen du befinner dig på, ibland är det svårt att hitta en kvalificerad person för ett specifikt jobb. I det här inlägget tittar vi på en datamodell för att hjälpa rekryterare och HR-avdelningar att hålla sig organiserade under anställningsprocessen.
De flesta av oss har varit delaktiga i anställningsprocessen – oftast som arbetssökande. Men vi kan också vara involverade på anställningssidan, kanske genom att testa sökandens tekniska kunskaper. Rekryteringsprocessen tar en viss tid och gruppen sökande växer hela tiden mindre när vi närmar oss det slutgiltiga beslutet. Resultatet bör vara valet av den bästa personen för jobbet.
Att rekrytera i sig är ganska komplicerat, så vi kommer att diskutera en ganska omfattande datamodell för att täcka alla aspekter av processen. Luta dig tillbaka i stolen och njut av dagens artikel!
Så fungerar rekryteringsprocessen
De flesta delar av rekryteringsprocessen är allmänt kända, men vi kommer att diskutera exakt hur det fungerar innan vi går vidare till datamodellen.
-
upptäcka ett behov
Detta är ett absolut måste i rekryteringsprocessen; det blir ingen process om ledningen inte är medveten om behovet av att anställa en ny medarbetare. Det behovet kan vara resultatet av att starta ett nytt företag, växa i ett befintligt företag eller att en nuvarande anställd slutar.
Om inte ett företag har strikt definierade positioner (t.ex. banker) är det inte alltid lätt att avgöra när man ska anställa en ny medarbetare. Att prata med anställda och se mycket övertid kan sporra en nyanställning. Interna eller externa regler kan också kräva att vissa tjänster endast ges till personer med en specifik kompetens och relevant arbetslivserfarenhet (t.ex. internrevisor).
-
Beskriv positionen och dess nödvändiga färdigheter
För att få en uppfattning om detta steg, tänk på en riktigt välskriven arbetsbeskrivning. Den innehåller:
- En lista över alla uppgifter relaterade till jobbet
- Minsta utbildnings- och arbetslivserfarenhetskvalifikationer
- Särskilda färdigheter som är nödvändiga för jobbfunktioner
- Ytterligare eller föredragna färdigheter
- En sammanfattning av vad arbetsgivaren förväntar sig av den sökande och vad den sökande kan förvänta sig av detta jobb
- Ett löneintervall och kanske ett förmånspaket
Denna information är viktig för både rekryterare och sökande. Det är ingen idé att bjuda in tio sökande till urvalsprocessen om ingen av dem kommer att vara nöjd med det ekonomiska erbjudandet. Och ju mer detaljerad arbetsbeskrivningen är, desto lättare blir det att attrahera kvalificerade sökande.
-
Definiera vem som ska hantera processen och när varje uppgift ska ske
Nästa steg är att definiera specifika datum när varje del av processen kommer att ske. Företag kan också tilldela anställda till varje steg. Om företaget har en personalavdelning kommer det troligen att hantera varje del av rekryteringsprocessen, även om andra anställda kan bidra med sin specifika kunskap när det behövs (t.ex. om vi anställer en IT-specialist bör chefen för IT-avdelningen bedöma kandidater ' tekniska förmågor).
Om det inte finns någon HR-avdelning kan vi förvänta oss att ledningspersonal kommer att ansvara för processen. I små och medelstora företag behövs detta inte bara, det är önskvärt.
-
Lägg upp jobbet
Nu är vi redo att lägga upp en arbetsbeskrivning på vår sida, på jobbbrädor eller aggregatorer eller i en tidning. Arbetsinlägget bör innehålla punkterna som anges i steg 2. Detta kommer att hjälpa potentiella kandidater att avgöra om de vill söka tjänsten. Det är viktigt att göra arbetsbeskrivningen korrekt; vi har alla slösat bort vår tid på att intervjua för ett jobb som inte matchade dess beskrivning eller våra förväntningar.
-
Välja ut, testa och intervjua kandidater
Efter ansökningsperiodens slut kommer de sökande med den mest relevanta kompetensen och erfarenheten att bjudas in till en första utvärderingsfas (vanligtvis en intervju eller ett test). Övriga sökande kommer att informeras om att de inte har blivit utvalda till jobbet. Ett stort företag bör bjuda in ett fördefinierat minsta antal kandidater till den första utvärderingen. Detta sparar tid för både de sökande och företaget.
