Gästförfattare:Monica Rathbun (@SQLEspresso)
Ibland kan problem med hårdvaruprestanda, som Disk I/O-latens, koka ner till icke-optimerad arbetsbelastning snarare än underpresterande hårdvara. Många databasadministratörer, inklusive jag, vill omedelbart skylla på lagringen för långsamheten. Innan du går och spenderar massor av pengar på ny hårdvara bör du alltid undersöka din arbetsbelastning för onödiga I/O.
Saker att undersöka
| Artikel | I/O-effekt | Möjliga lösningar |
|---|---|---|
| Oanvända index | Extra skrivningar | Ta bort/inaktivera index |
| Saknade index | Extra läsningar | Lägg till index/täckande index |
| Implicita omvandlingar | Extra läsningar och skrivningar | Hemligt eller kastat fält vid källan innan värdet utvärderas |
| Funktioner | Extra läsningar och skrivningar | Tog bort dem, konvertera data före utvärdering |
| ETL | Extra läsningar och skrivningar | Använd SSIS, Replikering, Change Data Capture, Tillgänglighetsgrupper |
| Order &Group Bys | Extra läsningar och skrivningar | Ta bort dem där det är möjligt |
Oanvända index
Vi känner alla till kraften i ett index. Att ha rätt index kan göra ljusår av skillnad i frågehastighet. Men hur många av oss upprätthåller kontinuerligt våra index utöver indexombyggnad och omorganiseringar? Det är viktigt att regelbundet köra ett indexskript för att utvärdera vilka index som faktiskt används. Jag använder personligen Glenn Berrys diagnostiska frågor för att göra detta.
Du kommer att bli förvånad över att upptäcka att några av dina index inte har lästs alls. Dessa index är en påfrestning på resurser, särskilt på en mycket transaktionstabell. När du tittar på resultaten, var uppmärksam på de index som har ett högt antal skrivningar i kombination med ett lågt antal läsningar. I det här exemplet kan du se att jag slösar bort skrivningar. Det icke-klustrade indexet har skrivits till 11 miljoner gånger, men bara läst två gånger.

Jag börjar med att inaktivera indexen som faller inom denna kategori och släpper dem sedan efter att jag har bekräftat att inga problem har uppstått. Att göra den här övningen rutinmässigt kan avsevärt minska onödiga I/O-skrivningar till ditt system, men kom ihåg att användningsstatistiken på dina index bara är lika bra som den senaste omstarten, så se till att du har samlat in data under en hel konjunkturcykel innan du skriver av ett index som "värdelöst".
Saknade index
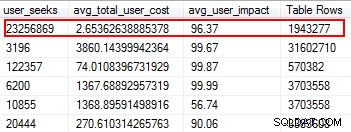
Saknade index är en av de enklaste sakerna att fixa; trots allt, när du kör en exekveringsplan kommer den att berätta om några index inte hittades men det skulle ha varit användbart. Men vänta, jag hoppas att du inte bara godtyckligt lägger till index baserat på detta förslag. Att göra detta kan skapa dubbletter av index, och index som kan ha minimal användning, och därför slösa I/O. Återigen, tillbaka till Glenns skript, ger han oss ett bra verktyg för att utvärdera användbarheten av ett index genom att tillhandahålla användarsökningar, användarpåverkan och antal rader. Var uppmärksam på dem med hög läsning tillsammans med låg kostnad och effekt. Det här är ett bra ställe att börja och hjälper dig att minska läs-I/O.
