Jag fick nyligen en e-postfråga från någon i gruppen om CLR_MANUAL_EVENT väntetyp; specifikt, hur man felsöker problem med att denna väntetid plötsligt blir utbredd för en befintlig arbetsbelastning som till stor del förlitade sig på rumsliga datatyper och frågor med de rumsliga metoderna i SQL Server.
Som konsult är min första fråga nästan alltid:"Vad har förändrats?" Men i det här fallet, som i så många fall, var jag säker på att ingenting hade förändrats med programmets kod eller arbetsbelastningsmönster. Så mitt första stopp var att dra upp CLR_MANUAL_EVENT vänta i SQLskills.com Wait Types Library för att se vilken annan information vi redan hade samlat in om denna väntetyp, eftersom det vanligtvis inte är en väntan som jag ser problem med i SQL Server. Det jag tyckte var riktigt intressant var diagrammet/värmekartan över händelser för denna väntetyp som tillhandahålls av SentryOne överst på sidan:
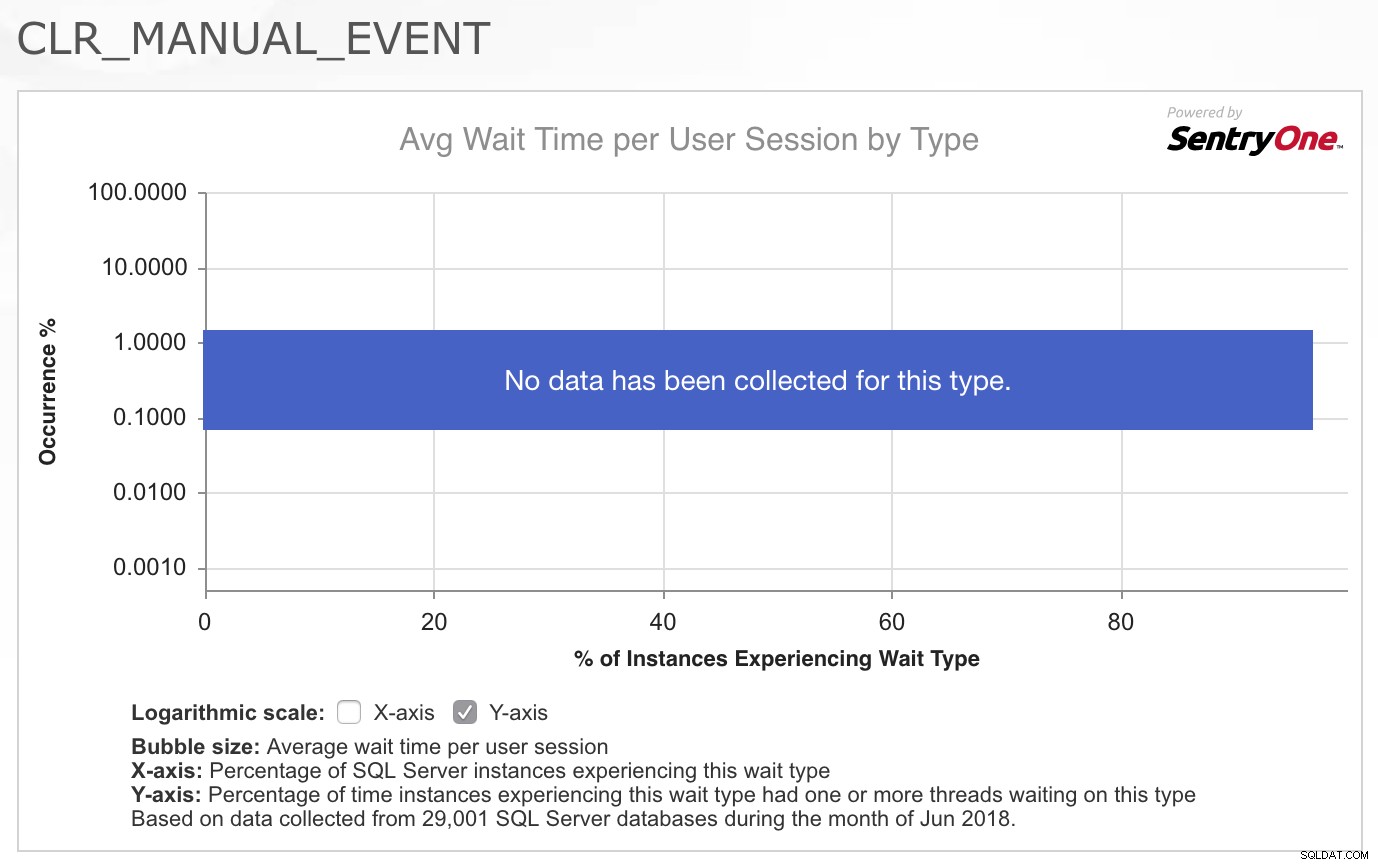
Det faktum att ingen data har samlats in för denna typ genom ett bra tvärsnitt av deras kunder bekräftade verkligen för mig att detta inte är något som vanligtvis är ett problem, så jag blev fascinerad av det faktum att denna specifika arbetsbelastning nu uppvisade problem med denna väntan. Jag var inte säker på vart jag skulle gå för att undersöka problemet ytterligare så jag svarade på e-postmeddelandet och sa att jag var ledsen att jag inte kunde hjälpa vidare eftersom jag inte hade någon aning om vad som skulle orsaka bokstavligen dussintals trådar som utför rumsliga frågor till börjar plötsligt behöva vänta i 2-4 sekunder åt gången på denna väntetyp.
