Jag har haft många samtal nyligen om olika typer av arbetsbelastningar – särskilt att förstå om en arbetsbelastning är parametriserad, adhoc eller en blandning. Det är en av sakerna vi tittar på under en hälsorevision, och Kimberly har en bra fråga från sin Plan-cache och inlägg om optimering för adhoc-arbetsbelastningar som är en del av vår verktygslåda. Jag har kopierat frågan nedan, och om du aldrig har kört den mot någon av dina produktionsmiljöer tidigare, ta dig definitivt tid att göra det.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Om jag kör den här frågan mot en produktionsmiljö kan vi få utdata som följande:
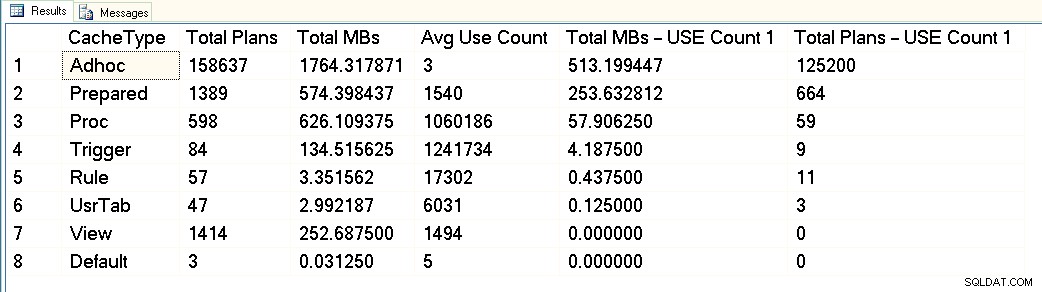
Från den här skärmdumpen kan du se att vi har cirka 3 GB totalt dedikerat till plancachen, och av det är 1,7 GB för planerna med över 158 000 adhoc-frågor. Av dessa 1,7 GB används cirka 500 MB för 125 000 planer som exekverar EN endast tid. Cirka 1 GB av planens cache är för förberedda planer och procedurplaner, och de tar bara upp cirka 300 MB utrymme. Men notera det genomsnittliga antalet användningar – långt över 1 miljon för procedurer. När jag tittar på denna utdata skulle jag kategorisera den här arbetsbelastningen som blandad – några parametriserade frågor, några adhoc.
Kimberlys blogginlägg diskuterar alternativ för att hantera en plancache fylld med många adhoc-frågor. Plan cache bloat är bara ett problem du måste brottas med när du har en adhoc-arbetsbelastning, och i det här inlägget vill jag utforska effekten det kan ha på CPU som ett resultat av alla kompilationer som måste inträffa. När en fråga körs i SQL Server går den igenom kompilering och optimering, och det finns overhead i samband med denna process, vilket ofta visar sig som CPU-kostnad. När en frågeplan är i cachen kan den återanvändas. Frågor som är parametriserade kan sluta med att återanvända en plan som redan finns i cacheminnet, eftersom frågetexten är exakt densamma. När en adhoc-fråga körs kommer den bara att återanvända planen i cachen om den har exakt samma text och inmatningsvärden .
