I den här artikeln kommer vi att lära oss om HAVING-satskonceptet och hur man använder det i SQL.
Vad är HAVING-satsen?
I Structured Query Language anger HAVING-satsen som används med GROUP BY-satsen villkoren som filtrerar resultaten som visas i utdata. Den returnerar endast de data från gruppen som uppfyller villkoren.
Med HAVING-satsen kan vi använda WHERE-satsen även i frågan. Om vi använder båda satserna tillsammans, kommer WHERE-satsen att exekveras först där den filtrerar de individuella raderna, sedan grupperas raderna och i slutet filtrerar HAVING-satsen grupperna.
Villkoren för HAVING-satsen placeras efter GROUP BY-satsen. HAVING-satsen uppförde sig på samma sätt som WHERE-satsen i Structured Query Language använder inte GROUP BY-satsen. Vi kan använda aggregerade funktioner som MIN, MAX, SUM, AVG och COUNT. Denna funktion används endast med SELECT-satsen och HAVING-satsen.
Syntax för HAVING-satsen:
SELECT COLUMNS, AGGREGATE FUNCTION, FROM TABLENAME WHERE CONDITION GROUP BY COLUMN HAVING CONDITIONS; Det finns några steg vi måste lära oss för hur man använder HAVING-satsen i SQL-frågan:
1. Skapa en ny databas eller använd en befintlig databas genom att välja databasen med nyckelordet USE följt av databasnamnet.
2. Skapa en ny tabell i den valda databasen, eller så kan du använda en redan skapad tabell.
3. Om tabellen skapas ny, infoga posterna i den nyskapade databasen med INSERT-frågan och visa infogade data med SELECT-frågan utan HAVING-satsen.
4. Nu är vi redo att använda HAVING-satsen i SQL-frågorna.
Steg 1:Skapa en ny databas eller använd en redan skapad databas.
Jag har redan skapat en databas. Jag kommer att använda mitt befintliga skapade databasnamn.
USE SCHOOL;
Skola är databasnamnet.
De som inte har skapat en databas, följ frågan nedan för att skapa databasen:
CREATE DATABASE database_name;
När du har skapat databasen väljer du databasen med hjälp av nyckelordet USE följt av databasens namn.
Steg 2:Skapa en ny tabell eller använd redan befintlig tabell:
Jag har redan skapat en tabell. Jag kommer att använda den befintliga tabellen som heter Student.
Följ syntaxen CREATE TABLE nedan för att skapa de nya tabellerna:
CREATE TABLE table_name(
columnname1 datatype(column size),
columnname2 datatype(column size),
columnname3 datatype(column size)
);
Steg 3:Infoga posterna i den nyskapade tabellen med INSERT-frågan och visa posterna med SELECT-frågan.
Använd nedanstående syntax för att infoga nya poster i tabellen:
INSERT INTO table_name VALUES(value1, value2, value3);Så här visar du posterna från tabellen med syntaxen nedan:
SELECT * FROM table_name;
Följande fråga kommer att visa uppgifter om anställda
SELECT * FROM Student;
Utdata från ovanstående SELECT-fråga är:
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS | CHEMISTRY_MARKS | MATHS_MARKS | TOTAL_MARKS |
| 1 | NEHA | 85 | 88 | 100 | 273 |
| 2 | VISHAL | 70 | 90 | 82 | 242 |
| 3 | SAMKEET | 75 | 88 | 96 | 259 |
| 4 | NIKHIL | 60 | 75 | 80 | 215 |
| 5 | YOGESH | 56 | 65 | 78 | 199 |
| 6 | ANKITA | 95 | 85 | 96 | 276 |
| 7 | SONAM | 98 | 89 | 100 | 287 |
| 8 | VINEET | 85 | 90 | 100 | 275 |
| 9 | SANKET | 86 | 78 | 65 | 229 |
| 10 | PRACHI | 90 | 80 | 75 | 245 |
Steg 4:Vi är redo att använda HAVING-satsen i Structured Query Language.
Vi kommer nu att göra en djupdykning i HAVING-satsen med hjälp av exempel.
Vi har en tabell som heter Student som innehåller följande poster.
