Integrerad transport är något vi ofta hör om på internet eller i nyheterna. Även om det inte är något nytt, är det definitivt en pågående process, med ständiga förändringar som implementeras. Idag ska vi ta en titt på en datamodell som kan hantera zon-, passagerar- och biljettinformation.
Låt oss gräva direkt in i vår integrerade transportdatamodell och börja med tanken bakom det hela.
Idé
Att integrera transport är nödvändigt för att maximera dess effektivitet och, för kunderna, dess enkla användning. Integration är relaterad till kostnader men också till tid, tillgänglighet, komfort och säkerhet. Det gäller såväl större städer som mindre. Tanken är att använda den befintliga transportinfrastrukturen och optimera den för bättre resultat; detta kan innebära att komma med nya scheman, aviseringar, linjer eller stationer. Kanske räcker det att bara ha lite information för att du ska bestämma dig för att vänta på bussen, hyra en cykel eller helt enkelt gå till din destination.
Låt oss förklara detta med två exempel.
När det gäller en stor stad finns det vanligtvis många olika transportmedel tillgängliga:bussar, taxibilar, spårvagnar, järnvägar, tunnelbana, etc. Detta kan leda till att många olika privata företag tillhandahåller olika transporttjänster. Att kombinera till och med ett fåtal av dessa tjänster skulle definitivt gynna passagerare och företag genom att sänka kostnaderna, öka effektiviteten och ge mer service per biljett.
Det finns också liknande fördelar för en mindre stad. Det kanske inte finns samma antal alternativ att kombinera, men de kan organiseras för att uppnå maximal effektivitet.
Den här artikeln kommer huvudsakligen att fokusera på integrerade transportbiljettsystem. Vi kommer inte att fokusera på alla aspekter av integration och de olika typerna av transporter; det skulle vara för komplicerat.
Med detta i åtanke, låt oss gå vidare till vår modell.
Datamodell
Modellen består av två ämnesområden:
Cities & companiesTickets
Vi kommer att beskriva dem i den ordning de är listade.
Städer och företag
I det första ämnesområdet kommer vi att lagra alla tabeller som krävs för att skapa transportzoner i städer.
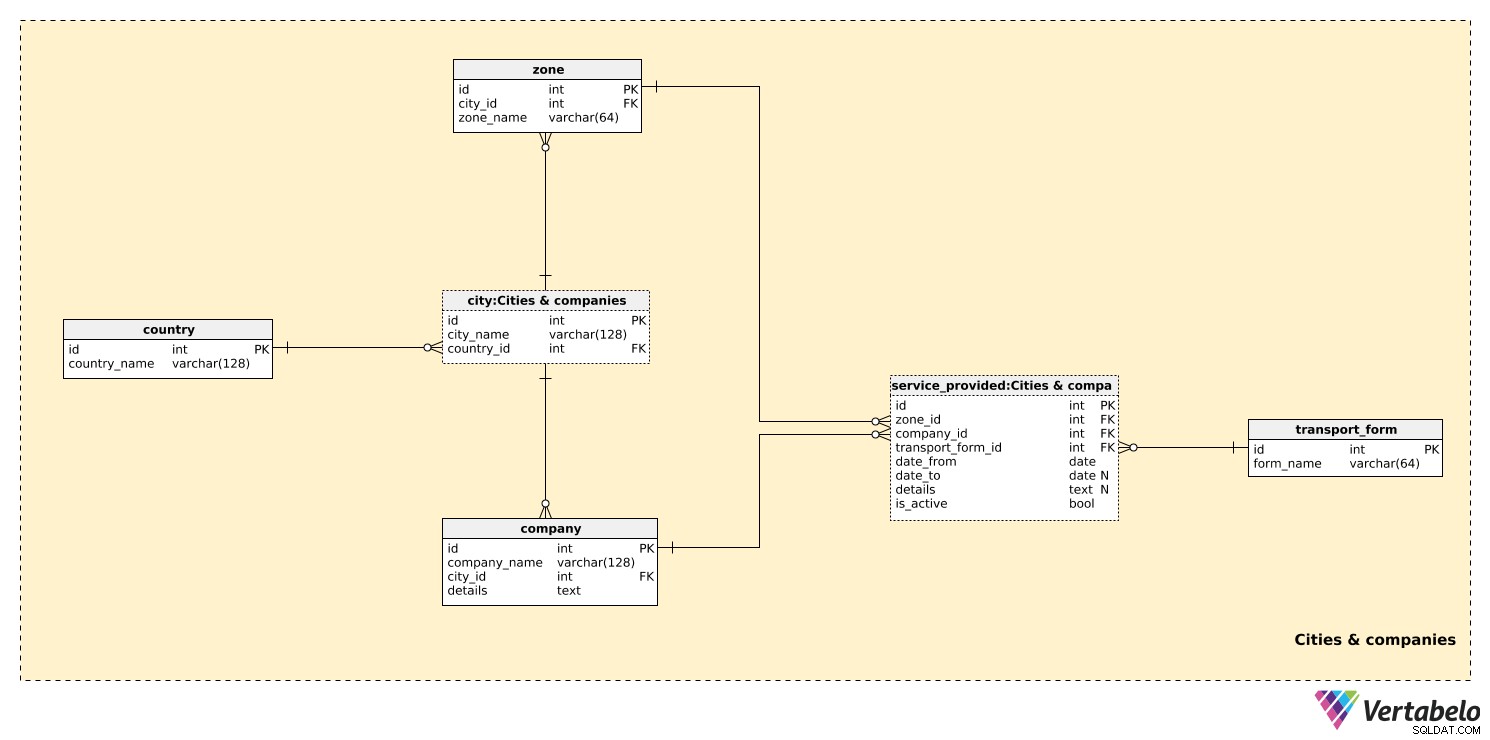
country Tabellen innehåller en lista med UNIKT country_name värden. Den här tabellen används endast som referens i city tabell. Även om vi kan förvänta oss att vår modell kommer att täcka transporter i endast ett land, vill vi ha möjlighet att inkludera flera länder. För varje stad lagrar vi den UNIKA kombinationen city_name – country_id .
