Introduktion
Du måste redan ha hört termen "Sortering" i SQL Server. Sortering är en konfiguration som bestämmer hur teckendatasortering görs. Detta är en viktig inställning som har en enorm inverkan på hur SQL Server-databasmotorn beter sig vid hantering av teckendata. I den här artikeln syftar vi till att diskutera sammanställningar i allmänhet och visa några exempel på hur man hanterar sammanställningar.
Var hittar jag sorteringar?
Du kan hitta SQL-sortering på server-, databas- och kolumnnivå. En annan viktig sak att veta är att sorteringsinställningen inte behöver vara densamma på server-, databas- och kolumnnivå. Du kan också uppdatera dina frågor för att använda specifika sorteringar. Det är vid denna tidpunkt som du kommer att inse vikten av att konfigurera rätt sortering i din miljö eftersom det finns en stor risk för oväntade problem om sorteringen inte är konsekvent.
Vad finns det för olika sorters sorteringar?
Du kan få hela listan över tillgängliga sorteringar genom att fråga systemfunktionen sys.fn_helpcollations()
select * from sys.fn_helpcollations()
Detta kommer att returnera följande utdata.
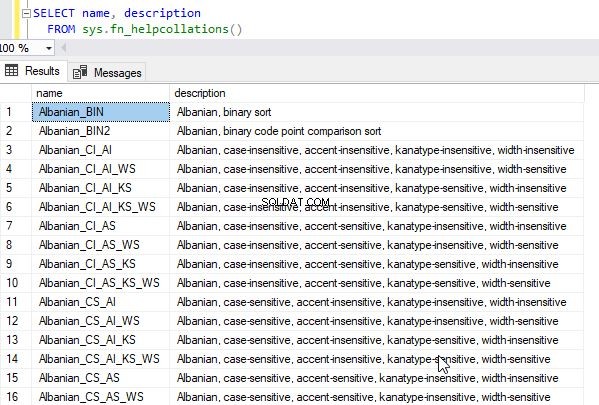
Om du letar efter specifika sorteringar efter språk kan du filtrera namnet ytterligare. Om du till exempel letar efter sortering som stöds av maorispråk kan du använda följande fråga.
select * from sys.fn_helpcollations()
where name like '%Maori%' Detta kommer att returnera följande utdata.
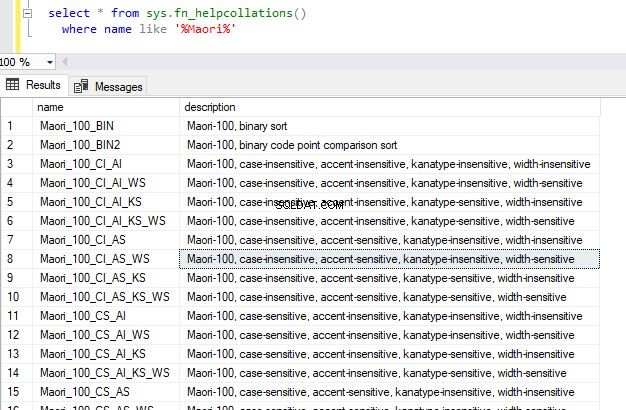
På så sätt kan du söka efter de sorteringar som stöds för den sortering du väljer. När du bara frågade efter systemfunktionen fn_helpcollations() returnerades totalt 5508 rader, vilket betyder att det finns så många sorteringar som stöds. Observera att detta täcker en majoritet av språken runt om i världen.
Vilka är de olika alternativen du ser i sorteringsnamnet?
Till exempel, i den här sorteringen:Maori_100_CS_AI_KS_WS_SC_UTF8, kan du se de olika alternativen i sorteringsnamnet.
