Tidigare denna månad publicerade jag ett tips om något som vi förmodligen alla önskar att vi inte behövde göra:sortera eller ta bort dubbletter från avgränsade strängar, vanligtvis med användardefinierade funktioner (UDF). Ibland behöver du sätta ihop listan igen (utan dubbletter) i alfabetisk ordning, och ibland kan du behöva behålla den ursprungliga ordningen (det kan till exempel vara listan med nyckelkolumner i ett dåligt index).
För min lösning, som adresserar båda scenarierna, använde jag en taltabell, tillsammans med ett par användardefinierade funktioner (UDF) – en för att dela strängen, den andra för att sätta ihop den igen. Du kan se det tipset här:
- Ta bort dubbletter från strängar i SQL Server
Naturligtvis finns det flera sätt att lösa detta problem; Jag gav bara en metod att prova om du har fastnat med strukturdata. Red-Gates @Phil_Factor följde upp med ett snabbt inlägg som visade hans tillvägagångssätt, som undviker funktionerna och siffertabellen och väljer istället inline XML-manipulation. Han säger att han föredrar att ha frågor med ett påstående och undvika både funktioner och rad-för-rad-behandling:
- Avduplicera avgränsade listor i SQL Server
Sedan postade en läsare, Steve Mangiameli, en looping-lösning som en kommentar till tipset. Hans resonemang var att användningen av en siffertabell verkade överkonstruerad för honom.
Vi tre av oss misslyckades alla med att ta itu med en aspekt av detta som vanligtvis kommer att vara ganska viktig om du utför uppgiften tillräckligt ofta eller på någon skala:prestanda .
Testning
Nyfiken på att se hur väl inline-XML och looping-metoderna skulle fungera jämfört med min taltabellbaserade lösning, konstruerade jag en fiktiv tabell för att utföra några tester; mitt mål var 5 000 rader, med en genomsnittlig stränglängd på mer än 250 tecken och minst 10 element i varje sträng. Med en mycket kort cykel av experiment kunde jag uppnå något mycket nära detta med följande kod:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Detta gav en tabell med exempelrader som såg ut så här (värden trunkerade):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Data som helhet hade följande profil, som borde vara tillräckligt bra för att avslöja eventuella prestandaproblem:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Observera att jag bytte till varchar här från nvarchar i den ursprungliga artikeln, eftersom proven som Phil och Steve levererade antog varchar , strängar med max 255 eller 8000 tecken, en-teckenavgränsare, etc. Jag har lärt mig min läxa på den hårda vägen, att om du ska ta någons funktion och inkludera den i prestationsjämförelser, ändrar du så lite som möjligt – helst ingenting. I verkligheten skulle jag alltid använda nvarchar och inte anta något om den längsta möjliga strängen. I det här fallet visste jag att jag inte förlorade någon data eftersom den längsta strängen bara är 2 905 tecken, och i den här databasen har jag inga tabeller eller kolumner som använder Unicode-tecken.
Därefter skapade jag mina funktioner (som kräver en siffertabell). En läsare upptäckte ett problem i funktionen i mitt tips, där jag antog att avgränsaren alltid skulle vara ett enda tecken, och rättade till det här. Jag konverterade också nästan allt till varchar(8000) för att jämna ut spelplanen när det gäller strängtyper och längder.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Därefter skapade jag en enda, inline tabellvärderad funktion som kombinerade de två funktionerna ovan, något som jag nu önskar att jag hade gjort i den ursprungliga artikeln, för att undvika den skalära funktionen helt och hållet. (Även om det är sant att inte alla skalära funktioner är fruktansvärda i skala, det finns väldigt få undantag.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Jag skapade också separata versioner av inline TVF som var dedikerade till vart och ett av de två sorteringsvalen, för att undvika flyktigheten i CASE uttryck, men det visade sig inte ha någon dramatisk inverkan alls.
Sedan skapade jag Steves två funktioner:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Sedan lägger jag in Phils direkta frågor i min testrigg (observera att hans frågor kodar < som < för att skydda dem från XML-tolkningsfel, men de kodar inte > eller & – Jag har lagt till platshållare ifall du behöver skydda dig mot strängar som potentiellt kan innehålla dessa problematiska tecken):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Testriggen var i princip de två frågorna, och även följande funktionsanrop. När jag validerat att de alla returnerade samma data, varvade jag skriptet med DATEDIFF ut och loggade den till en tabell:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Och sedan körde jag prestandatester på två olika system (en fyrkärnig med 8 GB och en 8-kärnig virtuell dator med 32 GB), och i varje fall på både SQL Server 2012 och SQL Server 2016 CTP 3.2 (13.0.900.73).
