Det finns funktioner många av oss drar sig för, som markörer, triggers och dynamisk SQL. Det råder ingen tvekan om att var och en har sina användningsfall, men när vi ser en utlösare med en markör inuti dynamisk SQL, kan det få oss att krypa ihop (trippel jävla).
Planguider och sp_prepare är i en liknande båt:om du såg mig använda en av dem skulle du höja på ögonbrynen; om du såg mig använda dem tillsammans, skulle du förmodligen kolla min temperatur. Men som med markörer, triggers och dynamisk SQL, har de sina användningsfall. Och jag stötte nyligen på ett scenario där det var fördelaktigt att använda dem tillsammans.
Bakgrund
Vi har mycket data. Och många applikationer som körs mot den datan. Vissa av dessa applikationer är svåra eller omöjliga att ändra, särskilt applikationer från en tredje part. Så när deras kompilerade applikation skickar ad hoc-förfrågningar till SQL Server, särskilt som en förberedd sats, och när vi inte har friheten att lägga till eller ändra index, finns flera tuningmöjligheter omedelbart utanför bordet.
I det här fallet hade vi en tabell med ett par miljoner rader. En förenklad och sanerad version:
CREATE TABLE dbo.TheThings
(
ThingID bigint NOT NULL,
TypeID uniqueidentifier NOT NULL,
dt1 datetime NOT NULL DEFAULT sysutcdatetime(),
dt2 datetime NOT NULL DEFAULT sysutcdatetime(),
dt3 datetime NOT NULL DEFAULT sysutcdatetime(),
CONSTRAINT PK_TheThings PRIMARY KEY (ThingID)
);
CREATE INDEX ix_type ON dbo.TheThings(TypeID);
SET NOCOUNT ON;
GO
DECLARE @guid1 uniqueidentifier = 'EE81197A-B2EA-41F4-882E-4A5979ACACE4',
@guid2 uniqueidentifier = 'D989AADB-5C34-4EE1-9BE2-A88B8F74A23F';
INSERT dbo.TheThings(ThingID, TypeID)
SELECT TOP (1000) 1000 + ROW_NUMBER() OVER (ORDER BY name), @guid1
FROM sys.all_columns;
INSERT dbo.TheThings(ThingID, TypeID)
SELECT TOP (1) 2500, @guid2
FROM sys.all_columns;
INSERT dbo.TheThings(ThingID, TypeID)
SELECT TOP (1000) 3000 + ROW_NUMBER() OVER (ORDER BY name), @guid1
FROM sys.all_columns; Det förberedda uttalandet från applikationen såg ut så här (som syns i plancachen):
(@P0 varchar(8000))SELECT * FROM dbo.TheThings WHERE TypeID = @P0
Problemet är att för vissa värden av TypeID , skulle det finnas många tusen rader. För andra värden skulle det vara färre än 10. Om fel plan väljs (och återanvänds) baserat på en parametertyp kan detta vara problem för de andra. För frågan som hämtar en handfull rader vill vi ha en indexsökning med uppslagningar för att hämta de ytterligare icke täckta kolumnerna, men för frågan som returnerar 700 000 rader vill vi bara ha en klustrad indexskanning. (Helst skulle indexet täcka, men det här alternativet fanns inte i korten den här gången.)
I praktiken fick applikationen alltid skanningsvariationen, även om det var den som behövdes ungefär 1 % av tiden. 99 % av frågorna använde en skanning på 2 miljoner rader när de kunde ha använt en sökning + 4 eller 5 uppslagningar.