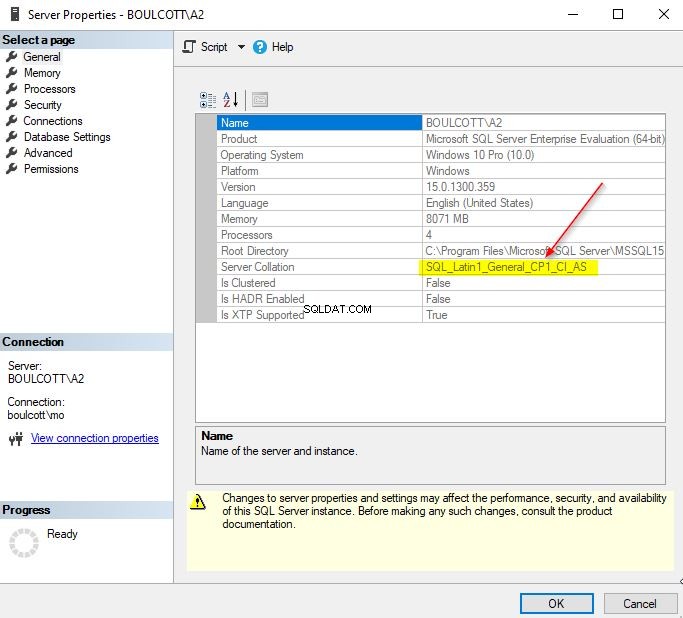
CS – skiftlägeskänslig
AI – accentokänslig
KS – kana typkänslig
WS – breddkänslig
SC – kompletterande tecken
UTF8 – Kodningsstandard
Baserat på typen av ett sorteringsalternativ som valts kommer SQL Server-databasmotorn att fungera annorlunda när det gäller att hantera teckendata för sortering och sökning. Till exempel, om du använder det skiftlägeskänsliga alternativet i SQL-sorteringen, kommer databasmotorn att bete sig annorlunda för en frågeoperation som letar efter "Adam" eller "adam". Förutsatt att du har en tabell som heter "sample" och det finns en förnamnskolumn med en användare "adam". Frågan nedan ger inga resultat om det inte finns någon rad med förnamnet "Adam". Detta beror på alternativet "CS-skiftlägeskänslig" i sorteringen.
select * from sample
where firstname like '%Adam%' Med detta enkla exempel kan du förstå betydelsen av att välja rätt SQL-sorteringsalternativ. Se till att du förstår applikationskraven innan du väljer sortering i första hand.
Hitta sortering på SQL Server-instans
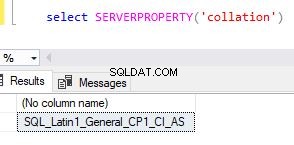
Du kan hämta serverkollationen i SQL Server Management Studio (SSMS) genom att högerklicka på SQL-instansen, klicka sedan på alternativet "Egenskaper" och markera fliken "Allmänt". Denna sortering väljs som standard vid installationen av SQL Server.
Alternativt kan du använda alternativet serverproperty för att hitta sorteringsvärdet.
select SERVERPROPERTY('collation'),
Hitta sammanställning av en SQL-databas
I SSMS, högerklicka på SQL-databasen och gå till "Egenskaper". Du kan kontrollera sorteringsdetaljerna på fliken "Allmänt" som visas nedan.
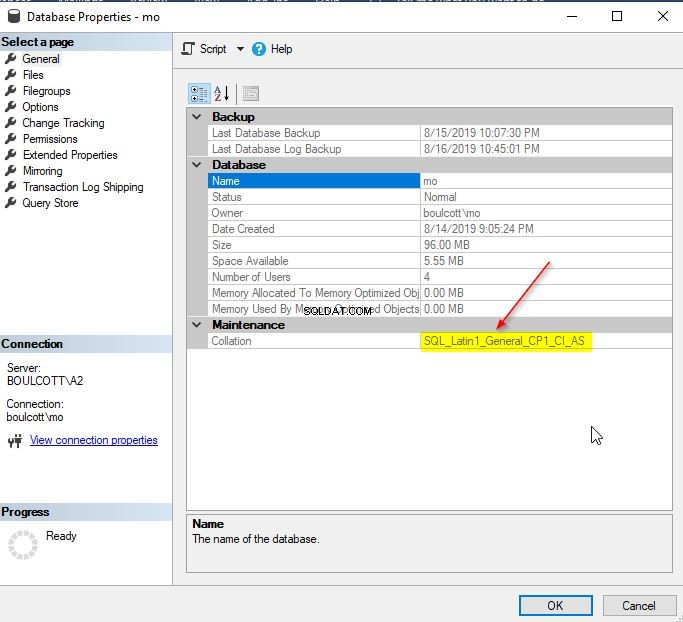
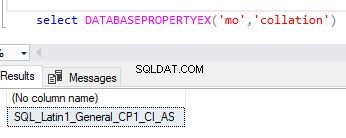
Alternativt kan du använda databasepropertyex-funktionen för att få information om en databassortering.
