Den serialiserbara isoleringsnivå ger fullständigt skydd från samtidighetseffekter som kan hota dataintegriteten och leda till felaktiga frågeresultat. Att använda serialiserbar isolering innebär att om en transaktion som kan visas ge korrekta resultat utan samtidig aktivitet, kommer den att fortsätta att fungera korrekt när den konkurrerar med vilken kombination som helst av samtidiga transaktioner.
Detta är en mycket kraftig garanti , och en som förmodligen matchar de intuitiva transaktionsisoleringsförväntningarna hos många T-SQL-programmerare (även om i själva verket relativt få av dessa kommer att rutinmässigt använda serialiserbar isolering i produktionen).
SQL-standarden definierar ytterligare tre isoleringsnivåer som erbjuder mycket svagare ACID isoleringsgarantier än som kan serialiseras, i utbyte mot potentiellt högre samtidighet och färre potentiella biverkningar som blockering, låsning och avbrott i tid.
Till skillnad från serialiserbar isolering definieras de andra isoleringsnivåerna enbart i termer av vissa samtidighetsfenomen som kan observeras. Den näst starkaste av standardisoleringsnivåerna efter serialiserbar heter repeterbar läsning . SQL-standarden anger att transaktioner på denna nivå tillåter ett enstaka samtidighetsfenomen som kallas fantom .
Precis som vi tidigare har sett viktiga skillnader mellan den vanliga intuitiva betydelsen av ACID-transaktionsegenskaper och verkligheten, omfattar fantomfenomenet ett bredare spektrum av beteenden än vad som ofta uppskattas.
Det här inlägget i serien tittar på de faktiska garantierna som den upprepade läsningen ger isoleringsnivå och visar några av de fantomrelaterade beteenden som kan uppstå. För att illustrera några punkter kommer vi att hänvisa till följande enkla exempelfråga, där den enkla uppgiften är att räkna det totala antalet rader i en tabell:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Repeterbar läsning
En udda sak med den repeterbara läsisoleringsnivån är att den inte gör det garanterar faktiskt att läsningar är repeterbara , åtminstone i en allmänt förstådd mening. Detta är ytterligare ett exempel där enbart intuitiv mening kan vara vilseledande. Att köra samma fråga två gånger inom samma repeterbara lästransaktion kan verkligen ge olika resultat.
Utöver detta innebär SQL Server-implementeringen av repeterbar läsning att en enda läsning av en uppsättning data kan missa några rader som logiskt sett borde beaktas i frågeresultatet. Även om detta beteende onekligen är implementeringsspecifikt, är det helt i linje med definitionen av repeterbar läsning som finns i SQL-standarden.
Det sista jag snabbt vill notera innan jag går in i detaljer är att repeterbar läsning i SQL Server inte tillhandahålla en punkt-i-tidsvy av data.
Icke-repeterbara läsningar
Den repeterbara läsisoleringsnivån ger en garanti för att data inte kommer att ändras under transaktionens livstid när den har lästs för första gången.
Det finns ett par subtiliteter i den definitionen. För det första tillåter det att data ändras efter transaktionen startar men innan data är först åtkomst. För det andra finns det ingen garanti för att transaktionen faktiskt kommer att stöta på all data som logiskt sett kvalificerar sig. Vi kommer att se exempel på båda dessa inom kort.
Det finns en annan preliminär preliminär som vi behöver komma ur vägen snabbt, som har att göra med den exempelfråga vi kommer att använda. I rättvisans namn är semantiken i den här frågan lite flummig. Med risk för att låta lite filosofiskt, vad betyder det att räkna antalet rader i tabellen? Bör resultatet återspegla tabellens tillstånd som det var vid någon speciell tidpunkt? Ska denna tidpunkt vara början eller slutet av transaktionen, eller något annat?
Det här kan tyckas lite kräsen, men frågan är giltig i vilken databas som helst som stöder samtidiga dataläsningar och modifieringar. Att köra vår exempelfråga kan ta godtyckligt lång tid (med tanke på en tillräckligt stor tabell, eller resursbegränsningar till exempel) så samtidiga ändringar är inte bara möjliga, de kan vara oundvikliga .
Den grundläggande frågan här är potentialen för samtidighetsfenomenet som kallas en fantom i SQL-standarden. Medan vi räknar rader i tabellen kan en annan samtidig transaktion infoga nya rader på en plats som vi redan har kontrollerat, eller ändra en rad vi inte har kontrollerat ännu på ett sådant sätt att den flyttar till en plats vi redan har tittat på. Människor tänker ofta på fantomer som rader som magiskt kan dyka upp när de läses en andra gång, i ett separat uttalande, men effekterna kan vara mycket mer subtila än så.
Exempel på samtidig infogning
Det här första exemplet visar hur samtidiga inlägg kan producera en icke-repeterbar läsa och/eller resultera i att rader hoppas över. Föreställ dig att vår testtabell initialt innehåller fem rader med värdena som visas nedan:

Vi ställer nu in isoleringsnivån till repeterbar läsning, startar en transaktion och kör vår räknefråga. Som du kan förvänta dig är resultatet fem . Inget stort mysterium än så länge.
Kör fortfarande i samma repeterbara läs transaktion , kör vi räknefrågan igen, men den här gången medan en andra samtidiga transaktion infogar nya rader i samma tabell. Diagrammet nedan visar händelseförloppet, där den andra transaktionen lägger till rader med värdena 2 och 6 (du kanske har märkt att dessa värden var iögonfallande genom att de saknades precis ovanför):
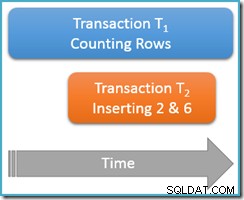
Om vår räkningsfråga kördes på serialiserbar isoleringsnivå, skulle det garanterat räknas antingen fem eller sju rader (se föregående artikel i den här serien om du behöver en uppdatering om varför det är fallet). Hur fungerar löpning på mindre isolerade repeterbar läsnivå påverkar saker?
Tja, upprepad läsning isolering garanterar att den andra körningen av räknefrågan kommer att se alla tidigare lästa rader, och de kommer att vara i samma tillstånd som tidigare. Haken är att repeterbar läsisolering säger inget om hur transaktionen ska behandla de nya raderna (fantomerna).
Föreställ dig att vår radräkningstransaktion (T1 ) har en fysisk exekveringsstrategi där rader söks i en stigande indexordning. Detta är ett vanligt fall, till exempel när en framåtordnad b-trädindexavsökning används av exekveringsmotorn. Nu, precis efter transaktion T1 räknar raderna 1 och 3 i stigande ordning, transaktion T2 kan smyga sig in, infoga nya rader 2 och 6 och sedan genomföra sin transaktion.
Även om vi i första hand tänker på logiska beteenden vid denna tidpunkt, bör jag nämna att det inte finns något i SQL Server-låsningsimplementeringen av repeterbar läsning för att förhindra transaktion T2 från att göra detta. Delade lås tagna av transaktion T1 på tidigare lästa rader förhindrar dessa rader att ändras, men de förhindrar inte nya rader från att infogas i intervallet av värden som testas av vår räknefråga (till skillnad från nyckelintervallslåsen i låsbar serialiserbar isolering skulle göra det).
Hur som helst, med de två nya raderna begångna, transaktion T1 fortsätter sin sökning i stigande ordning och möter så småningom raderna 4, 5, 6 och 7. Observera att T1 ser ny rad 6 i detta scenario, men inte ny rad 2 (på grund av den beställda sökningen och dess position när infogningen skedde).
Resultatet är att den repeterbara läsningen räkningsfråga rapporterar att tabellen innehåller sex rader (värden 1, 3, 4, 5, 6 och 7). Detta resultat är inkonsekvent med det tidigare resultatet av fem rader erhållits inom samma transaktion . Den andra läsningen räknade fantomrad 6 men missade fantomrad 2. Så mycket för den intuitiva innebörden av en repeterbar läsning!
Exempel på samtidig uppdatering
En liknande situation kan uppstå med en samtidig uppdatering istället för en insats. Föreställ dig att vår testtabell är återställd till att innehålla samma fem rader som tidigare:

Den här gången kör vi bara vår räkningsfråga en gång vid den repeterbara läsningen isoleringsnivå, medan en andra samtidig transaktion uppdaterar raden med värde 5 till att ha värdet 2:
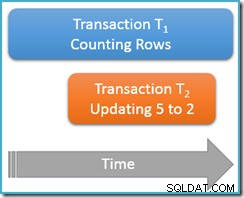
Transaktion T1 återigen börjar räkna rader, (i stigande ordning) möter raderna 1 och 3 först. Nu glider transaktion T2 in, ändrar värdet på rad 5 till 2 och commits:

Jag har visat den uppdaterade raden i samma position som tidigare för att göra ändringen tydlig, men b-tree-indexet vi skannar upprätthåller data i logisk ordning, så den verkliga bilden är närmare detta:

Poängen är att transaktion T1 skannar samtidigt samma struktur i framåtordning och är för närvarande placerad precis efter posten för värde 3. Räknefrågan fortsätter att skanna framåt från den punkten och hittar raderna 4 och 7 (men inte rad 5 förstås).
För att sammanfatta, såg räknefrågan raderna 1, 3, 4 och 7 i det här scenariot. Den rapporterar ett antal fyra rader – vilket är konstigt, eftersom tabellen verkar ha innehållit fem rader hela!
En andra körning av räknefrågan inom samma repeterbara lästransaktion skulle rapportera fem rader, av liknande skäl som tidigare. Som en sista notering, om du undrar, ger samtidiga raderingar inte en möjlighet för en fantombaserad anomali under repeterbar läsisolering.
Sluta tankar
De föregående exemplen använde båda skanningar i stigande ordning av en indexstruktur för att presentera en enkel bild av vilken typ av effekter fantomer kan ha på en repeterbar läsning fråga. Det är viktigt att förstå att dessa illustrationer inte på något viktigt sätt förlitar sig på skanningsriktningen eller det faktum att ett b-trädindex användes. Vänligen gör inte bildar uppfattningen att beställda skanningar på något sätt är ansvarsfulla och därför bör undvikas!
Samma samtidighetseffekter kan ses med en avsökning i fallande ordning av en indexstruktur, eller i en mängd andra fysiska dataåtkomstscenarier. Den stora poängen är att fantomfenomen är specifikt tillåtna (men inte obligatoriska) av SQL-standarden för transaktioner på den repeterbara läsnivån av isolering.
Inte alla transaktioner kräver den fullständiga isoleringsgarantin som tillhandahålls av serialiserbar isolering, och inte många system skulle kunna tolerera biverkningarna om de gjorde det. Ändå lönar det sig att ha en god förståelse för exakt vilka garantier de olika isoleringsnivåerna ger.
Nästa gång
Nästa del i den här serien tittar på de ännu svagare isoleringsgarantierna som erbjuds av SQL Servers standardisoleringsnivå, läs committed .
[ Se indexet för hela serien ]