Inställningar
För vår testning kommer vi att generera en slumpmässig sträng i TSQL och sammanfoga den till en fråga så att varje exekvering har ett annat bokstavligt värde. Jag har packat detta i en lagrad procedur som anropar frågan med Dynamic String Execution (EXEC @QueryString), så den beter sig som en adhoc-sats. Att anropa det från en lagrad procedur innebär att vi kan köra det ett känt antal gånger.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
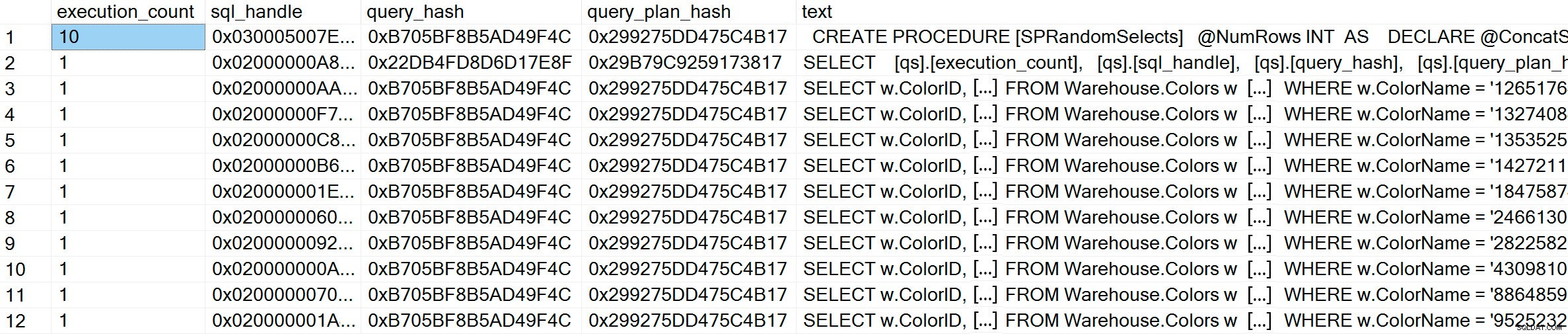
GO Efter exekvering, om vi kontrollerar planens cache, kan vi se att vi har 10 unika poster, var och en med ett execution_count på 1 (zooma in på bilden om det behövs för att se de unika värdena för predikatet):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Nu skapar vi en nästan identisk lagrad procedur som kör samma fråga, men parametriserad:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO Inom plancachen, förutom de 10 adhoc-frågorna, ser vi en post för den parameteriserade frågan som har körts 10 gånger. Eftersom inmatningen är parametriserad, även om väldigt olika strängar skickas in i parametern, är frågetexten exakt densamma:
Test
Nu när vi förstår vad som händer i plancachen, låt oss skapa mer belastning. Vi kommer att använda en kommandoradsfil som anropar samma .sql-fil på 10 olika trådar, där varje fil anropar den lagrade proceduren 10 000 gånger. Vi rensar planens cache innan vi börjar, och fångar total CPU% och SQL-kompilationer/sek med PerfMon medan skripten körs.
Adhoc.sql-filinnehåll:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Parameterized.sql-filinnehåll:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Exempel på kommandofil (visas i Anteckningar) som anropar .sql-filen:
Exempel på kommandofil (visas i Anteckningar) som skapar 10 trådar som var och en anropar filen Run_Adhoc.cmd:
Efter att ha kört varje uppsättning frågor totalt 100 000 gånger, om vi tittar på plancachen ser vi följande:

Det finns mer än 10 000 adhoc-planer i planens cache. Du kanske undrar varför det inte finns en plan för alla 100 000 adhoc-förfrågningar som körs, och det har att göra med hur planens cache fungerar (den är storlek baserat på tillgängligt minne, när oanvända planer har åldrats, etc.). Det avgörande är att så många adhoc-planer finns, jämfört med vad vi ser för resten av cachetyperna.
PerfMon-data, som visas nedan, är mest talande. Exekveringen av de 100 000 parametriserade frågorna slutfördes på mindre än 15 sekunder, och det fanns en liten topp i Compilations/sek i början, vilket knappt märks på grafen. Samma antal adhoc-körningar tog drygt 60 sekunder att slutföra, med kompilationer/sek. spik nära 2000 innan det sjönk närmare 1000 runt 45 sekunders strecket, med CPU nära eller på 100 % under större delen av tiden.