select DATABASEPROPERTYEX('Your DB Name','collation')
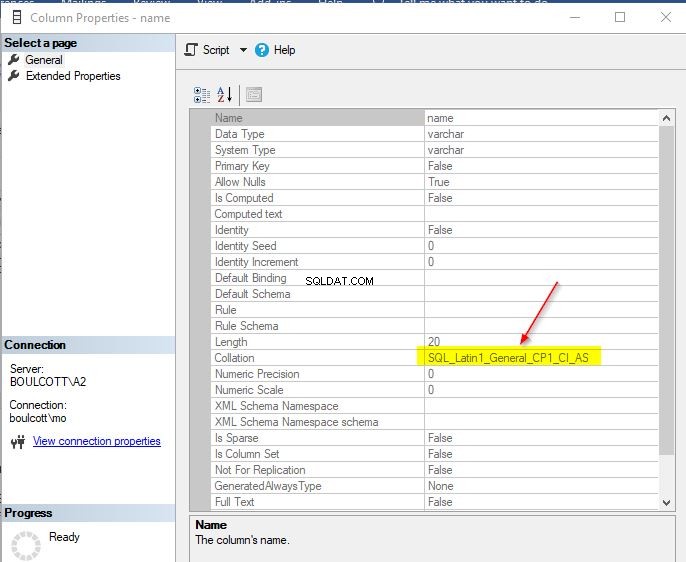
Hitta sammanställning av en kolumn i en tabell
I SSMS, gå till tabellen, sedan kolumner och högerklicka slutligen på de enskilda kolumnerna för att se "Egenskaper". Om kolumnen är av en teckendatatyp kommer du att se detaljer om sorteringen.
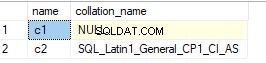
Men samtidigt, om du kontrollerar värdet för en icke-teckendatatyp, kommer sorteringsvärdet att vara null. Nedan är en skärmdump av en kolumn som har int datatyp.
Alternativt kan du använda en exempelfråga nedan för att se sorteringsvärdena för kolumner.
select sc.name, sc.collation_name from sys.columns sc inner join sys.tables t on sc.object_id=t.object_id where t.name='t1' – enter your table name
Nedan är utdata för frågan.
Prova olika sorteringar i SQL-frågor
I det här avsnittet kommer vi att se hur sorteringsordningen påverkas när olika sorteringar används i frågor. En exempeltabell skapas med 2 kolumner som visas nedan.
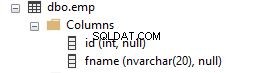
Kolumnen fname har standardsorteringen av databasen den tillhör. I det här fallet är sorteringen SQL_Latin1_General_CP1_CI_AS.
