I del 5 av min serie om tabelluttryck tillhandahöll jag följande lösning för att generera en serie tal med hjälp av CTE, en tabellvärdeskonstruktor och korskopplingar:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Det finns många praktiska användningsfall för ett sådant verktyg, inklusive att generera en serie datum- och tidsvärden, skapa exempeldata och mer. Vissa plattformar inser det gemensamma behovet och tillhandahåller ett inbyggt verktyg, såsom PostgreSQL:s generation_series-funktion. I skrivande stund tillhandahåller T-SQL inte ett sådant inbyggt verktyg, men man kan alltid hoppas och rösta på att ett sådant verktyg ska läggas till i framtiden.
I en kommentar till min artikel nämnde Marcos Kirchner att han testade min lösning med varierande tabellvärdekonstruktorkardinaliteter, och fick olika exekveringstider för de olika kardinaliteterna.
 Jag använde alltid min lösning med en bastabellvärdekonstruktorkardinalitet på 2, men Marcos kommentar fick mig att tänka. Det här verktyget är så användbart att vi som community borde gå samman för att försöka skapa den snabbaste versionen vi kan. Att testa olika bastabellkardinaliteter är bara en dimension att prova. Det kan finnas många andra. Jag kommer att presentera prestandatesterna som jag har gjort med min lösning. Jag experimenterade huvudsakligen med olika tabellvärdeskonstruktorkardinaliteter, med seriell kontra parallell bearbetning, och med radläge kontra batchlägesbearbetning. Det kan dock vara så att en helt annan lösning är ännu snabbare än min bästa version. Så, utmaningen är igång! Jag kallar alla jedi, padawan, trollkarl och lärling. Vilken är den bästa lösningen du kan trolla fram? Har du det inom dig att slå den snabbaste lösningen hittills? Om så är fallet, dela din kommentar som en kommentar till den här artikeln och förbättra gärna alla lösningar som lagts upp av andra.
Jag använde alltid min lösning med en bastabellvärdekonstruktorkardinalitet på 2, men Marcos kommentar fick mig att tänka. Det här verktyget är så användbart att vi som community borde gå samman för att försöka skapa den snabbaste versionen vi kan. Att testa olika bastabellkardinaliteter är bara en dimension att prova. Det kan finnas många andra. Jag kommer att presentera prestandatesterna som jag har gjort med min lösning. Jag experimenterade huvudsakligen med olika tabellvärdeskonstruktorkardinaliteter, med seriell kontra parallell bearbetning, och med radläge kontra batchlägesbearbetning. Det kan dock vara så att en helt annan lösning är ännu snabbare än min bästa version. Så, utmaningen är igång! Jag kallar alla jedi, padawan, trollkarl och lärling. Vilken är den bästa lösningen du kan trolla fram? Har du det inom dig att slå den snabbaste lösningen hittills? Om så är fallet, dela din kommentar som en kommentar till den här artikeln och förbättra gärna alla lösningar som lagts upp av andra.
Krav:
- Implementera din lösning som en inline-tabellvärderad funktion (iTVF) med namnet dbo.GetNumsYourName med parametrarna @low AS BIGINT och @high AS BIGINT. Som ett exempel, se de jag skickar in i slutet av den här artikeln.
- Du kan skapa stödtabeller i användardatabasen om det behövs.
- Du kan lägga till tips efter behov.
- Som nämnts bör lösningen stödja avgränsare av typen BIGINT, men du kan anta en maximal seriekardinalitet på 4 294 967 296.
- För att utvärdera prestandan för din lösning och jämföra den med andra testar jag den med intervallet 1 till 100 000 000, med Ignorera resultat efter exekvering aktiverat i SSMS.
Lycka till för oss alla! Må det bästa samhället vinna.;)
Olika kardinaliteter för bastabellvärdekonstruktor
Jag experimenterade med olika kardinaliteter för basens CTE, som började med 2 och avancerade i en logaritmisk skala, och kvadrerade föregående kardinalitet i varje steg:2, 4, 16 och 256.
