 Denna artikel är den åttonde delen i en serie om tabelluttryck. Hittills har jag gett en bakgrund till tabelluttryck, som täckte både de logiska och optimeringsaspekterna av härledda tabeller, de logiska aspekterna av CTE:er och några av optimeringsaspekterna av CTE:er. Den här månaden fortsätter jag bevakningen av optimeringsaspekter av CTE:er, särskilt med hur flera CTE-referenser hanteras.
Denna artikel är den åttonde delen i en serie om tabelluttryck. Hittills har jag gett en bakgrund till tabelluttryck, som täckte både de logiska och optimeringsaspekterna av härledda tabeller, de logiska aspekterna av CTE:er och några av optimeringsaspekterna av CTE:er. Den här månaden fortsätter jag bevakningen av optimeringsaspekter av CTE:er, särskilt med hur flera CTE-referenser hanteras.
I mina exempel kommer jag att fortsätta använda exempeldatabasen TSQLV5. Du kan hitta skriptet som skapar och fyller i TSQLV5 här, och dess ER-diagram här.
Flera referenser och icke-determinism
Förra månaden förklarade och visade jag att CTE:er blir okapslade, medan temporära tabeller och tabellvariabler faktiskt kvarstår med data. Jag gav rekommendationer när det gäller när det är vettigt att använda CTE:er jämfört med när det är vettigt att använda temporära objekt ur frågeprestandasynpunkt. Men det finns en annan viktig aspekt av CTE-optimering, eller fysisk bearbetning, att överväga utöver lösningens prestanda – hur flera referenser till CTE från en yttre fråga hanteras. Det är viktigt att inse att om du har en yttre fråga med flera referenser till samma CTE, blir var och en okapslad separat. Om du har icke-deterministiska beräkningar i CTE:s inre fråga, kan dessa beräkningar få olika resultat i de olika referenserna.
Säg till exempel att du anropar funktionen SYSDATETIME i en CTE:s inre fråga och skapar en resultatkolumn som heter dt. I allmänhet, förutsatt att indata inte ändras, utvärderas en inbyggd funktion en gång per fråga och referens, oberoende av antalet rader som är involverade. Om du endast refererar till CTE en gång från en yttre fråga, men interagerar med dt-kolumnen flera gånger, ska alla referenser representera samma funktionsutvärdering och returnera samma värden. Men om du hänvisar till CTE flera gånger i den yttre frågan, vare sig det är med flera underfrågor som hänvisar till CTE eller en koppling mellan flera instanser av samma CTE (säg alias som C1 och C2), referenserna till C1.dt och C2.dt representerar olika utvärderingar av det underliggande uttrycket och kan resultera i olika värden.
För att visa detta, överväg följande tre batcher:
-- Batch 1 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 VÄLJ @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); PRINT @i;GO -- Batch 2 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 MED C AS (VÄLJ SYSDATETIME() AS dt ) VÄLJ @i +=1 FRÅN C WHERE dt =dt; PRINT @i;GO -- Batch 3 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 MED C AS (VÄLJ SYSDATETIME() AS dt ) VÄLJ @i +=1 WHERE (VÄLJ dt FRÅN C) =(VÄLJ dt FRÅN C); SKRIV UT @i;GO
Baserat på vad jag just förklarade, kan du identifiera vilken av satserna som har en oändlig loop och vilken kommer att sluta någon gång på grund av att de två jämförelserna av predikatet utvärderas till olika värden?
Kom ihåg att jag sa att ett anrop till en inbyggd icke-deterministisk funktion som SYSDATETIME utvärderas en gång per fråga och referens. Det betyder att du i Batch 1 har två olika utvärderingar och efter tillräckligt många iterationer av slingan kommer de att resultera i olika värden. Försök. Hur många iterationer rapporterade koden?
När det gäller Batch 2 har koden två referenser till dt-kolumnen från samma CTE-instans, vilket betyder att båda representerar samma funktionsutvärdering och bör representera samma värde. Följaktligen har batch 2 en oändlig loop. Kör den så länge du vill, men så småningom måste du stoppa kodexekveringen.
