Inlägg av Dan Holmes, som bloggar på sql.dnhlms.com.
SQL Server Books Online (BOL), whitepapers och många andra källor visar dig hur och varför du kanske vill uppdatera statistik på en tabell eller ett index. Du får dock bara ett sätt att forma dessa värderingar. Jag kommer att visa dig hur du kan skapa statistiken precis som du vill inom gränserna för de 200 tillgängliga stegen.
Ansvarsfriskrivning :Det här fungerar för mig eftersom jag känner till min applikation, min databas och min användares vanliga arbetsflöde och applikationsanvändningsmönster. Däremot använder den odokumenterade kommandon och, om den används felaktigt, kan det få din applikation att prestera betydligt sämre.I vår applikation läser och skriver Scheduling-användaren regelbundet data som representerar händelser för morgondagen och de kommande dagarna. Data för idag och tidigare används inte av schemaläggaren. Först på morgonen börjar datamängden för morgondagen på ett par hundra rader och vid middagstid kan den vara 1400 och högre. Följande diagram illustrerar radantalet. Denna data samlades in på morgonen onsdagen den 18 november 2015. Historiskt sett kan du se att det vanliga radantalet är cirka 1 400 förutom helgdagar och nästa dag.
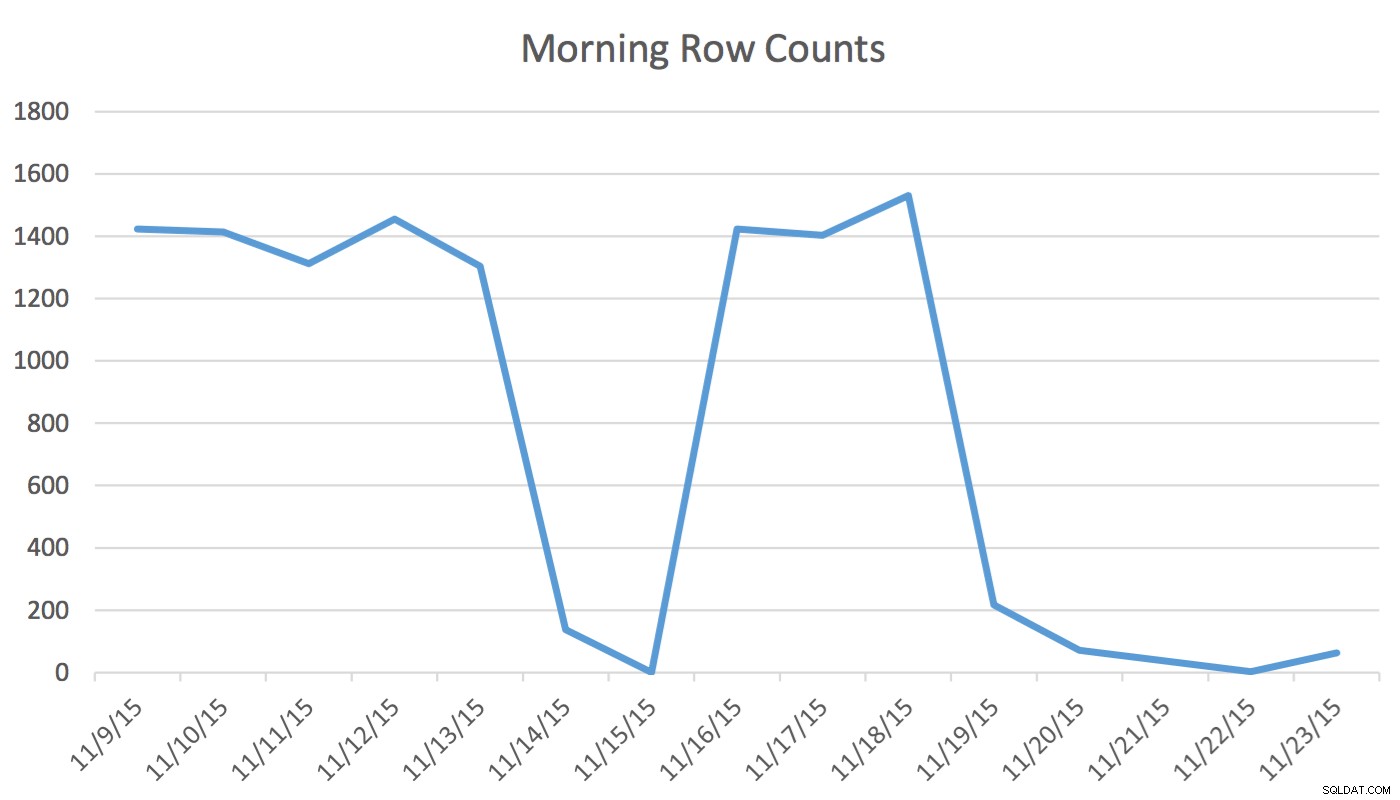
För Schemaläggaren är den enda relevanta informationen de närmaste dagarna. Vad som händer idag och hände igår är inte relevant för hans aktivitet. Så hur orsakar detta problem? Den här tabellen har 2 259 205 rader vilket innebär att förändringen i radantal från morgon till middag inte kommer att räcka för att utlösa en SQL Server-initierad statistikuppdatering. Dessutom ett manuellt schemalagt jobb som bygger statistik med UPDATE STATISTICS fyller i histogrammet med ett urval av alla data i tabellen men kanske inte inkluderar relevant information. Detta radräkningsdelta är tillräckligt för att ändra planen. Men utan en statistikuppdatering och ett korrekt histogram kommer planen inte att förändras till det bättre när data ändras.
Ett relevant urval av histogrammet för denna tabell från en säkerhetskopia daterad 2015-11-4 kan se ut så här:
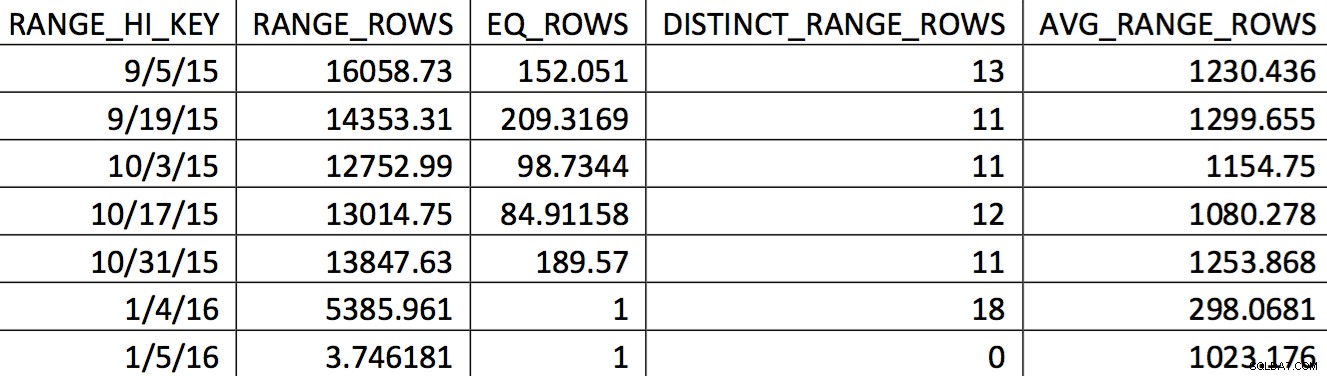
Värdena av intresse återspeglas inte korrekt i histogrammet. Det som skulle användas för datumet 11/5/2015 skulle vara det höga värdet 1/4/2016. Baserat på grafen är detta histogram uppenbarligen inte en bra informationskälla för optimeraren för datumet av intresse. Att tvinga in användningsvärdena i histogrammet är inte tillförlitligt, så hur kan du göra det? Mitt första försök var att upprepade gånger använda WITH SAMPLE alternativet UPDATE STATISTICS och fråga histogrammet tills de värden jag behövde fanns i histogrammet (en ansträngning som beskrivs här). I slutändan visade sig det tillvägagångssättet vara opålitligt.
Detta histogram kan leda till en plan med denna typ av beteende. Underskattningen av rader ger en Nested Loop-koppling och en indexsökning. Läsvärdena är senare högre än de borde vara på grund av detta planval. Detta kommer också att ha en effekt på uttalandets varaktighet.
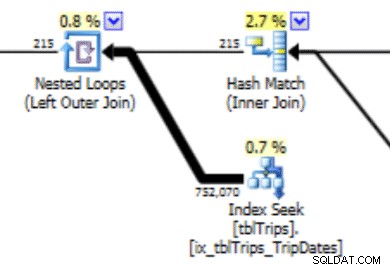
Det som skulle fungera mycket bättre är att skapa data precis som du vill ha den, och så här gör du det.
Det finns ett alternativ för UPDATE STATISTICS som inte stöds :STATS_STREAM . Detta används av Microsoft Customer Support för att exportera och importera statistik så att de kan återskapa en optimerare utan att ha all data i tabellen. Vi kan använda den funktionen. Tanken är att skapa en tabell som efterliknar DDL för statistiken vi vill anpassa. Relevanta uppgifter läggs till i tabellen. Statistiken exporteras och importeras till den ursprungliga tabellen.
I det här fallet är det en tabell med 200 rader med inte NULL-datum och 1 rad som inkluderar NULL-värdena. Dessutom finns det ett index i den tabellen som matchar indexet som har de dåliga histogramvärdena.
Namnet på tabellen är tblTripsScheduled . Den har ett icke-klustrat index på (id, TheTripDate) och ett klustrat index på TheTripDate . Det finns en handfull andra kolumner, men bara de som ingår i indexet är viktiga.
Skapa en tabell (temp tabell om du vill) som efterliknar tabellen och indexet. Tabellen och indexet ser ut så här:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Därefter måste tabellen fyllas i med 200 rader med data som statistiken ska baseras på. För min situation är det dagen under de närmaste sextio dagarna. De senaste och senare 60 dagarna fylls med ett "slumpmässigt" urval var tionde dag. (cnt värde i CTE är ett felsökningsvärde. Det spelar ingen roll i slutresultatet.) Den fallande ordningen för rn kolumnen säkerställer att de 60 dagarna ingår, och sedan så mycket av det förflutna som möjligt.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Vår tabell är nu fylld med varje rad som är värdefull för användaren idag och ett urval av historiska rader. Om kolumnen TheTripdate var nullbar, skulle infogningen också ha inkluderat följande:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Därefter uppdaterar vi statistiken på indexet för vår temperaturtabell.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Exportera nu den statistiken till en tillfällig tabell. Bordet ser ut så här. Den matchar utdata från DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS har en möjlighet att exportera statistiken som en stream. Det är den strömmen vi vill ha. Den strömmen är också samma ström som UPDATE STATISTICS strömalternativet använder. För att göra det:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Det sista steget är att skapa SQL som uppdaterar statistiken för vår måltabell och sedan köra den.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); Vid det här laget har vi ersatt histogrammet med vårt specialbyggda. Du kan verifiera genom att kontrollera histogrammet:
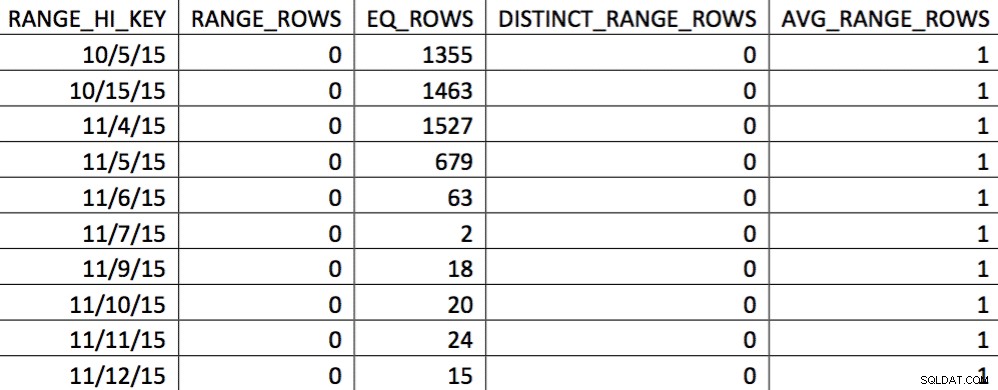
I detta urval av data den 11/4 representeras alla dagar från 11/4 och framåt, och de historiska uppgifterna är representerade och korrekta. Genom att gå igenom den del av frågeplanen som visats tidigare kan du se att optimeraren gjorde ett bättre val baserat på den korrigerade statistiken:
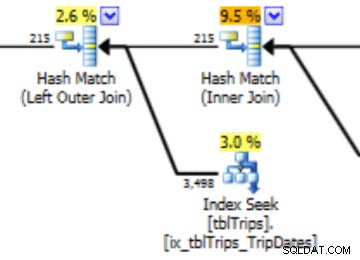
Det finns en prestandafördel med importerad statistik. Kostnaden för att beräkna statistiken är på en "offline"-tabell. Den enda stilleståndstiden för produktionstabellen är strömimportens varaktighet.
Den här processen använder odokumenterade funktioner och det ser ut som att det kan vara farligt, men kom ihåg att det finns en enkel att ångra:uppdateringsstatistiken. Om något går fel kan statistiken alltid uppdateras med standard T-SQL.
Att schemalägga den här koden att köras regelbundet kan i hög grad hjälpa optimeraren att skapa bättre planer givet en datauppsättning som ändras över tipping point men inte tillräckligt för att utlösa en statistikuppdatering.
När jag avslutade det första utkastet av denna artikel ändrades radantalet på tabellen i det första diagrammet från 217 till 717. Det är en förändring på 300 %. Det räcker för att ändra optimerarens beteende men inte tillräckligt för att utlösa en statistikuppdatering. Denna dataändring skulle ha lämnat en dålig plan på plats. Det är med den process som beskrivs här som detta problem löses.
Referenser:
- UPPDATERA STATISTIK (böcker online)
- SQL 2008 Statistik Whitepaper
- Tipping Point Search