Innan du börjar experimentera med olika baskardinaliteter kan det vara bra att ha en formel som med tanke på baskardinalitet och maximalt intervallkardinalitet skulle berätta hur många nivåer av CTE:er du behöver. Som ett preliminärt steg är det lättare att först komma på en formel som med tanke på baskardinaliteten och antalet nivåer av CTE:er beräknar vad som är den maximala resulterande intervallkardinaliteten. Här är en sådan formel uttryckt i T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Med ovanstående exempel på indatavärden ger detta uttryck en maximal intervallkardinalitet på 4 294 967 296.
Sedan innebär den omvända formeln för att beräkna antalet CTE-nivåer som behövs kapsla två loggfunktioner, som så:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Med ovanstående exempel på indatavärden ger detta uttryck 5. Observera att detta nummer är ett tillägg till bas-CTE som har tabellvärdekonstruktorn, som jag döpte till L0 (för nivå 0) i min lösning.
Fråga mig inte hur jag kom till dessa formler. Historien jag håller mig till är att Gandalf uttalade dem till mig på alviska i mina drömmar.
Låt oss gå vidare till prestandatestning. Se till att du aktiverar Kasta resultat efter körning i dialogrutan för SSMS-frågealternativ under Grid, Results. Använd följande kod för att köra ett test med bas CTE-kardinalitet på 2 (kräver 5 ytterligare nivåer av CTE):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Jag fick planen som visas i figur 1 för det här utförandet.
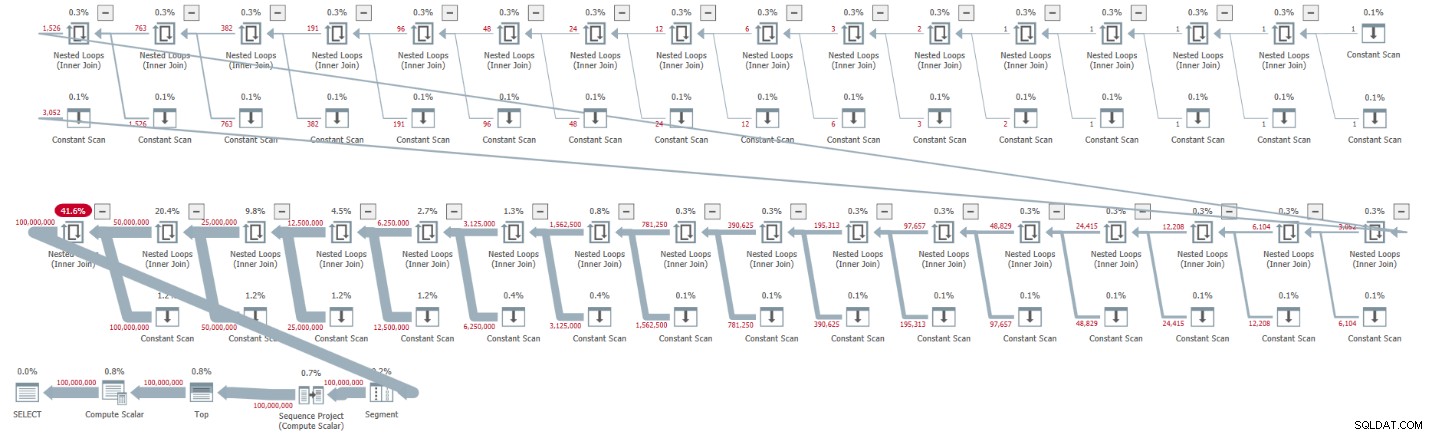 Figur 1:Plan för bas CTE-kardinalitet på 2
Figur 1:Plan för bas CTE-kardinalitet på 2
Planen är seriell och alla operatörer i planen använder radlägesbehandling som standard. Om du får en parallell plan som standard, t.ex. när du kapslar in lösningen i en iTVF och använder ett stort utbud, tvingar du nu fram en serieplan med en MAXDOP 1-tips.
Observera hur uppackningen av CTE:erna resulterade i 32 instanser av Constant Scan-operatorn, som var och en representerar en tabell med två rader.
Jag fick följande prestandastatistik för den här körningen:
CPU time = 30188 ms, elapsed time = 32844 ms.