Vi kan enkelt återskapa detta i Management Studio genom att köra den här frågan:
DBCC FREEPROCCACHE; DECLARE @P0 uniqueidentifier = 'EE81197A-B2EA-41F4-882E-4A5979ACACE4'; SELECT * FROM dbo.TheThings WHERE TypeID = @P0; GO DBCC FREEPROCCACHE; DECLARE @P0 uniqueidentifier = 'D989AADB-5C34-4EE1-9BE2-A88B8F74A23F'; SELECT * FROM dbo.TheThings WHERE TypeID = @P0; GO
Planerna kom tillbaka så här:
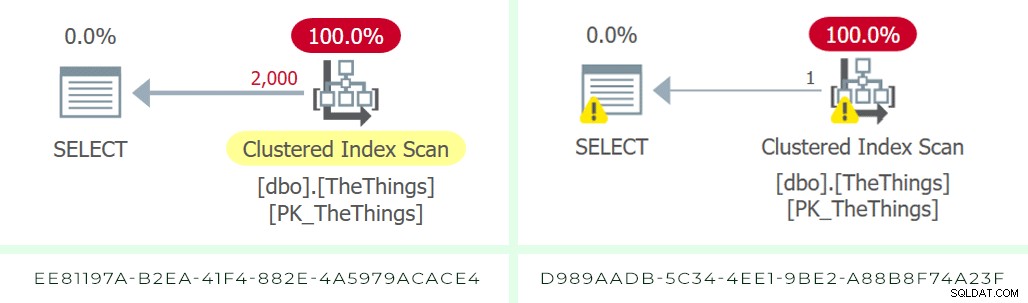 Uppskattningen i båda fallen var 1 000 rader; varningarna till höger beror på kvarvarande I/O.
Uppskattningen i båda fallen var 1 000 rader; varningarna till höger beror på kvarvarande I/O.
Hur kunde vi se till att frågan gjorde rätt val beroende på parametern? Vi skulle behöva göra det omkompilera, utan att lägga till tips till frågan, aktivera spårningsflaggor eller ändra databasinställningar.
Om jag körde frågorna självständigt med OPTION (RECOMPILE) , jag skulle få sökningen när det är lämpligt:
DBCC FREEPROCCACHE;
DECLARE @guid1 uniqueidentifier = 'EE81197A-B2EA-41F4-882E-4A5979ACACE4',
@guid2 uniqueidentifier = 'D989AADB-5C34-4EE1-9BE2-A88B8F74A23F';
SELECT * FROM dbo.TheThings WHERE TypeID = @guid1 OPTION (RECOMPILE);
SELECT * FROM dbo.TheThings WHERE TypeID = @guid2 OPTION (RECOMPILE);
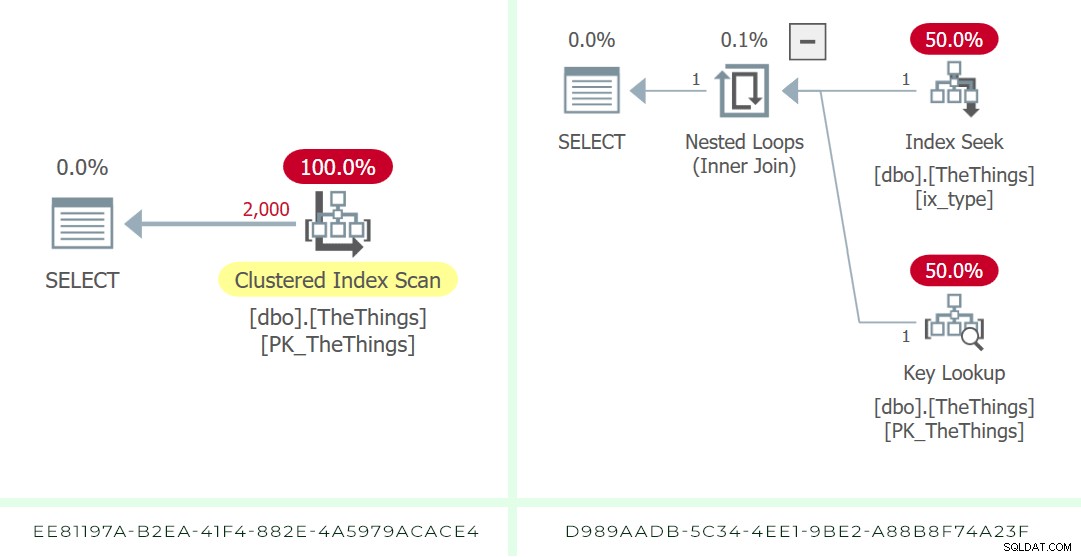 Med RECOMPILE får vi mer exakta uppskattningar och en sökning när vi behöver en.
