Introduktion
Denna handledning innehåller information om SQL (DDL, DML) som jag har samlat in under mitt yrkesliv. Detta är det minsta du behöver veta när du arbetar med databaser. Om det finns ett behov av att använda komplexa SQL-konstruktioner, så brukar jag surfa på MSDN-biblioteket, som lätt kan hittas på internet. Enligt min mening är det väldigt svårt att hålla allt i huvudet och förresten, det finns inget behov av detta. Jag rekommenderar att du bör känna till alla huvudkonstruktioner som används i de flesta relationsdatabaser som Oracle, MySQL och Firebird. Ändå kan de skilja sig åt i datatyper. Till exempel, för att skapa objekt (tabeller, begränsningar, index, etc.), kan du helt enkelt använda integrerad utvecklingsmiljö (IDE) för att arbeta med databaser och det finns inget behov av att studera visuella verktyg för en viss databastyp (MS SQL, Oracle , MySQL, Firebird, etc.). Detta är praktiskt eftersom du kan se hela texten, och du behöver inte titta igenom många flikar för att skapa, till exempel, ett index eller en begränsning. Om du ständigt arbetar med databaser, är det mycket snabbare att skapa, modifiera och särskilt bygga om ett objekt med hjälp av skript än i ett visuellt läge. Dessutom, enligt min mening, i skriptläget (med vederbörlig precision), är det lättare att specificera och kontrollera regler för namngivning av objekt. Dessutom är det bekvämt att använda skript när du behöver överföra databasändringar från en testdatabas till en produktionsdatabas.
SQL är uppdelat i flera delar. I min artikel kommer jag att gå igenom de viktigaste:
DDL – Data Definition Language
DML – Data Manipulation Language, som inkluderar följande konstruktioner:
- SELECT – dataurval
- INSERT – ny infogning av data
- UPPDATERING – datauppdatering
- RADERA – radering av data
- SAMMANFATTNING – datasammanslagning
Jag kommer att förklara alla konstruktioner i studiefall. Dessutom tycker jag att ett programmeringsspråk, särskilt SQL, bör studeras i praktiken för bättre förståelse.
Det här är en steg-för-steg handledning, där du måste utföra exempel medan du läser den. Men om du behöver veta kommandot i detaljer, surfa sedan på Internet, till exempel MSDN.
När jag skapade den här handledningen har jag använt MS SQL Server-databasen, version 2014, och MS SQL Server Management Studio (SSMS) för att köra skript.
Kort om MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) är Microsoft SQL Server-verktyget för att konfigurera, hantera och administrera databaskomponenter. Den innehåller en skriptredigerare och ett grafikprogram som fungerar med serverobjekt och inställningar. Huvudverktyget i SQL Server Management Studio är Object Explorer, som låter en användare visa, hämta och hantera serverobjekt. Denna text är delvis hämtad från Wikipedia.
För att skapa en ny skriptredigerare, använd knappen Ny fråga:
För att byta från den aktuella databasen kan du använda rullgardinsmenyn:
För att utföra ett visst kommando eller en uppsättning kommandon, markera den och tryck på knappen Execute eller F5. Om det bara finns ett kommando i editorn eller om du behöver utföra alla kommandon, markera då inget.
När du har kört skript som skapar objekt (tabeller, kolumner, index), välj motsvarande objekt (till exempel tabeller eller kolumner) och klicka sedan på Uppdatera på genvägsmenyn för att se ändringarna.
Egentligen är detta allt du behöver veta för att utföra exemplen häri.
Teori
En relationsdatabas är en uppsättning tabeller länkade samman. I allmänhet är en databas en fil som lagrar strukturerad data.
Database Management System (DBMS) är en uppsättning verktyg för att arbeta med särskilda databastyper (MS SQL, Oracle, MySQL, Firebird, etc.).
Obs! Som i våra dagliga liv säger vi "Oracle DB" eller bara "Oracle" som faktiskt betyder "Oracle DBMS", och i denna handledning kommer jag att använda termen "databas".
En tabell är en uppsättning kolumner. Mycket ofta kan du höra följande definitioner av dessa termer:fält, rader och poster, som betyder detsamma.
En tabell är huvudobjektet för relationsdatabasen. All data lagras rad för rad i tabellkolumner.
