Introduktion
Att uppnå minimal loggning med INSERT...SELECT till en tom klustrade indexmål är inte riktigt så enkelt som beskrivs i Data Performance Loading Guide .
Det här inlägget ger nya detaljer om kraven för minimal loggning när infogningsmålet är ett tomt traditionellt klustrat index. (Ordet "traditionell" där utesluter columnstore och minnesoptimerad (‘Hekaton’) klustrade tabeller). För de villkor som gäller när måltabellen är en hög, se föregående artikel i denna serie.
Sammanfattning för klustrade tabeller
Prestandaguide för dataladdning innehåller en sammanfattning på hög nivå av de villkor som krävs för minimal loggning i klustrade tabeller:
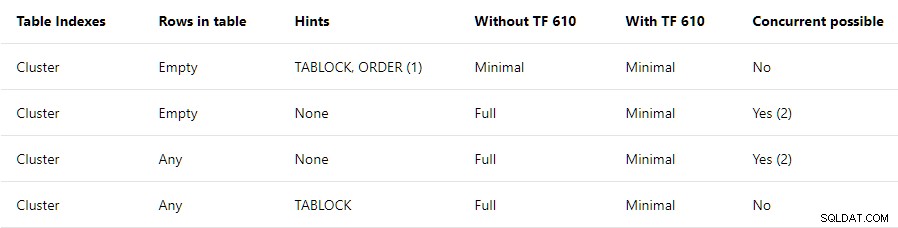
Det här inlägget handlar om enbart den övre raden . Det står att TABLOCK och ORDER tips krävs, med en notering som säger:
Om du använder BULK INSERT måste beställningstipset användas.
Töm mål med bordslås
Sammanfattningen översta raden antyder att alla inlägg till ett tomt klustrade index kommer att loggas minimalt så länge som TABLOCK och ORDER tips är specificerade. TABLOCK ledtråd krävs för att aktivera RowSetBulk anläggning som används för högbordsbulklaster. En ORDER ledtråd krävs för att säkerställa att rader kommer till Clustered Index Insert planoperatör i målindex nyckelordning . Utan denna garanti kan SQL Server lägga till indexrader som inte är korrekt sorterade, vilket inte skulle vara bra.
Till skillnad från andra bulkladdningsmetoder är det inte möjligt för att ange önskad ORDER tips om en INSERT...SELECT påstående. Det här tipset är inte detsamma som att använda en ORDER BY sats på INSERT...SELECT påstående. En ORDER BY sats på en INSERT garanterar bara hur någon identitet värden tilldelas, inte radinfogningsordning.
För INSERT...SELECT , gör SQL Server sin egen beslutsamhet huruvida rader ska presenteras för Clustered Index Insert operatör i nyckelordning eller inte. Resultatet av denna bedömning är synligt i genomförandeplaner genom DMLRequestSort egenskapen för Infoga operatör. DMLRequestSort egendom måste ställas in på true för INSERT...SELECT in i ett index för att minimalt loggas . När den är inställd på false , minimal loggning kan inte inträffa.
Att ha DMLRequestSort inställd på true är den enda acceptabla garantin av beställning av infogning av indata för SQL Server. Man kan inspektera genomförandeplanen och förutse att rader bör/kommer/måste anlända i klustrad indexordning, men utan de specifika interna garantierna tillhandahålls av DMLRequestSort , den bedömningen spelar ingen roll.
När DMLRequestSort är sant , SQL Server kan införa en explicit Sortering operatör i genomförandeplanen. Om det internt kan garantera beställning på andra sätt, Sortera kan utelämnas. Om både sorterings- och ingensorteringsalternativ är tillgängliga, kommer optimeraren att göra en kostnadsbaserad val. Kostnadsanalysen tar inte hänsyn till minimal loggning direkt; den drivs av de förväntade fördelarna med sekventiell I/O och undvikande av siddelning.
DMLRequestSort-villkor
Båda följande test måste godkännas för att SQL Server ska välja att ställa in DMLRequestSort till sant vid infogning i ett tomt klustrade index med specificerad tabelllåsning:
- En uppskattning av mer än 250 rader på inmatningssidan av Clustered Index Insert operatör; och
- En uppskattad datastorlek på mer än 2 sidor . Den uppskattade datastorleken är inte ett heltal, så ett resultat på 2 001 sidor skulle uppfylla detta villkor.
(Detta kan påminna dig om villkoren för heap minimal loggning , men den obligatoriska uppskattade datastorleken här är två sidor istället för åtta.)
Beräkning av datastorlek
Den uppskattade datastorleken beräkningen här är föremål för samma egenheter som beskrivs i föregående artikel för heaps, förutom att 8-byte RID är inte närvarande.