Mindre städer kommer förmodligen bara att ha en zon, medan större städer kommer att ha flera zoner. En lista över alla möjliga zoner lagras i zone tabell. För varje zon lagrar vi dess zone_name och en hänvisning till den aktuella staden. Detta par bildar den alternativa nyckeln för denna tabell.
Vi kan förvänta oss att vårt system kommer att lagra information om flera transportföretag. Företag kommer att ge ut sina egna biljetter, men de kommer också att kunna utfärda biljetter tillsammans med andra företag. För varje company , lagrar vi den UNIKA kombinationen av company_name och city_id var den ligger. All nödvändig ytterligare information kan lagras i texten details fältet.
Det sista vi behöver definiera är vilken transportform varje företag tillhandahåller. Några förväntade värden är "buss", "spårvagn", "tunnelbana" och "järnväg". För varje värde i transport_form tabell lagrar vi det UNIKA formulärnamnet.
zone_id– Refererar tillzonetabell och anger det område där denna form av transport tillhandahålls av detta företag.company_id– Refererar tillcompanytillhandahåller denna tjänst i denna zon.transport_form_id– Refererar tilltransport_formtabell och anger vilken typ av tjänst som tillhandahålls.date_fromochdate_to– Den period under vilken denna tjänst tillhandahålls av detta företag. Observera attdate_tokan innehålla ett NULL-värde om den här tjänsten fortfarande är tillgänglig och/eller inte har något förväntat utgångsdatum.details– Alla andra detaljer, i ett ostrukturerat textformat.is_active– Om denna tjänst är aktiv (pågående) eller inte. Detta är en enkel på/av-knapp som vi kan använda i vissa fall istället fördate_from–date_toserviceaktivitetsintervall. Den bästa användningen av detta attribut skulle vara att förenkla frågor, d.v.s. genom att testa detta värde istället för att testa datumintervallet och "leka" med NULL-värden.
Biljetter
Det tidigare ämnesområdet var bara förberedelser inför huvudsaken:biljetter. Och det är vad detta ämnesområde kommer att täcka.
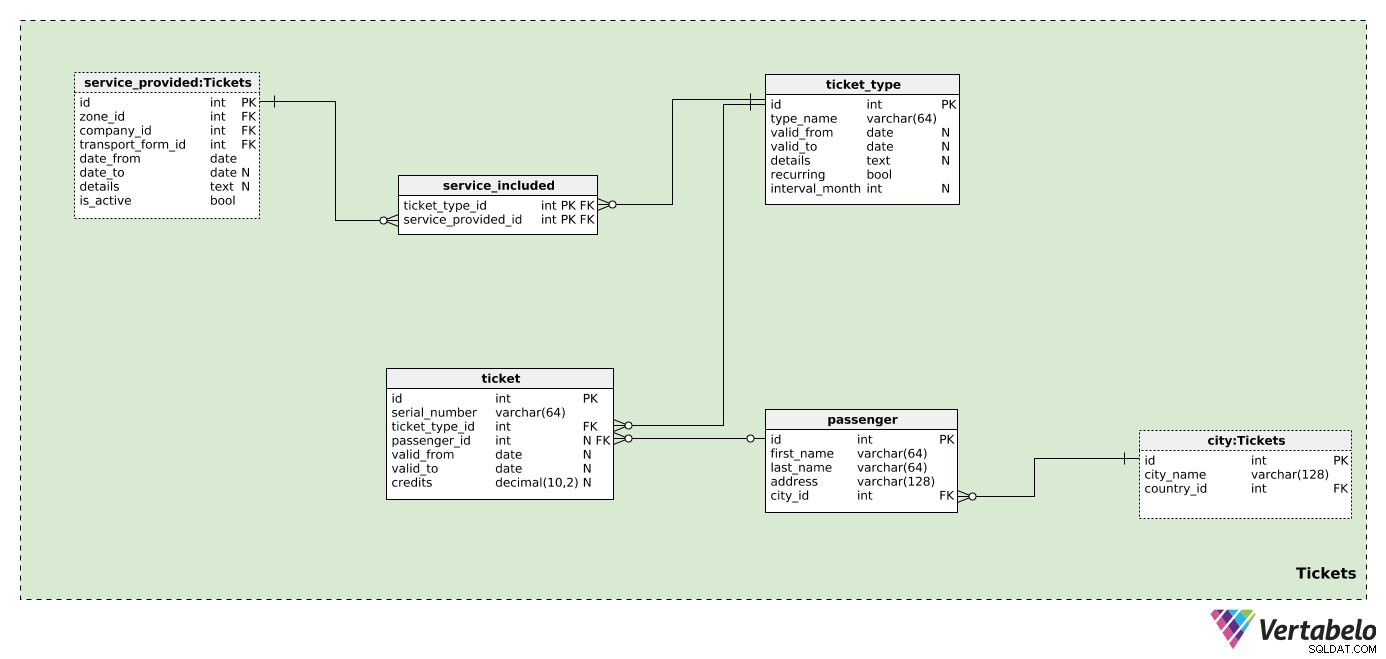
Vi har definierat företag, zoner och transportformer, men vi har inga bestämmelser för passagerare och biljetter - kärnan i denna modell. Vi antar att en biljett kan användas för en eller flera zoner som täcks av ett eller flera företag.
