Förra året bloggade Andy Mallon om att utöka en kolumn från int till bigint utan stillestånd. (Varför detta inte är en operation som endast är metadata i moderna versioner av SQL Server är förståndig, men det är ett annat inlägg.)
Vanligtvis när vi hanterar det här problemet är de breda och massiva tabeller (både i radantal och ren storlek), och kolumnen vi behöver ändra är den enda/ledande kolumnen i klustringsnyckeln. Det finns vanligtvis andra komplikationer också inblandade – inkommande främmande nyckelbegränsningar, massor av icke-klustrade index och en upptagen databas som är extremt känslig för loggaktivitet (eftersom den är involverad i ändringsspårning, replikering, tillgänglighetsgrupper eller alla tre ).
Av denna anledning måste vi ta ett tillvägagångssätt som Andy beskrev, där vi bygger en skuggtabell med det nya schemat, skapar triggers för att hålla båda kopiorna synkroniserade och sedan batchar/återfyller i det lagets egen takt tills de är redo att byta i kopian som den verkliga affären.
Men jag är lat!
Det finns vissa fall där du kan byta kolumn direkt, om du har råd med ett litet fönster med stillestånd/blockering, och det blir en mycket enklare operation. Förra veckan dök ett sådant fall upp, med en tabell över 1 TB, men bara 100 000 rader. Nästan all data var off-row (LOB), de hade råd med ett litet fönster av driftstopp om det behövdes, och de planerade att inaktivera ändringsspårning och konfigurera om det ändå. Jag var säker på att återskapandet av den klustrade PK:n inte skulle behöva röra LOB-data (mycket), föreslog jag att detta kan vara ett fall där vi bara kan tillämpa ändringen direkt.
I ett isolerat scenario (inga inkommande främmande nycklar, inga ytterligare index, inga aktiviteter beroende på loggläsaren och inga farhågor om samtidighet) satte jag ihop några tester för att i ett vakuum se vad denna förändring skulle kräva i termer av varaktighet och påverka transaktionsloggen. Huvudfrågan som jag inte visste hur jag skulle svara på i förväg var:"Vad är den inkrementella kostnaden för att uppdatera tabeller på plats när det finns stora mängder icke-nyckeldata?"
Jag ska försöka packa ihop mycket i ett inlägg här. Jag testade en hel del, och allt är relaterat, även om inte alla testscenarier gäller dig. Snälla stå ut med mig.
Tabellerna