Med RECOMPILE får vi mer exakta uppskattningar och en sökning när vi behöver en.
Men återigen, vi kunde inte lägga till ledtråden till frågan direkt.
Låt oss prova en planguide
Många varnar för planguider, men vi var typ i ett hörn här. Vi skulle definitivt föredra att ändra frågan, eller indexen, om vi kunde. Men det här kan vara det näst bästa.
EXEC sys.sp_create_plan_guide @name = N'TheThingGuide', @stmt = N'SELECT * FROM dbo.TheThings WHERE TypeID = @P0', @type = N'SQL', @params = N'@P0 varchar(8000)', @hints = N'OPTION (RECOMPILE)';
Verkar okomplicerat; att testa det är problemet. Hur simulerar vi ett förberett uttalande i Management Studio? Hur kan vi vara säkra på att ansökan får den guidade planen och att det uttryckligen beror på planguiden?
Om vi försöker simulera den här frågan i SSMS, behandlas detta som ett ad hoc-uttalande, inte ett förberett uttalande, och jag kunde inte få detta att hämta planguiden:
DECLARE @P0 varchar(8000) = 'D989AADB-5C34-4EE1-9BE2-A88B8F74A23F'; -- also tried uniqueidentifier SELECT * FROM dbo.TheThings WHERE TypeID = @P0
Dynamisk SQL fungerade inte heller (detta behandlades också som en ad hoc-sats):
DECLARE @sql nvarchar(max) = N'SELECT * FROM dbo.TheThings WHERE TypeID = @P0',
@params nvarchar(max) = N'@P0 varchar(8000)', -- also tried uniqueidentifier
@P0 varchar(8000) = 'D989AADB-5C34-4EE1-9BE2-A88B8F74A23F';
EXEC sys.sp_executesql @sql, @params, @P0; Och jag kunde inte göra detta, eftersom det inte heller skulle ta upp planguiden (parametriseringen tar över här, och jag hade inte friheten att ändra databasinställningar, även om detta skulle behandlas som ett förberett uttalande) :
SELECT * FROM TheThings WHERE TypeID = 'D989AADB-5C34-4EE1-9BE2-A88B8F74A23F';
Jag kan inte kontrollera planens cache för frågor som körs från appen, eftersom den cachade planen inte indikerar något om planguideanvändning (SSMS injicerar den informationen i XML för dig när du genererar en faktisk plan). Och om frågan verkligen observerar RECOMPILE-tipset som jag skickar in i planguiden, hur skulle jag någonsin kunna se några bevis i planens cache?
Låt oss försöka sp_prepare
Jag har använt sp_prepare mindre i min karriär än planguider, och jag skulle inte rekommendera att använda det för applikationskod. (Som Erik Darling påpekar kan uppskattningen hämtas från densitetsvektorn, inte från att sniffa parametern.)
I mitt fall vill jag inte använda det av prestandaskäl, jag vill använda det (tillsammans med sp_execute) för att simulera det förberedda uttalandet som kommer från appen.
