Problem med replikeringsfördröjning i PostgreSQL är inte ett utbrett problem för de flesta inställningar. Även om det kan inträffa och när det händer kan det påverka dina produktionsinställningar. PostgreSQL är designat för att hantera flera trådar, såsom frågeparallellism eller distribuera arbetstrådar för att hantera specifika uppgifter baserat på de tilldelade värdena i konfigurationen. PostgreSQL är designat för att hantera tunga och stressiga belastningar, men ibland (på grund av en dålig konfiguration) kan din server fortfarande gå söderut.
Att identifiera replikeringsfördröjningen i PostgreSQL är inte en komplicerad uppgift, men det finns några olika metoder för att undersöka problemet. I den här bloggen tar vi en titt på vad du ska titta på när din PostgreSQL-replikering släpar efter.
Typer av replikering i PostgreSQL
Innan vi dyker in i ämnet, låt oss först se hur replikering i PostgreSQL utvecklas eftersom det finns en mängd olika tillvägagångssätt och lösningar när det gäller replikering.
Warm standby för PostgreSQL implementerades i version 8.2 (tillbaka 2006) och baserades på loggleveransmetoden. Detta innebär att WAL-posterna flyttas direkt från en databasserver till en annan för att användas, eller helt enkelt en analog inställning till PITR, eller mycket liknande vad du gör med rsync.
Detta tillvägagångssätt, även gammalt, används fortfarande idag och vissa institutioner föredrar faktiskt detta äldre tillvägagångssätt. Detta tillvägagångssätt implementerar en filbaserad loggsändning genom att överföra WAL-poster en fil (WAL-segment) åt gången. Även om det har en baksida; Ett stort fel på de primära servrarna, transaktioner som ännu inte har skickats kommer att gå förlorade. Det finns ett fönster för dataförlust (du kan ställa in detta genom att använda parametern archive_timeout, som kan ställas in på så lågt som några sekunder, men en så låg inställning kommer att avsevärt öka den bandbredd som krävs för filsändning).
I PostgreSQL version 9.0 introducerades Streaming Replication. Den här funktionen gjorde att vi kunde hålla oss mer uppdaterade jämfört med filbaserad loggsändning. Dess tillvägagångssätt är att överföra WAL-poster (en WAL-fil är sammansatt av WAL-poster) i farten (bara en postbaserad loggsändning), mellan en masterserver och en eller flera standbyservrar. Detta protokoll behöver inte vänta på att WAL-filen ska fyllas i, till skillnad från filbaserad loggsändning. I praktiken kommer en process som kallas WAL-mottagare, som körs på standby-servern, att ansluta till den primära servern med en TCP/IP-anslutning. På den primära servern finns en annan process som heter WAL-avsändaren. Dess roll är ansvarig för att skicka WAL-registren till standby-servrarna när de händer.
Asynkron replikeringsinställningar i strömmande replikering kan orsaka problem som dataförlust eller slavfördröjning, så version 9.1 introducerar synkron replikering. Vid synkron replikering kommer varje commit av en skrivtransaktion att vänta tills bekräftelse tas emot att commit har skrivits till skriv-framåtloggningsdisken på både den primära och standby-servern. Den här metoden minimerar risken för dataförlust, eftersom för att det ska hända måste både mastern och standby-enheten misslyckas samtidigt.
Den uppenbara nackdelen med denna konfiguration är att svarstiden för varje skrivtransaktion ökar, eftersom vi måste vänta tills alla parter har svarat. Till skillnad från MySQL finns det inget stöd, som i en semi-synkron miljö av MySQL, kommer den att failback till asynkron om timeout har inträffat. Så i With PostgreSQL är tiden för en commit (minst) tur och retur mellan primär och standby. Skrivskyddade transaktioner kommer inte att påverkas av det.
I takt med att PostgreSQL utvecklas förbättras kontinuerligt och ändå är dess replikering mångsidig. Du kan till exempel använda fysisk streaming asynkron replikering eller använda logisk streaming replikering. Båda övervakas olika men använder samma tillvägagångssätt när du skickar data över replikering, vilket fortfarande är strömmande replikering. För mer information kolla i manualen för olika typer av lösningar i PostgreSQL när du hanterar replikering.