En dag senare fick jag ett vänligt uppföljningsmejl från personen som ställde frågan som informerade mig om att de hade löst problemet. Faktum är att ingenting i den faktiska applikationens arbetsbelastning hade förändrats, men det skedde en förändring i miljön. Ett mjukvarupaket från tredje part installerades på alla servrar i deras infrastruktur av deras säkerhetsteam, och den här programvaran samlade in data med fem minuters intervall och fick .NET-skräphämtningsprocessen att köras otroligt aggressivt och "blev galen" som sa de. Beväpnad med denna information och en del av mina tidigare kunskaper om .NET-utveckling bestämde jag mig för att jag ville leka lite med detta och se om jag kunde återskapa beteendet och hur vi skulle kunna gå till väga för att felsöka orsakerna ytterligare.
Bakgrundsinformation
Under åren har jag alltid följt PSSQL-bloggen på MSDN, och det är vanligtvis en av mina platser när jag minns att jag har läst om ett problem relaterat till SQL Server någon gång i det förflutna men jag kan kommer inte ihåg alla detaljer.
Det finns ett blogginlägg med titeln Långa väntetider på CLR_MANUAL_EVENT och CLR_AUTO_EVENT av Jack Li från 2008 som förklarar varför dessa väntetider säkert kan ignoreras i den samlade sys.dm_os_wait_stats DMV eftersom väntetiderna inträffar under normala förhållanden, men det tar inte upp vad man ska göra om väntetiderna är för långa, eller vad som kan orsaka att de syns i flera trådar i sys.dm_os_waiting_tasks aktivt.
Det finns ett annat blogginlägg av Jack Li från 2013 med titeln Ett prestandaproblem som involverar CLR-sopsamling och SQL CPU-affinitetsinställning som jag hänvisar till i vår IEPTO2 prestandajusteringsklass när jag pratar om flera instansöverväganden och hur .NET Garbage Collector (GC) som triggas av en instans kan påverka de andra instanserna på samma server.
GC i .NET finns för att minska minnesanvändningen för applikationer som använder CLR genom att tillåta att minnet som allokerats till objekt rensas upp automatiskt, vilket eliminerar behovet för utvecklare att manuellt behöva hantera minnesallokering och -deallokering i den grad som krävs av ohanterad kod . GC-funktionaliteten finns dokumenterad i Books Online om du vill veta mer om hur det fungerar, men detaljerna utöver det faktum att samlingar kan blockeras är inte viktiga för att felsöka aktiva väntetider på CLR_MANUAL_EVENT i SQL Server vidare.
Kom till roten till problemet
Med vetskapen om att sophämtning av .NET var det som orsakade problemet, bestämde jag mig för att experimentera med en enda rumslig fråga mot AdventureWorks2016 och ett mycket enkelt PowerShell-skript för att anropa sopsamlaren manuellt i en loop för att spåra vad som händer i sys.dm_os_waiting_tasks inuti SQL Server för frågan:
USE AdventureWorks2016; GO SELECT a.SpatialLocation.ToString(), a.City, b.SpatialLocation.ToString(), b.City FROM Person.Address AS a INNER JOIN Person.Address AS b ON a.SpatialLocation.STDistance(b.SpatialLocation) <= 100 ORDER BY a.SpatialLocation.STDistance(b.SpatialLocation);
Den här frågan jämför alla adresser i Person.Address tabell mot varandra för att hitta en adress som ligger inom 100 meter från någon annan adress i tabellen. Detta skapar en långvarig parallell uppgift inuti SQL Server som också ger ett stort kartesiskt resultat. Om du bestämmer dig för att återskapa detta beteende på egen hand, förvänta dig inte att detta slutför eller returnerar resultat. När frågan körs börjar den överordnade tråden för uppgiften vänta på CXPACKET väntar och frågan fortsätter att bearbetas i flera minuter. Men det jag var intresserad av var vad som händer när sophämtning sker i CLR-körtiden eller om GC anropas så jag använde ett enkelt PowerShell-skript som skulle loopa och manuellt tvinga GC:n att köras.