För SQL Server 2012 och tidigare betyder detta 5 extra byte per rad ingår i datastorleksberäkningen:En byte för en intern bit flagga och fyra byte för uniquiifier (används i beräkningen även för unika index, som inte lagrar en uniquiifier ).
För SQL Server 2014 och senare, uniquiifier är korrekt utelämnad för unik index, men en extra byte för den interna biten flaggan behålls.
Demo
Följande skript bör köras på en SQL Server-utvecklingsinstans i en ny testdatabas inställd på att använda SIMPLE eller BULK_LOGGED återställningsmodell.
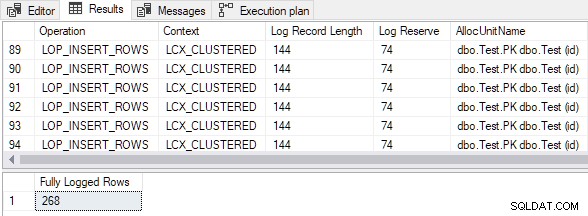
Demon laddar 268 rader till en helt ny klustrad tabell med INSERT...SELECT med TABLOCK och rapporter om transaktionsloggposterna som genererats.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Om du kör skriptet på SQL Server 2012 eller tidigare, ändra TOPP klausul i skriptet från 268 till 252, av skäl som kommer att förklaras inom ett ögonblick.)
Utdata visar att alla infogade rader loggades helt trots den tomma målgruppstabell och TABLOCK tips:
Beräknad storlek på infogningsdata
Exekveringsplanens egenskaper för Clustered Index Insert operatören visar att DMLRequestSort är inställd på false . Detta beror på att även om det uppskattade antalet rader att infoga är fler än 250 (uppfyller det första kravet), beräknas datastorlek inte överstiga två 8KB-sidor.
Beräkningsdetaljerna (för SQL Server 2014 och framåt) är följande:
- Total fast längd kolumnstorlek =54 byte :
- Typ id 104
bit=1 byte (intern). - Typ id 56
heltal=4 byte (idkolumn). - Typ id 56
heltal=4 byte (c1kolumn). - Typ id 175
char(45)=45 byte (utfyllnadkolumn).
- Typ id 104
- Noll bitmapp =3 byte .
- Radhuvud overhead =4 byte .
- Beräknad radstorlek =54 + 3 + 4 =61 byte .
- Beräknad datastorlek =61 byte * 268 rader =16 348 byte .
- Beräknade datasidor =16 384 / 8192 =1,99560546875 .
Den beräknade radstorleken (61 byte) skiljer sig från den sanna radlagringsstorleken (60 byte) med den extra en byte av intern metadata som finns i infogningsströmmen. Beräkningen tar inte heller hänsyn till de 96 byte som används på varje sida av sidhuvudet, eller andra saker som radversionering overhead. Samma beräkning på SQL Server 2012 lägger till ytterligare 4 byte per rad för uniquiifier (vilket inte finns i unika index som tidigare nämnts). De extra byten betyder att färre rader förväntas få plats på varje sida:
- Beräknad radstorlek =61 + 4 =65 byte .
- Beräknad datastorlek =65 byte * 252 rader =16 380 byte
- Beräknade datasidor =16 380 / 8192 =1,99951171875 .
Ändra TOPP sats från 268 rader till 269 (eller från 252 till 253 för 2012) gör den förväntade datastorleksberäkningen bara tippa över minimigränsen på två sidor:
- SQL Server 2014
- 61 byte * 269 rader =16 409 byte.
- 16 409 / 8192 =2,0030517578125 sidor.
- SQL Server 2012
- 65 byte * 253 rader =16 445 byte.
- 16 445 / 8192 =2,0074462890625 sidor.
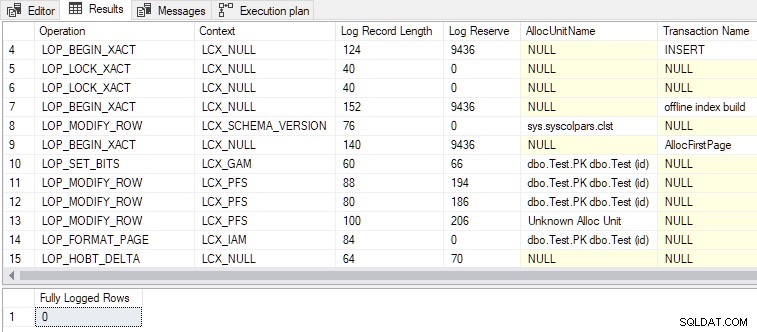
Med det andra villkoret nu också uppfyllt, DMLRequestSort är inställd på true och minimal loggning uppnås, som visas i utgången nedan:
Några andra intressanta platser:
- Totalt 79 loggposter genereras, jämfört med 328 för den fullständigt loggade versionen. Färre loggposter är det förväntade resultatet av minimal loggning.