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS | CHEMISTRY_MARKS | MATHS_MARKS | TOTAL_MARKS |
| 1 | NEHA | 85 | 88 | 100 | 273 |
| 2 | VISHAL | 70 | 90 | 82 | 242 |
| 3 | SAMKEET | 75 | 88 | 96 | 259 |
| 4 | NIKHIL | 60 | 75 | 80 | 215 |
| 5 | YOGESH | 56 | 65 | 78 | 199 |
| 6 | ANKITA | 95 | 85 | 96 | 276 |
| 7 | SONAM | 98 | 89 | 100 | 287 |
| 8 | VINEET | 85 | 90 | 100 | 275 |
| 9 | SANKET | 86 | 78 | 65 | 229 |
| 10 | PRACHI | 90 | 80 | 75 | 245 |
Exempel 1: Skriv en fråga för att visa summan av fysikbetyg där summan av fysikbetyg är större än 60 grupper efter student-id.
SELECT STUDENT_ID, STUDENT_NAME, SUM(PHYSICS_MARKS) AS PHYSICS_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING SUM(PHYSICS_MARKS) > 60;I ovanstående fråga har vi tagit en aggregatfunktion som heter SUM() följt av kolumnnamnet physics_marks, som kommer att summera kolumnen. Först exekveras Sum(physics_marks), sedan exekveras HAVING-satsvillkoret i slutet, och det slutliga resultatet kommer att visas. Vi har använt GROUP BY-satsen följt av kolumnnamnet Student_Id för att gruppera samma värden och betrakta dem som en grupp. Om värdena inte är desamma kommer ingen grupp att bildas för värden. Och i slutet har vi använt HAVING-satsen där vi sätter villkoret som hjälper till att visa endast de elevdetaljer där summan av fysikbetyg är större än 60. Om elevernas fysikbetyg är mindre än 60, kommer den inte att visa rekord.
Utdata från ovanstående fråga är:
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS |
| 1 | NEHA | 85 |
| 2 | VISHAL | 70 |
| 3 | SAMKEET | 75 |
| 6 | ANKITA | 95 |
| 7 | SONAM | 98 |
| 8 | VINEET | 85 |
| 9 | SANKET | 86 |
| 10 | PRACHI | 90 |
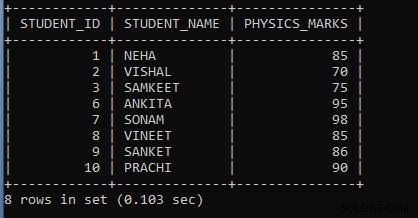
Som vi kan se i utdata visas endast de student-ID, namn och fysikbetyg där summan av fysikbetyg är större än 60. Eftersom vi använde GROUP BY-sats och inga värden är lika, räknas de som en enda grupp .
Exempel 2: Skriv en fråga för att visa det maximala antalet kemibetyg där det maximala antalet kemibetyg är mindre än 90 grupper efter student-id.
SELECT STUDENT_ID, STUDENT_NAME, MAX(CHEMISTRY_MARKS) AS CHEMISTRY_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING MAX(CHEMISTRY_MARKS) < 90; I ovanstående fråga har vi tagit en aggregatfunktion som heter MAX() följt av kolumnnamnet kemi_märken, som kommer att hitta de maximala poängen för kolumnen. Vi har använt GROUP BY-satsen följt av kolumnnamnet Student_Id för att gruppera samma värden och betrakta dem som en grupp. Om värdena inte är desamma, kommer en separat grupp att bildas för värden. Och i slutet har vi använt HAVING-satsen där vi sätter villkoret som hjälper till att visa endast de studentuppgifter där det maximala antalet kemibetyg är mindre än 90. Om elevens kemibetyg är större än 90, kommer det inte att visa journalerna. Först exekveras MAX(kemi_märken), sedan körs HAVING-satsvillkoret i slutet och det slutliga resultatet kommer att visas. Utdata från ovanstående fråga är:
| STUDENT_ID | STUDENT_NAME | CHEMISTRY_MARKS |
| 1 | NEHA | 88 |
| 3 | SAMKEET | 88 |
| 4 | NIKHIL | 75 |
| 5 | YOGESH | 65 |
| 6 | ANKITA | 85 |
| 7 | SONAM | 89 |
| 9 | SANKET | 78 |
| 10 | PRACHI | 80 |
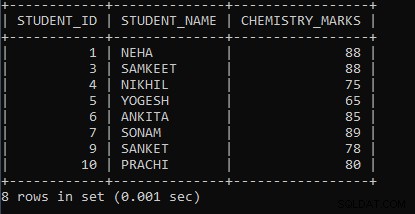
Som vi kan se i resultatet visas endast de student-ID, namn och kemimärken där det maximala antalet kemibetyg är mindre än 90. Eftersom vi använde GROUP BY-sats och inga värden är lika, räknas de som en enda grupp.
Exempel 3: Skriv en fråga för att visa matematikbetygen där ett lägsta antal matematikbetyg är större än 70 grupper efter student-id.