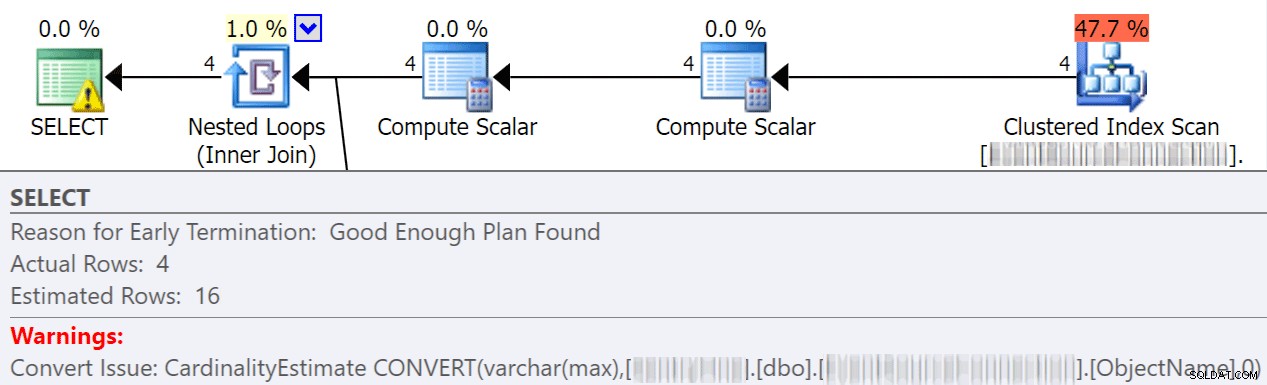
Implicita omvandlingar
Implicita konverteringar sker ofta när en fråga jämför två eller flera kolumner med olika datatyper. I exemplet nedan måste systemet utföra extra I/O för att jämföra en varchar(max)-kolumn med en nvarchar(4000)-kolumn, vilket leder till en implicit konvertering och i slutändan en skanning istället för en sökning. Genom att fixa tabellerna så att de har matchande datatyper, eller helt enkelt konvertera detta värde före utvärdering, kan du avsevärt minska I/O och förbättra kardinalitet (de beräknade rader som optimeraren bör förvänta sig).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias går in mycket mer i detalj i det här fantastiska inlägget:"Hur dyra är implicita konverteringar på kolumnsidan?"
Funktioner
En av de mest undvikbara, lätta att fixa sakerna jag har stött på som sparar på I/O-kostnader är att ta bort funktioner från where-klausuler. Ett perfekt exempel är en datumjämförelse, som visas nedan.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Oavsett om det är på en JOIN-sats eller i en WHERE-sats gör detta att varje kolumn konverteras innan den utvärderas. Genom att helt enkelt konvertera dessa kolumner före utvärdering till en tillfällig tabell kan du eliminera massor av onödiga I/O.
Eller, ännu bättre, utför inga konverteringar alls (för det här specifika fallet talar Aaron Bertrand här om att undvika funktioner i where-satsen, och notera att detta fortfarande kan vara dåligt även om det går att konvertera till datum).
ETL
Ta dig tid att undersöka hur din data laddas. Stympar och laddar du om bord? Kan du implementera replikering, en skrivskyddad AG-replika, eller logga leverans istället? Är alla tabeller skrivna för att verkligen läsas? Hur laddar du upp data? Är det genom lagrade procedurer eller SSIS? Att undersöka saker som detta kan minska I/O dramatiskt.
I min miljö upptäckte jag att vi trunkerade 48 tabeller dagligen med över 120 miljoner rader varje morgon. Utöver det laddade vi 9,6 miljoner rader per timme. Du kan föreställa dig hur mycket onödig I/O det skapade. I mitt fall var implementering av transaktionsreplikering min vallösning. När de väl implementerats hade vi mycket färre klagomål från användarna om avmattningar under våra laddningstider, vilket ursprungligen hade tillskrivits den långsamma lagringen.
Beställ efter &Gruppera efter
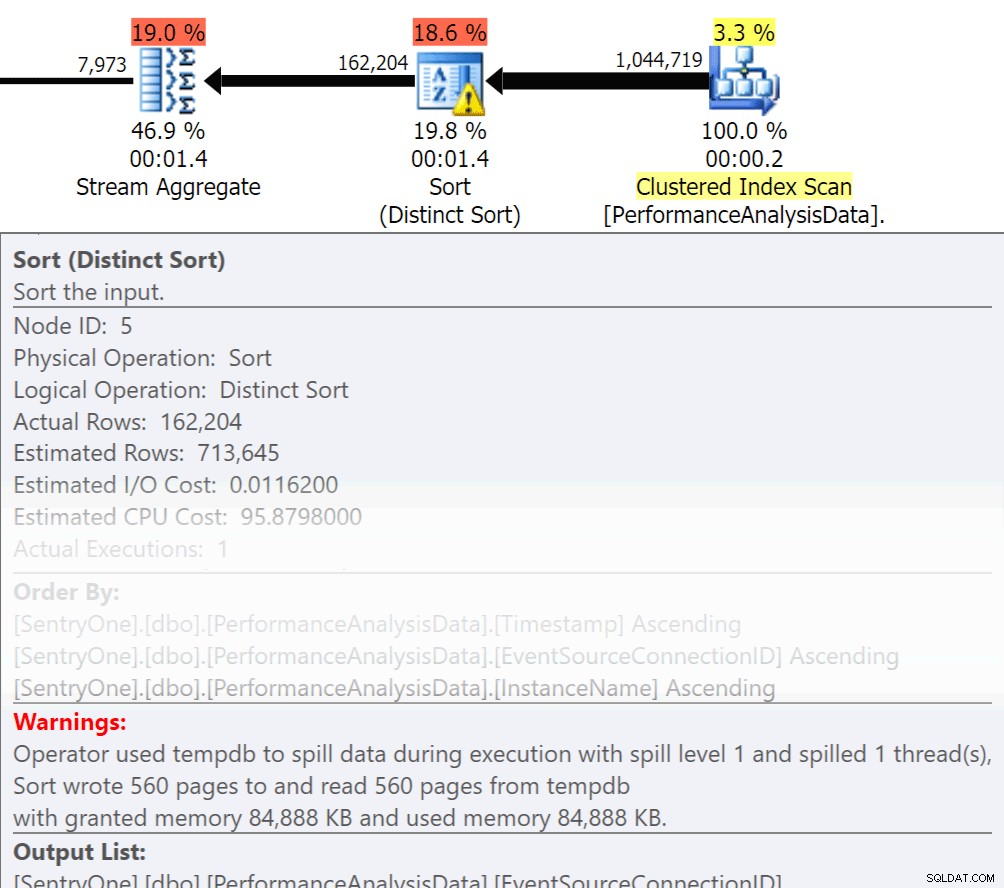 Fråga dig själv, måste den informationen returneras i ordning? Behöver vi verkligen gruppera oss i förfarandet, eller kan vi hantera det i en anmälan eller ansökan? Order By och Group By operationer kan göra att läsningar spills över till disken, vilket orsakar ytterligare disk I/O. Om dessa åtgärder är motiverade, se till att du har stödjande index och färsk statistik över kolumnerna som sorteras eller grupperas. Detta kommer att hjälpa optimeraren under planskapandet. Eftersom vi ibland använder Order By och Group By i temporära tabeller. se till att du har Auto Skapa statistik på för TEMPDB såväl som dina användardatabaser. Ju mer uppdaterad statistiken är, desto bättre kardinalitet kan optimeraren få, vilket resulterar i bättre planer, mindre spill-over och mindre I/O.