För att infoga några poster i tabellen, använd en fråga nedan. Tilldela dina egna värden till parametrarna.
insert into emp values (1,'mohammed') insert into emp values (2,'moinudheen') insert into emp values (3,'Mohammed') insert into emp values (4,'Moinudheen') insert into emp values (5,'MOHAMMED') insert into emp values (6,'MOINUDHEEN')
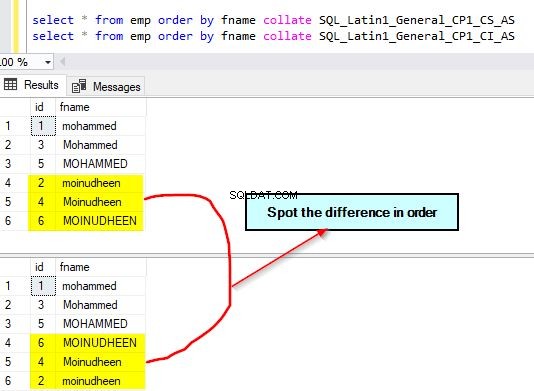
Fråga nu emp-tabellen och sortera den efter kolumnen fname med hjälp av olika sorteringar. Vi kommer att använda standardsorteringen av kolumnen för sortering samt en annan skiftlägeskänslig sortering – SQL_Latin1_General_CP1_CS_AS.
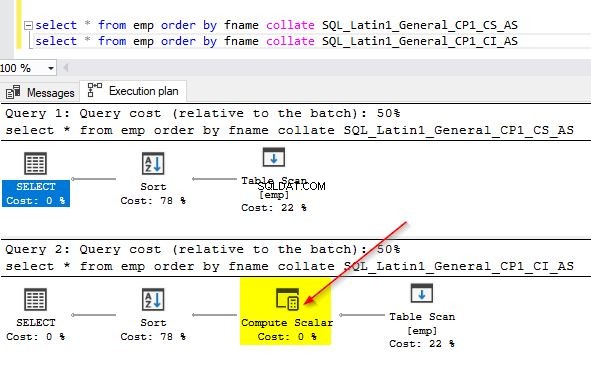
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – this is default
Utdata för dessa frågor ges nedan. Lägg märke till skillnaden i sortering som används. Vi använder skiftlägeskänslig istället för skiftlägesokänslig.
Du kan också kontrollera frågeplanerna för båda dessa frågor för att se skillnaden. På den första frågeplanen där vi använder en annan sortering än den i kolumnen kan du lägga märke till den extra operatorn "Compute Scalar".
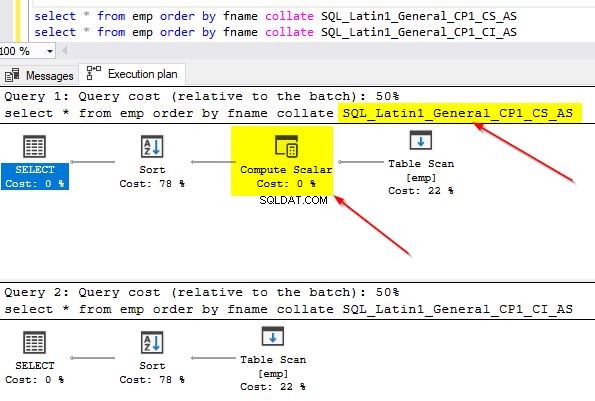
När du för musen över operatorn "Compute Scalar" kommer du att se ytterligare detaljer som visas nedan. Detta beror på den implicita konverteringen som äger rum eftersom vi använder en annan sortering än den standard som används i kolumnen.
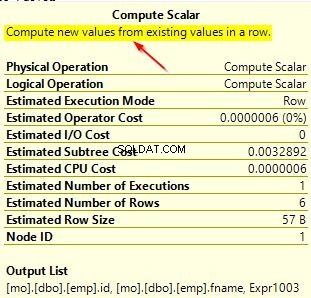
Med det här lilla exemplet kan du se vilken typ av inverkan på frågeprestanda när du använder sorteringar uttryckligen i frågor. I vår demodatabas använde vi en enkel tabell men föreställ dig ett realtidsscenario där små förändringar i frågeprestanda kan orsaka oväntade resultat.
