IGNORE_DUP_KEY alternativet för unika index anger hur SQL Server svarar på ett försök att INSERT dubbletter av värden:Det gäller bara för tabeller (inte vyer) och endast för inlägg. Valfri infogningsdel av en MERGE sats ignorerar någon IGNORE_DUP_KEY indexinställning.
När IGNORE_DUP_KEY är OFF , resulterar den första dubbletten som påträffas i ett fel , och ingen av de nya raderna infogas.
När IGNORE_DUP_KEY är ON , infogade rader som skulle bryta mot unika kasseras. De återstående raderna har infogats. En varning meddelande sänds ut istället för ett felmeddelande:
Artikelsammanfattning
IGNORE_DUP_KEY indexalternativ kan anges för både klustrade och icke-klustrade unika index. Att använda det på ett klustrat index kan resultera i mycket sämre prestanda än för ett icke-klustrat unikt index.
Storleken på prestandaskillnaden beror på hur många unika överträdelser som påträffas under INSERT drift. Ju fler överträdelser, desto sämre presterar det klustrade unika indexet i jämförelse. Om det inte finns några överträdelser alls kan det klustrade indexinlägget till och med prestera bättre.
Klustrade unika indexinlägg
För ett klustrat unikt index med IGNORE_DUP_KEY set, hanteras dubbletter av lagringsmotorn .
Mycket av arbetet med att infoga varje rad utförs innan dubbletten upptäcks. Till exempel en Clustered Index Insert Operatören navigerar ner i det klustrade index b-trädet till den punkt där den nya raden skulle hamna, med sidspärrar och den vanliga hierarkin av lås, innan den upptäcker dubblettnyckeln.
När villkoret för dubblettnyckeln upptäcks visas ett fel är upphöjd. Istället för att avbryta exekveringen och returnera felet till klienten, hanteras felet internt. Den problematiska raden infogas inte och körningen fortsätter och letar efter nästa rad att infoga. Om den raden stöter på en dubblettnyckel, uppstår och hanteras ett annat fel, och så vidare.
Undantag är mycket dyra att kasta och fånga. Ett betydande antal dubbletter kommer att sakta ner exekveringen mycket märkbart.
Icke-klustrade unika indexinlägg
För ett icke-klustrat unikt index med IGNORE_DUP_KEY set, hanteras dubbletter av frågeprocessorn . Dubletter upptäcks och en varning avges innan varje insättningsförsök görs.
Frågeprocessorn tar bort dubbletter från infogningsströmmen och säkerställer att inga dubbletter ses av lagringsmotorn. Som ett resultat kommer inga unika nyckelintrångsfel upp eller hanteras internt.
Avvägningen
Det finns en avvägning mellan kostnaden för att upptäcka och ta bort dubblettnycklar i exekveringsplanen, kontra kostnaden för att utföra betydande insättningsrelaterat arbete, och att kasta och fånga upp fel när en dubblett hittas.
Om dubbletter förväntas vara mycket sällsynta , kan lagringsmotorlösningen (klustrade index) mycket väl vara mer effektiv. När dubbletter är mindre sällsynta, kommer frågeprocessormetoden sannolikt att ge utdelning. Den exakta övergångspunkten kommer att bero på faktorer som körtidseffektiviteten för de exekveringsplanskomponenter som används för att upptäcka och ta bort dubbletter.
Resten av den här artikeln ger en demo och tittar mer i detalj på varför lagringsmotormetoden kan fungera så dåligt.
Demo
Följande skript skapar en tillfällig tabell med en miljon rader. Den har 1 000 unika värden och 1 000 rader för varje unikt värde. Denna datamängd kommer att användas som datakälla för infogning i tabeller med olika indexkonfigurationer.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Baslinje
Följande infogning i en tabellvariabel med ett icke-unikt klustrat index tar cirka 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Observera att IGNORE_DUP_KEY saknas på måltabellsvariabeln.
Klustrat unikt index
Att infoga samma data i ett unikt kluster index med IGNORE_DUP_KEY ställ in ON tar cirka 15 900 ms — nästan 18 gånger värre:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Icke-klusterat unikt index
Infogar data till en unik icke-klustrad index med IGNORE_DUP_KEY ställ in ON tar cirka 700 ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Resultatöversikt
Baslinjetestet tar 900 ms för att infoga alla en miljon rader. Det icke-klustrade indextestet tar 700 ms för att bara infoga de 1 000 distinkta nycklarna. Det klustrade indextestet tar 15 900 ms för att infoga samma 1 000 unika rader.