Små och medelstora företag kan besluta sig för att fortsätta processen tills de hittar den bästa passformen. I sådana fall kommer ansökningsperioden att vara öppen tills rätt kandidat har hittats och alla andra datum kommer att definieras längs vägen.
Intervju- och testprocessen kommer att variera beroende på företagsstorlek och organisation. I stora företag med HR-avdelningar kommer det sannolikt att finnas en uppsättning tester för att kontrollera sökandes jobbkunskaper. Andra tester kan mäta psykologiska och personlighetsdrag för att bestämma matchningen mellan sökande och jobb, matchning mellan sökande och företag eller till och med sökandens förstånd. ☺
Dessa test kommer vanligtvis att delas upp i flera steg, och varje steg kommer att minska antalet sökande.
-
Den sista intervjun
Det här steget kommer förmodligen att vara en intervju med de få bästa sökandena. Det är det viktigaste steget i processen eftersom de sökande kan tala för sig själva, visa sin kompetens och personlighet och avgöra om företaget och befattningen kommer att passa dem. Efter detta steg kommer den bästa sökanden att få ett erbjudande. Om de accepterar är rekryteringsprocessen för den tjänsten över. Om den sökande tackar nej till jobberbjudandet kommer företaget att lämna ett erbjudande till sitt nästa val.
-
Finns det skillnader i rekryteringsprocessen för små, medelstora och stora företag? Hur ska vi lösa dem i vår modell?
Det kommer att finnas vissa skillnader i rekryteringsprocesserna för små, medelstora och stora företag. Dessutom kommer processen att variera beroende på vilka tjänster som rekryteras. Tänk på hur olika de färdigheter och erfarenheter som krävs är för en innehållsansvarig, en ornitolog och en kryssningsfartygskapten. Vissa jobb kommer att ha fler tester och intervjuer, andra kanske bara har ett fåtal. Men i slutändan handlar allt om att få rätt svar och att rangordna sökande.
I den här modellen kommer jag att behandla alla tester och intervjuer på samma sätt. Vi lagrar varje sökandes svar, relaterar dem till den relevanta frågan och lagrar sökandens poäng för varje steg i processen.
-
Vem kan använda denna datamodell?
Denna modell är mycket specifik och bör endast användas för rekryteringsprocessen. Men det är inte begränsat till HR-avdelningar; du kan också använda den här modellen för att driva en professionell rekryteringstjänst.
-
Datamodellen
Datamodellen består av fem huvudämnesområden:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Jag kommer att beskriva varje ämnesområde separat, i samma ordning som de är listade.
Avsnitt 1:Jobb
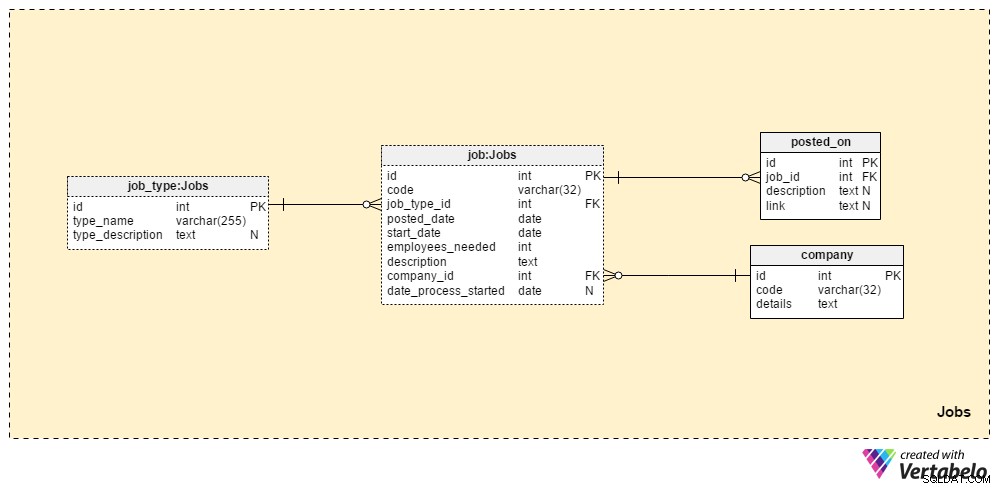
Jobs sektionen kommer att lagra alla detaljer för alla positioner vi någonsin har lagt upp. De två ordbokstabellerna, company tabellen och job_type tabell, är en del av den initiala installationen. De återstående två tabellerna, job och posted_on , innehåller "riktiga" data relaterade till jobbannonser.