Kontrollerar om det är möjligt att ändra sortering på instansnivå
I det här avsnittet kommer vi att granska olika scenarier där vi kan behöva ändra standardsorteringarna. Du kan stöta på situationer när servrar eller databaser överlämnas till dig och de kanske inte uppfyller dina standardpolicyer, så du kan behöva ändra sorteringen. Standardinställningen för SQL Server är SQL_Latin1_General_CP1_CI_AS. Det är inte enkelt att ändra sorteringen på SQL-instansnivå. Det kräver att man skriptar ut alla objekt i användardatabaserna, exporterar data, släpper användardatabaserna, bygger om huvuddatabasen med den nya sammanställningen, skapar användardatabaserna och sedan importerar all data. Så om du installerar nya SQL-instanser, se bara till att du får sorteringen rätt första gången, annars kan du behöva göra mycket oönskat arbete senare. Att i detalj förklara stegen för att ändra sammanställning på instansnivå ligger utanför ramen för denna artikel på grund av de detaljerade steg som krävs för vart och ett av stegen.
Ändra sortering på databasnivå
Lyckligtvis är det inte lika svårt att ändra databassorteringen som att ändra instanssorteringen. Vi kan uppdatera sammanställningen med både SSMS och T-SQL. I SSMS, högerklicka bara på databasen, gå till "Egenskaper" och klicka på fliken "Alternativ" på vänster sida. Där kan du se alternativet att ändra sorteringen i rullgardinsmenyn.
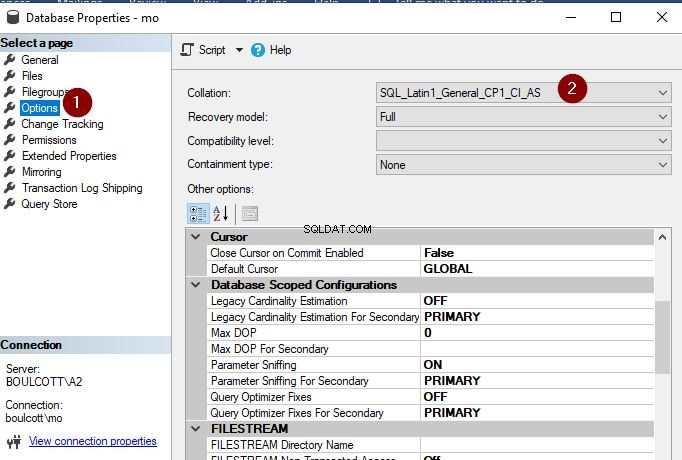
Klicka på "OK" när du är klar. Jag har precis ändrat databassorteringen till SQL_Latin1_General_CP1_CI_AS. Se bara till att du utför den här operationen när databasen inte används eftersom operationen annars kommer att misslyckas enligt nedan.
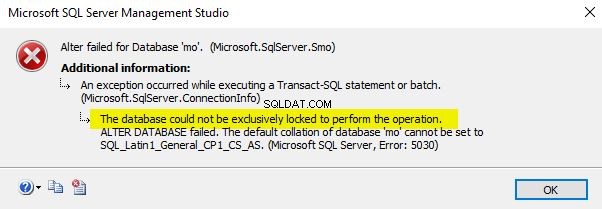
Använd den fortsatta frågan för att ändra databassorteringen med T-SQL.
USE master; GO ALTER DATABASE mo COLLATE SQL_Latin1_General_CP1_CS_AS; GO
Du skulle märka att en ändring av sorteringen på databasnivå inte kommer att påverka sorteringen av de befintliga kolumnerna i tabellerna. Du kan använda de tidigare exemplen för att kontrollera inverkan av sortering på sorteringsordningen för frågorna nedan.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – - this is default
Kolumnsamlingen fname förblir den ursprungliga och förblir oförändrad även efter att du har ändrat sorteringen på databasnivå.
