Generellt sett är den bästa sortens sort som helt undviks. Med noggrann indexering och ibland lite kreativ frågeskrivning kan vi ofta ta bort behovet av en sorteringsoperatör från exekveringsplanerna. Om data som ska sorteras är stor kan undvikande av denna typ av sortering ge mycket betydande prestandaförbättringar.
Den näst bästa sortens sort är den vi inte kan undvika, men som reserverar en lämplig mängd minne och använder allt eller det mesta för att göra något värdefullt. Att vara värt besväret kan ta många former. Ibland kan en sortering mer än betala för sig själv genom att möjliggöra en senare operation som fungerar mycket mer effektivt på sorterad input. Andra gånger är sorteringen helt enkelt nödvändig, och vi behöver bara göra den så effektiv som möjligt.
Sedan kommer de sorter som vi vanligtvis vill undvika:de som reserverar mycket mer minne än de behöver, och de som reserverar för lite. Det senare fallet är det som de flesta fokuserar på. Med otillräckligt minne reserverat (eller tillgängligt) för att slutföra den nödvändiga sorteringsoperationen i minnet, kommer en sorteringsoperatör, med några få undantag, att spilla datarader till tempdb . I verkligheten innebär detta nästan alltid att man skriver sorteringssidor till fysisk lagring (och läser tillbaka dem senare förstås).
I moderna versioner av SQL Server resulterar en utspilld sortering i en varningsikon i planer efter genomförande, som kan inkludera detaljer om hur mycket data som spilldes, hur många trådar som var inblandade och spillnivån.
Bakgrund:Spillnivåer
Tänk på uppgiften att sortera 4000MB data, när vi bara har 500MB minne tillgängligt. Självklart kan vi inte sortera hela uppsättningen i minnet på en gång, men vi kan bryta ner uppgiften:
Vi läser först 500 MB data, sorterar uppsättningen i minnet och skriver sedan resultatet till disken. Att utföra detta totalt 8 gånger förbrukar hela 4000MB-inmatningen, vilket resulterar i 8 uppsättningar sorterade data med en storlek på 500MB. Det andra steget är att utföra en 8-vägs sammanslagning av de sorterade datamängderna. Observera att en sammanslagning krävs, inte en enkel sammanlänkning av uppsättningarna eftersom data endast garanteras sorteras efter behov inom en viss 500 MB uppsättning i mellanstadiet.
I princip kunde vi läsa och slå samman en rad i taget från var och en av de åtta sorteringskörningarna, men det skulle inte vara särskilt effektivt. Istället läser vi den första delen av varje sorts körning tillbaka i minnet, säg 60 MB. Detta förbrukar 8 x 60 MB =480 MB av de 500 MB vi har tillgängliga. Vi kan sedan effektivt utföra 8-vägs sammanslagningen i minnet ett tag, och buffra den slutliga sorterade utdata med det 20 MB minne som fortfarande är tillgängligt. När var och en av buffertarna för sortkörningsminnen töms, läser vi en ny sektion av den typen som körs in i minnet. När alla sorteringskörningar har förbrukats är sorteringen klar.
Det finns några ytterligare detaljer och optimeringar som vi kan inkludera, men det är grundplanen för ett nivå 1-utsläpp, även känt som ett engångsutsläpp. En enda extra passage över data krävs för att producera den slutliga sorterade utdata.
Nu skulle en n-vägs sammanslagning teoretiskt kunna rymma en sorts vilken storlek som helst, i vilken mängd minne som helst, helt enkelt genom att öka antalet mellanliggande lokalt sorterade uppsättningar. Problemet är att när 'n' ökar, slutar vi med att vi läser och skriver mindre bitar av data. Att till exempel sortera 400 GB data i 500 MB minne skulle innebära något som en 800-vägs sammanslagning, med endast cirka 0,6 MB från varje mellansorterad uppsättning i minnet åt gången (800 x 0,6 MB =480 MB, vilket lämnar lite utrymme för en utgångsbuffert).
Flera sammanslagningspass kan användas för att kringgå detta. Den allmänna idén är att successivt slå samman små bitar till större, tills vi effektivt kan producera den slutliga sorterade utströmmen. I exemplet kan detta innebära att man slår samman 40 av de 800 first-pass-sorterade seten åt gången, vilket resulterar i 20 större bitar, som sedan kan slås samman igen för att bilda utdata. Med totalt två extra pass över data, skulle detta vara ett nivå 2-spill, och så vidare. Lyckligtvis möjliggör en linjär ökning av spillnivån en exponentiell ökning av sorteringsstorleken, så djupa sorteringsnivåer är sällan nödvändiga.
Nivå 15 000-spillet
Vid det här laget kanske du undrar vilken kombination av litet minnesbidrag och enorm datastorlek som eventuellt kan resultera i ett spill på nivå 15 000. Försöker du sortera hela Internet i 1 MB minne? Möjligen, men det är alldeles för svårt att demo. För att vara ärlig har jag ingen aning om en så genuint hög spillnivå ens är möjlig i SQL Server. Målet här (ett fusk, helt klart) är att få SQL Server att rapportera ett spill på nivå 15 000.
Den viktigaste ingrediensen är partitionering. Sedan SQL Server 2012 har vi tillåtits maximalt (bekvämt) 15 000 partitioner per objekt (stöd för 15 000 partitioner finns även på 2008 SP2 och 2008 R2 SP1, men du måste aktivera det manuellt per databas, och vara medveten om alla varningarna).
Det första vi behöver är en 15 000-elements partitionsfunktion och ett tillhörande partitionsschema. För att undvika ett riktigt enormt inline-kodblock använder följande skript dynamisk SQL för att generera de nödvändiga satserna:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Skriptet är lätt nog att modifiera till ett lägre antal om din installation kämpar med 15 000 partitioner (särskilt ur minnessynpunkt, som vi kommer att se inom kort). Nästa steg är att skapa en normal (ej partitionerad) heaptabell med en enda heltalskolumn och sedan fylla den med heltal från 1 till 15 000 inklusive:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Det borde vara klart inom 100 ms eller så. Om du har ett nummerbord tillgängligt får du gärna använda det istället för en mer setbaserad upplevelse. Sättet som bastabellen fylls på är inte viktigt. För att få ut vårt 15 000-nivåutsläpp behöver vi bara skapa ett partitionerat klustrat index på bordet:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Utförandetiden beror mycket på vilket lagringssystem som används. På min bärbara dator, med en ganska typisk konsument-SSD från ett par år sedan, tar det runt 20 sekunder, vilket är ganska betydande med tanke på att vi bara har att göra med 15 000 rader totalt. På en ganska lågspecifik Azure VM med ganska dålig I/O-prestanda tog samma test närmare 20 minuter.
Analys
Utförandeplanen för indexbygget är:
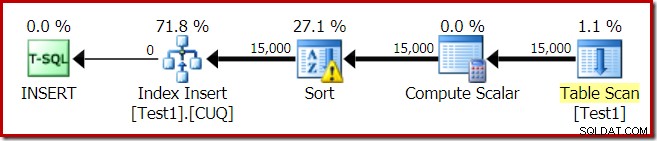
Tabellskanningen läser de 15 000 raderna från vår högtabell. Compute Scalar beräknar destinationsindexpartitionsnumret för varje rad med den interna funktionen RangePartitionNew() . Sorteringen är den mest intressanta delen av planen, så vi kommer att titta på den mer i detalj.
Först sorteringsvarningen, som visas i Plan Explorer:

En liknande varning från SSMS (tagen från en annan körning av skriptet):
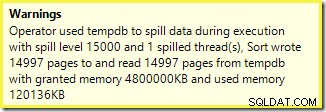
Det första att notera är rapporten om en 15 000 sorters spillnivå, som utlovat. Detta är inte helt korrekt, men detaljerna är ganska intressanta. Sorteringen i denna plan har ett Partition ID egendom, som normalt inte finns:
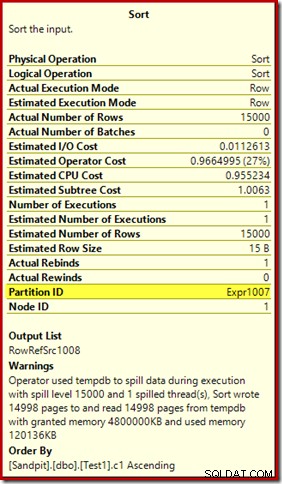
Den här egenskapen är lika med definitionen av den interna partitioneringsfunktionen i Compute Scalar.
Det här är ett ojusterat indexbygge , eftersom källan och destinationen har olika partitioneringsarrangemang. I det här fallet uppstår den skillnaden eftersom källhögtabellen inte är partitionerad, men destinationsindexet är det. Som en konsekvens skapas 15 000 separata sorteringar under körning:en per icke-tom målpartition. Var och en av dessa sorters spill till nivå 1, och SQL Server summerar alla dessa spill för att ge den slutliga sorteringsnivån på 15 000.
De 15 000 separata sorteringarna förklarar det stora minnesanslaget. Varje sorteringsinstans har en minimistorlek på 40 sidor, vilket är 40 x 8KB =320KB. De 15 000 sorteringarna kräver därför minst 15 000 x 320 kB =4 800 000 kB minne. Det är bara mindre än 4,6 GB RAM som är reserverat exklusivt för en fråga som sorterar 15 000 rader som innehåller en enda heltalskolumn. Och varje sort spills till disk, trots att de bara får en rad! Om parallellitet användes för indexuppbyggnaden skulle minnesbidraget kunna ökas ytterligare med antalet trådar. Observera också att den enskilda raden är skriven på en sida, vilket förklarar antalet sidor som skrivits till och lästs från tempdb. Det verkar finnas ett rastillstånd som innebär att det rapporterade antalet sidor ofta är några mindre än 15 000.
Det här exemplet speglar förstås ett kantfall, men det är fortfarande svårt att förstå varför varje sort spelar ut sin enda rad istället för att sortera i minnet den har fått. Kanske är detta designat av någon anledning, eller så är det helt enkelt en bugg. Hur som helst, det är fortfarande ganska underhållande att se ett slags några hundra KB data som tar så lång tid med ett 4,6 GB minne och ett spill på 15 000 nivåer. Om du inte stöter på det i en produktionsmiljö, kanske. Hur som helst är det något att vara medveten om.
Den vilseledande spillrapporten på 15 000 nivåer kommer i stort sett ner på representationsbegränsningar i showplanens resultat. Den grundläggande frågan är något som uppstår på många ställen där upprepade handlingar förekommer, till exempel på insidan av de kapslade slingornas sammanfogning. Det skulle säkert vara användbart att kunna se en mer exakt uppdelning istället för en total summa i dessa fall. Med tiden har detta område förbättrats lite, så vi har nu mer planinformation per tråd eller per partition för vissa operationer. Det är fortfarande en lång väg kvar att gå.
Det är fortfarande mindre bra att 15 000 separata nivå 1-utsläpp rapporteras här som ett enda spill på 15 000 nivåer.
Testvarianter
Den här artikeln handlar mer om att lyfta fram planinformationsbegränsningar och potentialen för dålig prestanda när extrema antal partitioner används, än om att göra den specifika exempeloperationen mer effektiv, men det finns ett par intressanta varianter jag också vill titta på .
Online, sortera i tempdb
Utför samma åtgärd för att skapa ett partitionerat index med ONLINE = ON, SORT_IN_TEMPDB = ON lider inte av samma enorma minnesbidrag och spill:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Observera att du använder ONLINE i sig är inte tillräckligt. Faktum är att det resulterar i samma plan som tidigare med alla samma problem, plus en extra overhead för att bygga varje indexpartition online. För mig resulterar det i en exekveringstid på långt över en minut. Gud vet hur lång tid det skulle ta på en lågspecifik Azure-instans med fruktansvärda I/O-prestanda.
Hur som helst, exekveringsplanen med ONLINE = ON, SORT_IN_TEMPDB = ON är:

Sorteringen utförs innan destinationspartitionsnumret beräknas. Den har inte egenskapen Partition ID, så det är bara en normal sort. Hela operationen pågår i cirka tio sekunder (det finns fortfarande många partitioner att skapa). Den reserverar mindre än 3MB minne och använder maximalt 816KB. En rejäl förbättring jämfört med 4,6 GB och 15 000 spill.
Indexera först, sedan data
Liknande resultat kan erhållas genom att först skriva data till en högtabell:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Skapa sedan en tom partitionerad klustrad tabell och infoga data från högen:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Detta tar cirka tio sekunder, med ett minne på 2 MB och inget spill:
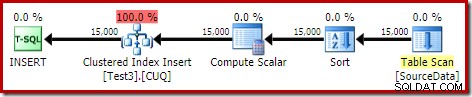
Naturligtvis kan sorteringen också undvikas helt genom att indexera den (o-partitionerade) källtabellen och infoga data i indexordning (den bästa sorteringen är ingen sortering alls, kom ihåg).
Partitionerad heap, sedan data och sedan index
För den här sista varianten skapar vi först en partitionerad hög och laddar de 15 000 testraderna:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Det skriptet körs i en sekund eller två, vilket är ganska bra. Det sista steget är att skapa det partitionerade klustrade indexet:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Det är en total katastrof, både ur prestationssynpunkt och ur ett informationsperspektiv för showplanen. Själva operationen pågår i knappt en minut, med följande utförandeplan:

Detta är en samlokaliserad insättningsplan. Constant Scan innehåller en rad för varje partitions-id. Den inre sidan av slingan söker till den aktuella uppdelningen av högen (ja, en sökning på en hög). Sorteringen har en partitions-id-egenskap (trots att den är konstant per loop-iteration) så det finns en sortering per partition och det oönskade spillbeteendet. Statistikvarningen på högbordet är falsk.
Roten av infogningsplanen indikerar att ett minnesbidrag på 1MB reserverades, med maximalt 144KB använt:
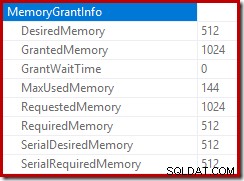
Sorteringsoperatören rapporterar inte ett spill på nivå 15 000, men gör annars en hel röra av den inblandade per-loop iterationens matematik:

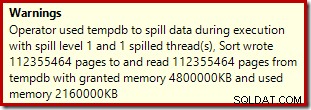
Övervakning av minnet ger DMV under körning visar att denna fråga faktiskt bara reserverar 1MB, med maximalt 144KB som används vid varje iteration av loopen. (Däremot är 4,6 GB minnesreservation i det första testet absolut äkta.) Detta är förstås förvirrande.
Problemet (som nämnts tidigare) är att SQL Server blir förvirrad över hur man bäst rapporterar om vad som hänt under många iterationer. Det är förmodligen inte praktiskt att inkludera planprestandainformation per partition per iteration, men det går inte att komma ifrån det faktum att det nuvarande arrangemanget ger förvirrande resultat ibland. Vi kan bara hoppas att man en dag kan hitta ett bättre sätt att rapportera denna typ av information, i ett mer konsekvent format.