Det snabbaste sättet att beräkna en median använder SQL Server 2012 OFFSET tillägg till ORDER BY klausul. Med en nära sekund använder den näst snabbaste lösningen en (eventuellt kapslad) dynamisk markör som fungerar på alla versioner. Den här artikeln tittar på en vanlig ROW_NUMBER före 2012 lösning på medianberäkningsproblemet för att se varför det fungerar sämre och vad som kan göras för att det ska gå snabbare.
Single Median Test
Exempeldata för detta test består av en enda tio miljoner radtabell (reproducerad från Aaron Bertrands originalartikel):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); OFFSET-lösningen
För att sätta riktmärket, här är SQL Server 2012 (eller senare) OFFSET-lösning skapad av Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
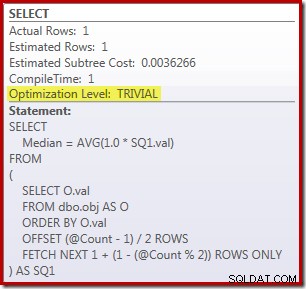
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Frågan för att räkna raderna i tabellen kommenteras och ersätts med ett hårdkodat värde för att koncentrera sig på kärnkodens prestanda. Med en varm cache och insamling av exekveringsplan avstängd kör den här frågan i 910 ms i genomsnitt på min testmaskin. Utförandeplanen visas nedan:

Som en sidoanteckning är det intressant att denna måttligt komplexa fråga kvalificerar sig för en trivial plan:
ROW_NUMBER-lösningen
För system som kör SQL Server 2008 R2 eller tidigare, använder den bästa prestanda av de alternativa lösningarna en dynamisk markör som nämnts tidigare. Om du inte kan (eller inte vill) överväga det som ett alternativ är det naturligt att överväga att emulera 2012 års OFFSET exekveringsplan med ROW_NUMBER .
Grundidén är att numrera raderna i lämplig ordning och sedan filtrera efter bara en eller två rader som behövs för att beräkna medianen. Det finns flera sätt att skriva detta i Transact SQL; en kompakt version som fångar alla nyckelelement är följande:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
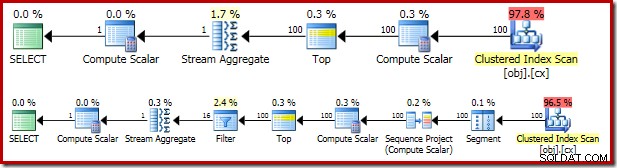
Den resulterande exekveringsplanen är ganska lik OFFSET version:

Det är värt att titta på var och en av planoperatörerna i sin tur för att förstå dem till fullo:
- Segmentoperatören är överflödig i denna plan. Det skulle krävas om
ROW_NUMBERrankningsfunktionen hade enPARTITION BYklausul, men det gör den inte. Trots det finns det kvar i den slutliga planen. - Sekvensprojektet lägger till ett beräknat radnummer till strömmen av rader.
- Compute Scalar definierar ett uttryck som är associerat med behovet av att implicit konvertera
valkolumn till numerisk så att den kan multipliceras med konstant bokstavlig1.0i frågan. Denna beräkning skjuts upp tills den behövs av en senare operatör (som råkar vara strömaggregatet). Denna körtidsoptimering innebär att den implicita konverteringen endast utförs för de två raderna som bearbetas av Stream Aggregate, inte de 5 000 001 raderna som anges för Compute Scalar. - Topoperatorn introduceras av frågeoptimeraren. Den känner igen att som mest bara den första
(@Count + 2) / 2rader behövs av frågan. Vi kunde ha lagt till enTOP ... ORDER BYi underfrågan för att göra detta explicit, men denna optimering gör det i stort sett onödigt. - Filtret implementerar villkoret i
WHEREsats, filtrerar bort alla utom de två 'mitten' raderna som behövs för att beräkna medianen (den introducerade toppen är också baserad på detta villkor). - Strömaggregatet beräknar
SUMochCOUNTav de två medianraderna. - Den slutliga Compute Scalar beräknar medelvärdet från summan och räkningen.
Rå prestanda
Jämfört med OFFSET plan kan vi förvänta oss att de ytterligare segment-, sekvensprojekt- och filteroperatörerna kommer att ha en negativ effekt på prestandan. Det är värt att ta en stund att jämföra de uppskattade kostnader för de två planerna:
OFFSET planen har en beräknad kostnad på 0,0036266 enheter, medan ROW_NUMBER planen uppskattas till 0,0036744 enheter. Det är väldigt små siffror och det är liten skillnad mellan de två.
Så det är kanske förvånande att ROW_NUMBER frågan körs faktiskt i 4000 ms i genomsnitt jämfört med 910 ms genomsnitt för OFFSET lösning. En del av denna ökning kan säkert förklaras av extraplansoperatörernas omkostnader, men en faktor fyra verkar överdriven. Det måste finnas mer i det.
Du har säkert också märkt att kardinalitetsuppskattningarna för båda uppskattade planerna ovan är ganska hopplöst fel. Detta beror på effekten av Top-operatorerna, som har ett uttryck som refererar till en variabel som deras radantalgränser. Frågeoptimeraren kan inte se innehållet i variabler vid kompilering, så den använder sin standardgissning på 100 rader. Båda planerna stöter faktiskt på 5 000 001 rader vid körning.
Allt detta är väldigt intressant, men det förklarar inte direkt varför ROW_NUMBER frågan är mer än fyra gånger långsammare än OFFSET version. Trots allt är uppskattningen av 100 raders kardinalitet lika fel i båda fallen.
Förbättra prestandan för ROW_NUMBER-lösningen
I min tidigare artikel såg vi hur den grupperade medianen OFFSET presterade testet kan nästan fördubblas genom att helt enkelt lägga till en PAGLOCK antydan. Denna ledtråd åsidosätter lagringsmotorns normala beslut att skaffa och släppa delade lås vid radgranulariteten (på grund av den låga förväntade kardinaliteten).
Som en ytterligare påminnelse, PAGLOCK ledtråd var onödig i den enda medianen OFFSET test på grund av en separat intern optimering som kan hoppa över delade lås på radnivå, vilket resulterar i att endast ett litet antal av avsiktsdelade lås tas på sidnivå.
Vi kan förvänta oss ROW_NUMBER enda medianlösning för att dra nytta av samma interna optimering, men det gör den inte. Övervakar låsaktivitet medan ROW_NUMBER fråga körs ser vi över en halv miljon individuella radnivå delade lås tas och släpps.
Så nu vet vi vad problemet är, vi kan förbättra låsprestandan på samma sätt som vi gjorde tidigare:antingen med en PAGLOCK låsgranularitetstips, eller genom att öka kardinalitetsuppskattningen med den dokumenterade spårningsflaggan 4138.
Att inaktivera "radmålet" med hjälp av spårningsflaggan är den mindre tillfredsställande lösningen av flera skäl. För det första är det bara effektivt i SQL Server 2008 R2 eller senare. Vi skulle med största sannolikhet föredra OFFSET lösning i SQL Server 2012, så detta begränsar effektivt spårningsflaggan endast till SQL Server 2008 R2. För det andra kräver användning av spårningsflaggan behörigheter på administratörsnivå, såvida den inte tillämpas via en planguide. Ett tredje skäl är att inaktivering av radmål för hela frågan kan ha andra oönskade effekter, särskilt i mer komplexa planer.
Däremot PAGLOCK tipset är effektivt, tillgängligt i alla versioner av SQL Server utan några speciella behörigheter och har inga större bieffekter utöver låsning av granularitet.
Använder PAGLOCK ledtråd till ROW_NUMBER fråga ökar prestandan dramatiskt:från 4000 ms till 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 ms resultatet är fortfarande betydligt långsammare än 910 ms för OFFSET lösning, men det är åtminstone nu i samma bollplank. Den återstående prestandaskillnaden beror helt enkelt på det extra arbetet i utförandeplanen:

I OFFSET planen bearbetas fem miljoner rader så långt som till toppen (med uttrycken definierade i Compute Scalar uppskjutna som diskuterats tidigare). I ROW_NUMBER plan måste samma antal rader bearbetas av segment, sekvensprojekt, topp och filter.