job_type ordboken innehåller en lista över olika och UNIKA jobbtyper. Vi kan förvänta oss värden som ”senior databasadministratör” eller "IT-journalist" ska lagras i type_name attribut. type_description attribut kan lagra en mer detaljerad beskrivning av jobbet.
company ordboken innehåller en lista över alla företag vi arbetar med. Om vi anställer anställda endast för vårt företag kommer denna ordbok endast att innehålla vårt företagsnamn. Om vi är en rekryteringsbyrå kommer den att lagra namnen på alla företag som anställt oss.
En lista över alla jobbpositioner som vi någonsin har lagt ut lagras i "jobb"-tabellen. Attributen i den här tabellen är:
code– Vårt interna UNIKA ID används för att beteckna ett jobb.job_type_id– Refererar till den relaterade jobbtypen.posted_date– Datumet då denna tjänst postades.start_date– Det förväntade startdatumet (första arbetsdagen) för jobbet.employees_needed– Antalet medarbetare vi vill anställa under den här rekryteringsprocessen. Oftast kommer detta att ha värdet "1", men i vissa fall – t.ex. när du startar ett nytt företag eller etablerar en ny avdelning – vi kan förvänta oss större värden.description– En detaljerad beskrivning av den positionen. Det här är platsen där vi listar alla nödvändiga, föredragna och önskade jobbkunskaper.company_id– Refererar till id:t för företaget som anlitade oss. Om vi är en rekryteringsbyrå kommer detta att hänvisa till ett företagsnamn som lagras icompanytabell. Annars blir det vårt eget företags ID.date_process_started– Startdatumet för rekryteringsprocessen. Detta kan vara NULL om vi behöver definiera framtida steg och åtgärder för det här jobbet.
Den sista tabellen i detta ämnesområde är posted_on tabell. För varje job_id , lagrar vi en link till jobbinlägget och den relaterade description . Vi skulle kunna använda dessa uppgifter för att ta reda på var de sökande hittar våra jobb.
Avsnitt 2:Sökande, rekryterare och dokument
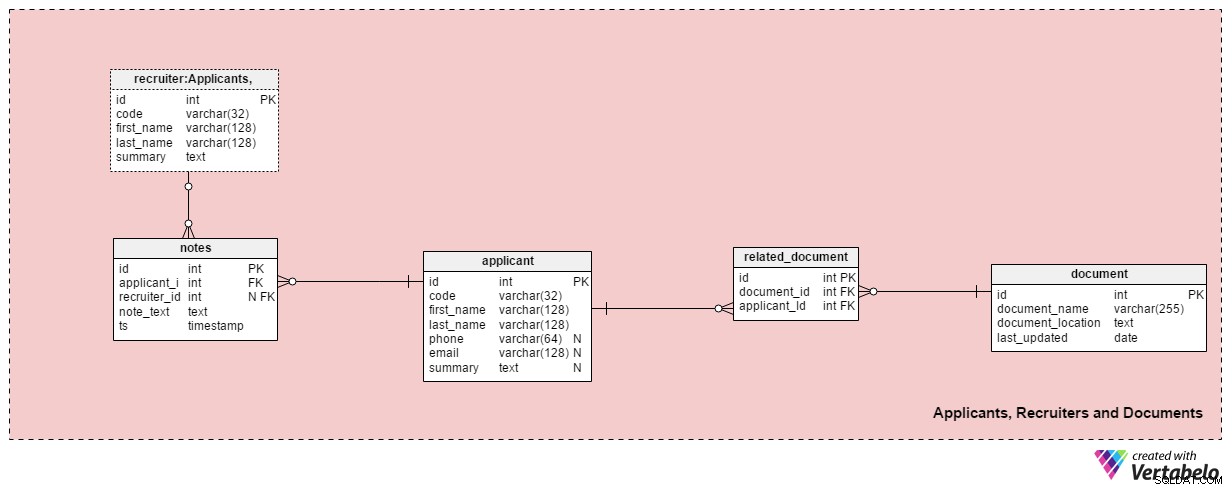
Detta ämnesområde innehåller alla tabeller som behövs för att lagra information om rekryterare, sökande och deras relaterade dokument.