Orsaker till PostgreSQL-replikeringsfördröjning
Som definierats i vår tidigare blogg är en replikeringsfördröjning kostnaden för fördröjning för transaktion(er) eller operation(er) beräknad av dess tidsskillnad för exekvering mellan primär/master mot standby/slav nod.
Eftersom PostgreSQL använder strömmande replikering är den utformad för att vara snabb eftersom ändringar registreras som en uppsättning sekvenser av loggposter (byte-för-byte) som fångas upp av WAL-mottagaren och sedan skriver dessa loggposter till WAL-filen. Sedan startar uppstartsprocessen av PostgreSQL upp data från det WAL-segmentet och strömmande replikering börjar. I PostgreSQL kan en replikeringsfördröjning uppstå av dessa faktorer:
- Nätverksproblem
- Kan inte hitta WAL-segmentet från det primära. Vanligtvis beror detta på kontrollbeteendet där WAL-segment roteras eller återvinns
- Upptagen noder (primära och standby(er)). Kan orsakas av externa processer eller vissa dåliga frågor som orsakas av att vara resurskrävande
- Dålig hårdvara eller hårdvaruproblem som gör att det tar en viss fördröjning
- Dålig konfiguration i PostgreSQL, t.ex. ett litet antal max_wal_sändare ställs in under behandling av massor av transaktionsförfrågningar (eller stora volymer ändringar).
Vad man ska leta efter med PostgreSQL-replikeringsfördröjning
PostgreSQL-replikering är ännu mångsidig men att övervaka replikeringens hälsa är subtil men inte komplicerad. I det här tillvägagångssättet kommer vi att visa upp är baserade på en primär standby-inställning med asynkron streamingreplikering. Den logiska replikeringen kan inte gynna de flesta av de fall vi diskuterar här men vyn pg_stat_subscription kan hjälpa dig att samla in information. Vi kommer dock inte att fokusera på det i den här bloggen.
Använda pg_stat_replication View
Det vanligaste tillvägagångssättet är att köra en fråga som refererar till denna vy i den primära noden. Kom ihåg att du bara kan hämta information från den primära noden med den här vyn. Denna vy innehåller följande tabelldefinition baserad på PostgreSQL 11 som visas nedan:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Där fälten definieras som (inkluderar PG <10 version),
- pid :Process-id för walsenderprocessen
- usesysid :OID för användare som används för strömmande replikering.
- användarnamn :Namn på användare som används för strömmande replikering
- application_name :Applikationsnamn kopplat till master
- client_addr :Adress till standby-/strömmande replikering
- client_hostname :Värdnamn för vänteläge.
- client_port :TCP-portnummer där standby kommunicerar med WAL-sändare
- backend_start :Starttid när SR anslutit till Master.
- backend_xmin :standbys xmin-horisont rapporterad av hot_standby_feedback.
- tillstånd :Aktuellt WAL-avsändarläge, dvs streaming
- sent_lsn /sent_location :Senaste transaktionsplatsen skickades till standby.
- write_lsn /write_location :Senaste transaktionen skrevs på disk i standby
- flush_lsn /flush_location :Senaste transaktionsspolning på disk i standby.
- replay_lsn /replay_location :Senaste transaktionsspolning på disk i standby.
- write_lag :Förfluten tid under engagerade WAL från primär till standby (men ännu inte inloggad i standby)
- flush_lag :Förfluten tid under genomförda WAL från primär till standby (WAL har redan tömts men ännu inte tillämpats)
- replay_lag :Förfluten tid under committed WALs från primär till standby (fullständigt committed i standby-nod)
- sync_priority :Prioritet för standby-server som väljs som synkron standby
- sync_state :Synkronisera standbyläge (är det asynkront eller synkront).
En exempelfråga skulle se ut så här i PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncDetta berättar i princip vilka platsblock i WAL-segmenten som har skrivits, tömts eller tillämpats. Det ger dig en detaljerad överblick över replikeringsstatusen.