OBS:DETTA ÄR INTE EN REKOMMENDERAD PRAXIS I PRODUKTIONSKOD AV MÅNGA SKÄL!
while (1 -eq 1) {[System.GC]::Collect() } När PowerShell-fönstret kördes började jag nästan omedelbart se CLR_MANUAL_EVENT väntar som inträffar på de parallella underuppgiftstrådarna (visas nedan, där exec_context_id är större än noll) i sys.dm_os_waiting_tasks :
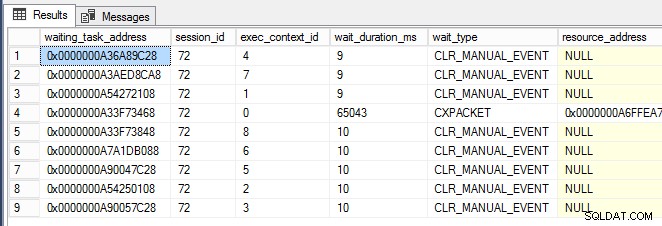
Nu när jag kunde utlösa det här beteendet och det började bli tydligt att SQL Server inte nödvändigtvis är problemet här och bara kan vara offer för annan aktivitet, ville jag veta hur man gräver djupare och lokaliserar grundorsaken till problemet . Det var här PerfMon kom väl till pass för att spåra .NET CLR-minnesräknargruppen för alla uppgifter på servern.
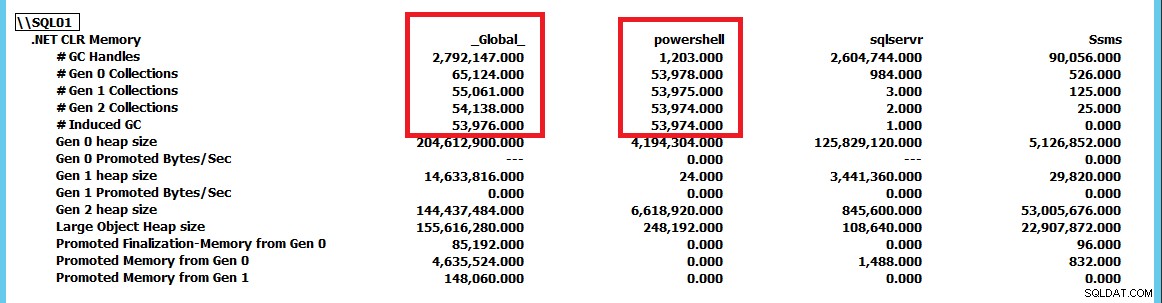
Den här skärmdumpen har förminskats för att visa samlingarna för sqlservr och powershell som applikationer jämfört med _Global_ samlingar av .NET runtime. Genom att tvinga GC.Collect() att köra konstant kan vi se att powershell instans driver GC-samlingarna på servern. Med hjälp av denna PerfMon-räknargrupp kan vi spåra vilka applikationer som utför flest insamlingar och därifrån fortsätta vidare utredning av problemet. I det här fallet eliminerar du CLR_MANUAL_EVENT genom att helt enkelt stoppa PowerShell-skriptet väntar inuti SQL Server och frågan fortsätter att bearbetas tills vi antingen stoppar den eller låter den returnera de miljarder rader med resultat som skulle matas ut av den.
Slutsats
Om du har aktiva väntan på CLR_MANUAL_EVENT orsakar programfördröjningar, anta inte automatiskt att problemet finns inuti SQL Server. SQL Server använder skräpinsamling på servernivå (åtminstone före SQL Server 2017 CU4 där små servrar med mindre än 2 GB RAM kan använda skräpinsamling på klientnivå för att minska resursanvändningen). Om du ser att det här problemet uppstår i SQL Server, använd .NET CLR-minnesräknargruppen i PerfMon och kontrollera om en annan applikation driver sophämtning i CLR och blockerar CLR-uppgifterna internt i SQL Server som ett resultat.