Resultat
Resultaten jag observerade sammanfattas i följande diagram, som visar varaktigheten i millisekunder för varje typ av fråga, i medeltal över alfabetisk och ursprunglig ordning, de fyra server/versionskombinationerna och en serie med 15 körningar för varje permutation. Klicka för att förstora:
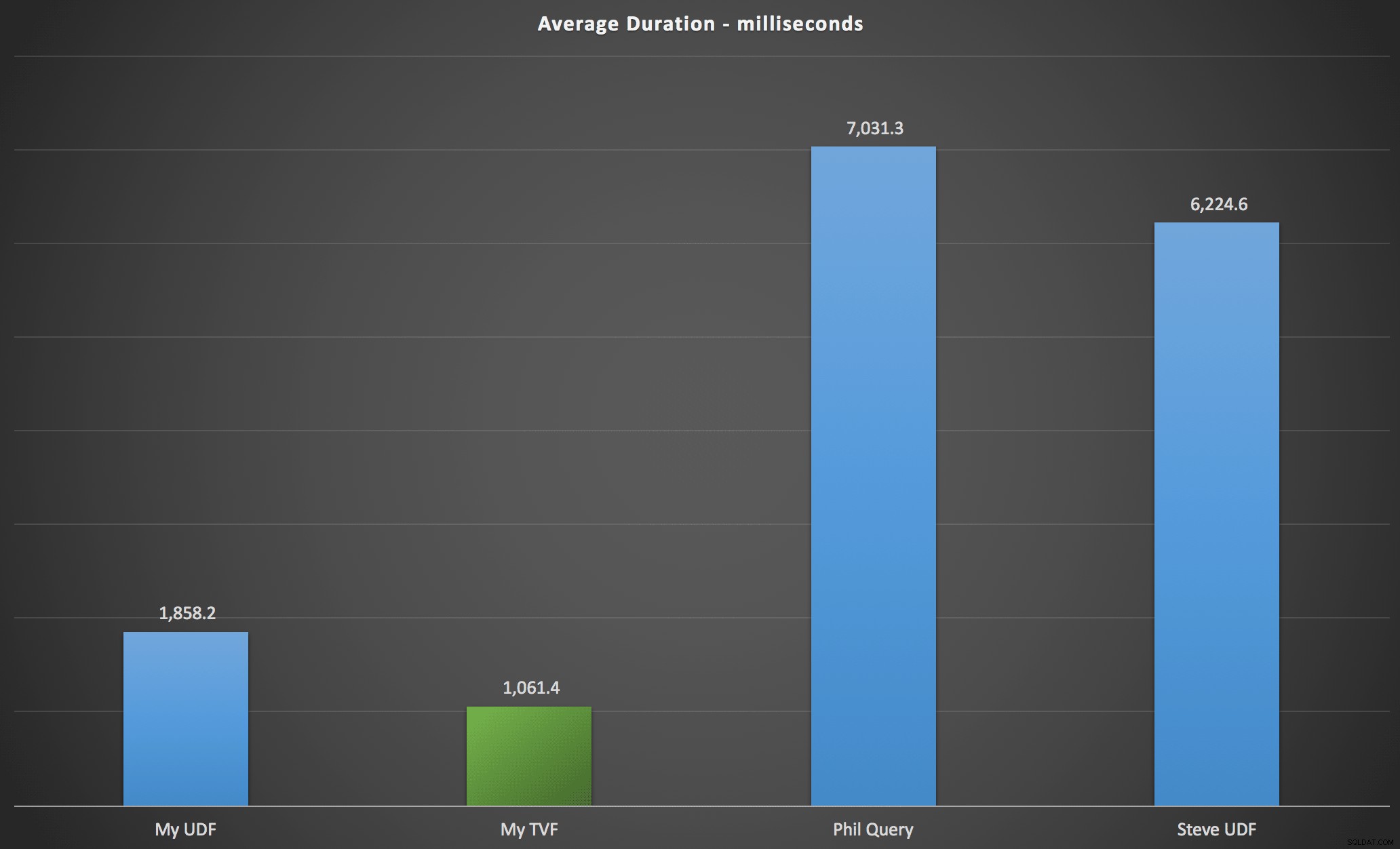
Detta visar att siffertabellen, även om den ansågs överkonstruerad, faktiskt gav den mest effektiva lösningen (åtminstone vad gäller varaktighet). Detta var förstås bättre med den enda TVF som jag implementerade på senare tid än med de kapslade funktionerna från den ursprungliga artikeln, men båda lösningarna går runt de två alternativen.