Jag skapade 6 tabeller, inklusive en baslinje som endast hade nyckelkolumnen, en tabell med 4K lagrade i rad och sedan fyra tabeller vardera med en varchar(max)-kolumn fylld med varierande mängder strängdata (4K, 16K, 64K och 256K).
CREATE TABLE dbo.withJustId( id int NOT NULL, CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withoutLob( id int NOT NULL, extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob004( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob016( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)), CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob064 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)), CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob256 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)), CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id));
Jag fyllde var och en med 100 000 rader:
INSERT dbo.withJustId (id) SELECT TOP (100000) id =ROW_NUMBER() OVER (ORDER BY c1.name) FRÅN sys.all_columns SOM c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLobSELECT064 id FROM dbo.withJustId;INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Jag erkänner att ovanstående är orealistiskt; hur ofta har vi en tabell som bara är en identifierare + LOB-data? Jag körde testerna igen med dessa ytterligare fyra kolumner för att ge sidorna med icke-LOB-data lite mer verklig substans:
fill1 char(320) NOT NULL DEFAULT ('x'), count1 int NOT NULL DEFAULT (0), count2 int NOT NULL DEFAULT (0), dt datetime2 NOT NULL DEFAULT sysutcdatetime(),
Dessa tabeller är bara något större i termer av total storlek, men den proportionella ökningen av mängden icke-LOB-data (ej illustrerad i det här diagrammet) är den stora men dolda skillnaden:
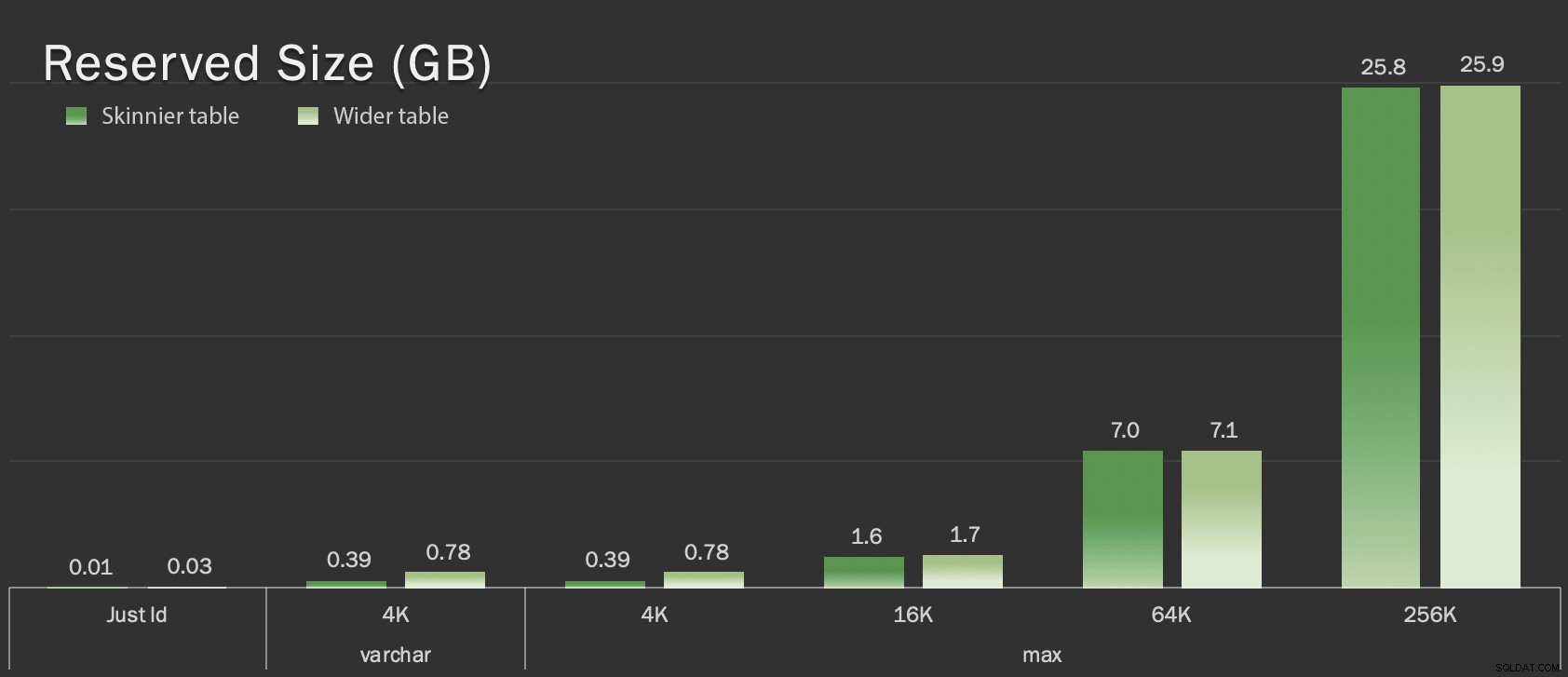 Reserverad storlek på tabeller, i GB
Reserverad storlek på tabeller, i GB
Testen
Sedan tog jag tid och samlade in loggdata för var och en av dessa operationer (med och utan ONLINE = ON ) mot varje variant av tabellen:
ALTER TABLE dbo. DROP CONSTRAINT pk_; ALTER TABLE dbo. ALTER COLUMN id bigint NOT NULL; -- MED (ONLINE =PÅ); ALTER TABLE dbo. LÄGG TILL BEGRÄNSNING pk_ PRIMÄRNYCKEL CLUSTERED (id);
I verkligheten använde jag dynamisk SQL för att generera alla dessa tester, så att jag inte pillade manuellt med skript före varje test.
I ett annat inlägg kommer jag att dela den dynamiska SQL som jag använde för att generera dessa tester och samla in tidpunkterna för varje steg.