Använd följande kod för att testa lösningen med en bas-CTE-kardinalitet på 4, vilket enligt vår formel kräver fyra nivåer av CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Jag fick planen som visas i figur 2 för det här utförandet.
 Figur 2:Plan för bas CTE-kardinalitet på 4
Figur 2:Plan för bas CTE-kardinalitet på 4
Uppackningen av CTE:erna resulterade i 16 Constant Scan-operatorer, som var och en representerar en tabell med 4 rader.
Jag fick följande prestandastatistik för den här körningen:
CPU time = 23781 ms, elapsed time = 25435 ms.
Detta är en anständig förbättring med 22,5 procent jämfört med den tidigare lösningen.
När man undersöker väntestatistik som rapporterats för frågan, är den dominerande väntetypen SOS_SCHEDULER_YIELD. Faktum är att antalet väntetider märkligt sjönk med 22,8 procent jämfört med den första lösningen (väntantalet 15 280 mot 19 800).
Använd följande kod för att testa lösningen med en bas-CTE-kardinalitet på 16, vilket enligt vår formel kräver tre nivåer av CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Jag fick planen som visas i figur 3 för det här utförandet.
 Figur 3:Plan för bas CTE-kardinalitet på 16
Figur 3:Plan för bas CTE-kardinalitet på 16
Denna gång resulterade uppackningen av CTE i 8 Constant Scan-operatorer, som var och en representerar en tabell med 16 rader.
Jag fick följande prestandastatistik för den här körningen:
CPU time = 22968 ms, elapsed time = 24409 ms.
Denna lösning minskar den förflutna tiden ytterligare, om än med bara några ytterligare procent, vilket motsvarar en minskning med 25,7 procent jämfört med den första lösningen. Återigen, väntetalet för SOS_SCHEDULER_YIELD väntetyp fortsätter att sjunka (12 938).
När vi avancerar i vår logaritmiska skala, innebär nästa test en bas CTE-kardinalitet på 256. Det är långt och fult, men prova:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Jag fick planen som visas i figur 4 för det här utförandet.
 Figur 4:Plan för bas CTE-kardinalitet på 256
Figur 4:Plan för bas CTE-kardinalitet på 256
Den här gången resulterade uppackningen av CTE:erna i endast fyra Constant Scan-operatorer, var och en med 256 rader.
Jag fick följande prestationsnummer för den här exekveringen:
CPU time = 23516 ms, elapsed time = 25529 ms.
Den här gången verkar det som om prestandan försämrades något jämfört med den tidigare lösningen med en bas-CTE-kardinalitet på 16. Faktum är att väntetalet för väntetypen SOS_SCHEDULER_YIELD ökade lite till 13 176. Så det verkar som att vi hittat vårt gyllene nummer – 16!
Parallella kontra serieplaner
Jag experimenterade med att tvinga fram en parallell plan med tipset ENABLE_PARALLEL_PLAN_PREFERENCE, men det slutade med att det skadade prestandan. Faktum är att när jag implementerade lösningen som en iTVF, fick jag en parallell plan på min maskin som standard för stora räckvidder och var tvungen att tvinga fram en seriell plan med en MAXDOP 1-tips för att få optimal prestanda.
Satsbearbetning
Den huvudsakliga resursen som används i planerna för mina lösningar är CPU. Med tanke på att batchbearbetning handlar om att förbättra CPU-effektiviteten, särskilt när man hanterar ett stort antal rader, är det värt att prova det här alternativet. Den huvudsakliga aktiviteten här som kan dra nytta av batchbearbetning är radnummerberäkningen. Jag testade mina lösningar i SQL Server 2019 Enterprise Edition. SQL Server valde radlägesbehandling för alla tidigare visade lösningar som standard. Tydligen klarade den här lösningen inte heuristiken som krävs för att aktivera batchläge på rowstore. Det finns ett par sätt att få SQL Server att använda batchbearbetning här.
Alternativ 1 är att involvera en tabell med ett kolumnlagerindex i lösningen. Du kan uppnå detta genom att skapa en dummy-tabell med ett columnstore-index och introducera en dummy left join i den yttersta frågan mellan våra Nums CTE och den tabellen. Här är dummy-tabelldefinitionen:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Revidera sedan den yttre frågan mot Nums för att använda FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Här är ett exempel med en bas CTE-kardinalitet på 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Jag fick planen som visas i figur 5 för det här utförandet.