applicant Tabellen listar alla sökande vi någonsin haft kontakt med. Varje sökande är UNIKT definierad i vårt system med en "kod". Utöver det kommer vi att lagra varje sökandes för- och efternamn, phone nummer, email adress och deras summary . Denna tabell kan anpassas för specifika behov, t.ex. lägga till ytterligare telefonnummer, e-postmeddelanden eller fysiska adresser.
Vi hänvisar sökande med tillgängliga dokument. En lista över alla tillgängliga dokument (CV eller CV, examina eller diplom, utskrifter, intyg, etc.) lagras i document tabell. För varje dokument lagrar vi dess namn i systemet, dess plats och tidpunkten för den senaste uppdateringen.
Vi kopplar sökande till dokument med hjälp av related_document tabell. Den innehåller bara två främmande nycklar, som bildar document_id – applicant_id UNIKT par.
recruiter Tabellen listar de anställda som kan tilldelas en jobbansökan eller som skriver in anteckningar relaterade till en sökande. Varje rekryterare definieras UNIKT av hennes eller hans code . Vi lagrar endast grundläggande information som first_name , last_name och rekryterarens summary .
Den sista tabellen i detta ämnesområde är notes tabell. Det är här vi lagrar alla anteckningar relaterade till en sökande. Vi kunde lagra anteckningar som "Den sökande missade mötet" eller "Den sökande gjorde det bra vid första intervjun" . För varje anteckning lagrar vi ID för rekryteraren som gjorde anteckningen, ID för den relaterade sökanden, note_text , och tidsstämpeln när anteckningen skapades.
Avsnitt 3:Testdetaljer
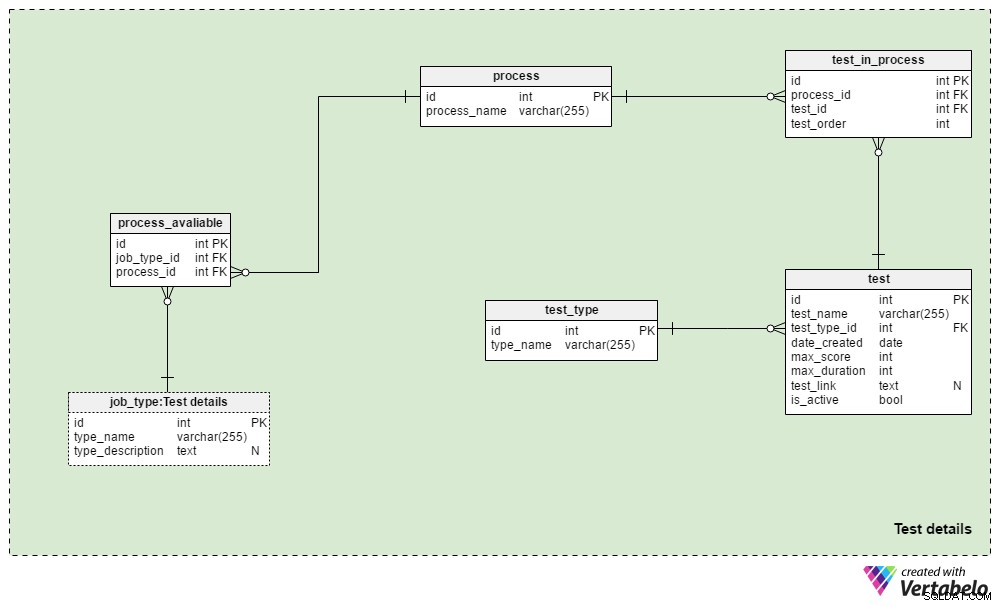
Test details ämnesområdet innehåller de tabeller som används för att definiera rekryteringsprocesser och de tester som används under dessa processer. Vi kommer i allmänhet alltid att använda samma urvalsprocess för samma jobbtyp:ändringar görs endast när de krävs av affärsförhållandena. Vi skulle kunna använda några olika processer för varje jobbtyp, och vi kommer nästan säkert att använda samma process för olika jobbtyper.