DECLARE @o int;
EXEC sys.sp_prepare @o OUTPUT, N'@P0 varchar(8000)',
N'SELECT * FROM dbo.TheThings WHERE TypeID = @P0';
EXEC sys.sp_execute @o, 'EE81197A-B2EA-41F4-882E-4A5979ACACE4'; -- PK scan
EXEC sys.sp_execute @o, 'D989AADB-5C34-4EE1-9BE2-A88B8F74A23F'; -- IX seek + lookup
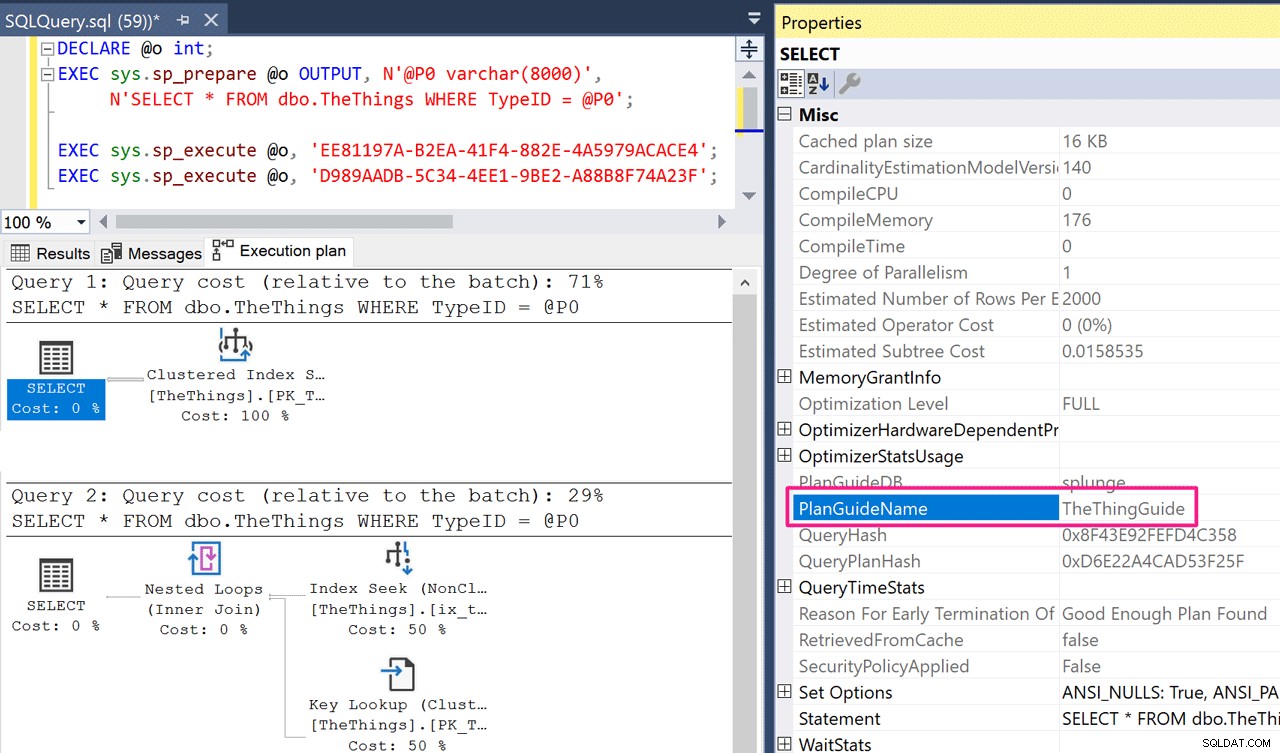 SSMS visar oss att planguiden användes i båda fallen.
SSMS visar oss att planguiden användes i båda fallen.
Du kommer inte att kunna kontrollera planens cache för dessa resultat på grund av omkompileringen. Men i ett scenario som mitt borde du kunna se effekterna av övervakning, explicit kontroll via Extended Events, eller observera lindring av symptomet som fick dig att undersöka den här frågan i första hand (var bara medveten om att genomsnittlig körtid, fråga statistik etc. kan påverkas av ytterligare kompilering).
Slutsats
Detta var ett fall där en planguide var fördelaktig och sp_prepare var användbar för att validera att den skulle fungera för applikationen. Dessa är inte ofta användbara, och mer sällan tillsammans, men för mig var det en intressant kombination. Även utan planguiden, om du vill använda SSMS för att simulera en app som skickar förberedda uttalanden, är sp_prepare din vän. (Se även sp_prepexec, som kan vara en genväg om du inte försöker validera två olika planer för samma fråga.)
Observera att den här övningen inte nödvändigtvis var för att få bättre prestanda hela tiden – det var att platta till prestationsvariansen. Omkompileringar är uppenbarligen inte gratis, men jag betalar en liten straffavgift för att 99 % av mina frågor körs på 250 ms och 1 % körs på 5 sekunder, snarare än att vara fast med en plan som är helt fruktansvärd för antingen 99 % av frågorna eller 1 % av frågorna.