Det här testet är medvetet inställt för att markera dåliga prestanda för implementeringen av lagringsmotorn, genom att generera 999 enheter bortkastat arbete (spärrar, lås, felhantering) för varje framgångsrik rad.
Det avsedda meddelandet är inte det IGNORE_DUP_KEY kommer alltid att prestera dåligt på klustrade index, bara vad det kan, och det kan vara stor skillnad mellan klustrade och icke-klustrade index.
Clustered Index Execution Plan
Det finns inte så mycket att se i den klustrade indexinfogningsplanen:
Det finns 1 000 000 rader som skickas till Clustered Index Insert operator, som visas som "returerande" 1 000 rader. När vi gräver i plandetaljerna kan vi se:
- 1 244 008 logiska läsningar hos infogningsoperatorn.
- Största delen av körningstiden spenderas vid Infogningen operatör.
- 11 ms av
SOS_SCHEDULER_YIELDväntar (dvs. inga andra väntar).
Inget som verkligen förklarar 15 900 ms av förfluten tid.
Varför prestanda är så dålig
Det är uppenbart att denna plan kommer att behöva göra mycket arbete för varje rad:
- Navigera de klustrade index b-trädnivåerna, lås och lås allt eftersom, för att hitta insättningspunkten för den nya posten.
- Om någon av de indexsidor som behövs inte finns i minnet måste de hämtas från disken.
- Konstruera en ny b-trädrad i minnet.
- Förbered loggposter.
- Om en nyckeldubblett hittas (som inte är en spökpost), skapa ett fel, hantera det felet internt, släpp den aktuella raden och återuppta vid en lämplig punkt i koden för att bearbeta nästa kandidatrad.
Det är en hel del arbete, och kom ihåg att allt händer för varje rad .
Den del som jag vill koncentrera mig på är felsökningen och hanteringen, eftersom det är extremt dyr. De återstående aspekterna som noterats ovan har redan gjorts så billiga som möjligt genom att använda en tabellvariabel och temporär tabell i demon.
Undantag
Det första jag vill göra är att visa att Clustered Index Insert Operatören gör verkligen ett undantag när den stöter på en dubblettnyckel.
Ett sätt att visa detta direkt är genom att bifoga en debugger och fånga en stackspårning vid den punkt då undantaget kastas:
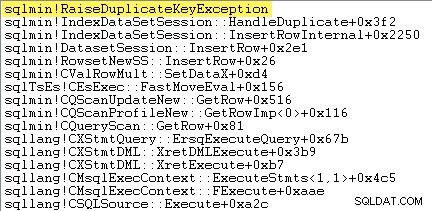
Det viktiga här är att det är mycket dyrt att kasta och fånga undantag.
Övervakning av SQL Server med Windows Performance Recorder medan testet kördes och analys av resultaten i Windows Performance Analyzer visar:
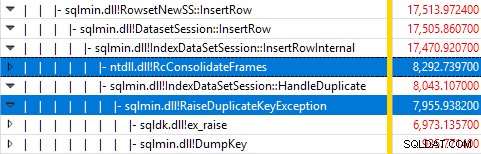
Nästan all frågekörningstid spenderas i sqlmin!IndexDataSetSession::InsertRowInternal som man kan förvänta sig för en fråga som inte gör något annat än att infoga rader.
Överraskningen är att 45 % av den tiden går åt till att ta upp undantag via sqlmin!RaiseDuplicateKeyException och ytterligare 47 % spenderas i det tillhörande undantagsfångstblocket (ntdll!RcConsolidateFrames hierarki) .
För att sammanfatta:Att höja och fånga undantag utgör 92 % av exekveringstiden av vår testklustrade indexinfogningsfråga.
Problem med datainsamling
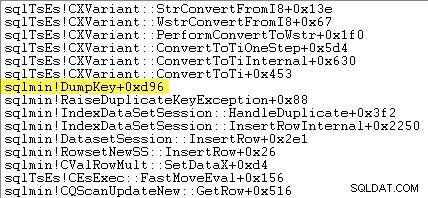
Skarpögda läsare kan märka en betydande mängd – cirka 12 % – av undantagstiden som spenderas i sqlmin!DumpKey i Windows Performance Analyzer-grafiken. Detta är värt att utforska snabbt, tillsammans med ett par relaterade saker.
