Den här artikeln är den femte delen i en serie om tabelluttryck. I del 1 gav jag bakgrunden till tabelluttryck. I del 2, del 3 och del 4 täckte jag både de logiska och optimeringsaspekterna av härledda tabeller. Den här månaden börjar jag bevakningen av vanliga tabelluttryck (CTE). Precis som med härledda tabeller kommer jag först att ta upp den logiska behandlingen av CTE, och i framtiden kommer jag till optimeringsöverväganden.
I mina exempel kommer jag att använda en exempeldatabas som heter TSQLV5. Du kan hitta skriptet som skapar och fyller det här, och dess ER-diagram här.
CTE
Låt oss börja med termen vanligt tabelluttryck . Varken denna term eller dess akronym CTE förekommer i ISO/IEC SQL-standardspecifikationerna. Så det kan vara så att termen har sitt ursprung i en av databasprodukterna och senare antagits av några av de andra databasleverantörerna. Du hittar det i dokumentationen för Microsoft SQL Server och Azure SQL Database. T-SQL stöder det från och med SQL Server 2005. Standarden använder termen frågeuttryck för att representera ett uttryck som definierar en eller flera CTE, inklusive den yttre frågan. Den använder termen med listelement att representera vad T-SQL kallar en CTE. Jag kommer att tillhandahålla syntaxen för ett frågeuttryck inom kort.
Källan till termen bortsett från, vanligt tabelluttryck , eller CTE , är den vanligaste termen av T-SQL-utövare för strukturen som är i fokus i denna artikel. Så låt oss först ta upp om det är en lämplig term. Vi har redan kommit fram till att termen tabelluttryck är lämpligt för ett uttryck som begreppsmässigt returnerar en tabell. Härledda tabeller, CTE:er, vyer och inline-tabellvärderade funktioner är alla typer av namngivna tabelluttryck som T-SQL stöder. Så, tabelluttrycket del av vanligt tabelluttryck verkar verkligen lämpligt. När det gäller det vanliga del av termen har det förmodligen att göra med en av designfördelarna med CTE:er jämfört med härledda tabeller. Kom ihåg att du inte kan återanvända det härledda tabellnamnet (eller mer exakt intervallvariabelns namn) mer än en gång i den yttre frågan. Omvänt kan CTE-namnet användas flera gånger i den yttre frågan. Med andra ord är CTE-namnet vanligt till den yttre frågan. Naturligtvis kommer jag att visa denna designaspekt i den här artikeln.
CTE:er ger dig liknande fördelar som härledda tabeller, inklusive möjliggörande av utveckling av modulära lösningar, återanvändning av kolumnalias, indirekt interaktion med fönsterfunktioner i satser som normalt inte tillåter dem, stöder modifieringar som indirekt förlitar sig på TOP eller OFFSET FETCH med orderspecifikation, och andra. Men det finns vissa designfördelar jämfört med härledda tabeller, som jag kommer att täcka i detalj efter att jag tillhandahållit syntaxen för strukturen.
Syntax
Här är standardens syntax för ett frågeuttryck:
7.17
Funktion
Ange en tabell.
Format
[
[
AS
|
[
|
[
|
[
|
[
SAMMANDRAG [ AV
HÄMTA { FÖRSTA | NÄSTA } [
|
7.18
Funktion
Ange genereringen av ordnings- och cykeldetekteringsinformation i resultatet av rekursiva frågeuttryck.
Format
SÖK
DEPTH FIRST BY
CYKEL
STANDARD
7.3
Funktion
Ange en uppsättning
Standardtermen frågeuttryck representerar ett uttryck som involverar en WITH-sats, en med lista , som är gjord av en eller flera med listelement , och en yttre fråga. T-SQL hänvisar till standarden med listelement som CTE.
T-SQL stöder inte alla standardsyntaxelement. Till exempel stöder den inte några av de mer avancerade rekursiva frågeelementen som låter dig styra sökriktningen och hantera cykler i en grafstruktur. Rekursiva frågor är i fokus i nästa månads artikel.