Fråga dig själv, måste den informationen returneras i ordning? Behöver vi verkligen gruppera oss i förfarandet, eller kan vi hantera det i en anmälan eller ansökan? Order By och Group By operationer kan göra att läsningar spills över till disken, vilket orsakar ytterligare disk I/O. Om dessa åtgärder är motiverade, se till att du har stödjande index och färsk statistik över kolumnerna som sorteras eller grupperas. Detta kommer att hjälpa optimeraren under planskapandet. Eftersom vi ibland använder Order By och Group By i temporära tabeller. se till att du har Auto Skapa statistik på för TEMPDB såväl som dina användardatabaser. Ju mer uppdaterad statistiken är, desto bättre kardinalitet kan optimeraren få, vilket resulterar i bättre planer, mindre spill-over och mindre I/O.
Nu har Group By definitivt sin plats när det gäller att aggregera data istället för att returnera massor av rader. Men nyckeln här är att minska I/O, tillägget av aggregeringen läggs till I/O.
Sammanfattning
Det här är bara toppen av isberget av saker att göra, men ett bra ställe att börja för att minska I/O. Innan du skyller hårdvaran på dina latensproblem, ta en titt på vad du kan göra för att minimera disktrycket.
Om författaren
 Monica Rathbun är för närvarande konsult på Denny Cherry &Associates Consulting och en Microsoft Data Platform MVP. Hon har varit ensam DBA i 15 år och arbetat med alla aspekter av SQL Server och Oracle. Hon reser och talar på SQLSaturdays och hjälper andra Lone DBA:er med tekniker om hur man kan göra mångas jobb. Monica är ledare för Hampton Roads SQL Server User Group och är en Mid-Atlantic Pass Regional Mentor. Du kan alltid hitta Monica på Twitter (@SQLEspresso) som delar ut användbara tips och tricks till sina följare. När hon inte är upptagen med jobbet, kommer du att hitta henne lekande taxichaufför för sina två döttrar fram och tillbaka till dansklasser.
Monica Rathbun är för närvarande konsult på Denny Cherry &Associates Consulting och en Microsoft Data Platform MVP. Hon har varit ensam DBA i 15 år och arbetat med alla aspekter av SQL Server och Oracle. Hon reser och talar på SQLSaturdays och hjälper andra Lone DBA:er med tekniker om hur man kan göra mångas jobb. Monica är ledare för Hampton Roads SQL Server User Group och är en Mid-Atlantic Pass Regional Mentor. Du kan alltid hitta Monica på Twitter (@SQLEspresso) som delar ut användbara tips och tricks till sina följare. När hon inte är upptagen med jobbet, kommer du att hitta henne lekande taxichaufför för sina två döttrar fram och tillbaka till dansklasser.