SQL Server 2014 SP2 och senare producerar körtid (”faktiska”) exekveringsplaner som kan inkludera förfluten tid och CPU-användning för varje utförandeplanoperatör (se KB3170113 och detta blogginlägg av Pedro Lopes).
Att tolka dessa siffror är inte alltid så enkelt som man kan förvänta sig. Det finns viktiga skillnader mellan radläge och batchläge exekvering, samt knepiga problem med radläge parallellism . SQL Server gör några timingsjusteringar parallella planer för att främja konsekvens, men de genomförs inte perfekt. Detta kan göra det svårt att dra slutsatser av bra prestanda.
Den här artikeln syftar till att hjälpa dig förstå var tidpunkterna kommer ifrån i varje enskilt fall och hur de bäst kan tolkas i sitt sammanhang.
Inställningar
Följande exempel använder den offentliga Stack Overflow 2013 databas (nedladdningsinformation), med ett enda index tillagt:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Testfrågorna returnerar antalet frågor med ett accepterat svar, grupperade efter månad och år. De körs på SQL Server 2019 CU9 , på en bärbar dator med 8 kärnor och 16 GB minne tilldelat till SQL Server 2019-instansen. Kompatibilitetsnivå 150 används uteslutande.
Serialexekvering i batchläge
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Utförandeplanen är (klicka för att förstora):
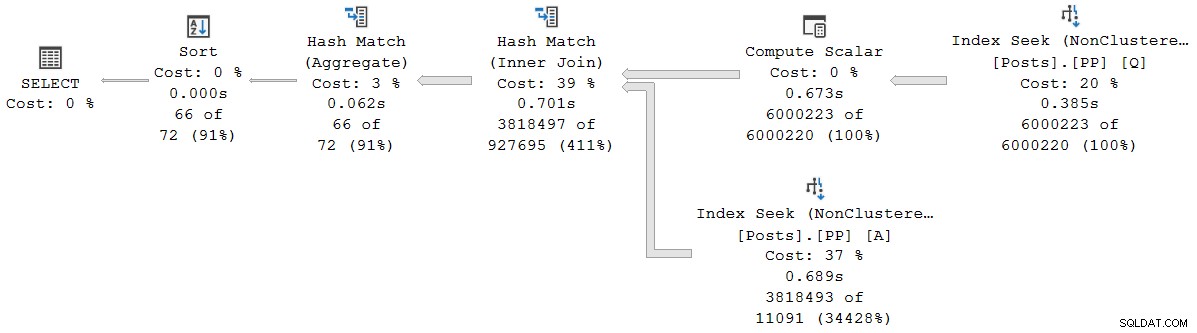
Varje operatör i den här planen körs i batchläge, tack vare batchläget på rowstore Funktionen Intelligent Query Processing i SQL Server 2019 (inget columnstore-index behövs). Frågan körs i 2 523 ms med 2 522 ms CPU-tid som används, när all data som behövs redan finns i buffertpoolen.
Som Pedro Lopes noterar i blogginlägget som länkades tidigare, rapporterade förfluten tid och CPU-tider för individuellt batchläge operatorer representerar den tid som används av den operatör ensam .
SSMS visar förfluten tid i den grafiska representationen. För att se CPU-tiderna , välj en planoperatör och titta sedan i Egenskaper fönster. Den här detaljerade vyn visar både förfluten tid och CPU-tid, per operatör och per tråd.
Showplan-tiderna (inklusive XML-representationen) är avkortade till millisekunder. Om du behöver större precision, använd query_thread_profile utökad händelse, som rapporteras på mikrosekunder . Utdata från denna händelse för exekveringsplanen som visas ovan är:
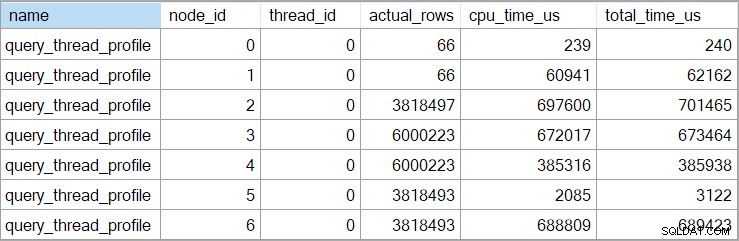
Detta visar förfluten tid för sammanfogningen (nod 2) är 701 465 µs (avkortat till 701 ms i showplan). Aggregatet har en förfluten tid på 62 162 µs (62 ms). "Frågor"-indexsökningen visas som igång i 385 ms, medan den utökade händelsen visar att den sanna siffran för nod 4 var 385 938 µs (mycket nästan 386 ms).