Här är T-SQL-syntaxen för en förenklad fråga mot en CTE:
Här är ett exempel på en enkel fråga mot en CTE som representerar kunder i USA:
Du hittar samma tre delar i ett uttalande mot en CTE som du skulle göra med ett uttalande mot en härledd tabell:
Det som är annorlunda med designen av CTE jämfört med härledda tabeller är var i koden dessa tre element finns. Med härledda tabeller kapslas den inre frågan i den yttre frågans FROM-sats, och tabelluttryckets namn tilldelas efter själva tabelluttrycket. Elementen är liksom sammanflätade. Omvänt, med CTE:er, separerar koden de tre elementen:först tilldelar du tabelluttrycket namn; för det andra anger du tabelluttrycket – från början till slut utan avbrott; För det tredje anger du den yttre frågan - från början till slut utan avbrott. Senare, under "Designöverväganden", kommer jag att förklara konsekvenserna av dessa designskillnader.
Ett ord om CTE:er och användningen av semikolon som en uttalandeterminator. Tyvärr, till skillnad från standard SQL, tvingar T-SQL dig inte att avsluta alla satser med semikolon. Det finns dock väldigt få fall i T-SQL där utan en terminator koden är tvetydig. I de fallen är uppsägningen obligatorisk. Ett sådant fall gäller det faktum att WITH-klausulen används för flera ändamål. En är att definiera en CTE, en annan är att definiera en tabelltips för en fråga, och det finns några ytterligare användningsfall. Som ett exempel, i följande uttalande används WITH-satsen för att tvinga fram den serialiserbara isoleringsnivån med ett tabelltips:
Potentialen för tvetydighet är när du har en oavslutad sats som föregår en CTE-definition, i vilket fall parsern kanske inte kan avgöra om WITH-satsen tillhör den första eller andra satsen. Här är ett exempel som visar detta:
Här kan analysatorn inte avgöra om WITH-satsen ska användas för att definiera en tabelltips för Customers-tabellen i den första satsen, eller starta en CTE-definition. Du får följande felmeddelande:
Lösningen är naturligtvis att avsluta uttalandet som föregår CTE-definitionen, men som en bästa praxis borde du verkligen avsluta alla dina uttalanden:
Du kanske har märkt att vissa människor börjar sina CTE-definitioner med semikolon som en praxis, som så:
Poängen med denna praxis är att minska risken för framtida fel. Tänk om någon vid ett senare tillfälle lägger till ett oavslutat uttalande precis före din CTE-definition i skriptet och inte bryr sig om att kontrollera hela skriptet, snarare bara deras uttalande? Ditt semikolon precis före WITH-satsen blir i praktiken deras uttalandeterminator. Du kan säkert se det praktiska i denna praxis, men det är lite onaturligt. Vad som rekommenderas, även om det är svårare att uppnå, är att ingjuta goda programmeringsrutiner i organisationen, inklusive uppsägning av alla uttalanden.
När det gäller syntaxreglerna som gäller för tabelluttrycket som används som den inre frågan i CTE-definitionen, är de samma som de som gäller för tabelluttrycket som används som den inre frågan i en härledd tabelldefinition. Dessa är:
För detaljer, se avsnittet "Ett tabelluttryck är en tabell" i del 2 av serien.
Om du undersöker erfarna T-SQL-utvecklare om de föredrar att använda härledda tabeller eller CTE:er, kommer inte alla att komma överens om vilket som är bäst. Naturligtvis har olika människor olika stylingpreferenser. Jag använder ibland härledda tabeller och ibland CTE:er. Det är bra att medvetet kunna identifiera de specifika skillnaderna i språkdesign mellan de två verktygen och välja utifrån dina prioriteringar i en given lösning. Med tid och erfarenhet gör du dina val mer intuitivt.
Dessutom är det viktigt att inte blanda ihop användningen av tabelluttryck och tillfälliga tabeller, men det är en prestationsrelaterad diskussion som jag kommer att ta upp i en framtida artikel.
CTE:er har rekursiva frågefunktioner och härledda tabeller har inte. Så om du behöver förlita dig på dem, skulle du naturligtvis välja CTE. Rekursiva frågor är i fokus i nästa månads artikel.
I del 2 förklarade jag att jag ser kapsling av härledda tabeller som att lägga till komplexitet till koden, eftersom det gör det svårt att följa logiken. Jag gav följande exempel och identifierade beställningsår under vilka mer än 70 kunder gjorde beställningar:
CTE:er stöder inte kapsling. Så när du granskar eller felsöker en lösning baserad på CTE:er går du inte vilse i den kapslade logiken. Istället för att kapsla bygger du fler modulära lösningar genom att definiera flera CTE:er under samma WITH-sats, separerade med kommatecken. Var och en av CTE:erna är baserad på en fråga som skrivs från början till slut utan avbrott. Jag ser det som en bra sak ur ett kodtydlighets- och underhållsperspektiv.