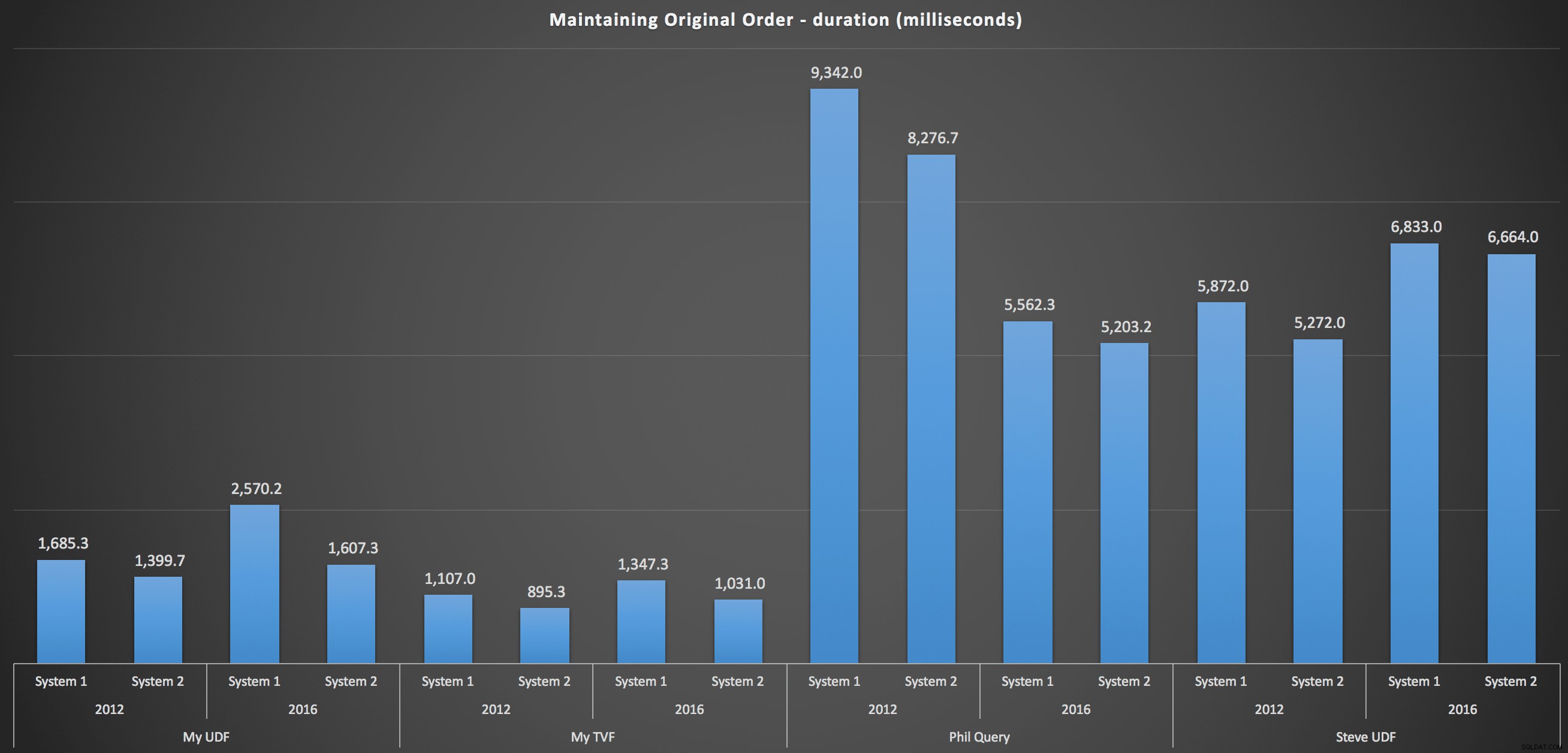
För att komma in mer i detalj, här är uppdelningarna för varje maskin, version och frågetyp, för att behålla den ursprungliga ordningen:
…och för att sätta ihop listan igen i alfabetisk ordning:
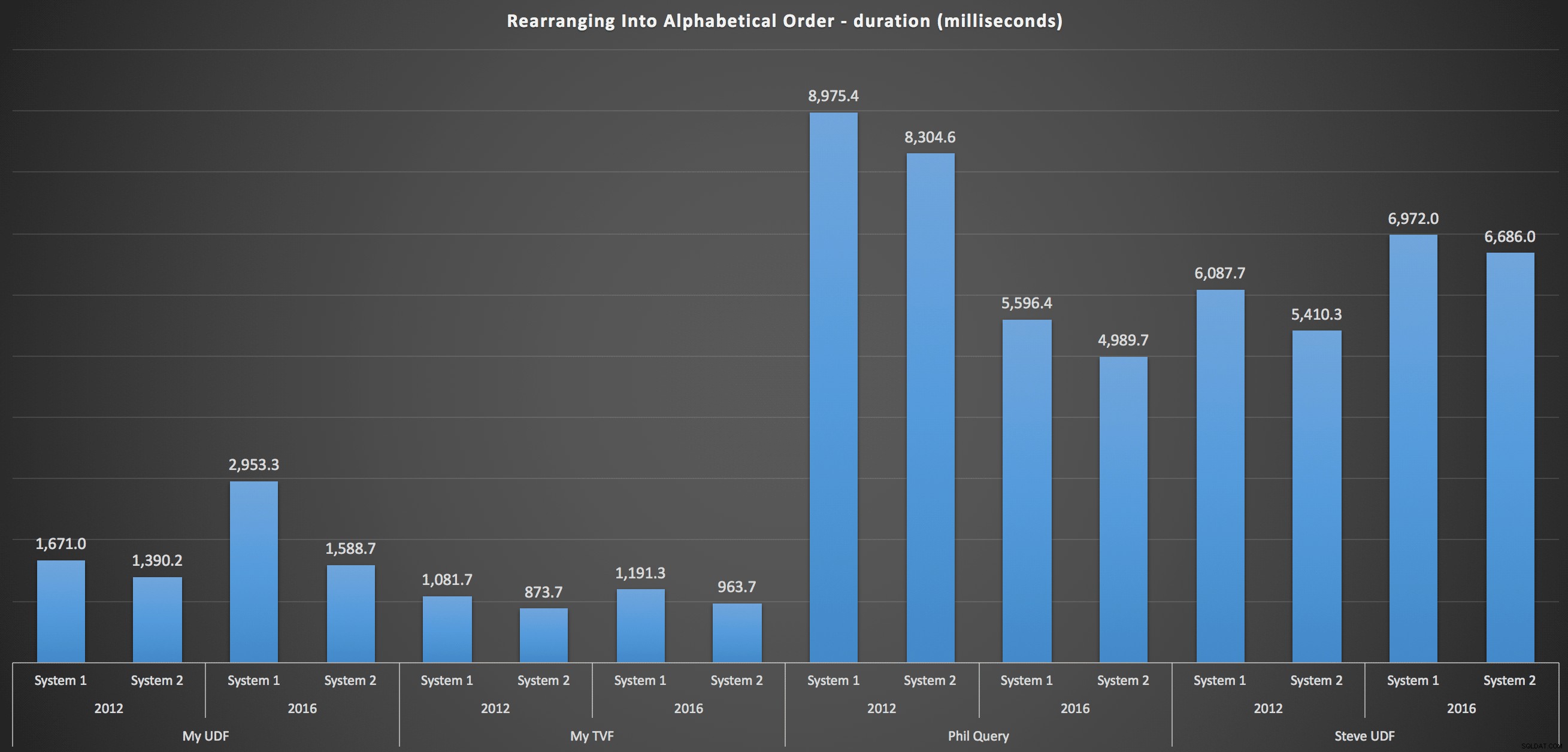
Dessa visar att sorteringsvalet hade liten inverkan på resultatet – båda diagrammen är praktiskt taget identiska. Och det är vettigt eftersom, med tanke på formen av indata, det finns inget index jag kan föreställa mig som skulle göra sorteringen mer effektiv – det är ett iterativt tillvägagångssätt oavsett hur du delar upp det eller hur du returnerar data. Men det är uppenbart att vissa iterativa tillvägagångssätt generellt sett kan vara sämre än andra, och det är inte nödvändigtvis användningen av en UDF (eller en siffertabell) som gör dem så.
Slutsats
Tills vi har inbyggd split- och sammanlänkningsfunktionalitet i SQL Server kommer vi att använda alla typer av ointuitiva metoder för att få jobbet gjort, inklusive användardefinierade funktioner. Om du hanterar en enstaka sträng åt gången, kommer du inte att se stor skillnad. Men när din data skalas upp kommer det att vara värt mödan att testa olika tillvägagångssätt (och jag menar inte på något sätt att metoderna ovan är de bästa du kommer att hitta – jag tittade inte ens på CLR, till exempel, eller andra T-SQL-metoder från denna serie).