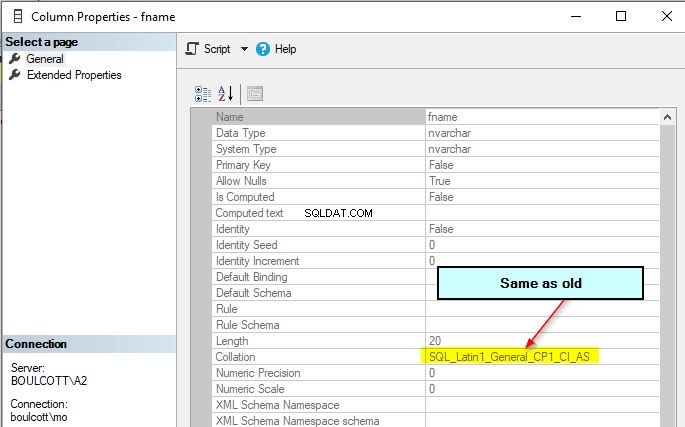
Den nya databasnivåsorteringen kommer dock att tillämpas för alla nya kolumner i de nya tabellerna som du kommer att skapa. Så testa alltid förändringen av databaskollationer noggrant eftersom det har en avsevärd inverkan på frågeutdata eller beteende.
Ändra sortering på kolumnnivå
I föregående avsnitt märkte du att även efter att ha ändrat sorteringen på databasnivå förblir sammanställningen av befintliga kolumner i tabellerna oförändrad. I det här avsnittet kommer vi att se hur vi kan ändra sammanställningen av befintliga kolumner i tabellerna för att matcha den för databassorteringen. I föregående avsnitt ändrade du databassorteringen till SQL_Latin1_General_CP1_CS_AS. Därefter vill du identifiera alla kolumner i användartabellerna som inte matchar denna databassortering. Du kan använda det här skriptet för att identifiera dessa kolumner.
select so.name TableName,sc.name ColumnName, sc.collation_name CollationName from sys.objects so inner join sys.columns sc on so.object_id=sc.object_id where sc.collation_name!='SQL_Latin1_General_CP1_CS_AS' and so.[type] ='U'
Exempelutdata från min demodatabas är som visas nedan.
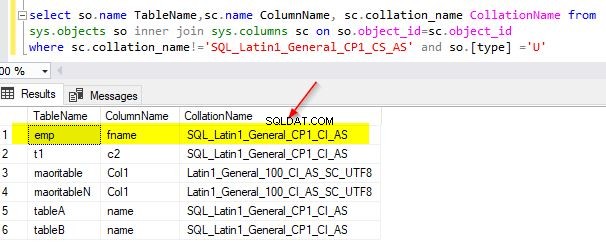
Anta att du vill ändra sammanställningen av den befintliga fname-kolumnen till "SQL_Latin1_General_CP1_CS_AS", då kan du använda detta ändringsskript nedan.
use mo
go
ALTER TABLE dbo.emp ALTER COLUMN fname
nvarchar(20) COLLATE SQL_Latin1_General_CP1_CS_AS NULL;
GO Om du använder de tidigare exemplen där du kontrollerade frågeprestanda med olika sorteringar, kommer du att märka att operatorn "compute scalar" inte används när vi använder samma sortering som databasen. Se skärmdumpen nedan. I det tidigare exemplet kunde du ha märkt att "Compute scalar"-operatorn användes i den första exekveringsplanen. Eftersom vi ändrade kolumnsorteringen för att matcha den för databassorteringen, finns det inget behov av implicit konvertering. Du kommer att se operatorn "Compute scalar" i den andra frågan eftersom den använder en annan sortering uttryckligen.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS – - this is default select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS
Kan vi ändra sammanställningen av systemdatabaser?
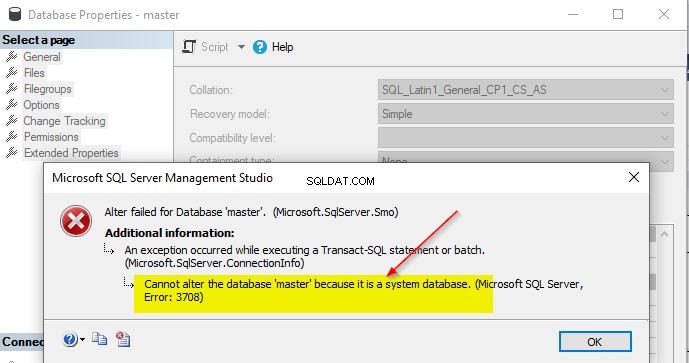
Det går inte att ändra sammanställningen av systemdatabaser. Om du försöker ändra sammanställningen av systemdatabaserna – master, model, msdb eller tempdb, får du detta felmeddelande.