Här är en lösning på ovannämnda uppgift med hjälp av CTE:
Jag gillar den CTE-baserade lösningen bättre. Men återigen, fråga erfarna utvecklare vilken av ovanstående två lösningar de föredrar, och de kommer inte alla att hålla med. Vissa föredrar faktiskt den kapslade logiken och att kunna se allt på ett ställe.
En mycket tydlig fördel med CTE:er jämfört med härledda tabeller är när du behöver interagera med flera instanser av samma tabelluttryck i din lösning. Kom ihåg följande exempel baserat på härledda tabeller från del 2 i serien:
Denna lösning returnerar orderår, orderantal per år och skillnaden mellan innevarande års och föregående års antal. Ja, du skulle kunna göra det lättare med LAG-funktionen, men mitt fokus här är inte att hitta det bästa sättet att uppnå denna mycket specifika uppgift. Jag använder det här exemplet för att illustrera vissa språkdesignaspekter av namngivna tabelluttryck.
Problemet med den här lösningen är att du inte kan tilldela ett namn till ett tabelluttryck och återanvända det i samma logiska frågebearbetningssteg. Du namnger en härledd tabell efter själva tabelluttrycket i FROM-satsen. Om du definierar och namnger en härledd tabell som den första ingången i en koppling, kan du inte också återanvända det härledda tabellnamnet som den andra ingången i samma koppling. Om du själv behöver sammanfoga två instanser av samma tabelluttryck, med härledda tabeller har du inget annat val än att duplicera koden. Det är vad du gjorde i exemplet ovan. Omvänt tilldelas CTE-namnet som det första elementet i koden bland de tre ovan (CTE-namn, inre fråga, yttre fråga). I termer av logisk frågebehandling, när du kommer till den yttre frågan, är CTE-namnet redan definierat och tillgängligt. Detta innebär att du kan interagera med flera instanser av CTE-namnet i den yttre frågan, som så:
Denna lösning har en klar programmerbarhetsfördel jämfört med den som baseras på härledda tabeller genom att du inte behöver underhålla två kopior av samma tabelluttryck. Det finns mer att säga om det ur ett fysiskt bearbetningsperspektiv, och jämföra det med användningen av tillfälliga tabeller, men jag kommer att göra det i en framtida artikel som fokuserar på prestanda.
En fördel som kod baserad på härledda tabeller har jämfört med kod baserad på CTE:er har att göra med closure-egenskapen som ett tabelluttryck ska ha. Kom ihåg att stängningsegenskapen för ett relationsuttryck säger att både input och output är relationer, och att ett relationsuttryck därför kan användas där en relation förväntas, som input till ännu ett relationsuttryck. På liknande sätt returnerar ett tabelluttryck en tabell och ska vara tillgängligt som en inmatningstabell för ett annat tabelluttryck. Detta gäller för en fråga som är baserad på härledda tabeller – du kan använda den där en tabell förväntas. Du kan till exempel använda en fråga som är baserad på härledda tabeller som den inre frågan i en CTE-definition, som i följande exempel:
Detsamma gäller dock inte för en fråga som är baserad på CTE. Även om det begreppsmässigt är tänkt att betraktas som ett tabelluttryck, kan du inte använda det som den inre frågan i härledda tabelldefinitioner, underfrågor och själva CTE:er. Till exempel är följande kod inte giltig i T-SQL:
Den goda nyheten är att du kan använda en fråga som är baserad på CTE:er som den inre frågan i vyer och inline-tabellvärderade funktioner, som jag tar upp i framtida artiklar.
Kom också ihåg att du alltid kan definiera en annan CTE baserat på den senaste frågan och sedan låta den yttersta frågan interagera med den CTE:
Ur felsökningssynpunkt, som nämnt, har jag vanligtvis lättare att följa logiken för kod som är baserad på CTE, jämfört med kod baserad på härledda tabeller. Lösningar baserade på härledda tabeller har dock en fördel genom att du kan markera vilken kapslingsnivå som helst och köra den självständigt, som visas i figur 1.
Med CTE är saker och ting svårare. För att kod som involverar CTE:er ska vara körbar måste den börja med en WITH-sats, följt av ett eller flera namngivna tabelluttryck i parentes separerade med kommatecken, följt av en fråga utan föregående kommatecken. Du kan markera och köra vilken som helst av de inre frågorna som verkligen är fristående, såväl som den kompletta lösningens kod; Du kan dock inte markera och köra någon annan mellanliggande del av lösningen. Till exempel visar figur 2 ett misslyckat försök att köra koden som representerar C2.