process tabellen är en enkel ordbok som endast innehåller ett UNIKT process_name attribut. Den listar alla rekryteringsprocesser som vi någonsin har använt och använder för närvarande.
Vi kommer att relatera processer till olika jobbtyper. Vi lagrar dessa relationer i process_available tabell. Dess enda attribut är det UNIKA paret job_type_id – process_id . När det finns flera processer tillgängliga för en jobbtyp, tillåter detta rekryteraren att välja en.
test_in_process Tabell används för att definiera testordningen under den processen. Attributen i den här tabellen är:
process_idochtest_id– Refererar till den relaterade processen och testet.test_order– Ordinalnumret för det testet eller steget i processen. Tillsammans medprocess_id, detta bildar tabellens UNIKA nyckel. Vi kan bara ha ett steg i taget under processen.
test Tabellen listar alla test som för närvarande och tidigare använts i rekryteringsprocessen. Vi kommer även att behandla CV-granskningar och intervjuer som tester. Även om de inte behöver definierade frågor och svar är de en del av en utvärdering. För varje test lagrar vi:
test_name– En UNIK beteckning för varje test.test_type_id– Refererar tilltest_typeordbok.date_created– Datumet då vi skapade detta test i vårt system.max_score– Maxpoäng som kan uppnås för detta test. Detta värde är summan av alla korrekta svar på det här testet eller det högsta betyg som rekryterare kan ge på ett CV eller en intervju.max_duration– Hur lång tid (i minuter) den sökande har på sig att genomföra testet.test_link– Innehåller en länk till testplatsen. Detta värde kan vara NULL när vi inte använder ett test i processen.is_active– Anger om vi för närvarande använder detta test.
Vi har redan nämnt test_type lexikon. Den innehåller alla UNIKA testnamn efter format, t.ex. "CV-granskning" , "skillnadstest online" , "papperstest" och "intervju" .
Den här modellen inkluderar inte den struktur som behövs för att lagra testfrågor och svar. Snarare lagrar den en länk till de platser som innehåller denna information. Samma design kommer att användas i Applications ämnesområde.
Avsnitt 4:Applikationer
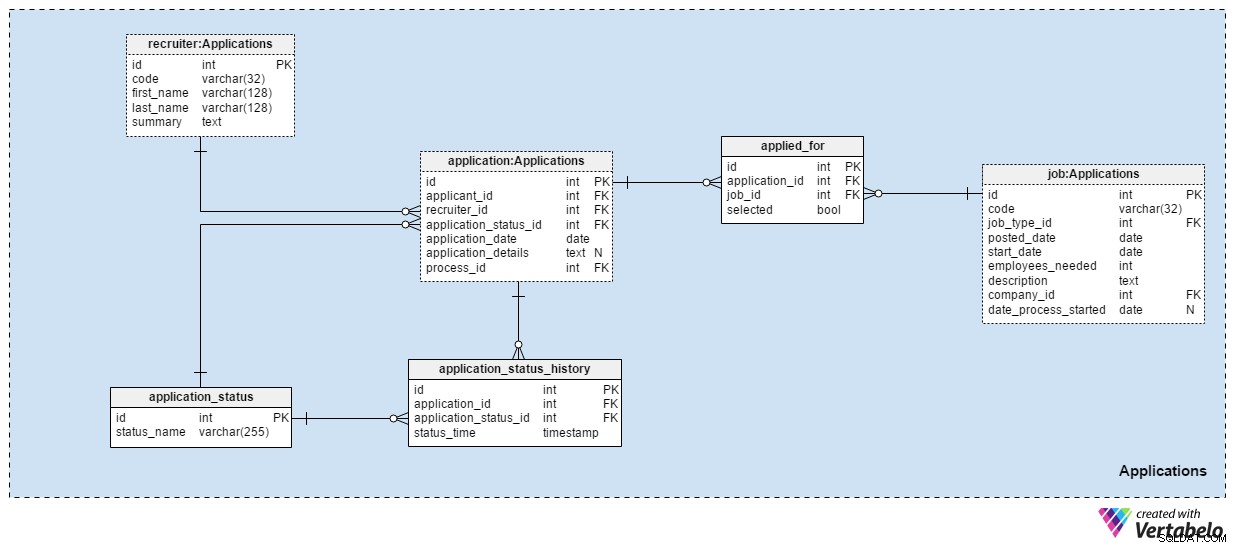
Applications ämnesområdet är förmodligen det viktigaste i denna datamodell. Alla andra ämnesområden som hittills nämnts beskrev applikationer. Den här lagrar de riktiga sakerna.