SELECT STUDENT_ID, STUDENT_NAME, MIN(MATHS_MARKS) AS MATHS_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING MIN(MATHS_MARKS) >70;I ovanstående fråga har vi tagit en aggregerad funktion som heter MIN() följt av kolumnnamnet maths_marks, som kommer att hitta minsta poäng för kolumnen. Vi har använt GROUP BY-satsen följt av kolumnnamnet Student_Id för att gruppera samma värden och betrakta dem som en grupp. Om värdena inte är desamma, kommer en separat grupp att bildas för värden. Och i slutet har vi använt HAVING-satsen där vi sätter villkoret som hjälper till att visa endast de elevuppgifter där minimibetyget för matematikbetyg är större än 70. Om studentens matematikbetyg är mindre än 70, kommer det inte att visa journalerna. Först exekveras MIN(maths_marks), sedan exekveras HAVING-satsvillkoret i slutet, och det slutliga resultatet kommer att visas.
Utdata från ovanstående fråga är:
| STUDENT_ID | STUDENT_NAME | MATHS_MARKS |
| 1 | NEHA | 100 |
| 2 | VISHAL | 82 |
| 3 | SAMKEET | 96 |
| 4 | NIKHIL | 80 |
| 5 | YOGESH | 78 |
| 6 | ANKITA | 96 |
| 7 | SONAM | 100 |
| 8 | VINEET | 100 |
| 10 | PRACHI | 75 |
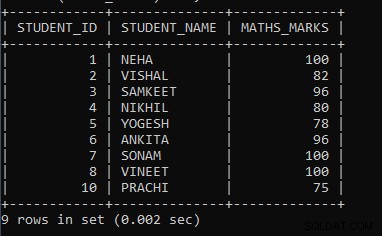
Som vi kan se i resultatet visas endast de elev-ID, namn och matematikbetyg där minimibetyget för matematikbetyg är större än 70. Eftersom vi använde GROUP BY-sats och inga värden är lika, räknas de som en enda grupp.
Exempel 4: Skriv en fråga för att visa elevinformation där minsta fysikbetyg är större än 56, OCH maximala matematikbetyg är mindre än 98.
SELECT STUDENT_ID, STUDENT_NAME, MIN(PHYSICS_MARKS) AS PHYSICS_MARKS , MAX(MATHS_MARKS) AS MATHS_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING MIN(PHYSICS_MARKS) >58 AND MAX(MATHS_MARKS)<98;Vi använde dubbla aggregerade funktioner i en enda fråga min() och max() i ovanstående fråga. Min() används för att ta reda på minimumbetygen för fysik, och Max() används för att ta reda på de maximala matematiska poängen. Först hittar frågan min() och max()-betygen för fysik och matematik från elevtabellen. Som vi använde GROUP BY-sats, så liknande värden mappas som en grupp, annars kommer värden att vara separerade. Eftersom inga värden är lika i tabellen har alla värden separerats. Inga värden kommer att mappas som en grupp. Därefter använde vi HAVING-satsen, som fungerar som WHERE-satsskillnad endast HAVING-satsen mappad in i gruppen. För det första är villkoret MIN(PHYSICS_MARKS)> 58. Eftersom inga värden är lika, kommer varje värde att betraktas som ett minimivärde, och jämfört med villkoret används samma tillvägagångssätt för MAX(MATHS_MARKS). Eftersom vi använde AND-operatorn i frågan, uppfyller dessa villkor båda villkoren. Endast dessa elevers poster visas i slutresultatet.
Utdata från ovanstående fråga är:
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS | MATHS_MARKS |
| 2 | VISHAL | 70 | 82 |
| 3 | SAMKEET | 75 | 96 |
| 4 | NIKHIL | 60 | 80 |
| 6 | ANKITA | 95 | 96 |
| 9 | SANKET | 86 | 65 |
| 10 | PRACHI | 90 | 75 |
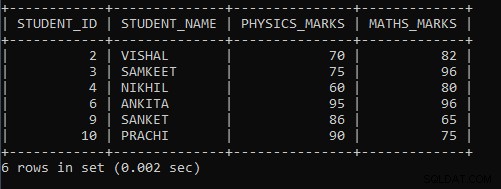
Som vi kan se i utgången visas endast de studentposter där minsta poäng för fysikvärden är större än 56 och maximala matematiska poäng är mindre än 98.
I exemplet ovan, om den används OR-operator istället för AND-operator, visas alla de tio posterna eftersom OR-operatorn säger att om ett villkor misslyckas och andra villkor är sanna, så uppfyller tabellposter villkoren.