Som en del av att ta fram ett undantag måste SQL Server samla in en del data som endast är tillgänglig vid den tidpunkt då felet uppstod. Felnumret som är associerat med ett dubblettnyckelundantag är 2627. Meddelandetexten i sys.messages för det felnumret är:
Information för att fylla i dessa platsmarkörer måste samlas in när felet uppstår – den kommer inte att vara tillgänglig senare! Det innebär att leta upp och formatera typen av begränsning, dess namn, det fullständiga namnet på målobjektet och det specifika nyckelvärdet. Allt det tar tid.
Följande stackspårning visar servern som formaterar dubblettnyckelvärdet som en Unicode-sträng under DumpKey ring:
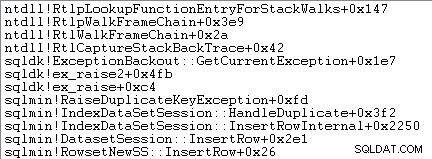
Undantagshantering involverar också att fånga en stackspårning:
SQL Server registrerar också information om undantag (inklusive stackframes) i en liten ringbuffert, som följande visar:
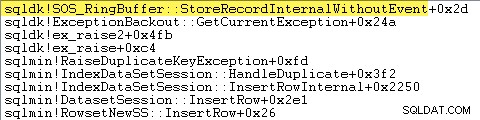
Du kan se dessa ringbuffertposter med ett kommando som:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Ett exempel på xml-posten för ett dubblettnyckelundantag följer. Notera stapelramarna:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Allt detta bakgrundsarbete händer för varje undantag. I vårt test betyder det att det händer 999 000 gånger — en gång för varje rad som stöter på en dubblett av nyckelöverträdelser.
Det finns många sätt att se detta, till exempel genom att köra en Profiler-spårning med Undantag händelse i Fel och varningar klass. I vårt testfall kommer detta så småningom producera 999 000 rader med TextData element som detta:
Brott mot UNIQUE KEY-begränsningen 'UQ__#AC166DE__3213663B8B6E2E0E'Kan inte infoga dubblettnyckel i objektet 'dbo.@T'.
Dupliceringsnyckelvärdet är (173).
Att bifoga Profiler innebär att varje undantagshanteringshändelse får en hel del extra omkostnader, eftersom extra data som behövs samlas in och formateras. Standarddata som nämnts tidigare samlas alltid in, även om ingen aktivt konsumerar informationen.
För att vara tydlig:Prestandasiffrorna som rapporteras i den här artikeln erhölls alla utan en ansluten debugger och ingen annan övervakning aktiv.
Icke-klusterad indexexekveringsplan
Trots att den är så mycket snabbare är den icke-klustrade indexinsättningsplanen ganska lite mer komplex, så jag kommer att dela upp den i två delar.
Det allmänna temat är att den här planen är snabbare eftersom den eliminerar dubbletter före försöker infoga dem i måltabellen.
Del 1
Först, den högra sidan av den icke-klustrade indexplanen:
Den här delen av planen avvisar alla rader som har en nyckelmatchning i måltabellen för det unika indexet med IGNORE_DUP_KEY ställ in ON .
Du kanske förväntar dig att se en Anti Semi Join här, men SQL Server har inte den nödvändiga infrastrukturen för att avge den nödvändiga varningen för dubblettnyckeln med en Anti Semi Join operatör. (Om det inte redan är vettigt, bör det snart.)