Som jämförelse testade jag också Andys metod (om än utan batchning, och bara på den smala versionen av bordet):
SKAPA TABELL dbo._copy ( id bigint NOT NULL -- <, extradata kolumn när det är relevant> CONSTRAINT pk_copy_ PRIMÄRNYCKEL CLUSTERED (id)); INSERT dbo._copy SELECT * FROM dbo.; EXEC sys.sp_rename N'dbo.', N'dbo._old', N'OBJECT';EXEC sys.sp_rename N'dbo._copy', N'dbo.' , N'OBJECT';
Jag hoppade över de bredare tabellerna här; Jag ville inte introducera komplexiteten i att koda och mäta batchoperationer. Den uppenbara smärtpunkten här är att, till skillnad från att ändra kolumnen på plats, med skuggmetoden måste du kopiera varje enskild byte av den LOB-datan. Batchning kan minimera den stora effekten av att försöka göra det i en enda transaktion, men all den blandningen kommer så småningom att behöva göras om nedströms. Batchning vid källan kan inte helt kontrollera hur mycket det kommer att göra ont vid destinationen.
Resultaten
De första resultaten jag kommer att visa är bara den genomsnittliga varaktigheten för ändringar på plats, för alla 12 tabellkonfigurationer och med och utan ONLINE = ON :
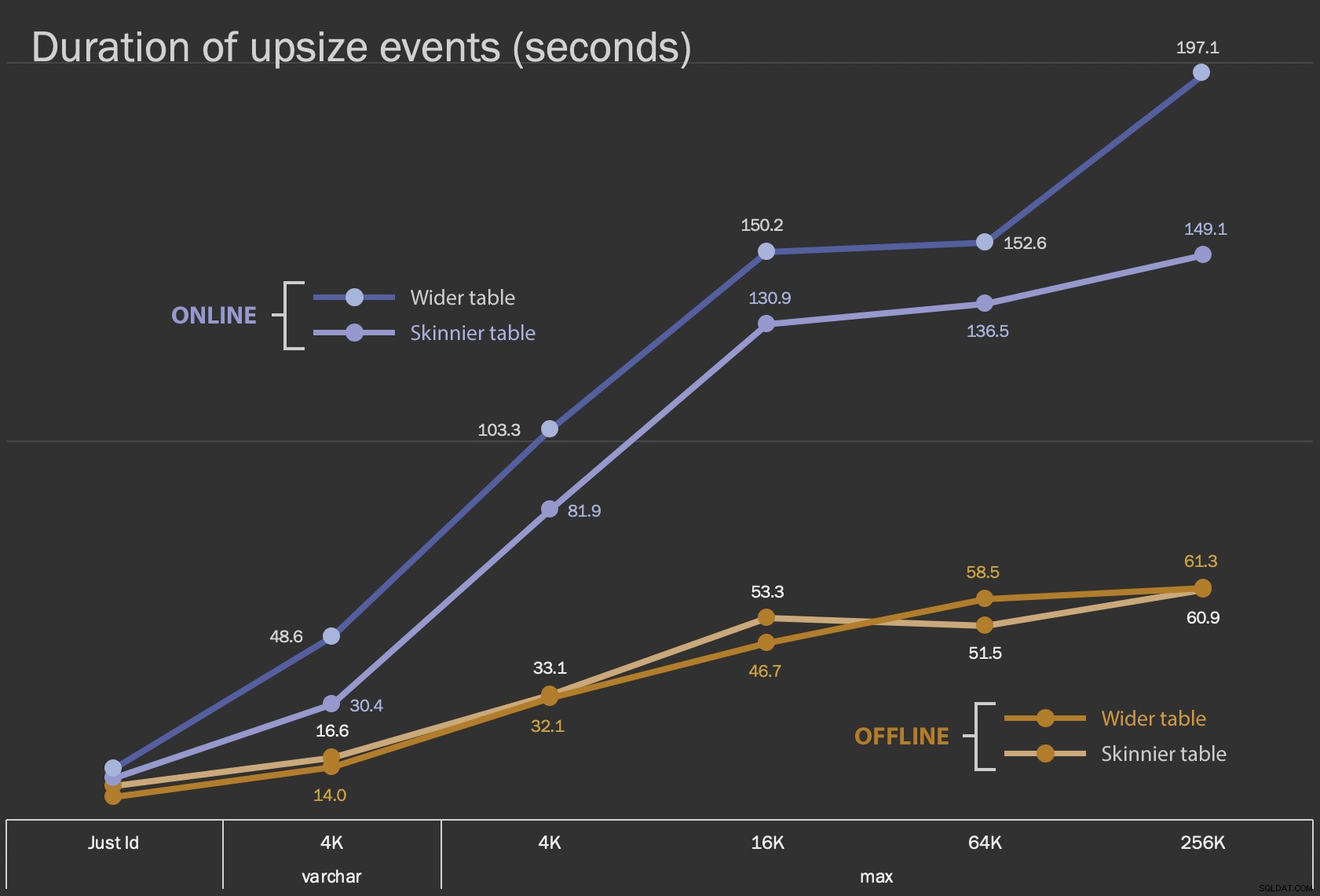 Längd, i sekunder, för att ändra kolumnen på plats
Längd, i sekunder, för att ändra kolumnen på plats
Att utföra detta som en onlineoperation tar längre tid (200 sekunder i värsta fall), men blockerar inte användare. Det verkar öka tillsammans med storleken, men inte helt linjärt. Att utföra den här operationen offline orsakar blockering, men är mycket snabbare och förändras inte lika drastiskt när bordet blir större (även i den största storleken hände detta fortfarande på ungefär en minut).