Så med CTE:er måste du ta till något besvärliga medel för att kunna felsöka ett mellansteg i lösningen. Till exempel är en vanlig lösning att tillfälligt injicera en SELECT * FROM your_cte-fråga precis under den relevanta CTE. Du markerar och kör sedan koden inklusive den injicerade frågan, och när du är klar tar du bort den injicerade frågan. Figur 3 visar denna teknik.
Problemet är att när du gör ändringar i koden – även tillfälliga mindre sådana som ovan – finns det en chans att när du försöker återgå till den ursprungliga koden kommer du att introducera en ny bugg.
Ett annat alternativ är att utforma din kod lite annorlunda, så att varje icke-första CTE-definition börjar med en separat kodrad som ser ut så här:
Sedan, närhelst du vill köra en mellanliggande del av koden ner till en given CTE, kan du göra det med minimala ändringar av din kod. Genom att använda en radkommentar kommenterar du bara den kodraden som motsvarar den CTE. Du markerar sedan och kör koden ner till och med CTE:s inre fråga, som nu anses vara den yttersta frågan, som illustreras i figur 4.
Om du inte är nöjd med den här stilen har du ännu ett alternativ. Du kan använda en blockkommentar som börjar precis före kommatecken som föregår CTE av intresse och slutar efter den öppna parentesen, som illustreras i figur 5.
Det handlar om personliga preferenser. Jag använder vanligtvis den tillfälligt injicerade SELECT * frågetekniken.
Det finns en viss begränsning i T-SQL:s stöd för tabellvärdekonstruktörer jämfört med standarden. Om du inte är bekant med konstruktionen, se till att kolla in del 2 i serien först, där jag beskriver den i detalj. Medan T-SQL låter dig definiera en härledd tabell baserad på en tabellvärdekonstruktor, tillåter den dig inte att definiera en CTE baserad på en tabellvärdeskonstruktor.
Här är ett exempel som stöds som använder en härledd tabell:
Tyvärr stöds inte liknande kod som använder en CTE:
Den här koden genererar följande fel:
Det finns dock ett par lösningar. En är att använda en fråga mot en härledd tabell, som i sin tur är baserad på en tabellvärdekonstruktor, som CTE:s inre fråga, som så:
En annan är att tillgripa tekniken som människor använde innan tabellvärderade konstruktörer introducerades i T-SQL – genom att använda en serie FROMless-frågor separerade av UNION ALL-operatorer, som så:
Observera att kolumnaliasen tilldelas direkt efter CTE-namnet.
De två metoderna blir algebriserade och optimerade på samma sätt, så använd den du är mer bekväm med.
Ett verktyg som jag använder ganska ofta i mina lösningar är en hjälptabell med tal. Ett alternativ är att skapa en tabell med faktiska tal i din databas och fylla i den med en lagom stor sekvens. En annan är att utveckla en lösning som producerar en talföljd i farten. För det senare alternativet vill du att ingångarna ska vara avgränsare för det önskade intervallet (vi kallar dem
Denna kod genererar följande utdata:
Den första CTE som kallas L0 är baserad på en tabellvärdekonstruktor med två rader. De faktiska värdena där är obetydliga; Det viktiga är att den har två rader. Sedan finns det en sekvens av fem ytterligare CTE:er som heter L1 till L5, som var och en tillämpar en korskoppling mellan två instanser av föregående CTE. Följande kod beräknar antalet rader som potentiellt genereras av var och en av CTE:erna, där @L är CTE-nivånumret:
Här är siffrorna som du får för varje CTE:
Att gå upp till nivå 5 ger dig över fyra miljarder rader. Detta borde vara tillräckligt för alla praktiska användningsfall som jag kan tänka mig. Nästa steg sker i CTE som kallas Nums. Du använder en ROW_NUMBER-funktion för att generera en sekvens av heltal som börjar med 1 baserat på ingen definierad ordning (ORDER BY (SELECT NULL)), och namnger resultatkolumnen rownum. Slutligen använder den yttre frågan ett TOP-filter baserat på rownum-ordning för att filtrera så många siffror som önskad sekvenskardinalitet (@high – @low + 1), och beräknar resultatnumret n som @low + rownum – 1.