LOP_BEGIN_XACT poster i minimalloggad poster reserverar en jämförelsevis stor mängd loggutrymme (9436 byte vardera). - Ett av transaktionsnamnen som anges i loggposterna är “offline index build” . Även om vi inte bad om att ett index skulle skapas som sådant, är bulkladdning av rader till ett tomt index i huvudsak samma operation.
- Den fullloggade insert tar ett exklusivt lås på tabellnivå (
Tab-X), medan den minimalt loggade insert tar schemamodifiering (Sch-M) precis som ett "riktigt" offlineindexbygge gör. - Masslaster en tom klustrad tabell med
INSERT...SELECTmedTABLOCKochDMRequestSortinställd på true använderRowsetBulkmekanism, precis som den minimalloggade heap loads gjorde i föregående artikel.
Kardinalitetsuppskattningar
Se upp för låga uppskattningar av kardinalitet vid Clustered Index Insert operatör. Om någon av tröskelvärdena krävs för att ställa in DMLRequestSort till sant inte nås på grund av felaktig kardinalitetsuppskattning, kommer infogningen att loggas fullständigt , oavsett det faktiska antalet rader och total datastorlek som påträffades vid körning.
Till exempel att ändra TOPP klausul i demoskriptet att använda en variabel resulterar i en fast kardinalitet gissning på 100 rader, vilket är under det minsta antalet 251 rader:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Planera cachelagring
DMLRequestSort egenskapen sparas som en del av den cachade planen. När en cachad plan återanvänds , värdet för DMLRequestSort är inte omräknat vid körningstidpunkten, om inte en omkompilering sker. Observera att omkompilering inte sker för TRIVIAL planer baserade på förändringar i statistik eller tabellkardinalitet.
Ett sätt att undvika oväntade beteenden på grund av cachelagring är att använda ett ALTERNATIV (OMKOMPILERA) antydan. Detta säkerställer rätt inställning för DMLRequestSort räknas om, till bekostnad av en kompilering vid varje exekvering.
Spårningsflagga
Det är möjligt att tvinga fram DMLRequestSort ställas in på true genom att ställa in odokumenterad och ostödd trace flag 2332, som jag skrev i Optimizing T-SQL-frågor som ändrar data. Tyvärr gör detta inte påverka minimal loggning berättigande till tomma klustrade tabeller — bilagan måste fortfarande uppskattas till fler än 250 rader och 2 sidor. Denna spårningsflagga påverkar annan minimalloggning scenarier, som behandlas i den sista delen av denna serie.
Sammanfattning
Massladdar en tom klustrade index med INSERT...SELECT återanvänder RowsetBulk mekanism som används för att masslasta högbord. Detta kräver tabelllåsning (normalt uppnås med en TABLOCK). tips) och en ORDER antydan. Det finns inget sätt att lägga till en ORDER ledtråd till en INSERT...SELECT påstående. Som en konsekvens uppnås minimal loggning till en tom klustrad tabell kräver att DMLRequestSort egenskapen för Clustered Index Insert operatorn är inställd på true . Detta garanti till SQL Server som rader presenteras för Infoga operatören kommer i målindexnyckelordning. Effekten är densamma som när du använder ORDER tips tillgänglig för andra massinsättningsmetoder som BULK INSERT och bcp .
För att DMLRequestSort ställas in på true , det måste finnas:
- Fler än 250 rader uppskattad ska införas; och
- En uppskattad infoga datastorlek på mer än två sidor .
Den uppskattade infoga beräkning av datastorlek inte matcha resultatet av att multiplicera exekveringsplanens uppskattade antal rader och uppskattad radstorlek egenskaper vid ingången till Infoga operatör. Den interna beräkningen (felaktigt) inkluderar en eller flera interna kolumner i infogningsströmmen, som inte finns kvar i det slutliga indexet. Den interna beräkningen tar inte heller hänsyn till sidhuvuden eller andra omkostnader som radversionering.
När du testar eller felsöker minimal loggning problem, se upp för låga uppskattningar av kardinalitet och kom ihåg att inställningen för DMLRequestSort cachelagras som en del av exekveringsplanen.
Den sista delen av denna serie beskriver de villkor som krävs för att uppnå minimal loggning utan att använda RowsetBulk mekanism. Dessa motsvarar direkt de nya faciliteterna som lagts till under spårningsflagga 610 till SQL Server 2008, och ändrades sedan till att vara på som standard från SQL Server 2016 och framåt.