Varje ansökan vi någonsin har fått registreras i application tabell. För varje ansökan kommer vi att lagra relaterade sökandes ID, rekryterarnas ID och en referens till den aktuella statusen för den ansökan. Vi uppdaterar denna status samtidigt som vi gör en ny post i application_status_history tabell. application_date attribut används för att lagra det aktuella datumet, medan alla ytterligare detaljer lagras i textformat. process_id attribut lagrar en referens till den process som valts för den applikationen.
Ansökningar kommer att ändra status över tiden. En lista över alla applikationsstatusar lagras i application_status lexikon. Det enda attributet är status_name och den kan bara hålla UNIKA värden. Förväntade värden inkluderar:"applied" , "CV granskat" , "valt för testet" , "avvisad efter CV-granskning" , "godkände testet" , "inbjuden till en intervju" och "uppsagd av sökande" .
Vi lagrar alla ansökningsstatusar i application_status_history tabell. Den här tabellen innehåller referenser till application tabellen och application_status lexikon. Vi lagrar även den exakta status_time när denna status tilldelades applikationen. application_id – status_time paret bildar den UNIKA nyckeln för denna tabell.
I de flesta fall kommer en sökande endast att söka en tjänst med en ansökan. Det är möjligt att en sökande kommer att ansöka om mer än en tjänst och vi kommer att välja den mest lämpliga rollen för dem under urvalsprocessen. I applied_for tabell, lagrar vi det UNIKA paret application_id – job_id . Vi kommer också att registrera om den sökande som är relaterad till den ansökan selected för den positionen. Vi kan förvänta oss att alla selected värden kommer att ställas in på "False" i början av urvalsprocessen och att vi endast uppdaterar en per varje jobbposition till "True" .
Avsnitt 5:Applikationstester
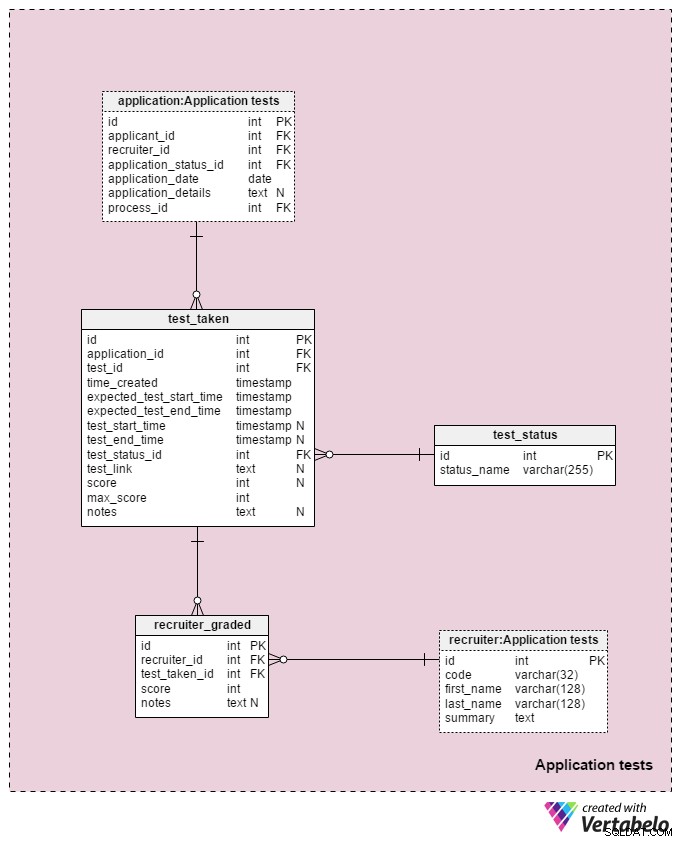
Det sista ämnesområdet i vår modell kommer att användas för att lagra resultaten av varje test som tas under urvalsprocessen. Två tabeller som används i detta ämnesområde är kopior från andra ämnesområden:application och recruiter . De används här för att förenkla modellen.