Frågor att använda i standbynoden
I standby-noden finns det funktioner som stöds för vilka du kan mildra detta till en fråga och ge dig en översikt över statusen för din standby-replikering. För att göra detta kan du köra följande fråga nedan (frågan är baserad på PG-version> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00I äldre versioner kan du använda följande fråga:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Vad säger frågan? Funktioner definieras i enlighet härmed här,
- pg_is_in_recovery ():(boolean) Sant om återställningen fortfarande pågår.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Skriv-förut-loggplatsen togs emot och synkroniserades till disken genom strömmande replikering.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) Den senaste loggplatsen för att skriva framåt spelades om under återställning. Om återhämtningen fortfarande pågår kommer detta att öka monotont.
- pg_last_xact_replay_timestamp (): (tidsstämpel med tidszon) Få tidsstämpel för senaste transaktion som spelas om under återställning.
Genom att använda lite grundläggande matematik kan du kombinera dessa funktioner. Den vanligaste använda funktionen som används av DBA är,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
eller i versioner PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Även om denna fråga har varit i praktiken och används av DBA:s. Ändå ger det dig inte en exakt bild av eftersläpningen. Varför? Låt oss diskutera detta i nästa avsnitt.
Identifiera fördröjning orsakad av WAL-segmentets frånvaro