När det gäller batch 3 har den yttre frågan två olika underfrågor som interagerar med CTE C, som var och en representerar en annan instans som går igenom en avvecklingsprocess separat. Koden tilldelar inte uttryckligen olika alias till de olika instanserna av CTE eftersom de två underfrågorna visas i oberoende omfattningar, men för att göra det lättare att förstå kan du tänka på att de två använder olika alias som C1 i en underfråga och C2 i den andra. Så det är som om en underfråga interagerar med C1.dt och den andra med C2.dt. De olika referenserna representerar olika utvärderingar av det underliggande uttrycket och kan därför resultera i olika värden. Testa att köra koden och se att den stannar någon gång. Hur många iterationer tog det tills det slutade?
Det är intressant att försöka identifiera de fall där du har en enstaka mot flera utvärderingar av det underliggande uttrycket i exekveringsplanen för frågor. Figur 1 har de grafiska exekveringsplanerna för de tre batcherna (klicka för att förstora).
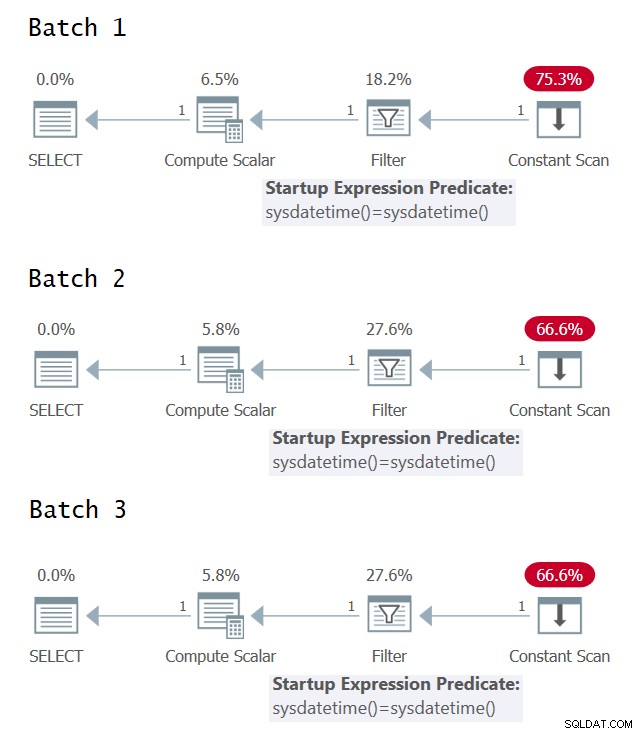 Figur 1:Grafiska exekveringsplaner för batch 1, batch 2 och batch 3
Figur 1:Grafiska exekveringsplaner för batch 1, batch 2 och batch 3
Tyvärr ingen glädje av de grafiska utförandeplanerna; de verkar alla identiska även om de tre partierna semantiskt sett inte har identiska betydelser. Tack vare @CodeRecce och Forrest (@tsqladdict) lyckades vi som community komma till botten med detta med andra medel.
Som @CodeRecce upptäckte, innehåller XML-planerna svaret. Här är de relevanta delarna av XML för de tre satserna:
−− Batch 1
…
…
−− Batch 2
…
…
…
…
Du kan tydligt se i XML-planen för Batch 1 att filterpredikatet jämför resultaten av två separata direkta anrop av den inneboende SYSDATETIME-funktionen.
I XML-planen för batch 2 jämför filterpredikatet det konstanta uttrycket ConstExpr1002 som representerar en anrop av funktionen SYSDATETIME med sig själv.
I XML-planen för batch 3 jämför filterpredikatet två olika konstantuttryck som kallas ConstExpr1005 och ConstExpr1006, som var och en representerar en separat anrop av funktionen SYSDATETIME.
Som ett annat alternativ föreslog Forrest (@tsqladdict) att använda spårningsflagga 8605, som visar den initiala frågeträdsrepresentationen skapad av SQL Server, efter att ha aktiverat spårningsflagga 3604 som gör att utdata från TF 8605 dirigeras till SSMS-klienten. Använd följande kod för att aktivera båda spårningsflaggorna:
Därefter kör du koden som du vill hämta frågeträdet för. Här är de relevanta delarna av utdata som jag fick från TF 8605 för de tre batcherna:
LogOp_Project COL:Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [tom]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Inte ägd,Value=1)
−− Batch 2
LogOp_Project COL:Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [tom]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Inte ägd,Value=1)
−− Batch 3
LogOp_Project COL:Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [tom]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [tom]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [tom]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Inte ägd,Värde=1)
I batch 1 kan du se en jämförelse mellan resultaten av två separata utvärderingar av den inneboende funktionen SYSDATETIME.