All information relaterade till varje test lagras i test_taken tabell. Den här tabellen innehåller också alla andra steg i processen som kan betygsättas, som en CV-granskning. Attributen i den här tabellen är:
application_id– Refererar tillapplicationtabell. Detta gäller ett test med den sökande som gjorde det.test_id– Refererar tilltestkatalog. Vi kan också referera tilltest_in_processtabell här, som skulle ge oss mer information om testet som tagits. Jag valde att inte göra det eftersom den här strukturen ger oss mer flexibilitet. (T.ex. om vi vill tillåta sökande att göra ett prov två gånger eller utanför vanliga tider).time_created– Den faktiska tiden då vi infogade detta test i vårt system.expected_test_start_timeochexpected_test_end_time– Start- och sluttider, som diskuterats med sökanden. Vi kan ändra dessa värden om den sökande eller rekryteraren behöver skjuta upp testet.test_start_timeochtest_end_time– De faktiska start- och sluttiderna för testet. Dessa kommer att innehålla NULL-värden när testet skapas; värden kommer att uppdateras när den sökande startar och avslutar detta test.test_status_id– Refererar tilltest_statusordbok.test_link– Länkar till provet med den sökandes svar. Den kommer att uppdateras när den sökande lämnar in provet.score– Den sökandes poäng på det provet. Detta bestäms antingen manuellt av en rekryterare (t.ex. för en CV-granskning) eller automatiskt (summan av alla testresultat). Det kan också innehålla ett NULL-värde för test som inte är poängsatta eller betygsatta på någon fördefinierad skala. Dessutom kan ett test som är schemalagt men ännu inte slutfört ha ett NULL-värde.max_score– Testets högsta möjliga poäng. Detta är samma som värdet som lagras itest.”max_scoreattribut. Jag vill behålla det värdet eftersom rekryteraren kan ändra testet medan det ges och därför ändra det maximala poängen som kan uppnås.notes– Eventuella ytterligare anteckningar eller kommentarer från rekryterare angående det specifika testet.
Kombinationen av test_id – application_id – expected_test_start_time attribut utgör den UNIKA nyckeln för denna tabell. Innan vi lägger till en ny testsession bör vi fortfarande kontrollera om det finns överlappande testintervall för den relaterade sökanden och alla relaterade rekryterare.
test_status ordboken innehåller en lista över alla UNIKA status_name som skulle kunna tilldelas ett test. Några förväntade värden inkluderar:"inte startat" , "pågår" , "slutfört framgångsrikt" , "slutfördes misslyckat" , "uppskjuten" , "avbruten" och "sökande annullerad" .
Den sista tabellen i vår modell är recruiter_graded tabell, som lagrar alla betyg som rekryterare gav vid betygsättningen av varje test. Därför lagrar vi referenser till recruiter och test_taken tabeller. Vi lagrar även score uppnått samt eventuella notes . Denna information är mycket viktig, särskilt när vi betygsätter tester manuellt (dvs. för CV-granskning och intervjuer).
Idag har vi diskuterat en datamodell som kan täcka nästan alla situationer i urvals- och rekryteringsprocessen – inklusive ovanliga undantag.
De flesta av oss har viss expertis inom detta ämne. Dela gärna med dig av dina erfarenheter när du var i rollen som rekryterare eller på andra sidan skrivbordet. Täcker den här modellen de situationer du ställts inför? Om inte, vilka ändringar skulle du föreslå?