För varje tabell såväl som för dess kolumner måste du ange ett namn, enligt vilket du kan hitta ett obligatoriskt objekt.
Namnet på objektet, tabellen, kolumnen och indexet kan ha minsta längd – 128 symboler.
Obs! I Oracle-databaser kan ett objektnamn ha minsta längd – 30 symboler. I en viss databas är det alltså nödvändigt att skapa anpassade regler för objektnamn.
SQL är ett språk som tillåter exekvering av frågor i databaser via DBMS. I ett visst DBMS kan ett SQL-språk ha sin egen dialekt.
DDL och DML – SQL-underspråket:
- DDL-språket används för att skapa och ändra en databasstruktur (tabell- och länkradering);
- DML-språket tillåter manipulering av tabelldata, dess rader. Den fungerar också för att välja data från tabeller, lägga till ny data, samt uppdatera och ta bort aktuell data.
Det är möjligt att använda två typer av kommentarer i SQL (enradig och avgränsad):
-- single-line comment
och
/* delimited comment */
Det handlar bara om teorin.
DDL – Data Definition Language
Låt oss överväga en exempeltabell med data om anställda representerade på ett sätt som är bekant för en person som inte är programmerare.
| Anställd-ID | Fullständigt namn | Födelsedatum | E-post | Position | Avdelning |
| 1000 | John | 19.02.1955 | example@sqldat.com | VD | Administration |
| 1001 | Daniel | 03.12.1983 | example@sqldat.com | programmerare | IT |
| 1002 | Mike | 07.06.1976 | example@sqldat.com | Revisor | Kontoavdelningen |
| 1003 | Jordanien | 17.04.1982 | example@sqldat.com | Senior programmerare | IT |
I det här fallet har kolumnerna följande rubriker:Medarbetar-ID, Fullständigt namn, Födelsedatum, E-post, Position och Avdelning.
Vi kan beskriva varje kolumn i denna tabell efter dess datatyp:
- Anställd-ID – heltal
- Fullständigt namn – sträng
- Födelsedatum – datum
- E-post – sträng
- Position – sträng
- Avdelning – sträng
En kolumntyp är en egenskap som anger vilken datatyp varje kolumn kan lagra.
Till att börja med måste du komma ihåg de huvudsakliga datatyperna som används i MS SQL:
| Definition | Beteckning i MS SQL | Beskrivning |
| sträng med variabel längd | varchar(N) och nvarchar(N) | Med hjälp av N-numret kan vi ange maximal stränglängd för en viss kolumn. Om vi till exempel vill säga att värdet för kolumnen Fullständigt namn kan innehålla 30 symboler (högst), är det nödvändigt att ange typen av nvarchar(30).
Skillnaden mellan varchar och nvarchar är att varchar tillåter lagring av strängar i ASCII-format, medan nvarchar lagrar strängar i Unicode-format, där varje symbol tar 2 byte. |
| sträng med fast längd | char(N) och nchar(N) | Denna typ skiljer sig från strängen med variabel längd på följande sätt:om strängens längd är mindre än N symboler, läggs mellanslag alltid till N-längden till höger. I en databas tar det alltså exakt N symboler, där en symbol tar 1 byte för char och 2 byte för nchar. I min praktik används denna typ inte mycket. Ändå, om någon använder det, så har vanligtvis denna typ formatet char(1), dvs när ett fält definieras av 1 symbol. |
| Heltal | int | Denna typ tillåter oss att endast använda heltal (både positivt och negativt) i en kolumn. Notera:ett nummerområde för denna typ är följande:från 2 147 483 648 till 2 147 483 647. Vanligtvis är det huvudtypen som används för att identifiera identifierare. |
| Flyttal | flyta | Siffror med en decimalkomma. |
| Datum | datum | Den används för att endast lagra ett datum (datum, månad och år) i en kolumn. Till exempel 2014-02-15. Denna typ kan användas för följande kolumner:mottagningsdatum, födelsedatum, etc., när du bara behöver ange ett datum eller när tiden inte är viktig för oss och vi kan släppa den. |
| Tid | tid | Du kan använda den här typen om det är nödvändigt att lagra tid:timmar, minuter, sekunder och millisekunder. Till exempel har du 17:38:31.3231603 eller så måste du lägga till flygets avgångstid. |
| Datum och tid | datumtid | Den här typen tillåter användare att lagra både datum och tid. Du har till exempel evenemanget den 15/02/2014 17:38:31.323. |
| Indikator | bit | Du kan använda den här typen för att lagra värden som "Ja"/"Nej", där "Ja" är 1 och "Nej" är 0. |
Dessutom är det inte nödvändigt att ange fältvärdet, såvida det inte är förbjudet. I det här fallet kan du använda NULL.