Du måste följa stegen som beskrivs tidigare för att ändra sorteringen på SQL Server-instansnivå för att ändra sammanställningen av systemdatabaserna. Det är viktigt att få kollationerna korrekta första gången du installerar SQL Server för att undvika sådana problem.
Det kända problemet om sorteringskonflikt
Ett annat vanligt problem du kan hitta är felet relaterat till sorteringskonflikt, särskilt när du använder tillfälliga objekt. De tillfälliga objekten lagras i tempdb. Den tempdb som är en systemdatabas kommer att anta sammanställningen av SQL-instansen. När du skapar användardatabaser som har annan sortering än SQL-instansen kommer du att stöta på problem när du använder tillfälliga objekt. Du kan också stöta på problem när du jämför kolumner i tabeller som har olika sorteringar. Vid det här laget vet du redan att en tabell kan ha kolumner med olika sorteringar eftersom vi inte kan ändra sammanställningen på tabellnivå. Det vanliga felmeddelandet som du kommer att märka är något i stil med "Kan inte lösa sorteringskonflikten mellan "Sortering1" och "Sortering2" i lika med operation." Collation1 och Collation2 kan vara vilken sortering som helst som används i en fråga. Med ett enkelt exempel kan vi producera en demo av denna sammanställningskonflikt. Om du har slutfört de tidigare exemplen i den här artikeln har du redan en tabell som heter "emp". Skapa bara en tillfällig tabell i din demodatabas och infoga poster med hjälp av det medföljande exempelskriptet.
create table #emptemp (id int, fname nvarchar(20)) insert into #emptemp select * from emp
Kör bara en join med båda tabellerna så får du det här sorteringskonfliktfelet som visas nedan.
select e.id, et.fname from emp e inner join #emptemp et on e.fname=et.fname

Du kommer att märka att användardatabassorteringen som används är "SQL_Latin1_General_CP1_CS_AS" och den stämmer inte överens med serversorteringen. För att åtgärda denna typ av fel kan du ändra kolumnerna som används i de tillfälliga objekten så att de använder standardsorteringen av användardatabasen. Du kan använda alternativet "database_default" eller uttryckligen ange sorteringsnamnet på användardatabasen. I det här exemplet använder vi sorteringen "SQL_Latin1_General_CP1_CS_AS". Prova något av dessa alternativ
Alternativ 1: Använd alternativet database_default
alter table #emptemp alter column fname nvarchar(20) collate database_default
När du är klar kör du select-satsen igen och felet åtgärdas.
Alternativ 2: Använd sammanställningen av användardatabasen explicit
alter table #emptemp alter column fname nvarchar(20) collate SQL_Latin1_General_CP1_CS_AS
När du är klar kör du select-satsen igen och felet kommer att åtgärdas.
Slutsats
I den här artikeln fick du reda på:
• konceptet med sortering
• de olika sorteringsalternativen som finns
• att hitta sorteringsdetaljer för alla SQL-instanser, databaser och kolumner
• A ARBETSEXEMPEL på att testa sorteringsalternativ i SQL-frågor
• ändra kollationer på instansnivå, databasnivå och kolumnnivå
• HUR MAN ändrar sortering av systemdatabaser
• en kollationskonflikt och hur för att fixa det
Nu vet du om vikten av sortering och det kritiska med att konfigurera korrekt sortering på SQL-instansen och även över databasobjekten. Testa alltid de olika scenarierna i din testmiljö innan du använder något av ovanstående alternativ på dina produktionssystem.