 Figur 5:Planera med batchbearbetning
Figur 5:Planera med batchbearbetning
Observera användningen av batchläget Window Aggregate-operator för att beräkna radnumren. Observera också att planen inte involverar dummybordet. Optimeraren optimerade det.
Uppsidan med alternativ 1 är att det fungerar i alla SQL Server-utgåvor och är relevant i SQL Server 2016 eller senare, eftersom batchläget Window Aggregate-operatorn introducerades i SQL Server 2016. Nackdelen är behovet av att skapa dummy-tabellen och inkludera det i lösningen.
Alternativ 2 för att få batchbearbetning för vår lösning, förutsatt att du använder SQL Server 2019 Enterprise Edition, är att använda den odokumenterade självförklarande tipsen OVERRIDE_BATCH_MODE_HEURISTICS (detaljer i Dmitry Pilugins artikel), som så:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Fördelen med alternativ 2 är att du inte behöver skapa ett dummybord och involvera det i din lösning. Nackdelarna är att du måste använda Enterprise-utgåvan, använda minst SQL Server 2019 där batchläge på rowstore introducerades, och lösningen innebär att du använder en odokumenterad ledtråd. Av dessa skäl föredrar jag alternativ 1.
Här är prestationstalen som jag fick för de olika bas-CTE-kardinaliteterna:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
Figur 6 har en prestandajämförelse mellan de olika lösningarna:
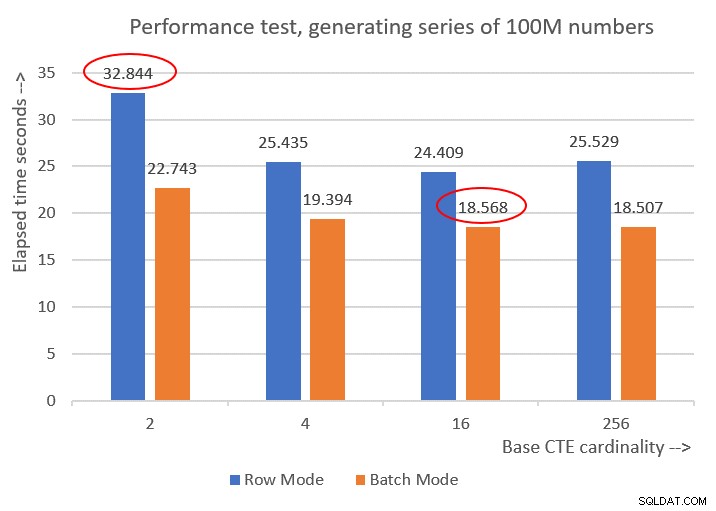 Figur 6:Prestandajämförelse
Figur 6:Prestandajämförelse
Du kan observera en anständig prestandaförbättring på 20-30 procent jämfört med motsvarigheterna i radläget.
Märkligt nog gick lösningen med bas-CTE-kardinalitet på 256 bäst med batch-läge. Det är dock bara en liten bit snabbare än lösningen med bas-CTE-kardinalitet på 16. Skillnaden är så liten, och den senare har en klar fördel när det gäller kodkorthet, att jag skulle hålla mig till 16.
Så mina inställningsförsök gav en förbättring på 43,5 procent från den ursprungliga lösningen med baskardinaliteten 2 med radlägesbearbetning.
Utmaningen är igång!
Jag skickar in två lösningar som mitt samhällsbidrag till denna utmaning. Om du kör på SQL Server 2016 eller senare och kan skapa en tabell i användardatabasen, skapa följande dummy-tabell:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Och använd följande iTVF-definition:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Använd följande kod för att testa det (se till att ha Ignorera resultat efter körning markerat):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Den här koden slutar på 18 sekunder på min maskin.
Om du av någon anledning inte kan uppfylla kraven för batchbehandlingslösningen skickar jag in följande funktionsdefinition som min andra lösning:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Använd följande kod för att testa den:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Den här koden slutar på 24 sekunder på min maskin.
Din tur!