I batch 2 ser du en utvärdering av funktionen som resulterar i en kolumn som heter Expr1000, och sedan en jämförelse mellan denna kolumn och sig själv.
I Batch 3 ser du två separata utvärderingar av funktionen. En i kolumn som heter Expr1000 (senare projicerad av underfrågakolumnen som heter Expr1001). En annan i kolumn som heter Expr1002 (senare projicerad av underfrågakolumnen som heter Expr1003). Du har då en jämförelse mellan Expr1001 och Expr1003.
Så, med lite mer grävande utöver vad den grafiska exekveringsplanen avslöjar, kan du faktiskt ta reda på när ett underliggande uttryck bara utvärderas en gång jämfört med flera gånger. Nu när du förstår de olika fallen kan du utveckla dina lösningar baserat på det önskade beteendet du är ute efter.
Det finns en annan klass av beräkningar som kan få dig i problem när de används i lösningar med flera referenser till samma CTE. Det är fönsterfunktioner som förlitar sig på icke-deterministisk ordning. Ta fönsterfunktionen ROW_NUMBER som ett exempel. När den används med delbeställning (beställning efter element som inte unikt identifierar raden), kan varje utvärdering av den underliggande frågan resultera i en annan tilldelning av radnumren även om den underliggande informationen inte ändrades. Med flera CTE-referenser, kom ihåg att var och en blir okapslad separat, och du kan få olika resultatuppsättningar. Beroende på vad den yttre frågan gör med varje referens, t.ex. vilka kolumner från varje referens den interagerar med och hur, kan optimeraren bestämma sig för att komma åt data för var och en av instanserna med hjälp av olika index med olika ordningskrav.
Betrakta följande kod som ett exempel:
Kan den här frågan någonsin returnera en icke-tom resultatuppsättning? Kanske är din första reaktion att den inte kan. Men tänk på det jag just förklarade lite mer noggrant och du kommer att inse att, åtminstone i teorin, på grund av de två separata CTE-unnesting-processerna som kommer att äga rum här - en av C1 och en annan av C2 - är det möjligt. Men det är en sak att teoretisera att något kan hända, och en annan att visa det. Till exempel, när jag körde den här koden utan att skapa några nya index, fick jag hela tiden en tom resultatuppsättning:
Jag fick planen som visas i figur 23 för den här frågan.
Vad som är intressant att notera här är att optimeraren valde att använda olika index för att hantera de olika CTE-referenserna eftersom det var vad den ansåg vara optimal. När allt kommer omkring handlar varje referens i den yttre frågan om en annan delmängd av CTE-kolumnerna. En referens resulterade i en ordnad framåtsökning av indexet idx_nc_orderedate och den andra i en oordnad avsökning av det klustrade indexet följt av en sorteringsoperation efter orderdatum stigande. Även om indexet idx_nc_orderedate uttryckligen endast definieras i orderdate-kolumnen som nyckel, så är det i praktiken definierat på (orderdate, orderid) som dess nycklar eftersom orderid är den klustrade indexnyckeln och ingår som den sista nyckeln i alla icke-klustrade index. Så en ordnad skanning av indexet avger faktiskt raderna ordnade efter orderdate, orderid. När det gäller den oordnade genomsökningen av det klustrade indexet, på lagringsmotornivån, skannas data i indexnyckelordning (baserat på orderid) för att tillgodose minimala konsistensförväntningar på standardisoleringsnivån som läser committed. Sorteringsoperatorn matar därför in data sorterad efter orderid, sorterar raderna efter orderdatum och i praktiken sänder ut raderna sorterade efter orderdate, orderid.
Återigen, i teorin finns det ingen garanti för att de två referenserna alltid kommer att representera samma resultatuppsättning även om den underliggande informationen inte ändras. Ett enkelt sätt att demonstrera detta är att ordna två olika optimala index för de två referenserna, men ha en ordning på data efter orderdate ASC, orderid ASC, och den andra ordna data efter orderdate DESC, orderid ASC (eller precis tvärtom). Vi har redan det tidigare indexet på plats. Här är kod för att skapa den senare:
Kör koden en andra gång efter att du skapat indexet:
Jag fick följande utdata när jag körde den här koden efter att ha skapat det nya indexet:
Hoppsan.
Undersök frågeplanen för den här exekveringen som visas i figur 3:
Lägg märke till att planens övre gren skannar indexet idx_nc_orderdate på ett ordnat framåtsätt, vilket gör att sekvensprojektoperatören som beräknar radnumren matar in data i praktiken ordnad efter orderdatum ASC, orderid ASC. Den nedre grenen av planen skannar det nya indexet idx_nc_odD_oid_I_sc på ett ordnat bakåtsätt, vilket får Sequence Project-operatören att i praktiken inta datan sorterad efter orderdate ASC, orderid DESC. Detta resulterar i ett annat arrangemang av radnummer för de två CTE-referenserna när det finns mer än en förekomst av samma orderdatumvärde. Följaktligen genererar frågan en icke-tom resultatuppsättning.
Om du vill undvika sådana buggar är ett uppenbart alternativ att bevara det inre frågeresultatet i ett temporärt objekt som en temporär tabell eller tabellvariabel. Men om du har en situation där du hellre föredrar att använda CTE, är en enkel lösning att använda total ordning i fönsterfunktionen genom att lägga till en tiebreaker. Med andra ord, se till att du sorterar efter en kombination av uttryck som unikt identifierar en rad. I vårt fall kan du helt enkelt lägga till orderid uttryckligen som en tiebreak, som så:
Du får en tom resultatuppsättning som förväntat:
Utan att lägga till några ytterligare index får du planen som visas i figur 4:
Den övre grenen av planen är densamma som för den tidigare planen som visas i figur 3. Den nedre grenen är dock lite annorlunda. Det nya indexet som skapats tidigare är inte riktigt idealiskt för den nya frågan i den meningen att den inte har data sorterad som ROW_NUMBER-funktionen behöver (orderdatum, orderid). Det är fortfarande det smalaste täckande indexet som optimeraren kunde hitta för sin respektive CTE-referens, så det är valt; den skannas dock på ett beställt:falskt sätt. En explicit sorteringsoperator sorterar sedan data efter orderdatum, orderid som ROW_NUMBER-beräkningen behöver. Naturligtvis kan du ändra indexdefinitionen så att både orderdate och orderid använder samma riktning och på så sätt kommer den explicita sorteringen att elimineras från planen. Huvudpoängen är dock att genom att använda total beställning undviker du att hamna i problem på grund av denna specifika bugg.
När du är klar, kör följande kod för rengöring:
Det är viktigt att förstå att flera referenser till samma CTE från en yttre fråga resulterar i separata utvärderingar av CTE:s inre fråga. Var särskilt försiktig med icke-deterministiska beräkningar, eftersom de olika utvärderingarna kan resultera i olika värden.
När du använder fönsterfunktioner som ROW_NUMBER och aggregat med en ram, se till att använda total ordning för att undvika att få olika resultat för samma rad i de olika CTE-referenserna.