Därför måste vi först definiera varje ticket_type . I den här tabellen listar vi alla möjliga typer av biljetter som säljs av företagen i vår databas. För varje typ lagrar vi följande värden:
type_name– Ett unikt namn som betecknar denna typ.valid_fromochvalid_to– Perioden då denna biljetttyp är (eller var) giltig. Båda fälten är nullbara; ett NULL-värde betyder att det inte finns något start- (eller slutdatum) för när detta var giltigt.details– Alla nödvändiga detaljer, i ostrukturerat textformat.recurring– En flagga som anger om denna biljetttyp är återkommande (t.ex. årligen, månadsvis) eller inte.interval_month– Om biljetttypen är återkommande kommer det här attributet att innehålla intervallet, i månader, när det återkommer (t.ex. "1" för en månadsbiljett, "12" för en årsbiljett).
Nu är vi redo att definiera de zoner som täcks av varje biljetttyp. I service_included tabell lagrar vi endast det UNIKA paret ticket_type_id – service_available_id . Den senare kommer också att ange företaget och zonen där denna biljett kan användas. Den här tabellen tillåter oss att definiera flera zoner per biljett; zoner kan tillhöra olika företag. Eftersom dessa är fördefinierade biljetttyper kommer varje biljetttyp att ha de zoner som definieras här (inte för varje enskild passagerare).
Vi kommer inte att lagra för många passagerardetaljer i denna modell. För varje passenger , lagrar vi endast deras first_name , last_name , address , och en referens till staden där de bor. All denna data kommer att visas på biljetten.
Den sista tabellen i vår modell är ticket tabell. Vi kommer inte att fokusera på engångsbiljetter här; snarare kommer vi att hantera prenumerationer och förbetalda biljetter. Dessa biljetter kommer att ha ett saldo, ett giltighetsdatum eller båda. Detta kan skilja sig betydligt beroende på företaget och dess regler. Om några företag bestämmer sig för att utfärda en biljett kan vi stödja det i den här tabellen – vi kommer att känna till alla viktiga detaljer. För varje biljett lagrar vi:
serial_number– En UNIK beteckning för varje biljett. Detta kan vara en kombination av siffror och bokstäver.ticket_type_id– Refererar till typen av den biljetten.passenger_id– Refererar till passageraren, om någon, som äger biljetten. I händelse av en förbetald biljett kan det inte finnas någon ägare.valid_fromochvalid_to– Anger den period under vilken denna biljett är giltig. NULL-värden anger att det inte finns någon nedre eller övre gräns.credits– Krediterna (som ett numeriskt värde) som för närvarande är tillgängliga på den biljetten. Om det är en förbetald biljett kan vi anta att passagerare kommer att köpa ytterligare krediter på biljetten. Om biljetten är giltig hela månaden (eller någon annan tidsperiod) utan några begränsningar för användningen kan detta värde vara NULL.
Förbättringar av den integrerade transportdatamodellen
Du kan märka att denna modell har förenklats avsevärt. Det beror på att integrerad transport helt enkelt är för stor för att täckas i en artikel. Det finns några saker som jag tror kan ändras i den här modellen:
- Zoner är för förenklade; vi borde kunna definiera dem mer dynamiskt.
- Vi täcker inte linjer (t.ex. busslinjer). Vad händer om de går från en zon till en annan, etc.?
- Vi lagrar inte biljettanvändningshistorik.
- Det finns ingen registrering för företag och passagerare.
Alla dessa skulle leda till det faktum att vi skulle sakna viktig data och inte kunde göra någon djupare analys. Så vad tycker du? Vad behöver denna modell? Vad skulle du lägga till eller ta bort? Dela dina idéer i kommentarerna.