PostgreSQL standby-noder, som är i återställningsläge, rapporterar inte till dig det exakta tillståndet för vad som händer med din replikering. Om du inte tittar på PG-loggen kan du samla information om vad som händer. Det finns ingen fråga du kan köra för att fastställa detta. I de flesta fall kommer organisationer och till och med små institutioner med programvara från tredje part för att låta dem varnas när ett larm utlöses.
En av dessa är ClusterControl, som erbjuder dig observerbarhet, skickar varningar när larm utlöses eller återställer din nod i händelse av en katastrof eller katastrof. Låt oss ta det här scenariot, mitt primära standby-async streaming-replikeringskluster har misslyckats. Hur skulle du veta om något är fel? Låt oss kombinera följande:
Steg 1:Bestäm om det finns en fördröjning
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Steg 2:Bestäm WAL-segmenten som tas emot från den primära och jämför med Standby-noden
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70För äldre versioner av PG <10, använd pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Det verkar se dåligt ut.
Steg 3:Bestäm hur illa det kan vara
Låt oss nu blanda formeln från steg #1 och i steg #2 och få skillnaden. Hur man gör detta, PostgreSQL har en funktion som heter pg_wal_lsn_diff som definieras som,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (plats pg_lsn, plats pg_lsn): (numerisk) Beräkna skillnaden mellan två loggplatser för att skriva framåt
Låt oss nu använda den för att bestämma eftersläpningen. Du kan köra det i vilken PG-nod som helst, eftersom det är vi bara tillhandahåller de statiska värdena:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Låt oss uppskatta hur mycket som är 1800913104, det verkar vara ungefär 1,6GiB som kan ha saknats i standbynoden,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Sistligen kan du fortsätta eller till och med före