För att utföra exempel kommer vi att skapa en testdatabas med namnet 'Test'.
För att skapa en enkel databas utan några ytterligare egenskaper, kör följande kommando:
CREATE DATABASE Test
För att ta bort en databas, kör följande kommando:
DROP DATABASE Test
För att byta till vår databas, använd kommandot:
USE Test
Alternativt kan du välja Testdatabasen från rullgardinsmenyn i SSMS-menyområdet.
Nu kan vi skapa en tabell i vår databas med beskrivningar, mellanslag och kyrilliska symboler:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar(30) )
I det här fallet måste vi slå in namn inom hakparenteser […].
Ändå är det bättre att ange alla objektnamn på latin och att inte använda mellanslag i namnen. I det här fallet börjar varje ord med en stor bokstav. Till exempel, för fältet "EmployeeID" kan vi ange PersonalNumber-namnet. Du kan också använda nummer i namnet, till exempel Telefonnummer1.
Obs! I vissa DBMS är det bekvämare att använda följande namnformat «PHONE_NUMBER». Du kan till exempel se detta format i ORACLE-databaser. Dessutom bör fältnamnet inte sammanfalla med nyckelorden som används i DBMS.
Av denna anledning kan du glömma syntaxen för hakparenteser och kan ta bort tabellen Anställda:
DROP TABLE [Employees]
Du kan till exempel namnge tabellen med anställda som "Anställda" och ange följande namn för dess fält:
- ID
- Namn
- Födelsedag
- E-post
- Position
- Avdelning
Mycket ofta använder vi "ID" för identifierarfältet.
Låt oss nu skapa en tabell:
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
För att ställa in de obligatoriska kolumnerna kan du använda alternativet INTE NULL.
För den aktuella tabellen kan du omdefiniera fälten med följande kommandon:
-- ID field update ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- Name field update ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Obs! Det allmänna konceptet för SQL-språket för de flesta DBMS är detsamma (från min egen erfarenhet). Skillnaden mellan DDL:er i olika DBMS:er ligger främst i datatyperna (de kan skilja sig inte bara genom deras namn utan också genom deras specifika implementering). Dessutom är den specifika SQL-implementeringen (kommandona) densamma, men det kan finnas små skillnader i dialekten. Genom att känna till grunderna i SQL kan du enkelt växla från ett DBMS till ett annat. I det här fallet behöver du bara förstå detaljerna för att implementera kommandon i ett nytt DBMS.
Jämför samma kommandon i ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- In ORACLE the int type is a value for number(38) Name nvarchar2(30), -- in ORACLE nvarchar2 is identical to nvarchar in MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- ID and Name field update (here we use MODIFY(…) instead of ALTER COLUMN ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (in this case the construction is the same as in the MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE skiljer sig i implementeringen av varchar2-typen. Dess format beror på DB-inställningarna och du kan spara en text, till exempel i UTF-8. Dessutom kan du ange fältlängden både i byte och symboler. För att göra detta måste du använda BYTE- och CHAR-värdena följt av längdfältet. Till exempel:
NAME varchar2(30 BYTE) – field capacity equals 30 bytes NAME varchar2(30 CHAR) -- field capacity equals 30 symbols
Värdet (BYTE eller CHAR) som ska användas som standard när du bara anger varchar2(30) i ORACLE kommer att bero på DB-inställningarna. Ofta kan man lätt bli förvirrad. Därför rekommenderar jag att du uttryckligen specificerar CHAR när du använder typen varchar2 (till exempel med UTF-8) i ORACLE (eftersom det är bekvämare att läsa stränglängden i symboler).
Men i det här fallet, om det finns några data i tabellen, är det nödvändigt att fylla i fälten ID och Namn i alla tabellrader för att framgångsrikt kunna utföra kommandon.
Jag kommer att visa det i ett särskilt exempel.
Låt oss infoga data i fälten ID, Position och Avdelning med följande skript:
INSERT Employees(ID,Position,Department) VALUES (1000,’CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
I det här fallet returnerar kommandot INSERT också ett fel. Detta händer eftersom vi inte har angett värdet för det obligatoriska fältet Namn.
Om det fanns några data i den ursprungliga tabellen skulle kommandot "ALTER TABLE Employees ALTER COLUMN ID int NOT NULL" fungera, medan kommandot "ALTER TABLE Employees ALTER COLUMN Name int NOT NULL" skulle returnera ett fel som fältet Namn har NULL-värden.
Låt oss lägga till värden i fältet Namn:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Dessutom kan du använda NOT NULL när du skapar en ny tabell med CREATE TABLE-satsen.
Låt oss först ta bort en tabell:
DROP TABLE Employees
Nu ska vi skapa en tabell med de obligatoriska fälten ID och Namn:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Du kan också ange NULL efter ett kolumnnamn, vilket antyder att NULL-värden är tillåtna. Detta är inte obligatoriskt, eftersom det här alternativet är inställt som standard.
Om du behöver göra den aktuella kolumnen icke-obligatorisk, använd följande syntax:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Alternativt kan du använda det här kommandot:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Dessutom kan vi med det här kommandot antingen ändra fälttypen till en annan kompatibel eller ändra dess längd. Låt oss till exempel utöka fältet Namn till 50 symboler:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Primär nyckel
När du skapar en tabell måste du ange en kolumn eller en uppsättning kolumner som är unika för varje rad. Med detta unika värde kan du identifiera en post. Detta värde kallas primärnyckeln. ID-kolumnen (som innehåller «en anställds personnummer» – i vårt fall är detta det unika värdet för varje anställd och kan inte dupliceras) kan vara den primära nyckeln för vår tabell med anställda.
Du kan använda följande kommando för att skapa en primärnyckel för tabellen:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
'PK_Employees' är ett begränsningsnamn som definierar primärnyckeln. Vanligtvis består namnet på en primärnyckel av prefixet 'PK_' och tabellnamnet.
Om primärnyckeln innehåller flera fält, måste du lista dessa fält inom parentes avgränsade med kommatecken:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Tänk på att i MS SQL bör alla fält i primärnyckeln INTE vara NULL.
Dessutom kan du definiera en primärnyckel när du skapar en tabell. Låt oss ta bort tabellen:
DROP TABLE Employees
Skapa sedan en tabell med följande syntax:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK after all the fileds as a constraint )
Lägg till data i tabellen:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior programmer',N'IT',N'Jordan')
Egentligen behöver du inte ange begränsningsnamnet. I det här fallet kommer ett systemnamn att tilldelas. Till exempel, «PK__Employee__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
eller
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Personligen skulle jag rekommendera att explicit specificera begränsningsnamnet för permanenta tabeller, eftersom det är lättare att arbeta med eller ta bort ett explicit definierat och tydligt värde i framtiden. Till exempel:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Ändå är det bekvämare att använda denna korta syntax, utan begränsningsnamn när du skapar temporära databastabeller (namnet på en temporär tabell börjar med # eller ##.
Sammanfattning:
Vi har redan analyserat följande kommandon:
- SKAPA TABELL table_name (lista över fält och deras typer, såväl som begränsningar) – tjänar till att skapa en ny tabell i den aktuella databasen;
- SLIPP TABELL table_name – tjänar till att ta bort en tabell från den aktuella databasen;
- ÄNDRA TABELL tabellnamn ALTER COLUMN kolumnnamn … – tjänar till att uppdatera kolumntypen eller för att ändra dess inställningar (till exempel när du behöver ställa in NULL eller NOT NULL);
- ÄNDRA TABELL tabellnamn LÄGG TILL BEGRÄNSNING constraint_name PRIMÄRNYCKEL (fält1, fält2,...) – används för att lägga till en primärnyckel till den aktuella tabellen;
- ÄNDRA TABELL table_name DROP CONSTRAINT constraint_name – används för att ta bort en restriktion från tabellen.
Tillfälliga tabeller
Abstrakt från MSDN. Det finns två typer av temporära tabeller i MS SQL Server:lokal (#) och global (##). Lokala temporära tabeller är endast synliga för deras skapare innan instansen av SQL Server kopplas bort. De raderas automatiskt efter att användaren kopplats bort från instansen av SQL Server. Globala temporära tabeller är synliga för alla användare under alla anslutningssessioner efter att dessa tabeller har skapats. Dessa tabeller raderas när användare kopplas bort från instansen av SQL Server.
Tillfälliga tabeller skapas i tempdb-systemdatabasen, vilket gör att vi inte översvämmer huvuddatabasen. Dessutom kan du ta bort dem med kommandot DROP TABLE. Mycket ofta används lokala (#) temporära tabeller.
För att skapa en tillfällig tabell kan du använda kommandot CREATE TABLE:
CREATE TABLE #Temp( ID int, Name nvarchar(30) )
Du kan ta bort den tillfälliga tabellen med kommandot DROP TABLE:
DROP TABLE #Temp
Dessutom kan du skapa en tillfällig tabell och fylla i den med data med hjälp av syntaxen SELECT ... INTO:
SELECT ID,Name INTO #Temp FROM Employees
Obs! I olika DBMS kan implementeringen av temporära databaser variera. Till exempel, i ORACLE och Firebird DBMS, bör strukturen för temporära tabeller definieras i förväg av kommandot CREATE GLOBAL TEMPORARY TABLE. Du måste också specificera sättet att lagra data. Efter detta ser en användare det bland vanliga tabeller och arbetar med det som med en konventionell tabell.
Databasnormalisering:dela upp i deltabeller (referenstabeller) och definiera tabellrelationer
Vår nuvarande tabell för anställda har en nackdel:en användare kan skriva vilken text som helst i fälten Position och Avdelning, vilket kan returnera fel, eftersom han för en anställd kan ange "IT" som en avdelning, medan för en annan anställd kan han ange "IT" avdelning". Som ett resultat blir det oklart vad användaren menade, om dessa anställda jobbar på samma avdelning eller om det finns en felstavning och det finns 2 olika avdelningar. Dessutom kommer vi i det här fallet inte att kunna gruppera data korrekt för en rapport, där vi måste visa antalet anställda för varje avdelning.
En annan nackdel är lagringsvolymen och dess dubblering, det vill säga du måste ange ett fullständigt namn på avdelningen för varje anställd, vilket kräver utrymme i databaser för att lagra varje symbol för avdelningsnamnet.
Den tredje nackdelen är komplexiteten i att uppdatera fältdata när du behöver ändra ett namn på vilken position som helst – från programmerare till junior programmerare. I det här fallet måste du lägga till ny data i varje tabellrad där positionen är "Programmerare".
För att undvika sådana situationer rekommenderas det att använda databasnormalisering – uppdelning i deltabeller – referenstabeller.
Låt oss skapa 2 referenstabeller "Positioner" och "Avdelningar":
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Observera att vi här har använt en ny fastighets-IDENTITY. Det betyder att data i ID-kolumnen automatiskt kommer att listas med början på 1. När nya poster läggs till kommer alltså värdena 1, 2, 3, etc. att tilldelas sekventiellt. Vanligtvis kallas dessa fält för autoinkrementfält. Endast ett fält med egenskapen IDENTITY kan definieras som en primärnyckel i en tabell. Vanligtvis, men inte alltid, är ett sådant fält den primära nyckeln i tabellen.
Obs! I olika DBMS kan implementeringen av fält med en inkrementerare skilja sig åt. I MySQL, till exempel, definieras ett sådant fält av egenskapen AUTO_INCREMENT. I ORACLE och Firebird kan du emulera den här funktionen med sekvenser (SEKVENS). Men så vitt jag vet har egenskapen GENERATED AS IDENTITY lagts till i ORACLE.
Låt oss fylla i dessa tabeller automatiskt baserat på aktuell data i fälten Position och Avdelning i tabellen Anställda:
-- fill in the Name field of the Positions table with unique values from the Position field of the Employees table INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – drop records where a position is not specified
Du måste göra samma steg för tabellen Avdelningar:
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
Om vi nu öppnar tabellerna Positioner och Avdelningar, kommer vi att se en numrerad lista med värden i ID-fältet:
SELECT * FROM Positions
| ID | Namn |
| 1 | Revisor |
| 2 | VD |
| 3 | Programmerare |
| 4 | Senior programmerare |
SELECT * FROM Departments
| ID | Namn |
| 1 | Administration |
| 2 | Kontoavdelningen |
| 3 | IT |
Dessa tabeller kommer att vara referenstabeller för att definiera befattningar och avdelningar. Nu kommer vi att hänvisa till identifierare för positioner och avdelningar. Låt oss först skapa nya fält i tabellen Anställda för att lagra identifierarna:
-- add a field for the ID position ALTER TABLE Employees ADD PositionID int -- add a field for the ID department ALTER TABLE Employees ADD DepartmentID int
Typen av referensfält bör vara densamma som i referenstabellerna, i det här fallet är det int.