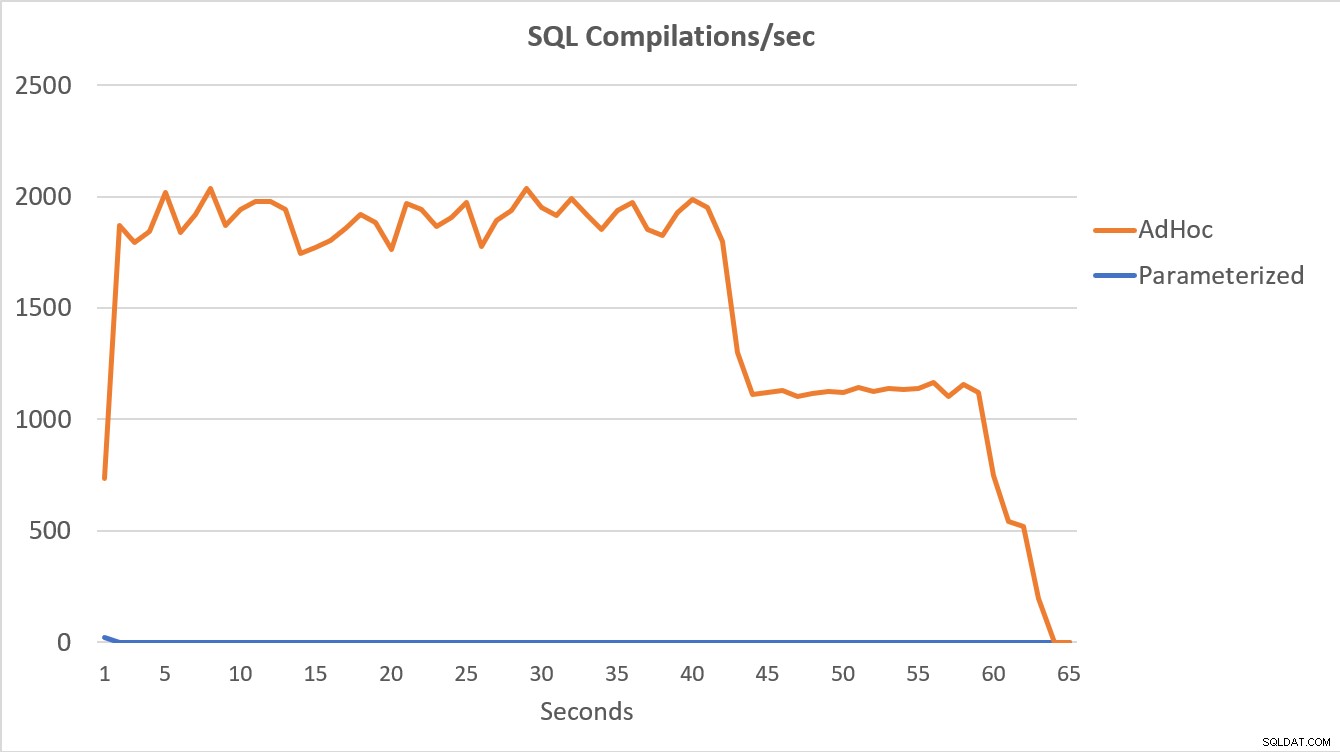
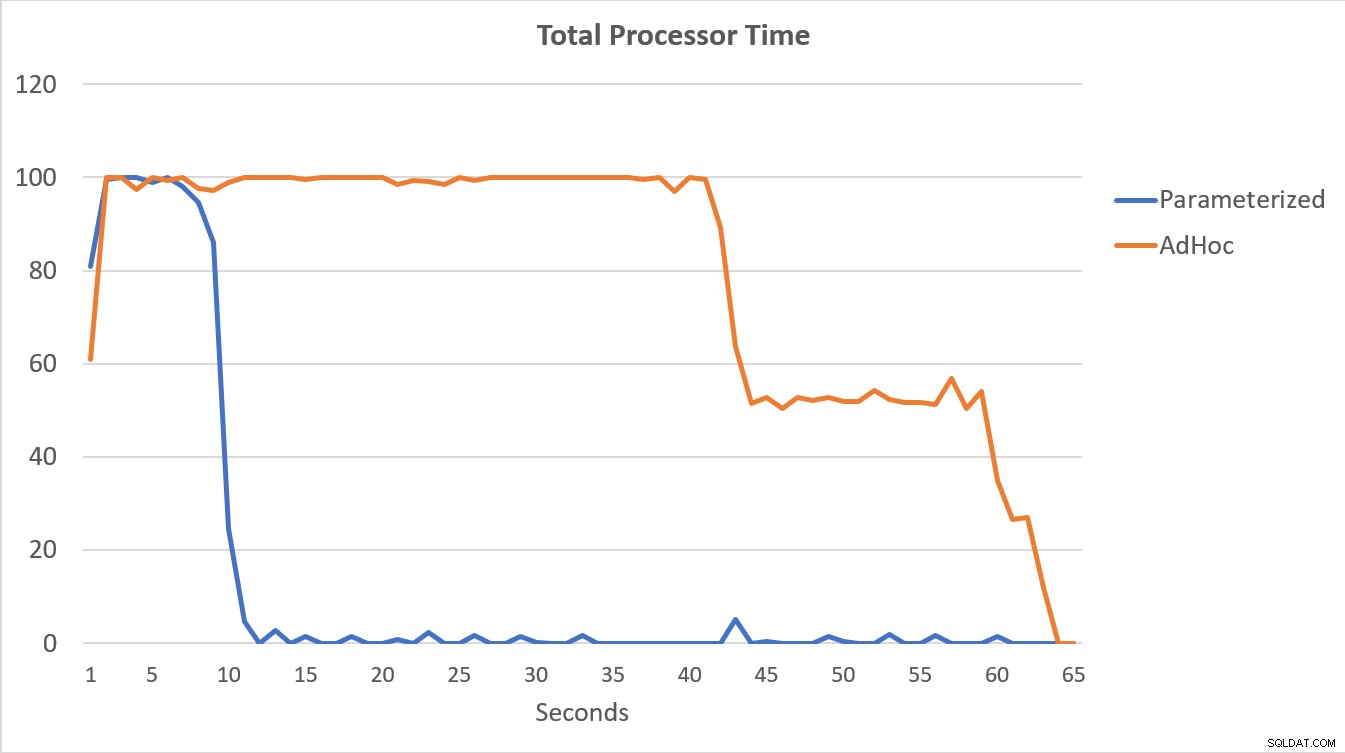
Sammanfattning
Vårt test var extremt enkelt eftersom vi bara skickade in varianter för en adhoc-fråga, medan vi i en produktionsmiljö kan ha hundratals eller tusentals olika varianter för hundratals eller tusentals av olika adhoc-frågor. Prestandapåverkan av dessa adhoc-frågor är inte bara plancachen som uppstår, men titta på plancachen är ett bra ställe att börja om du inte är bekant med vilken typ av arbetsbelastning du har. En stor mängd adhoc-frågor kan driva kompilationer och därför CPU, vilket ibland kan maskeras genom att lägga till mer hårdvara, men det kan absolut komma en punkt där CPU blir en flaskhals. Om du tror att detta kan vara ett problem, eller potentiellt problem, i din miljö, leta sedan efter vilka adhoc-frågor som körs oftast och se vilka alternativ du har för att parametrisera dem. Missförstå mig inte – det finns potentiella problem med parametriserade frågor (t.ex. planstabilitet på grund av dataskev), och det är ett annat problem du kan behöva arbeta igenom. Oavsett din arbetsbelastning är det viktigt att förstå att det sällan finns en "ställ in det och glöm det"-metod för kodning, konfiguration, underhåll, etc. SQL Server-lösningar är levande, andande enheter som alltid förändras och tar ständig omsorg och matning till fungera tillförlitligt. En av uppgifterna för en DBA är att hålla koll på den förändringen och hantera prestanda så bra som möjligt – oavsett om det är relaterat till adhoc eller parametriserade prestandautmaningar.