−− Batch 3DBCC TRACEON(3604); -- direkt utdata till clientGO DBCC TRACEON(8605); -- visa den första frågan treeGO
*** Konverterat träd:***
*** Konverterat träd:***
*** Konverterat träd:***Fönsterfunktioner med icke-deterministisk ordning
ANVÄND TSQLV5; MED C AS( SELECT *, ROW_NUMBER() ÖVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
orderid shipcountry orderid------------ --------------------- -----------(0 rader påverkade)
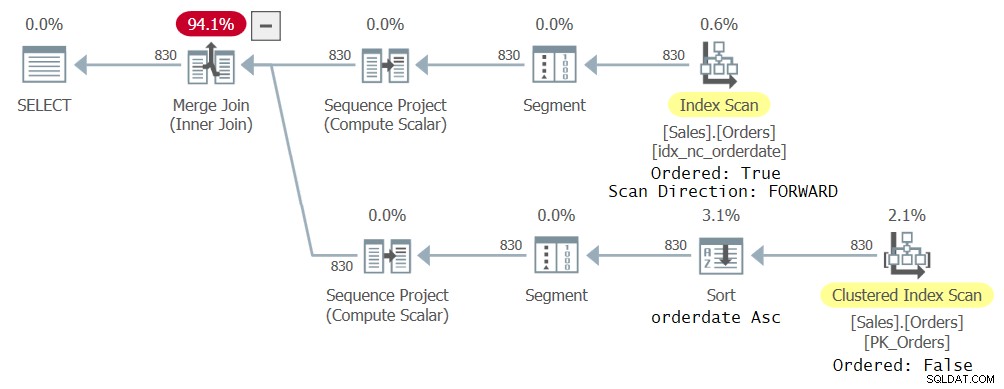 Figur 2:Första planen för fråga med två CTE-referenser
Figur 2:Första planen för fråga med två CTE-referenser SKAPA INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdatum DESC, orderid) INCLUDE(shipcountry);
MED C AS( SELECT *, ROW_NUMBER() ÖVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;
orderid shipcountry orderid------------ --------------------------------10251 Frankrike 1025010250 Brasilien 1025110261 Brasilien 1026010260 Tyskland 1026110271 USA 10270...11070 Tyskland 1107311077 USA 1107411076 Frankrike 1107511075 Schweiz 1107611074 Danmark 11077(546 rader påverkade)
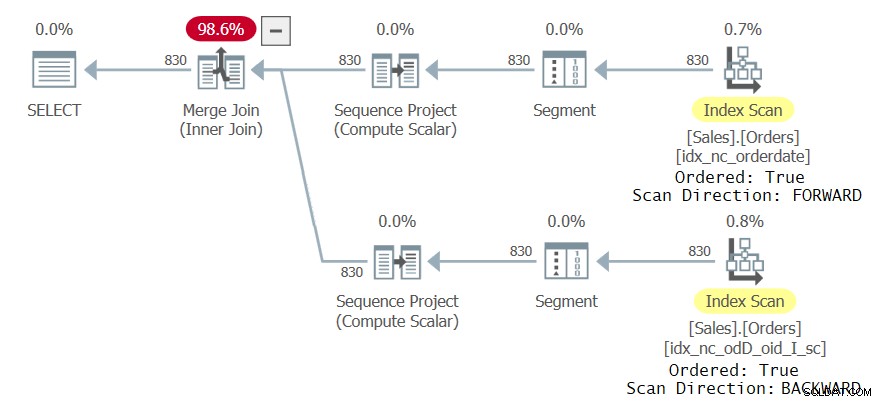 Figur 3:Andra plan för fråga med två CTE-referenser
Figur 3:Andra plan för fråga med två CTE-referenser MED C AS( SELECT *, ROW_NUMBER() ÖVER(ORDER BY orderdate, orderid) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;
orderid shipcountry orderid------------ --------------------- -----------(0 rader påverkade)
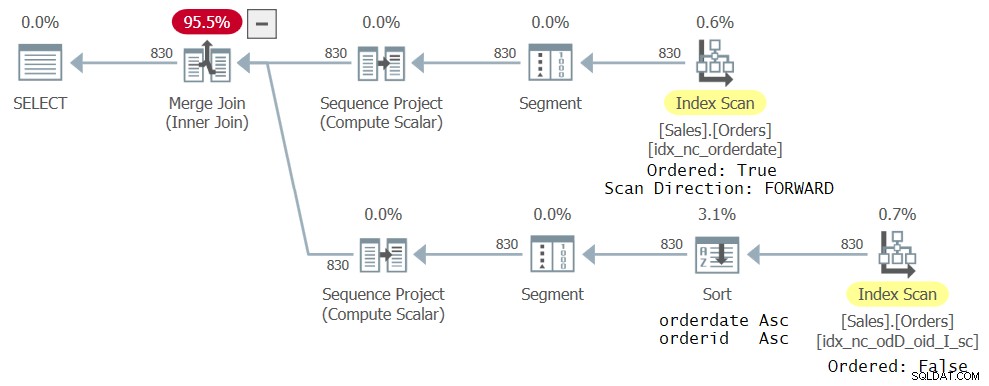 Figur 4:Tredje plan för fråga med två CTE-referenser
Figur 4:Tredje plan för fråga med två CTE-referenser SLÄPP INDEX OM FINNS idx_nc_odD_oid_I_sc PÅ Försäljningsbeställningar;
Slutsats