Vilken datamodell skulle tillåta dig att bekvämt söka efter böcker och låna dem i ditt lokala bibliotek?
Har du någonsin gått till ett bibliotek och lånat en bok? Kanske verkar det gammaldags i dagens värld av omedelbar internetkunskap och e-böcker. Men jag är säker på att det fortfarande finns den här analoga delen av dig som fortfarande gillar att lukta, röra och läsa böcker. Eller så kanske du blev tvungen att använda ett bibliotek när du inte kunde hitta något på internet! Ja, allt är inte online.
Så, hur skulle en datamodell organisera biblioteksböcker och lån? Låt oss dyka direkt in i den här modellen och se hur den fungerar!
Datamodellen
Jag hade publika bibliotek i åtanke när jag skapade denna datamodell. Det finns ett antagande att alla bibliotek i det allmänna biblioteksnätverket använder samma modell/system. Det är centraliserat och låter medlemmarna bläddra i samlingen för alla bibliotek i nätverket. Medlemmar kan också låna böcker från alla bibliotek i nätverket.
Biblioteksdatamodellen består av tretton tabeller uppdelade i två ämnesområden. Dessa områden är:
Books & LibrariesMembers & Loans
Vi går igenom varje ämnesområde separat och analyserar alla detaljer.
Böcker och bibliotek
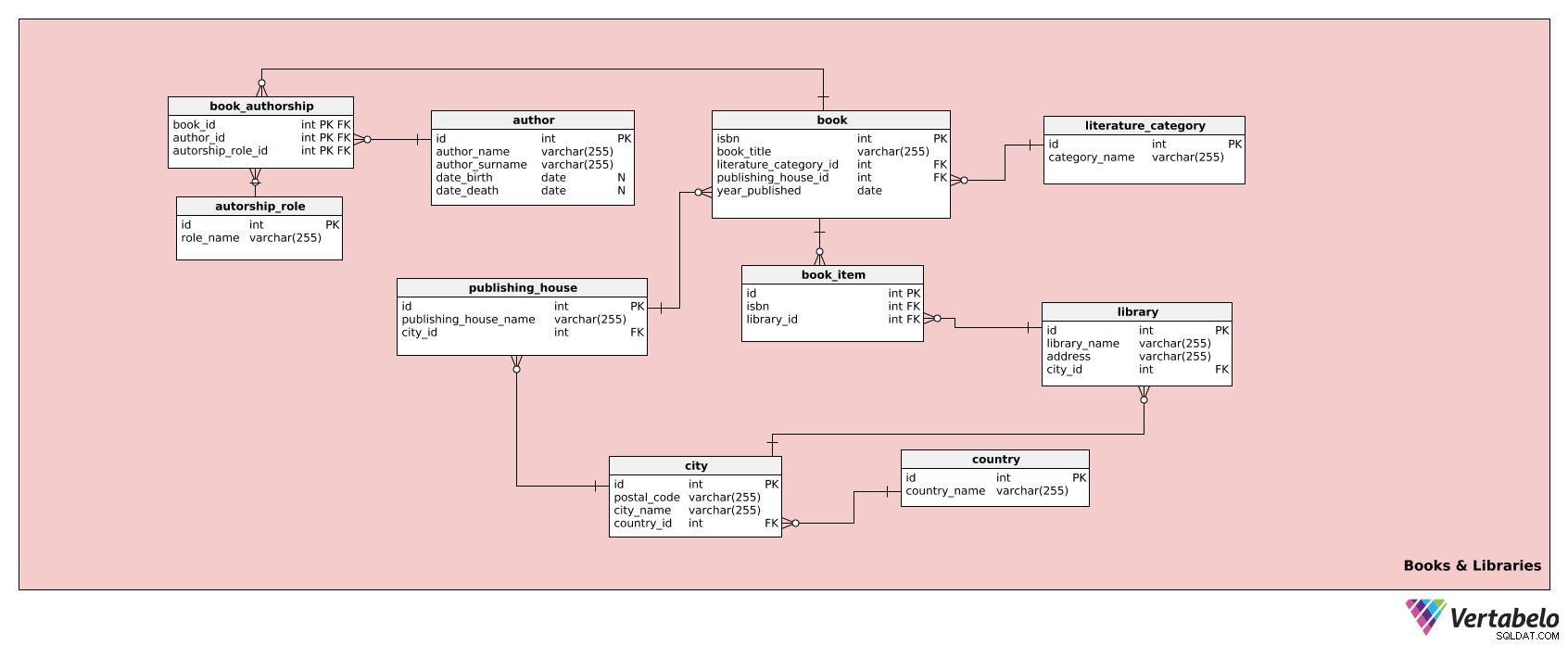
Detta ämnesområde lagrar information om böcker och bibliotek. Den består av tio tabeller:
authorauthorship_roleliterature_categorybookbook_authorshipbook_itempublishing_houselibrarycitycountry
Den första tabellen är author tabell. Den listar alla författare (plus deras relevanta uppgifter) av de böcker som biblioteket har i sin samling. För varje författare har vi:
id– Ett unikt ID för den författaren.author_name– Författarens förnamn.author_surname– Författarens efternamn.date_birth– Författarens födelsedatum.date_death– Datum för författarens död.
authorship_role tabell listar alla roller en författare kan ha, t.ex. författare, medförfattare, etc. Den här tabellen har följande attribut:
id– Ett unikt ID för varje roll.role_name– Namnet på den rollen, t.ex. "medförfattare". Detta är den alternativa nyckeln i tabellen.
Tabellen literature_category listar alla bokkategorier, t.ex. thriller, fransk litteratur, rysk realism, filosofi, etc. Tabellen innehåller följande attribut:
id– Ett unikt ID för den kategorin.category_name– Kategorins namn, t.ex. "mysterium". Detta är den alternativa nyckeln i tabellen.
Därefter har vi book tabell. Den här tabellen lagrar alla relevanta detaljer för varje titel som biblioteket har i sin samling. Observera att detta inte är den tabell som används för varje bok som föremål. För det kommer vi att använda en annan tabell, nämligen book_item tabell. book tabellen består av attributen:
isbn– Ett unikt ID för varje boktitel, vilket inom förlagsbranschen är International Standard Book Number (ISBN).book_title– Bokens titel.literature_category_id– Refererar tillliterature_categorytabell.publishing_house_id– Refererar tillpublishing_housetabell.year_published– Året då boken gavs ut.
Nästa tabell i vår modell är book_authorship tabell. Det är en skärningstabell som kommer att kopplas till book , author , och authorship_role tabeller. Den innehåller följande attribut:
book_id– Refererar tillbooktabell.author_id– Refererar tillauthortabell.authorship_role_id– Refererar tillauthorship_roletabell.
Dessa tre attribut bildar tillsammans tabellens sammansatta primärnyckel. En sammansatt primärnyckel betyder att alla kombinationer av alla tre attribut måste vara unika; varje kombination kan bara förekomma en gång.
Låt oss nu titta på book_item tabell, som vi nämnde tidigare som lagring av information för varje fysisk bok i ett bibliotek. Den kommer att innehålla följande information:
id– Ett unikt ID för varje bok som föremål.isbn– Refererar tillbooktabell.library_id– Refererar tilllibrarytabell.
Tabellen The publishing_house table is the next one in our model. It lists the publishers of all the books that the library has in its collection. The attributes in the table are as follows: tabellen är nästa i vår modell. Den listar förlagen av alla böcker som biblioteket har i sin samling. Attributen i tabellen är följande:
id– Ett unikt ID för varje förlag.publishing_house_name– Namnet på förlaget (t.ex. Penguin Books, McGraw-Hill, Simon &Schuster, etc.).city_id– Refererar tillcitytabell. Denna koppling gör det också möjligt för oss att bestämma både stad och land för förlaget.publishing_house_name–city_idpar är den alternativa nyckeln för denna tabell.