Här kan du verkligen uppskatta skönheten i CTE-designen och de besparingar som den möjliggör när du bygger lösningar på ett modulärt sätt. I slutändan packar avvecklingsprocessen upp 32 tabeller, som var och en består av två rader baserade på konstanter. Detta kan tydligt ses i exekveringsplanen för denna kod, som visas i figur 6 med SentryOne Plan Explorer.
Varje konstant avsökningsoperator representerar en tabell med konstanter med två rader. Saken är den att Top-operatören är den som begär dessa rader, och den kortsluter efter att den fått önskat nummer. Lägg märke till de 10 raderna ovanför pilen som flödar in i Top-operatorn.
Jag vet att den här artikelns fokus är den konceptuella behandlingen av CTE och inte fysiska/prestandaöverväganden, men genom att titta på planen kan du verkligen uppskatta hur kortfattad koden är jämfört med den långrandiga vad den översätter till bakom kulisserna.
Med hjälp av härledda tabeller kan du faktiskt skriva en lösning som ersätter varje CTE-referens med den underliggande frågan som den representerar. Det du får är ganska läskigt:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Format
VÄRDEN
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Felaktig syntax nära 'UC'. Om detta är avsett att vara ett vanligt tabelluttryck, måste du uttryckligen avsluta den föregående satsen med ett semikolon. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Designöverväganden
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70;> WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Figur 1:Kan markera och köra en del av koden med härledda tabeller
Figur 1:Kan markera och köra en del av koden med härledda tabeller  Figur 2:Kan inte markera och köra en del av koden med CTE
Figur 2:Kan inte markera och köra en del av koden med CTE  Figur 3:Injicera SELECT * under relevant CTE
Figur 3:Injicera SELECT * under relevant CTE , cte_name AS (
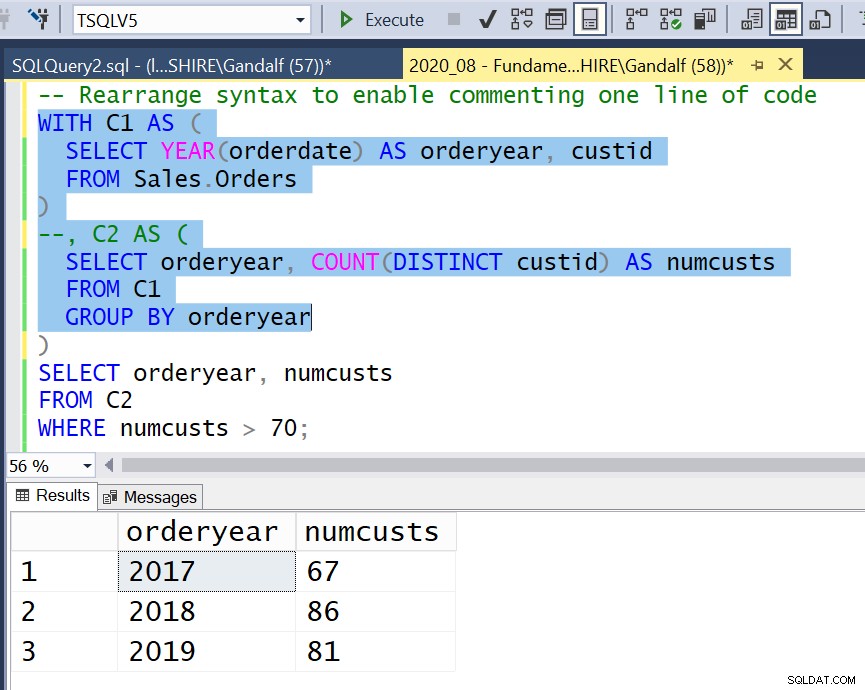 Figur 4:Ordna om syntax för att möjliggöra kommentering av en kodrad
Figur 4:Ordna om syntax för att möjliggöra kommentering av en kodrad  Figur 5:Använd blockkommentar
Figur 5:Använd blockkommentar Tabellvärdekonstruktor
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Felaktig syntax nära nyckelordet 'VALUES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Ta fram en talföljd
@low och @high ). Du vill att din lösning ska stödja potentiellt stora räckvidder. Här är min lösning för detta ändamål, med hjälp av CTE:er, med en begäran om intervallet 1001 till 1010 i detta specifika exempel:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Kardinalitet L0 2 L1 4 L2 16 L3 256 L4 65 536 L5 4 294 967 296  Figur 6:Plan för frågegenererande nummersekvens
Figur 6:Plan för frågegenererande nummersekvens DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Summary
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes