Jag tror att alla redan känner till mina åsikter om MERGE och varför jag håller mig borta från det. Men här är ett annat (anti-)mönster som jag ser överallt när folk vill utföra en upsert (uppdatera en rad om den finns och infoga den om den inte gör det):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Det här ser ut som ett ganska logiskt flöde som återspeglar hur vi tänker om detta i verkligheten:
- Finns det redan en rad för den här nyckeln?
- JA :OK, uppdatera den raden.
- NEJ :OK, lägg sedan till det.
Men det här är slöseri.
Att hitta raden för att bekräfta att den finns, bara för att behöva hitta den igen för att uppdatera den, gör dubbelt så mycket. för ingenting. Även om nyckeln är indexerad (vilket jag hoppas alltid är fallet). Om jag lägger in denna logik i ett flödesschema och associerar, vid varje steg, den typ av operation som skulle behöva ske i databasen, skulle jag ha detta:
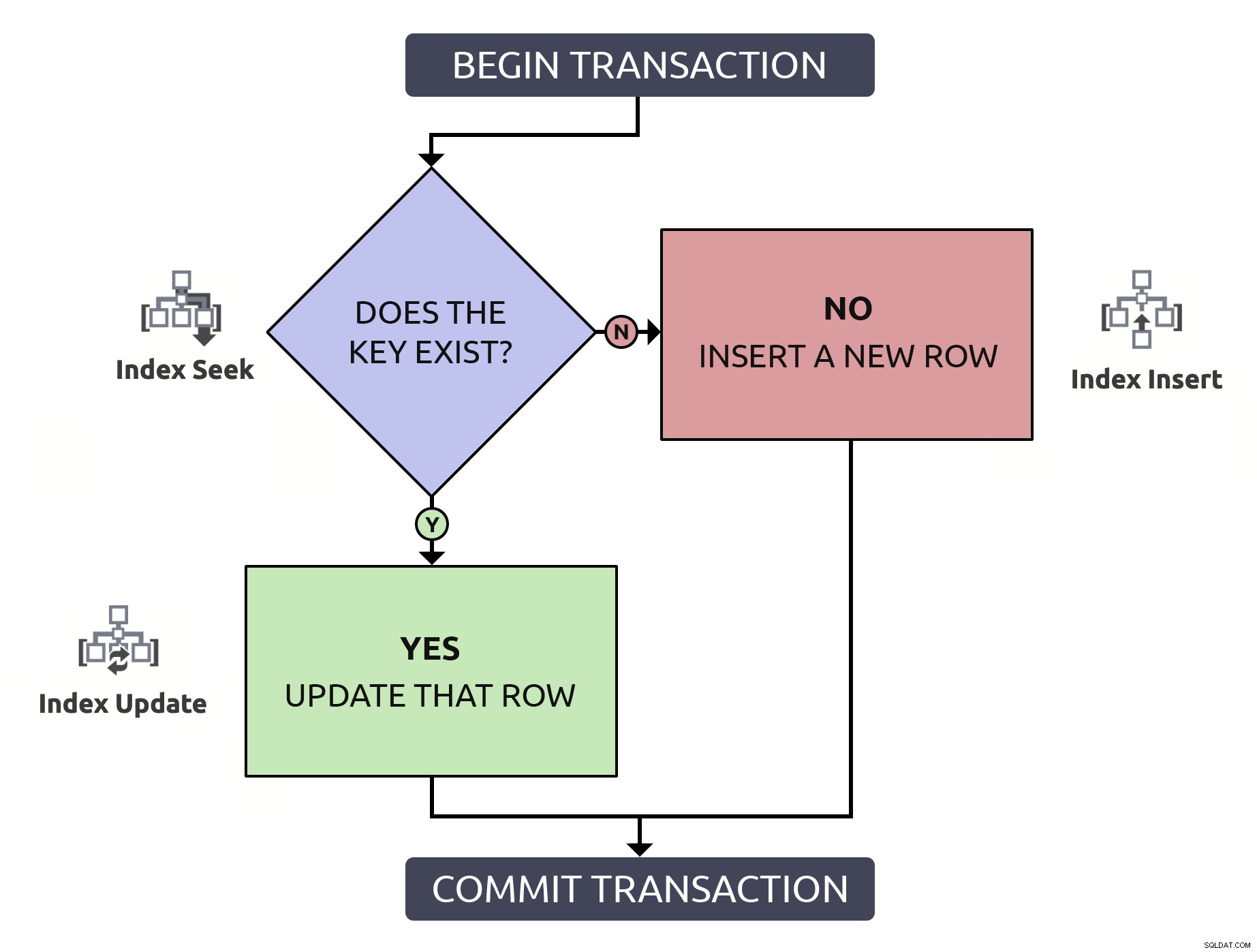 Observera att alla sökvägar kommer att medföra två indexoperationer.
Observera att alla sökvägar kommer att medföra två indexoperationer.