Okej, låt oss gå vidare till library tabell. Denna tabell hänvisas till i book_item tabell, där den definierar biblioteket där varje exemplar av en bok förvaras. Detta behövs eftersom samma boktitlar kan hittas i mer än ett bibliotek i ett nätverk (t.ex. varje bibliotek har förmodligen minst ett exemplar av Sagan om ringen ). Därför måste vi veta vilken bok som finns på vilket bibliotek. För att uppnå det behöver vi följande attribut:
id– Ett unikt ID för biblioteket.library_name– Namnet på det biblioteket.address– Adressen till det biblioteket.city_id– Refererar tillcitytabell.library_name-city_idpar är den alternativa nyckeln för denna tabell.
Nästa tabell i denna modell är city tabell. Det är en enkel lista över städer som vi kommer att använda för information om förlag, bibliotek och biblioteksmedlemmar. Attributen är:
id– Ett unikt ID för staden.postal_code– Postnummer för den staden.city_name– Stadens namn.country_id– Refererar tillcountrytabell.
Därefter finns det bara en tabell kvar i detta ämnesområde:country tabell. Detta är en lista över alla länder där våra bibliotek och/eller bokförlag finns. Den består av följande attribut:
id– Ett unikt ID för varje land.country_name– Landets namn. Detta är den alternativa nyckeln för tabellen.
Låt oss sedan undersöka det andra ämnesområdet.
Medlemmar och lån
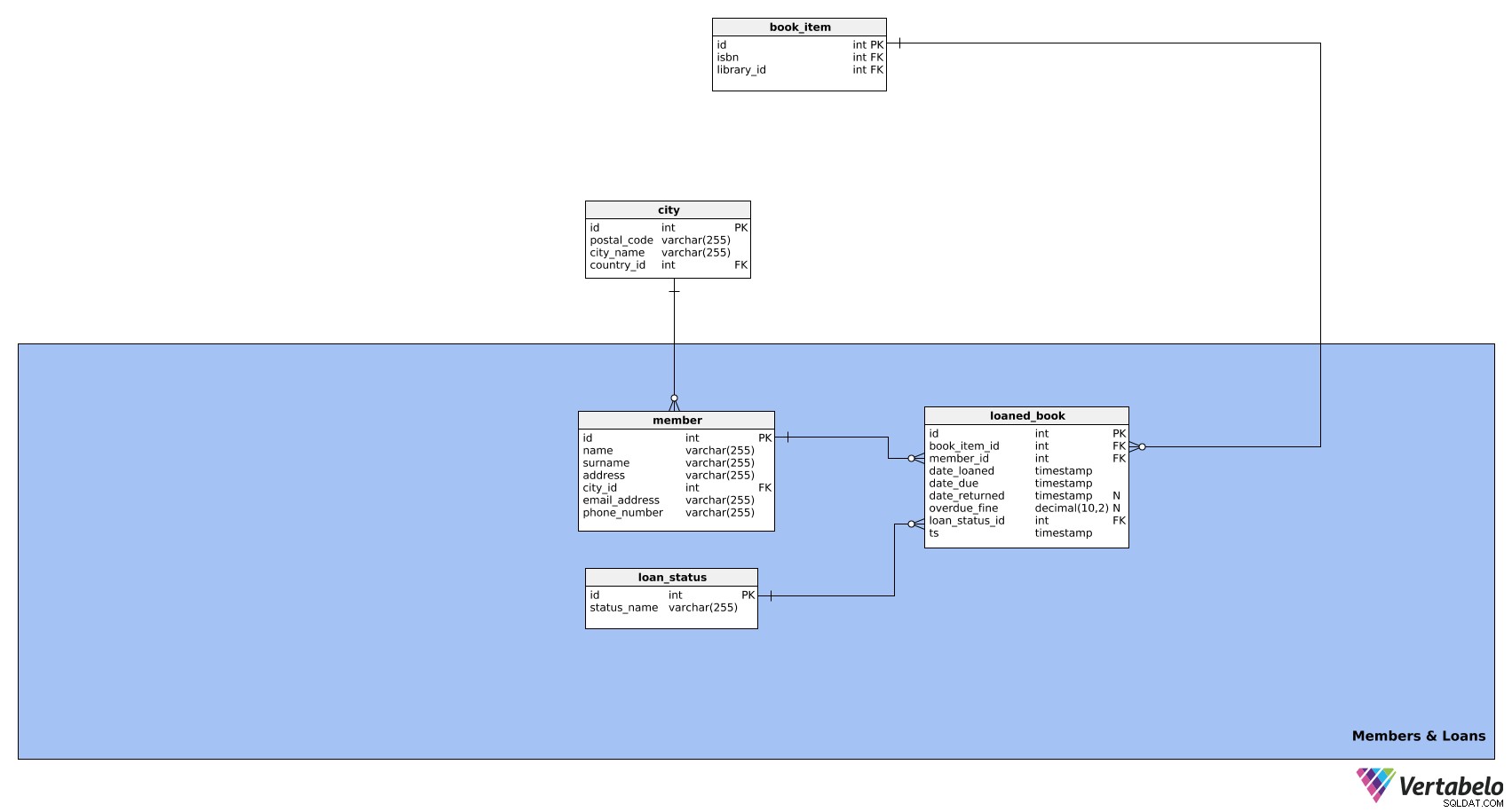
Syftet med detta ämnesområde är att hantera information om biblioteksmedlemmar och de böcker de lånar. Den består av tre tabeller:
memberloaned_bookloan_status
Låt oss nu prata om tabellerna.
Den första tabellen i detta område är member tabell. Den innehåller all relevant information om biblioteksmedlemmar. Dess attribut är följande:
id– Ett unikt ID för varje medlem.name– Medlemmens förnamn.surname– Medlemmens efternamn.address– Medlemmens adress.city_id– Refererar tillcitytabell.email_address– Medlemmens e-postadress.phone_number– Medlemmens telefonnummer.
Nästa tabell är loaned_book tabell. Den lagrar information om alla böcker som någonsin har lånats ut. På så sätt kan vi hålla reda på bibliotekets inventarier och status för eventuella utlånade böcker. Den här tabellen består av följande attribut:
id– Ett unikt ID för varje utlånad bok.book_item_id– Refererar tillbook_itemtabell.member_id– Refererar tillmembertabell.date_loaned– Datumet då den här boken lånades ut.date_due– Datum då denna bok ska returneras.date_returned– Datumet då boken faktiskt returnerades till biblioteket; detta kan vara NULL eftersom vi inte vet datumet förrän boken returneras.overdue_fine– Förseningsavgiften (om någon) betalas av medlemmen, som vanligtvis beräknas utifrån skillnaden mellandate_returnedochdate_due. Detta kan vara NULL eftersom en bok som returneras i tid inte har några böter.loan_status_id– Refererar tillloan_statustabell.ts– Tidsstämpeln när lånestatusen angavs.
loan_status Tabellen är den sista i vår datamodell. Det är helt enkelt en lista över alla möjliga lånestatusar, t.ex. aktiv, förfallen, returnerad, etc. Den här tabellen kommer att bestå av följande attribut:
id– Ett unikt ID för varje lånestatus.status_name– Ett namn som beskriver lånestatusen. Detta är den alternativa nyckeln för tabellen.
Det var allt – vi har gått igenom alla detaljer i vår datamodell!
Vad tycker du om biblioteksdatamodellen?
Vi har täckt allmänna principer i den här modellen, så det borde vara (med några justeringar) för varje bibliotek. Vet du några biblioteksdetaljer som vi missat? Eller kanske du tyckte att modellen var användbar och lättapplicerad? Säg din mening i kommentarsfältet.