Att jämföra dessa operationer på plats med byte och släpp-operationer är svårt att använda ett linjediagram på grund av den enorma skillnaden i skala. Istället ska jag visa ett horisontellt stapeldiagram för den tid som är involverad i varje tabellkonfiguration. När återskapandet går snabbare kommer jag att måla den radens bakgrund grön; när det är långsammare (eller faller mellan offline- och onlinemetoden) behöver jag förmodligen inte göra det, men jag målar den radens bakgrund röd.
| LOB-storlek | Tillvägagångssätt | Tabellkonfiguration | Längd (sekunder) | ||
|---|---|---|---|
| Bara ID | ALTER Offline | Smalare bord (10 MB) | 8.8 |
| Bredare tabell (30 MB) | 6.3 | ||
| ALTER Online | Smalare bord | 11.0 | |
| Bredare tabell | 13.6 | ||
| Återskapa | Smalare bord | 3.4 | |
| varchar 4K | Offline | Smalare bord (390 MB) | 16.6 |
| Bredare tabell (780 MB) | 14.0 | ||
| Online | Smalare bord | 30.4 | |
| Bredare tabell | 48.6 | ||
| Återskapa | Smalare bord | 1 290,0 | |
| max 4k | Offline | Smalare bord (390 MB) | 33.1 |
| Bredare tabell (780 MB) | 32.1 | ||
| Online | Smalare bord | 81.9 | |
| Bredare tabell | 103.3 | ||
| Återskapa | Smalare bord | 28.9 | |
| max 16k | Offline | Smalare bord (1,6 GB) | 53.3 |
| Bredare bord (1,7 GB) | 46.7 | ||
| Online | Smalare bord | 130.9 | |
| Bredare tabell | 150.2 | ||
| Återskapa | Smalare bord | 81.8 | |
| max 64k | Offline | Smalare bord (7,0 GB) | 51.5 |
| Bredare bord (7,1 GB) | 58.5 | ||
| Online | Smalare bord | 136.5 | |
| Bredare tabell | 152.6 | ||
| Återskapa | Smalare bord | 226.5 | |
| max 256k | Offline | Smalare bord (25,8 GB) | 60.9 |
| Bredare bord (25,9 GB) | 61.3 | ||
| Online | Smalare bord | 149.1 | |
| Bredare tabell | 197.1 | ||
| Återskapa | Smalare bord | 1 576,7 | |
Det här är en orättvis skakning av Andys metod, eftersom du – i den verkliga världen – inte skulle utföra hela operationen i ett skott. Jag visade inte transaktionslogganvändning här för korthetens skull, men det skulle vara enklare att kontrollera det genom att batchera i en sida vid sida-operation också. Även om hans tillvägagångssätt kräver mer arbete i förväg, är det mycket säkrare när det gäller driftstopp och/eller blockering. Men du kan se i fall där du har mycket data utanför rad och har råd med ett kort avbrott, att det är mycket mindre smärtsamt att ändra kolumnen direkt. "Too large to change in-place" är subjektivt och kan ge olika resultat beroende på vad "stor" betyder. Innan du bestämmer dig för ett tillvägagångssätt kan det vara meningsfullt att testa förändringen mot en rimlig kopia, eftersom operationen på plats kan representera en acceptabel kompromiss.
Slutsats
Jag skrev inte detta för att argumentera med Andy. Tillvägagångssättet i det ursprungliga inlägget är sunt, 100 % tillförlitligt, och vi använder det hela tiden. När brute force värderas framför kirurgisk precision, dock, och särskilt om du kan ta en del stillestånd, kan det finnas värde i det enklare tillvägagångssättet för vissa bordsformer.