Ännu viktigare, förutom prestanda, om du inte både använder en explicit transaktion och höjer isoleringsnivån, kan flera saker gå fel när raden inte redan finns:
- Om nyckeln finns och två sessioner försöker uppdatera samtidigt, kommer de båda att uppdateras (en kommer att "vinna"; "förloraren" kommer att följa med ändringen som fastnar, vilket leder till en "förlorad uppdatering"). Det här är inte ett problem i sig, och det är så vi bör förväntar sig att ett system med samtidighet fungerar. Paul White berättar mer om den interna mekaniken här, och Martin Smith talar om några andra nyanser här.
- Om nyckeln inte finns, men båda sessionerna klarar existenskontrollen på samma sätt, kan allt hända när de båda försöker infoga:
- stoppläge på grund av inkompatibla lås;
- höja nyckelöverträdelsefel det borde inte ha hänt; eller,
- infoga dubbletter av nyckelvärden om den kolumnen inte är korrekt begränsad.
Den sista är den värsta, IMHO, eftersom det är den som potentiellt förstör data . dödlägen och undantag kan hanteras enkelt med saker som felhantering, XACT_ABORT , och försök igen logik, beroende på hur ofta du förväntar dig kollisioner. Men om du vaggas in i en känsla av säkerhet att OM FINNS check skyddar dig från dubbletter (eller nyckelöverträdelser), det är en överraskning som väntar på att hända. Om du förväntar dig att en kolumn ska fungera som en nyckel, gör den officiell och lägg till en begränsning.
"Många människor säger..."
Dan Guzman pratade om tävlingsförhållandena för mer än ett decennium sedan i Conditional INSERT/UPDATE Race Condition och senare i "UPSERT" Race Condition With MERGE.
Michael Swart har också behandlat detta ämne flera gånger:
- Mythbusting:Concurrent Update/Insert Solutions – där han erkände att att lämna den ursprungliga logiken på plats och bara höja isoleringsnivån bara ändrade nyckelöverträdelser till dödlägen;
- Var försiktig med Merge Statement – där han kontrollerade sin entusiasm över
MERGE; och, - Vad du ska undvika om du vill använda MERGE – där han återigen bekräftade att det fortfarande finns gott om giltiga skäl att fortsätta undvika
MERGE.
Se till att du läser alla kommentarer på alla tre inläggen också.
Lösningen
Jag har fixat många dödlägen i min karriär genom att helt enkelt justera till följande mönster (gå bort den överflödiga kontrollen, slå in sekvensen i en transaktion och skydda den första bordets åtkomst med lämplig låsning):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Varför behöver vi två tips? Är inte UPDLOCK tillräckligt?
UPDLOCKanvänds för att skydda mot låsta konverteringar vid påståendet nivå (låt en annan session vänta istället för att uppmuntra ett offer att försöka igen).SERIALISERBARanvänds för att skydda mot ändringar av underliggande data under hela transaktionen (se till att en rad som inte finns fortsätter att inte existera).
Det är lite mer kod, men det är 1000 % säkrare och även i de värsta case (raden finns inte redan) fungerar den på samma sätt som anti-mönstret. I bästa fall, om du uppdaterar en rad som redan finns, blir det mer effektivt att bara hitta den raden en gång. Genom att kombinera denna logik med de operationer på hög nivå som skulle behöva ske i databasen, är det något enklare:
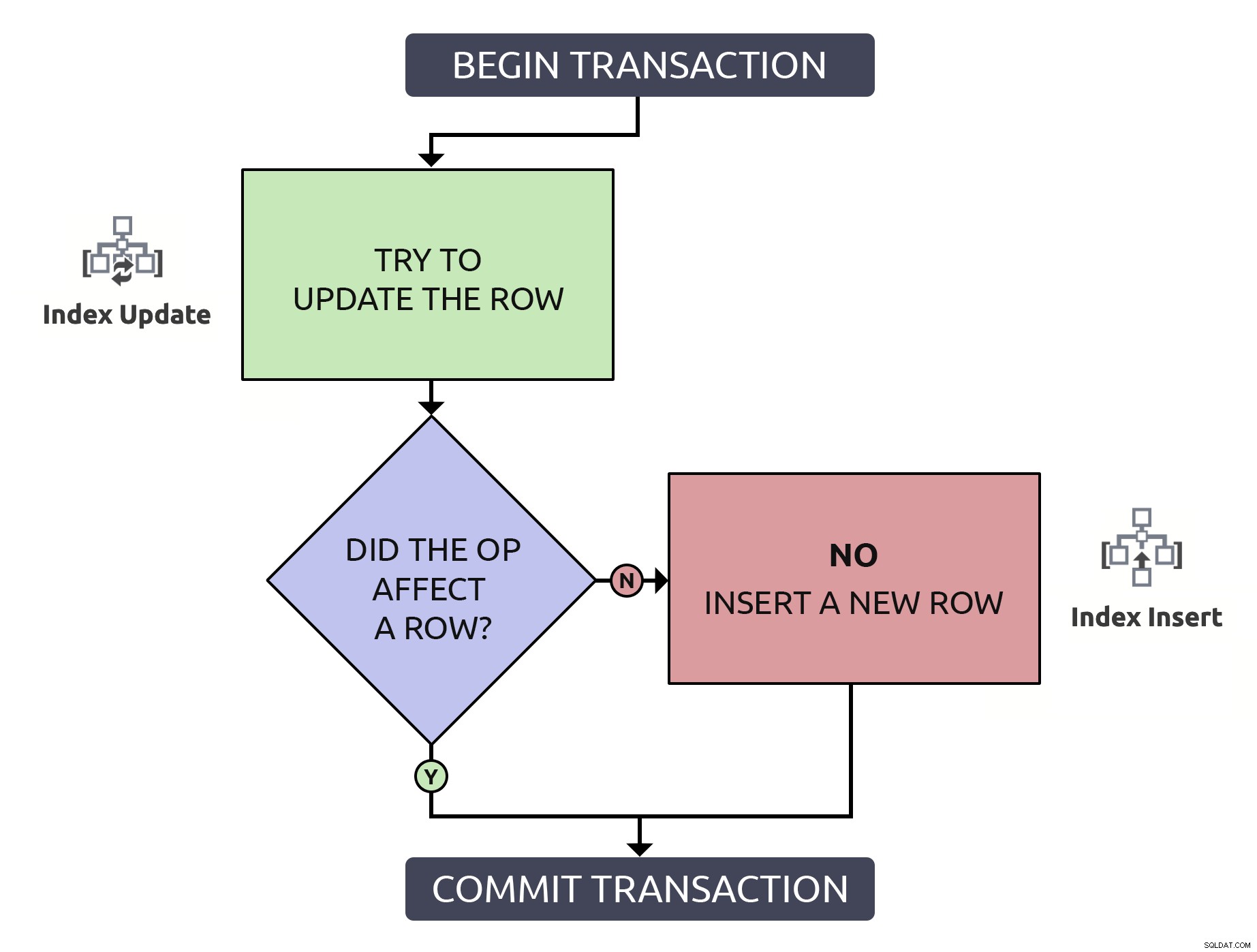 I det här fallet medför en sökväg endast en enda indexoperation.
I det här fallet medför en sökväg endast en enda indexoperation.
Men återigen, prestanda åt sidan:
- Om nyckeln finns och två sessioner försöker uppdatera den samtidigt, kommer de båda turas om och uppdatera raden framgångsrikt , som tidigare.
- Om nyckeln inte finns, kommer en session att "vinna" och infoga raden . Den andra måste vänta tills låsen släpps för att ens kontrollera om det finns, och tvingas uppdatera.
I båda fallen förlorar författaren som vann loppet sin data till allt som "förloraren" uppdaterade efter dem.
Observera att den totala genomströmningen på ett mycket samtidigt system kan lida, men det är en avvägning du bör vara villig att göra. Att du får massor av dödlägesoffer eller nyckelöverträdelsefel, men de sker snabbt, är inte ett bra resultatmått. Vissa människor skulle älska att se all blockering borttagen från alla scenarier, men en del av det är blockering som du absolut vill ha för dataintegritet.
Men vad händer om en uppdatering är mindre trolig?
Det är tydligt att ovanstående lösning optimerar för uppdateringar och antar att en nyckel som du försöker skriva till redan kommer att finnas i tabellen minst lika ofta som den inte gör det. Om du hellre föredrar att optimera för infogning, vet eller gissar att det är mer sannolikt att inlägg kommer att vara mer sannolikt än uppdateringar, kan du vända på logiken och fortfarande ha en säker upsert-operation:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Det finns också "bara gör det"-metoden, där du blindt infogar och låter kollisioner leda till undantag för den som ringer:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Kostnaden för dessa undantag uppväger ofta kostnaden för att kontrollera först; du måste prova det med en ungefärlig gissning av träff/missfrekvens. Jag skrev om detta här och här.
Vad sägs om att flytta upp flera rader?
Ovanstående handlar om beslut om enstaka infogning/uppdatering, men Justin Pealing frågade vad du ska göra när du bearbetar flera rader utan att veta vilken av dem som redan finns?
Om du antar att du skickar en uppsättning rader genom att använda något som en tabellvärderad parameter, skulle du uppdatera med en join och sedan infoga med att använda INTE FINNS, men mönstret skulle fortfarande vara likvärdigt med den första metoden ovan:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Om du får ihop flera rader på något annat sätt än en TVP (XML, kommaseparerad lista, voodoo), placera dem i en tabellform först och gå med i vad det nu är. Var noga med att inte optimera för inlägg först i det här scenariot, annars kommer du eventuellt att uppdatera vissa rader två gånger.
Slutsats
Dessa upsert-mönster är överlägsna de jag ser alltför ofta, och jag hoppas att du börjar använda dem. Jag kommer att peka på det här inlägget varje gång jag ser
Och om du känner att du måste använd MERGE , snälla, snälla inte @ mig; antingen har du en bra anledning (kanske behöver du någon obskyr MERGE). -endast funktionalitet), eller så tog du inte länkarna ovan på allvar.