SQL Server använder högprecision QueryPerformanceCounter API för att fånga tidsdata. Detta använder hårdvara, vanligtvis en kristalloscillator, som producerar fästingar med en mycket hög konstant hastighet oavsett processorhastighet, effektinställningar eller något sådant. Klockan fortsätter att gå i samma takt även under sömnen. Se den länkade mycket detaljerade artikeln om du är intresserad av alla de finare detaljerna. Den korta sammanfattningen är att du kan lita på att mikrosekundstalen är korrekta.
I denna rena batchmodeplan är den totala exekveringstiden mycket nära summan av de individuella operatörernas förflutna tider. Skillnaden beror till stor del på arbete efter uttalande som inte är kopplat till planoperatörer (som alla har stängts då), även om millisekundstympningen också spelar en roll.
I rena batchlägesplaner måste du manuellt summera aktuella och underordnade operatörstider för att få den kumulativa förfluten tid vid en given nod.
Parallell exekvering i batchläge
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Utförandeplanen är:
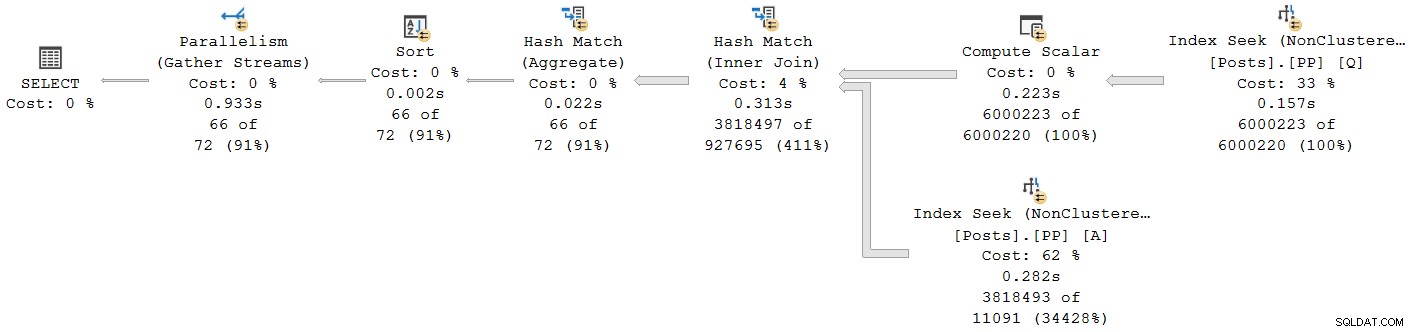
Alla operatörer utom det slutliga insamlingsströmutbytet körs i batchläge. Totalt förfluten tid är 933ms med 6 673 ms CPU-tid med en varm cache.
Välja hash-join och titta i SSMS Egenskaper fönster, ser vi förfluten tid och CPU-tid per tråd för den operatören:
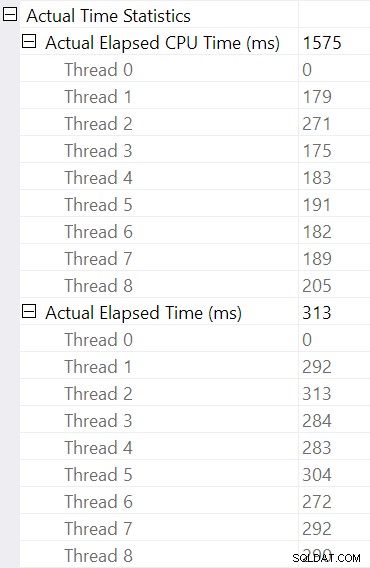
CPU-tiden som rapporterats för operatören är summan av de individuella trådens CPU-tider. Den rapporterade operatören förfluten tid är maximum av de förflutna tiderna per tråd. Båda beräkningarna utförs över de trunkerade millisekundvärdena per tråd. Som tidigare är den totala exekveringstiden mycket nära summan av individuella operatörers förflutna tider.
Parallella planer för batchläge använder inte utbyten för att fördela arbete mellan trådar. Batch-operatorer är implementerade så att flera trådar kan arbeta effektivt på en enda delad struktur (t.ex. hashtabell). Viss synkronisering mellan trådar krävs fortfarande i batch-läges parallella planer, men synkroniseringspunkter och andra detaljer är inte synliga i showplan-utdata.