frågan titta på loggarna som att använda tail -5f för att följa och kontrollera vad som händer. Gör detta för båda primära/standbynoder. I det här exemplet ser vi att det har ett problem,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...När du stöter på det här problemet är det bättre att bygga om dina standbynoder. I ClusterControl är det enkelt som ett klick. Gå bara till avsnittet Noder/Topologi och bygg om noden precis som nedan:
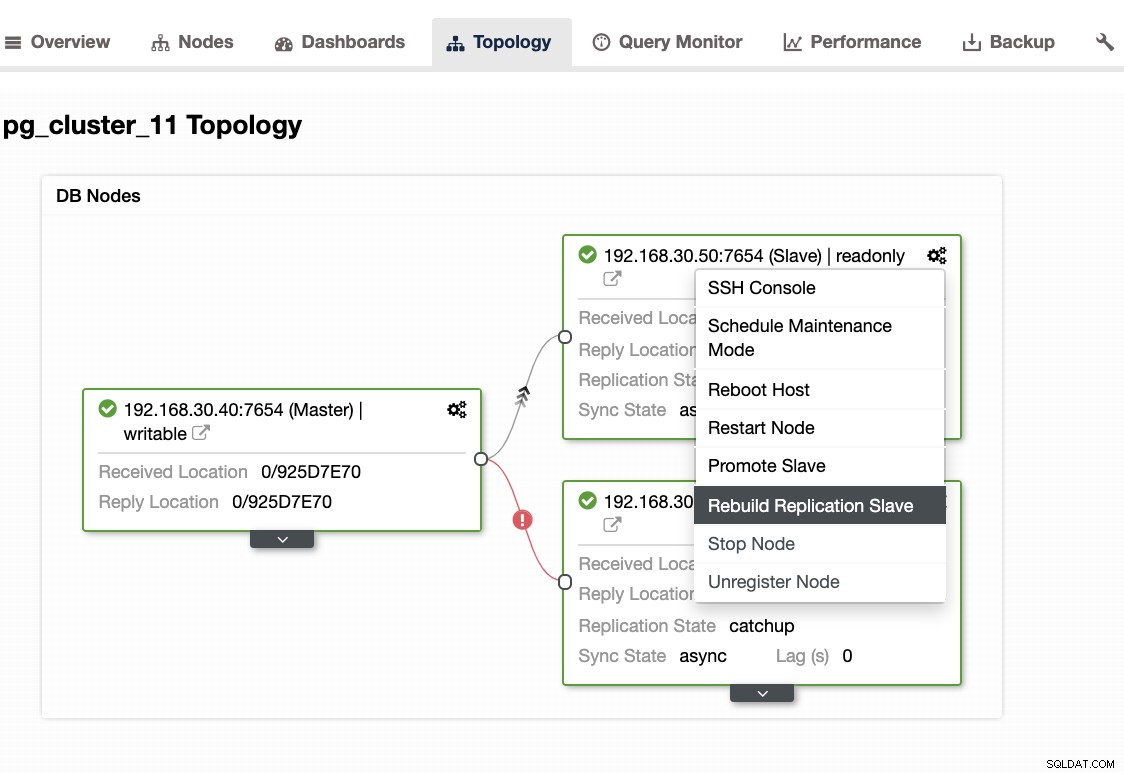
Andra saker att kontrollera
Du kan använda samma tillvägagångssätt i vår tidigare blogg (i MySQL), med hjälp av systemverktyg som ps, top, iostat, netstat-kombination. Till exempel kan du också hämta det aktuella återställda WAL-segmentet från standbynoden,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Hur kan ClusterControl hjälpa?
ClusterControl erbjuder ett effektivt sätt att övervaka dina databasnoder från primära till slavnoder. När du går till fliken Översikt har du redan en vy över din replikeringstillstånd:
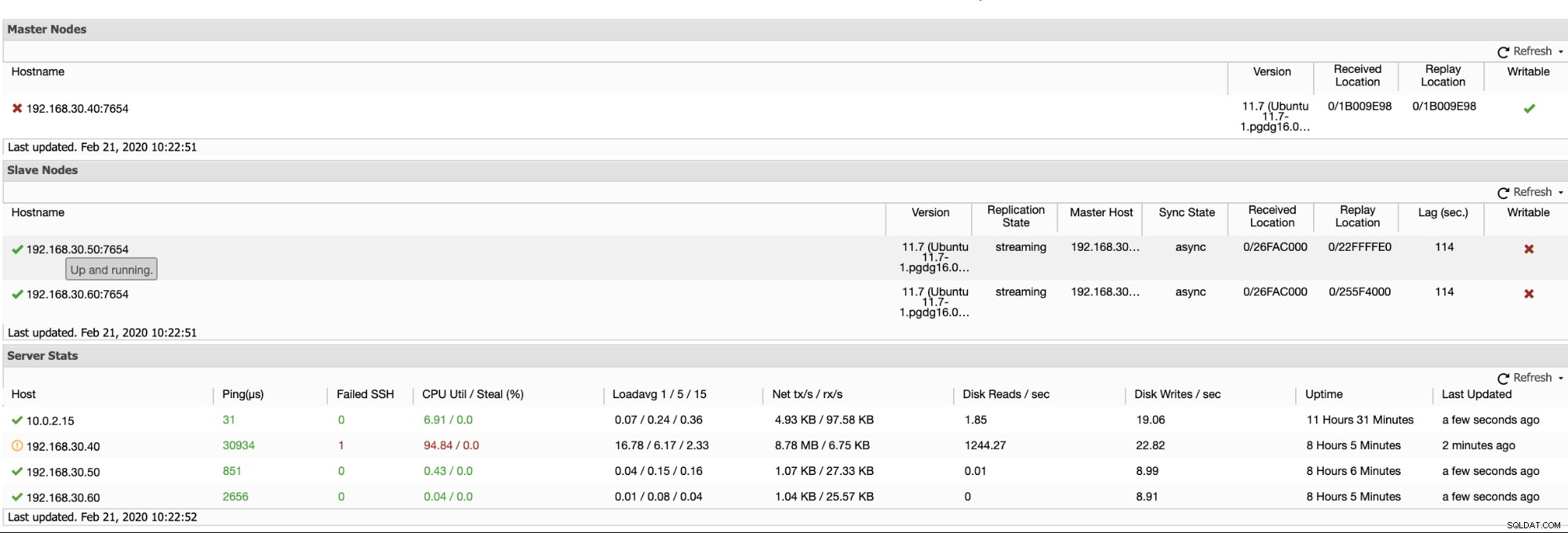
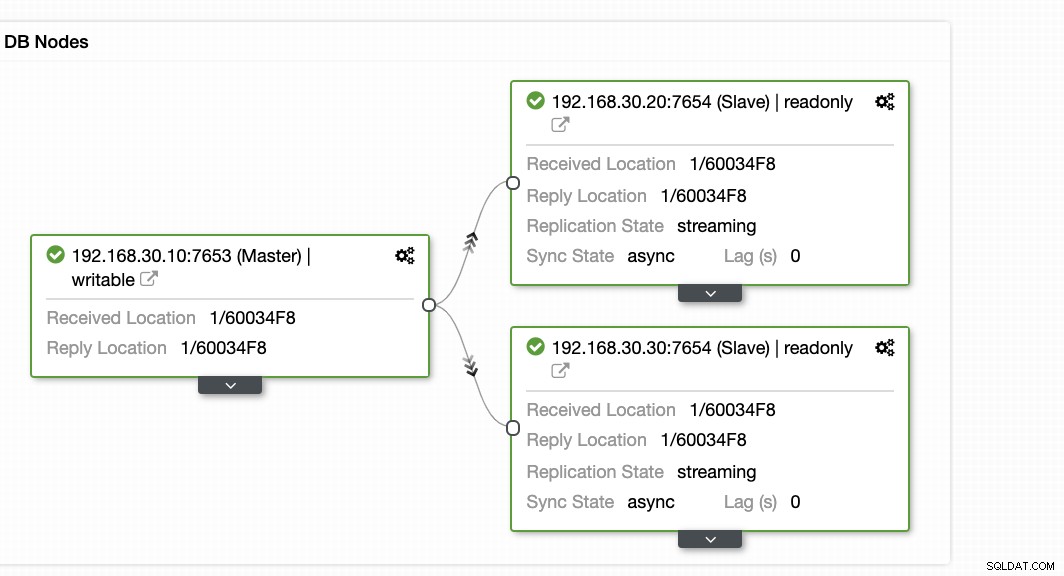
I grund och botten visar de två skärmdumparna ovan hur replikeringen är och vad som är aktuellt WAL-segment. Det är det inte alls. ClusterControl visar också den aktuella aktiviteten för vad som händer med ditt kluster.
Slutsats
Övervakning av replikeringshälsan i PostgreSQL kan sluta på ett annat tillvägagångssätt så länge du kan möta dina behov. Att använda tredjepartsverktyg med observerbarhet som kan meddela dig i händelse av en katastrof är din perfekta väg, oavsett om det är en öppen källkod eller ett företag. Det viktigaste är att du har planerat din katastrofåterställningsplan och affärskontinuitet före sådana problem.