SQL Server 2012 AlwaysOn Availability Groups kräver en databasspeglingsslutpunkt för varje SQL Server-instans som kommer att vara värd för en tillgänglighetsgruppreplik och/eller databasspeglingssession. Denna SQL Server-instansslutpunkt delas sedan av en eller flera tillgänglighetsgruppreplikor och/eller databasspeglingssessioner och är mekanismen för kommunikation mellan den primära repliken och de associerade sekundära replikerna.
Beroende på datamodifieringsarbetsbelastningen på den primära repliken kan kraven på tillgänglighetsgruppmeddelanden vara icke-triviala. Denna aktivitet är också känslig för trafik från samtidig gruppaktivitet som inte är tillgänglig. Om genomströmningen lider på grund av försämrad bandbredd och samtidig trafik, kan du överväga att isolera tillgänglighetsgrupptrafiken till sin egen dedikerade nätverksadapter för varje SQL Server-instans som är värd för en tillgänglighetsreplik. Det här inlägget kommer att beskriva denna process och även kortfattat beskriva vad du kan förvänta dig att se i ett scenario med försämrad genomströmning.
För den här artikeln använder jag ett fem noder virtuellt gäst Windows Server Failover Cluster (WSFC). Varje nod i WSFC har sin egen fristående SQL Server-instans som använder icke-delad lokal lagring. Varje nod har också en separat virtuell nätverksadapter för offentlig kommunikation, en virtuell nätverksadapter för WSFC-kommunikation och en virtuell nätverksadapter som vi kommer att dedikera till tillgänglighetsgruppkommunikation. I detta inlägg kommer vi att fokusera på informationen som behövs för de dedikerade nätverksadaptrarna för tillgänglighetsgruppen på varje nod:
| WSFC-nodnamn | Tillgänglighetsgrupp NIC TCP/IPv4-adresser |
|---|---|
| SQL2K12-SVR1 | 192.168.20.31 |
| SQL2K12-SVR2 | 192.168.20.32 |
| SQL2K12-SVR3 | 192.168.20.33 |
| SQL2K12-SVR4 | 192.168.20.34 |
| SQL2K12-SVR5 | 192.168.20.35 |
Att skapa en tillgänglighetsgrupp med ett dedikerat nätverkskort är nästan identiskt med en delad nätverkskortsprocess, bara för att "binda" tillgänglighetsgruppen till ett specifikt nätverkskort måste jag först ange LISTENER_IP argument i CREATE ENDPOINT kommandot, med de ovannämnda IP-adresserna för mina dedikerade nätverkskort. Nedan visar skapandet av varje slutpunkt över de fem WSFC-noderna:
:CONNECT SQL2K12-SVR1
USE [master];
GO
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = (192.168.20.31))
FOR DATA_MIRRORING (ROLE = ALL, ENCRYPTION = REQUIRED ALGORITHM AES);
GO
IF (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') <> 0
BEGIN
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
END
GO
USE [master];
GO
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [SQLSKILLSDEMOS\SQLServiceAcct];
GO
:CONNECT SQL2K12-SVR2
-- ...repeat for other 4 nodes... Efter att ha skapat dessa slutpunkter associerade med det dedikerade nätverkskortet, är resten av mina steg för att ställa in tillgänglighetsgrupptopologin inte annorlunda än i ett delat nätverkskort.