Dessutom kan du lägga till flera fält med ett kommando genom att lista fälten separerade med kommatecken:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Nu kommer vi att lägga till referensbegränsningar (FOREIGN KEY) till dessa fält, så att en användare inte kan lägga till några värden som inte är referenstabellernas ID-värden.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Samma steg bör göras för det andra fältet:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Nu kan användare bara infoga ID-värdena från motsvarande referenstabell i dessa fält. För att använda en ny avdelning eller position måste en användare lägga till en ny post i motsvarande referenstabell. Eftersom befattningar och avdelningar lagras i referenstabeller i ett exemplar behöver du bara ändra det i referenstabellen för att ändra deras namn.
Namnet på en referensrestriktion är vanligtvis sammansatt. Den består av prefixet «FK» följt av ett tabellnamn och ett fältnamn som hänvisar till referenstabellens identifierare.
Identifieraren (ID) är vanligtvis ett internt värde som endast används för länkar. Det spelar ingen roll vilket värde den har. Försök alltså inte att bli av med luckor i sekvensen av värden som visas när du arbetar med tabellen, till exempel när du tar bort poster från referenstabellen.
I vissa fall är det möjligt att bygga en referens från flera fält:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
I det här fallet representeras en primärnyckel av en uppsättning av flera fält (fält1, fält2, …) i tabellen "referenstabell".
Låt oss nu uppdatera fälten PositionID och DepartmentID med ID-värdena från referenstabellerna.
För att göra detta använder vi kommandot UPDATE:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Kör följande fråga:
SELECT * FROM Employees
| ID | Namn | Födelsedag | E-post | Position | Avdelning | Positions-ID | Avdelnings-ID |
| 1000 | John | NULL | NULL | VD | Administration | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Programmerare | IT | 3 | 3 |
| 1002 | Mike | NULL | NULL | Revisor | Kontoavdelningen | 1 | 2 |
| 1003 | Jordanien | NULL | NULL | Senior programmerare | IT | 4 | 3 |
Som du kan se matchar fälten PositionID och DepartmentID positioner och avdelningar. Således kan du ta bort fälten Position och Avdelning i tabellen Anställda genom att utföra följande kommando:
ALTER TABLE Employees DROP COLUMN Position,Department
Kör nu detta uttalande:
SELECT * FROM Employees
| ID | Namn | Födelsedag | E-post | Positions-ID | Avdelnings-ID |
| 1000 | John | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordanien | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
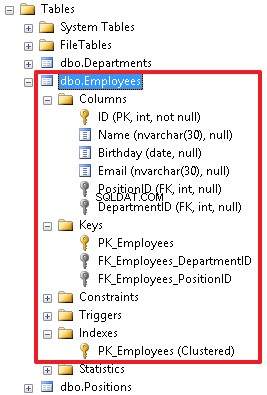
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Then create a diagram and check how our tables are linked:
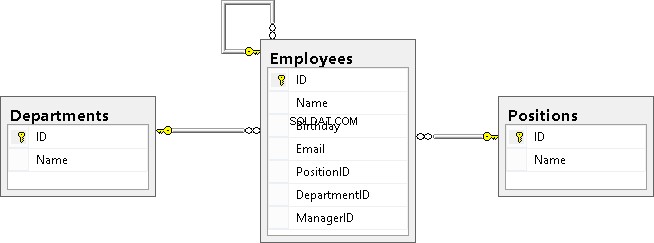
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
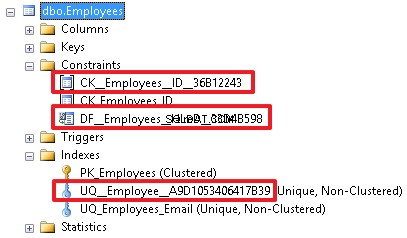
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Summary
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.