Radläge seriell exekvering
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Utförandeplanen är visuellt densamma som serieplanen för batchläge, men varje operatör körs nu i radläge:
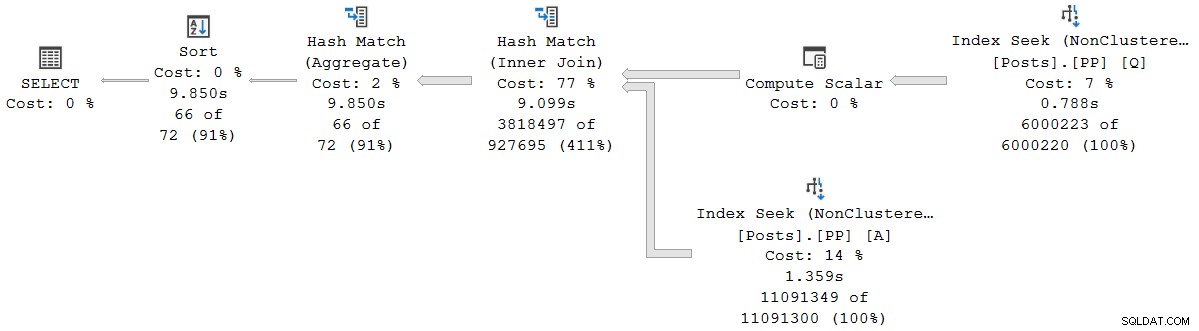
Frågan körs i 9 850 ms med 9 845 ms CPU-tid. Detta är mycket långsammare än frågan i seriell batchläge (2523ms/2522ms), som förväntat. Ännu viktigare för den aktuella diskussionen, radläget operatörens förflutna och CPU-tiderna representerar den tid som används av den nuvarande operatören och alla dess underordnade .
Den utökade händelsen visar också kumulativ CPU och förfluten tid vid varje nod (i mikrosekunder):
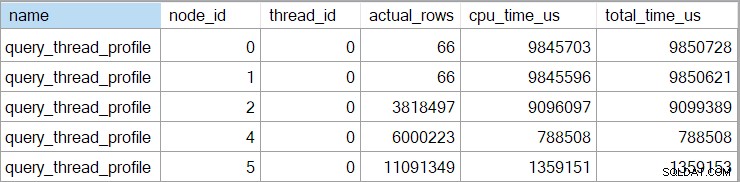
Det finns inga data för den skalära beräkningsoperatorn (nod 3) eftersom exekvering av radläge kan skjuta upp de flesta uttrycksberäkningar till operatorn som förbrukar resultatet. Detta är för närvarande inte implementerat för körning i batchläge.
Den rapporterade kumulativa förfluten tid för radlägesoperatorer betyder att tiden som visas för den sista sorteringsoperatorn stämmer överens med den totala exekveringstiden för frågan (i alla fall till millisekunders upplösning). Den förflutna tiden för hash-anslutningen inkluderar också bidrag från de två indexsöken under den, såväl som dess egen tid. För att beräkna förfluten tid för enbart radlägets hash-join, skulle vi behöva subtrahera båda söktiderna från den.
Det finns fördelar och nackdelar med båda presentationerna (kumulativt för radläge, individuell operatör endast för batchläge). Vad du än föredrar är det viktigt att vara medveten om skillnaderna.
Planer för blandat körningsläge
I allmänhet kan moderna utförandeplaner innehålla valfri blandning av radläges- och batchlägesoperatörer. Batchlägesoperatörerna kommer att rapportera tider bara för sig själva. Radlägesoperatorerna kommer att inkludera en kumulativ summa fram till den punkten i planen, inklusive alla barnoperatörer. För att vara tydlig med det:en radlägesoperatörs kumulativa tider inkluderar alla underordnade operatörer i batchläge.
Vi såg detta tidigare i planen för parallellt batchläge:Operatören för den sista (radläge) samla strömmar hade en visad (ackumulerad) förfluten tid på 0,933s — inklusive alla dess underordnade batchlägesoperatorer. De andra operatörerna var alla i batch-läge och rapporterade därför tider enbart för den enskilda operatören.
Denna situation, där vissa planoperatörer i samma plan har kumulativa tider och andra inte, kommer utan tvekan att betraktas som förvirrande av många människor.
Parallell exekvering av radläge
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Utförandeplanen är:

Varje operatör är radläge. Frågan körs i 4 677 ms med 23 311 ms CPU-tid (summan av alla trådar).
Som en exklusivt radlägesplan förväntar vi oss att alla tider är kumulativa . När man går från barn till förälder (höger till vänster), borde tiderna öka i den riktningen.
Låt oss titta på bara den högra delen av planen:
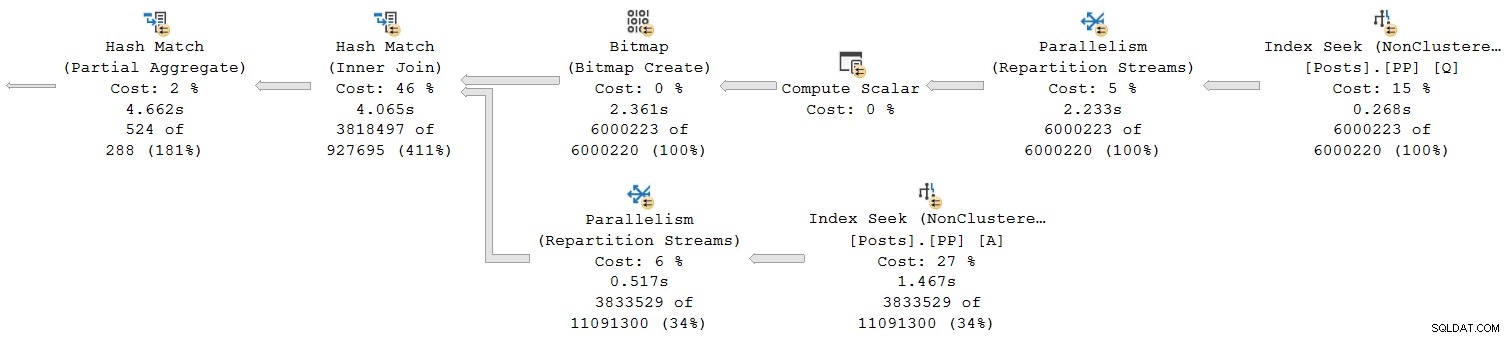
Arbetar man från höger till vänster på den översta raden, verkar kumulativa tider verkligen vara fallet. Men det finns ett undantag på den nedre ingången till hash-join:Indexsökningen har en förfluten tid på 1,467s , medan dess förälder ompartitionsströmmar har en förfluten tid på endast 0,517s .
Hur kan en förälder operatören körs kortare tid än dess barn om förflutna tider är kumulativa i radlägesplaner?
Inkonsekventa tider
Det finns flera delar till svaret på detta pussel. Låt oss ta det bit för bit, för det är ganska komplicerat:
Kom först ihåg att ett utbyte (parallellismoperatör) har två delar. Vänster hand (konsument ) sida är ansluten till en uppsättning trådar som löper operatörer i den parallella grenen till vänster. Höger hand (producent ) sidan av växeln är ansluten till en annan uppsättning trådar som kör operatörer i den parallella grenen till höger.
Rader från producentsidan sätts samman till paket och överförs sedan till konsumentsidan. Detta ger en viss grad av buffring och flödeskontroll mellan de två uppsättningarna av anslutna trådar. (Om du behöver en uppfräschning om utbyten och parallella plangrenar, se min artikel Parallella exekveringsplaner – grenar och trådar.)
Omfattningen av kumulativa tider
Tittar på parallellgrenen på producenten sidan av utbytet:
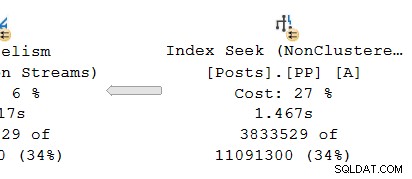
Som vanligt kör DOP (grad av parallellism) ytterligare arbetartrådar en oberoende serie kopia av planoperatörerna i denna gren. Så vid DOP 8 finns det 8 oberoende seriella indexsökningar som samarbetar för att utföra avståndsavsökningsdelen av den övergripande (parallella) indexsökningsoperationen. Varje enkeltrådad sökning är ansluten till en annan ingång (port) på producentsidan av den single shared växlingsoperatör.
En liknande situation finns för konsumenten sidan av utbytet. På DOP 8 finns det 8 separata enkeltrådade kopior av denna gren som alla körs oberoende:
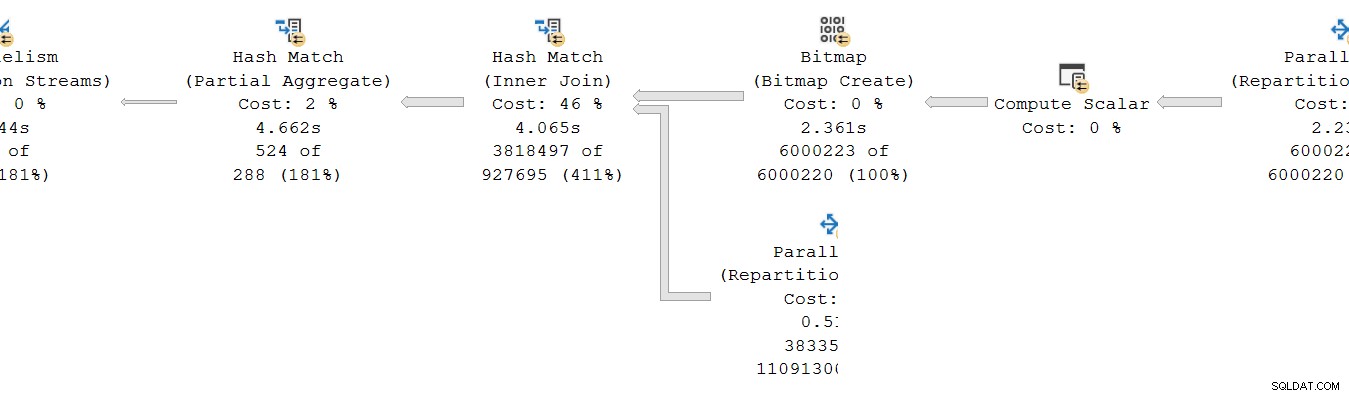
Var och en av dessa enkeltrådade underplaner körs på vanligt sätt, där varje operatör ackumulerar förfluten tid och CPU-tidsummor vid varje nod. Eftersom det är radlägesoperatorer representerar varje total tid spenderad den kumulativa summan för den aktuella noden och var och en av dess underordnade.
Den avgörande punkten är att de ackumulerade summorna inkludera endast operatorer i samma tråd och endast inom den nuvarande grenen . Förhoppningsvis är detta intuitivt vettigt, eftersom varje tråd har ingen aning om vad som kan hända någon annanstans.
Hur radlägesstatistik samlas in
Den andra delen av pusslet handlar om hur radantal och tidsmätningar samlas in i radlägesplaner. När information om körtid (”faktisk”) plan krävs lägger exekveringsmotorn till en osynlig profileringsoperatör till omedelbart vänster (förälder) för varje operatör i planen som kommer att köras under körning.
Denna operatör kan registrera (bland annat) skillnaden mellan tidpunkten då den överlämnade kontrollen till sin underordnade operatör och tidpunkten då kontrollen återlämnades. Denna tidsskillnad representerar den förflutna tiden för den övervakade operatören och alla dess barn , eftersom barnet ropar in sitt eget barn per rad och så vidare. En operatör kan anropas många gånger (för att initiera, sedan en gång per rad, slutligen för att stänga) så tiden som samlas in av profileringsoperatören är en ackumulering över potentiellt många iterationer per rad.
För mer information om profileringsdata samlas in med olika fångstmetoder, se produktdokumentationen som täcker Query Profiling Infrastructure. För de som är intresserade av sådana saker är namnet på den osynliga profileringsoperatören som används av standardinfrastrukturen sqlmin!CQScanProfileNew . Liksom alla radlägesiteratorer har den Open , GetRow och Close metoder, bland annat. Varje metod innehåller anrop till Windows QueryPerformanceCounter API för att samla in det aktuella timervärdet med hög upplösning.
Eftersom profileringsoperatören är till vänster för måloperatören mäter den bara konsumenten sidan av utbytet. Det finns ingen profileringsoperatör för producenten sidan av utbytet (tråkigt nog). Om det fanns skulle det matcha eller överskrida den förflutna tiden som visas på indexsökningen, eftersom indexsökningen och producentsidan kör samma uppsättning trådar och producentsidan av börsen är moderoperatören för indexsökningen.
Timing återbesökt

Med allt detta sagt, kan du fortfarande ha problem med tiderna som visas ovan. Hur kan en indexsökning ta 1,467s för att skicka rader till producentsidan av en börs, men konsumentsidan tar bara 0,517s att ta emot dem? Oavsett separata trådar, buffring och annat, säkert bör utbytet löpa (end-to-end) längre än sökningen gör?
Jo, det gör det, men det är ett annat mått från förfluten tid eller CPU-tid. Låt oss vara exakta om vad vi mäter här.
För radläge förfluten tid , föreställ dig ett stoppur per tråd hos varje operatör. Stoppuret startar när SQL Server anger koden för en operatör från sin överordnade och stoppar (men återställs inte) när den koden lämnar operatören för att återföra kontrollen tillbaka till föräldern (inte till ett barn). Förfluten tid inkluderar eventuella väntetider eller schemaläggningsförseningar – ingen av dem stoppar klockan.
För radläge CPU-tid , föreställ dig samma stoppur med samma egenskaper, förutom att det stannar under väntan och schemaläggningsförseningar. Den ackumulerar bara tid när operatören eller ett av dess barn aktivt kör på en schemaläggare (CPU). Den totala tiden på ett stoppur per tråd per operatör är uppbyggt av en start-stopp-cykel för varje rad.
Låt oss tillämpa det på den nuvarande situationen med konsumentsidan av börsen och indexsöket:
Kom ihåg att konsumentsidan av börsen och indexsökningen finns i separata grenar, så de körs på separata trådar . Konsumentsidan har inga barn i samma tråd. Indexsökningen har producentsidan av börsen som samma tråd, men vi har inget stoppur där.
Varje konsumenttråd startar sin klocka när dess överordnade operatör (sondsidan av hash-kopplingen) passerar kontrollen (t.ex. för att hämta en rad). Klockan fortsätter att gå medan konsumenten hämtar en rad från det aktuella utbytespaketet. Klockan stoppar när kontrollen lämnar konsumenten och återvänder till hash join-probsidan. Ytterligare föräldrar (det partiella aggregatet och dess överordnade utbyte) kommer också att arbeta på den raden (och kan vänta) innan kontrollen återgår till konsumentsidan av vår börs för att hämta nästa rad. Vid den tidpunkten börjar konsumentsidan av vårt utbyte att ackumulera förfluten tid och CPU-tid igen.
Under tiden, oberoende av vad konsumenttrådarna än gör, indexsökningen trådar fortsätter att lokalisera rader i indexet och mata in dem i börsen. En indexsökningstråd startar sitt stoppur när producentsidan av börsen ber den om en rad. Stoppuret pausas när raden skickas till växeln. När börsen frågar efter nästa rad, återupptas indexsökningens stoppur.
Observera att producentsidan av utbytet kan uppleva CXPACKET väntar medan utbytesbuffertarna fylls upp, men det kommer inte att läggas till de förflutna tiderna som registrerats vid indexsökningen eftersom dess stoppur inte går när det händer. Om vi hade ett stoppur för producentsidan av börsen, skulle den saknade tiden dyka upp där.
För att approximera en sammanfattning av situationen visuellt visar följande diagram när varje operatör ackumulerar förfluten tid i de två parallella grenarna:
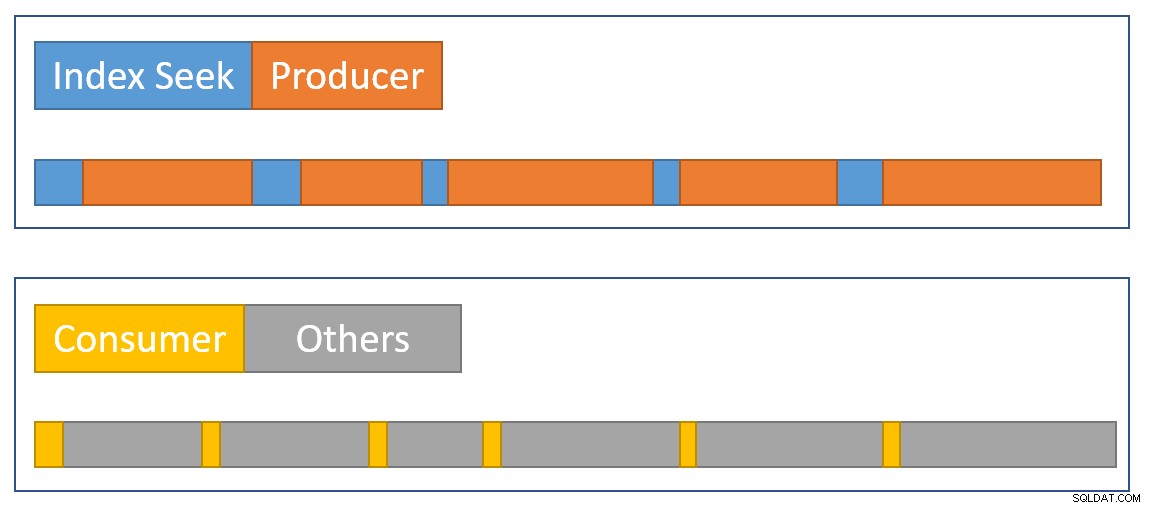
Den blå indexsöktidsstaplarna är korta eftersom det går snabbt att hämta en rad från ett index. apelsinen producenttiden kan vara lång på grund av CXPACKET väntar. Den gula konsumenttiderna är korta eftersom det går snabbt att hämta en rad från börsen när data finns tillgänglig. Den grå tidssegment representerar tid som används av de andra operatörerna (hash join-sondsida, partiell aggregat och dess moderbörsproducentsida) ovanför konsumentsidan av börsen.
Vi förväntar oss att utbytespaketen fylls snabbt av indexsökningen, men töms långsamt (relativt sett) av operatörerna på konsumentsidan eftersom de har mer att göra. Detta innebär att paket i utbytet vanligtvis är fulla eller nästan fulla. Konsumenten kommer att kunna hämta en väntande rad snabbt, men producenten kan behöva vänta på att paketutrymme ska dyka upp.
Det är synd att vi inte kan se förfluten tid hos producentsidan av börsen. Jag har länge varit av uppfattningen att ett utbyte bör representeras av två olika operatörer i genomförandeplaner. Det skulle göra CXPACKET svårt /CXCONSUMER vänta analys mycket mindre nödvändig, och utförandeplaner mycket lättare att förstå. Börsproducentens operatör skulle naturligtvis få en egen profileringsoperatör.
Alternativa mönster
Det finns många sätt som SQL Server kan uppnå konsekvent kumulativ förfluten och CPU-tid över parallella grenar i princip . Istället för att profilera operatörer kunde varje rad innehålla information om hur mycket som förflutit och CPU-tid den hade samlat på sig hittills på sin resa genom planen. Med historik kopplad till varje rad skulle det inte spela någon roll hur utbyten omfördelar rader mellan trådar och så vidare.
Det är inte så produkten har designats, så det är inte vad vi har (och det kan vara ineffektivt ändå). För att vara rättvis handlade den ursprungliga designen av radläge endast om saker som att samla in faktiska radantal och antalet iterationer hos varje operatör. Att lägga till förfluten tid per operatör till planerna var en mycket efterfrågad funktion , men det var inte lätt att införliva i det befintliga ramverket.
När bearbetning i batchläge lades till produkten, kunde ett annat tillvägagångssätt (enbart för den nuvarande operatören) implementeras som en del av den ursprungliga utvecklingen utan att bryta något. Återigen, i princip , radlägesoperatörer kunde ha modifierats för att fungera på samma sätt som batchlägesoperatörer, men det skulle ha krävt en hel del arbete med att omkonstruera varje befintlig radlägesoperatör. Det var mycket enklare att lägga till en ny datapunkt till de befintliga profileringsoperatörerna för radläge. Med tanke på begränsade tekniska resurser och en lång lista med önskade produktförbättringar måste kompromisser som denna ofta göras.
Det andra problemet
En annan kumulativ tidsinkonsekvens förekommer i den nuvarande planen på vänster sida:

Vid första anblicken verkar detta vara samma problem:Det partiella aggregatet har en förfluten tid på 4,662s , men utbytet ovanför körs bara i 2.844s . Samma grundmekanik som tidigare är naturligtvis i spel, men det finns en annan viktig faktor. En ledtråd ligger i de misstänkt lika tider som rapporterats för strömmen aggregering, sortering och ompartitionering.
Kommer du ihåg "tidsjusteringarna" jag nämnde i inledningen? Det är här de kommer in. Låt oss titta på de individuella förflutna tiderna för trådar på konsumentsidan av utbytet av ompartitionsströmmar:
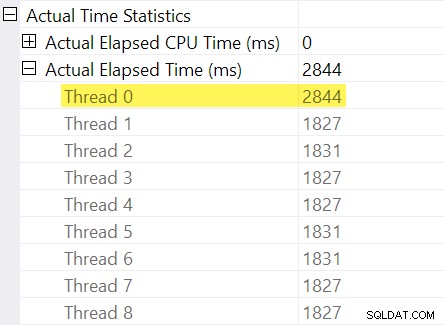
Kom ihåg att planerna visar den förflutna tiden för en parallelloperatör som maximum av gångerna per tråd. Alla 8 trådar hade en förfluten tid runt 1 830 ms men det finns en extra post för "Tråd 0" med 2 844 ms. Verkligen alla operatörer i denna parallella gren (börskonsumenten, sorteringen och strömaggregatet) har samma 2 844 ms bidrag från "Tråd 0".
Tråd noll (alias föräldrauppgift eller koordinator) kör bara operatörer direkt till vänster om den slutliga samlaströmsoperatören. Varför tilldelas det arbete här, i en parallell gren?
Förklaring
Det här problemet kan uppstå när det finns en blockerande operatör i parallellgrenen nedan (till höger om) den nuvarande. Utan denna justering skulle operatörer i den nuvarande grenen underrapportera förfluten tid med den tid som behövs för att öppna den underordnade grenen (det finns komplicerade arkitektoniska skäl för detta).
SQL Server ser till att ta hänsyn till detta genom att registrera underordnad grenfördröjning vid växeln i den osynliga profileringsoperatören. Tidsvärdet registreras mot förälderuppgiften ("Tråd 0") i skillnaden mellan dess första aktiva och senast aktiva gånger. (Det kan tyckas konstigt att registrera numret på det här sättet, men vid den tidpunkt då numret behöver registreras har de ytterligare parallella arbetartrådarna inte skapats ännu).
I det aktuella fallet är 2 844 ms-justeringen uppstår främst på grund av den tid det tar för hash-join att bygga sin hashtabell. (Observera att den här tiden skiljer sig från totalt exekveringstid för hash-join, vilket inkluderar den tid det tar att bearbeta probesidan av joinen).
Behovet av en justering uppstår eftersom en hash-join blockerar sin build-ingång. (Intressant nog är hashen partiellt aggregat i planen anses inte blockera i det här sammanhanget eftersom den bara är tilldelad en minimal mängd minne, spills aldrig till tempdb , och slutar helt enkelt aggregeras om det tar slut på minne (och återgår därigenom till ett streamingläge). Craig Freedman förklarar detta i sitt inlägg, Partial Aggregation).
Med tanke på att justeringen av förfluten tid representerar en initialiseringsfördröjning i den underordnade grenen, borde SQL Server för att behandla "Tråd 0"-värdet som en offset för de uppmätta siffrorna för förfluten tid per tråd inom den aktuella grenen. Med maximum av alla trådar eftersom den förflutna tiden är rimlig i allmänhet, eftersom trådar tenderar att starta samtidigt. Det gör det inte vettigt att göra detta när ett av trådvärdena är en offset för alla andra värden!
Vi kan göra korrekt offsetberäkning manuellt med hjälp av den information som finns tillgänglig i planen. På konsumentsidan av börsen har vi:
Den maximala förflutna tiden bland de ytterligare arbetartrådarna är 1 831 ms (exklusive offsetvärdet lagrat i "Tråd 0"). Lägger till offset på 2 844 ms ger totalt 4 675 ms .
I alla planer där tiderna per tråd är mindre än offset, kommer operatören att felaktigt visa offset som den totala förflutna tiden. Detta kommer sannolikt att inträffa när den tidigare blockeringsoperatören är långsam (kanske en sorts eller global sammanställning över en stor uppsättning data) och de senare filialoperatörerna är mindre tidskrävande.
Återbesök den här delen av planen:
Ersätter den 2 844 ms offset som felaktigt tilldelats ompartitionsströmmarna, sorterings- och strömaggregatoperatorerna med våra beräknade 4 675 ms värde placerar deras kumulativa förflutna tider prydligt mellan 4 662 ms vid det partiella aggregatet och 4 676 ms vid de sista samla strömmar. (Sorteringen och aggregatet fungerar på ett litet antal rader så deras förflutna tidsberäkningar kommer ut på samma sätt som sorteringen, men i allmänhet skulle de ofta vara olika):

Alla operatörer i planfragmentet ovan har 0 ms förfluten CPU-tid över alla trådar (bortsett från det partiella aggregatet, som har 14 891 ms). Planen med våra beräknade siffror är därför mycket mer vettig än den som visas:
- 4 675 ms – 4 662 ms =13 ms förflutit är ett mycket mer rimligt tal för den tid som förbrukas av ompartitionsströmmarna ensamma . Den här operatören förbrukar ingen CPU-tid och bearbetar bara 524 rader.
- 0ms förflutit (till millisekundsupplösning) är rimligt för den lilla sorteringen och strömmen (återigen, exklusive deras barn).
- 4 676 ms – 4 675 ms =1 ms verkar bra för de sista insamlingsströmmarna att samla in 66 rader på den överordnade uppgiftstråden för återgång till klienten.
Bortsett från den uppenbara inkonsekvensen i den givna planen mellan de partiella sammanlagda (4 662 ms) och uppdelningsströmmarna (2 844 ms), är det orimligt att tro att de slutliga insamlingsströmmarna på 66 rader kan vara ansvariga för 4 676 ms – 2 844 ms = 1 832 ms av förfluten tid. Det korrigerade antalet (1ms) är mycket mer exakt och kommer inte att vilseleda frågemottagare.
Nu, även om denna förskjutningsberäkning utfördes korrekt, kanske planer för parallellradsläge inte visa konsekventa kumulativa tider i alla fall, av de skäl som diskuterats tidigare. Att uppnå fullständig konsekvens kan vara svårt, eller till och med omöjligt utan stora arkitektoniska förändringar.
För att förutse en fråga som kan uppstå vid denna tidpunkt:Nej, den tidigare analysen av utbyte och indexsökning innebar inte ett "Tråd 0"-offsetberäkningsfel. Det finns ingen blockerande operatör under den växeln, så ingen initialiseringsfördröjning uppstår.
Ett sista exempel
Nästa exempelfråga använder samma databas och index som tidigare. Jag kommer inte att utforska det för mycket i detalj eftersom det bara tjänar till att utvidga punkter jag redan har gjort, för den intresserade läsaren.
Funktionerna i denna demo är:
- Utan en
ORDER GROUPledtråd, det visar hur ett partiellt aggregat inte anses vara en blockerande operatör, så ingen "Tråd 0"-justering uppstår vid utbytet av ompartitionsströmmar. De förflutna tiderna är konsekventa. - Med ledtråden introduceras blockeringssorter istället för en partiell hashaggregat. Två olika "Tråd 0"-justeringar visas vid de två ompartitioneringsväxlarna. Förfluten tid är inkonsekvent på båda grenarna, på olika sätt.
Fråga:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Utförandeplan utan ORDER GROUP (ingen justering, konsekventa tider):

Utförandeplan med ORDER GROUP (två olika justeringar, inkonsekventa tider):

Summary and conclusions
Row mode plan operators report cumulative times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.