Istället får vi en plan med ett antal intressanta funktioner:
- Den Clustered Index Scan är
Ordered:Trueför att ge input till Merge Left Semi Join sorterade efter kolumnc1i#Datatabell. - Indexsökning av tabellvariabeln är
Ordered:False - Sortera ordnar rader efter kolumn
c1i tabellvariabeln. Denna beställning kunde ha tillhandahållits av en beställd genomsökning av tabellvariabelindex påc1, men optimeraren bestämmer Sorteringen är det billigaste sättet att tillhandahålla den erforderliga nivån av Halloween-skydd. - Tabellvariabeln Indexsökning har intern
UPDLOCKochSERIALIZABLEtips som tillämpas för att säkerställa målstabilitet under planens genomförande. - Merge Left Semi Join söker efter matchningar i tabellvariabeln för varje värde på
c1returneras från#Datatabell. Till skillnad från en vanlig semi-join, sänder den ut varje rad som tas emot på sin övre ingång. Den sätter en flagga i en probkolumn för att indikera om den aktuella raden hittade en matchning eller inte. Sondkolumnen sänds ut från Merge Left Semi Join som ett uttryck som heterExpr1012. - Förstående operatören kontrollerar värdet på sondkolumnen
Expr1012. Första gången den ser en rad med ett sondkolumnvärde som inte är noll (vilket indikerar att en indexnyckelmatchning hittades), avger den ett "Duplicerad nyckel ignorerades" meddelande. - Förstående skickar bara vidare rader där sondkolumnen är null. Detta eliminerar inkommande rader som skulle producera ett duplicerat nyckelfel.
Det hela kan tyckas komplicerat, men det är i princip lika enkelt som att sätta en flagga om en matchning hittas, avge en varning första gången flaggan sätts och bara skicka rader vidare mot infogningen som inte redan finns i måltabellen .
Del 2
Den andra delen av planen följer Assert operatör:
Den tidigare delen av planen tog bort rader som hade en matchning i måltabellen. Den här delen av planen tar bort dubbletter inom infogningsuppsättningen .
Tänk dig till exempel att det inte finns några rader i måltabellen där c1 = 1 . Vi kan fortfarande orsaka ett dubblettnyckelfel om vi försöker infoga två rader med c1 = 1 från källtabellen. Vi måste undvika det för att respektera semantiken för IGNORE_DUP_KEY = ON .
Denna aspekt hanteras av segmentet och Topp operatörer.
Segmentet operatorn sätter en ny flagga (märkt Segment1015 ) när den stöter på en rad med ett nytt värde för c1 . Eftersom rader presenteras i c1 order (tack vare den orderbevarande Merge ), kan planen förlita sig på alla rader med samma c1 värde som kommer i en sammanhängande ström.
Topp operatören skickar en rad för varje grupp av dubbletter, vilket indikeras av Segment flagga. Om Topp operatorn stöter på mer än en rad för samma segment grupp (c1 värde), avger den ett "Duplicate key was ignored" varning, om det är första gången planen har stött på det tillståndet.
Nettoeffekten av allt detta är att endast en rad skickas till infogningsoperatorerna för varje unikt värde på c1 , och en varning genereras om det behövs.
Utförandeplanen har nu eliminerat alla potentiella dubbletter av nyckelöverträdelser, så den återstående tabellinfogningen och Indexinfoga Operatörer kan säkert infoga rader i heapen och icke-klustrade index utan rädsla för ett duplicerat nyckelfel.
Kom ihåg att UPDLOCK och SERIALIZABLE tips som tillämpas på måltabellen säkerställer att uppsättningen inte kan ändras under körning. Med andra ord kan en samtidig sats inte ändra måltabellen så att ett dubblettnyckelfel skulle inträffa vid Infoga operatörer. Det är inget problem här eftersom vi använder en privat tabellvariabel, men SQL Server lägger fortfarande till tipsen som en allmän säkerhetsåtgärd.
Utan dessa tips skulle en samtidig process kunna lägga till en rad i måltabellen som skulle generera en dubblett av nyckelöverträdelser, trots kontrollerna som gjorts av del 1 av planen. SQL Server måste vara säker på att existenskontrollresultaten förblir giltiga.
Den nyfikna läsaren kan se några av funktionerna som beskrivs ovan genom att aktivera spårningsflaggor 3604 och 8607 för att se optimerarens utdataträd:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Slutliga tankar
IGNORE_DUP_KEY indexalternativ är inte något de flesta kommer att använda särskilt ofta. Ändå är det intressant att titta på hur denna funktionalitet implementeras, och varför det kan finnas stora prestandaskillnader mellan IGNORE_DUP_KEY på klustrade och icke-klustrade index.
I många fall kommer det att löna sig att följa frågeprocessorns ledning och leta efter att skriva frågor som eliminerar dubbletter uttryckligen, snarare än att förlita sig på IGNORE_DUP_KEY . I vårt exempel skulle det innebära att skriva:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Detta körs på cirka 400 ms , bara för protokollet.