Efter att ha skapat min tillgänglighetsgrupp, om jag börjar köra datamodifieringsbelastning mot de primära repliktillgänglighetsdatabaserna, kan jag snabbt se att tillgänglighetsgruppens kommunikationstrafik flyter på det dedikerade nätverkskortet med Task Manager på nätverksfliken (det första avsnittet är genomströmningen för den dedikerade tillgänglighetsgruppen NIC):
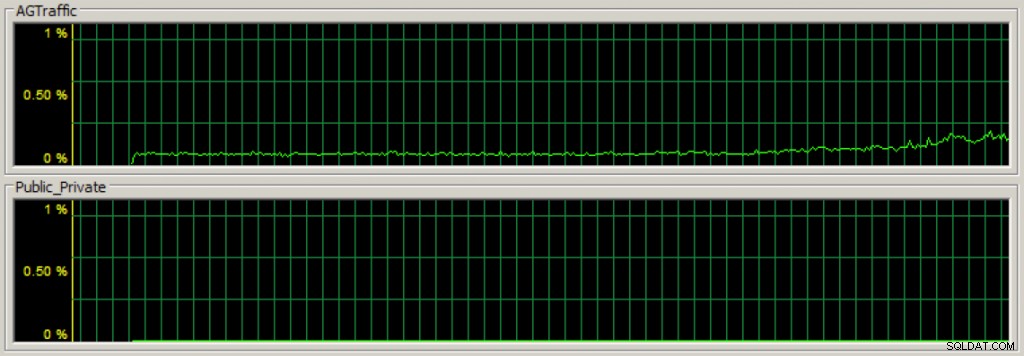
Och jag kan också spåra statistiken med hjälp av olika prestandaräknare. I bilden nedan är Inetl[R] PRO_1000 MT Network Connection _2 min dedikerade tillgänglighetsgrupp NIC och har majoriteten av NIC-trafiken jämfört med de två andra NIC:erna:

Att nu ha ett dedikerat nätverkskort för tillgänglighetsgrupptrafik kan vara ett sätt att isolera aktivitet och teoretiskt förbättra prestandan, men om ditt dedikerade nätverkskort har otillräcklig bandbredd, som du kan förvänta dig kommer prestanda att bli lidande och tillgänglighetsgrupptopologins hälsa försämras.
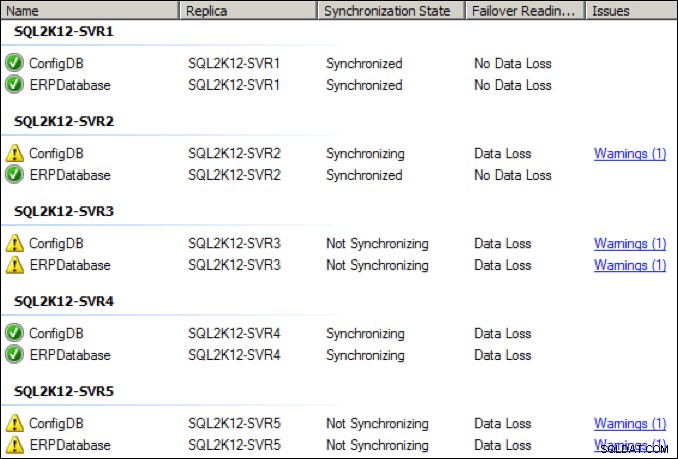
Till exempel ändrade jag den dedikerade tillgänglighetsgruppen NIC på den primära repliken till en utgående överföringsbandbredd på 28,8 Kbps för att se vad som skulle hända. Det behöver inte sägas att det inte var bra. NIC-genomströmningen för tillgänglighetsgruppen sjönk avsevärt:

Inom några sekunder försämrades hälsotillståndet hos de olika replikerna, och ett par av replikerna flyttade till ett tillstånd "inte synkroniseras":
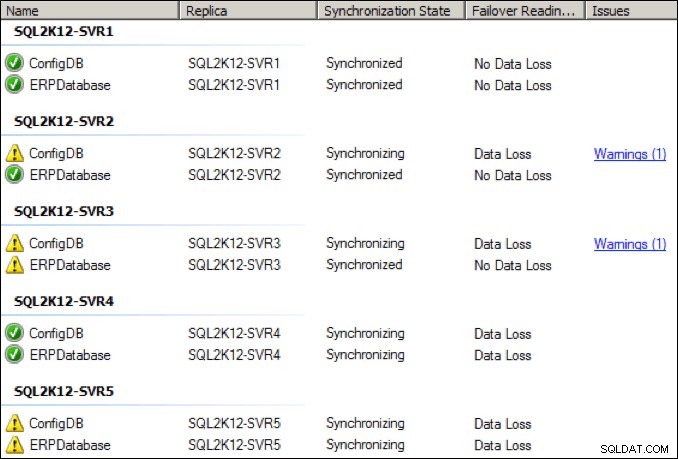
Jag ökade det dedikerade nätverkskortet på den primära repliken till 64 Kbps och efter några sekunder kom det också en första ikappspets:

Medan saker förbättrades, såg jag periodiska frånkopplingar och hälsovarningar vid denna lägre NIC-genomströmningsinställning:
Hur är det med tillhörande väntestatistik för den primära repliken?
När det fanns gott om bandbredd på det dedikerade nätverkskortet och alla tillgänglighetsrepliker var i ett sunt tillstånd, såg jag följande distribution under mina dataladdningar under en period på två minuter:
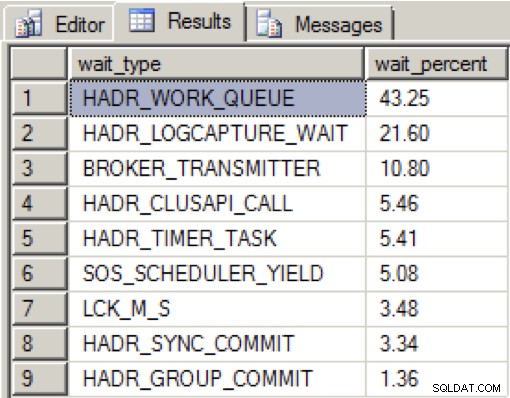
HADR_WORK_QUEUE representerar en förväntad bakgrundsarbetstråd som väntar på nytt arbete. HADR_LOGCAPTURE_WAIT representerar ytterligare en väntad väntan på att nya loggposter blir tillgängliga och förväntas enligt Books Online om loggskanningen fångas upp eller läser från disken.
När jag minskade genomströmningen av NIC tillräckligt för att få tillgänglighetsgruppen till ett ohälsosamt tillstånd, var väntetypsfördelningen som följer:
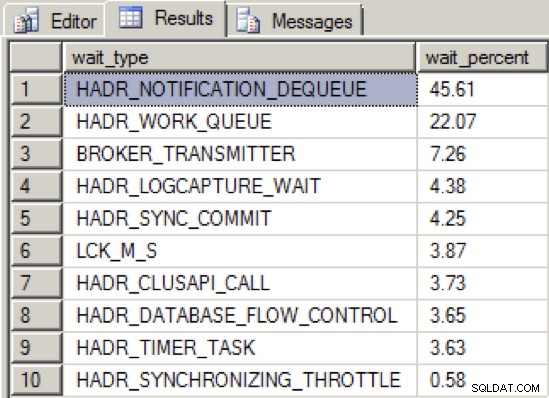
Vi ser nu en ny toppväntningstyp, HADR_NOTIFICATION_DEQUEUE . Detta är en av dessa väntetyper för "endast för intern användning" som definieras av Books Online, som representerar en bakgrundsuppgift som behandlar WSFC-meddelanden. Det som är intressant är att denna väntetyp inte pekar direkt på ett problem, och ändå visar testerna att denna väntetyp stiger till toppen i samband med försämrad tillgänglighet för gruppmeddelanden.
Så slutsatsen är att isolera din tillgänglighetsgruppaktivitet till ett dedikerat nätverkskort kan vara fördelaktigt om du tillhandahåller en nätverksgenomströmning med tillräcklig bandbredd. Men om du inte kan garantera bra bandbredd även om du använder ett dedikerat nätverk, kommer din tillgänglighetsgrupptopologi att bli lidande.