Gruppering är en viktig funktion som hjälper till att organisera och ordna data. Det finns många sätt att göra det, och en av de mest effektiva metoderna är SQL GROUP BY-satsen.
Du kan använda SQL GROUP BY för att dela upp rader i resultat i grupper med en aggregationsfunktion . Det låter enkelt att summera, snitta eller räkna rekord med den.
Men gör du det rätt?
"Rätt" kan vara subjektivt. När den körs utan kritiska fel med en korrekt utgång anses det vara bra. Det måste dock gå snabbt också.
I den här artikeln kommer hastigheten också att beaktas. Du kommer att se mycket frågeanalys med logiska läsningar och exekveringsplaner i alla punkter.
Låt oss börja.
1. Filtrera tidigt
Om du är förvirrad över när du ska använda WHERE och HAVING, är den här för dig. För beroende på vilket tillstånd du tillhandahåller kan båda ge samma resultat.
Men de är olika.
HAVING filtrerar grupperna med hjälp av kolumnerna i SQL GROUP BY-satsen. WHERE filtrerar raderna innan gruppering och aggregering sker. Så om du filtrerar med HAVING-satsen, sker gruppering för alla rader returnerade.
Och det är dåligt.
Varför? Det korta svaret är:det går långsamt. Låt oss bevisa detta med 2 frågor. Kolla in koden nedan. Innan du kör det i SQL Server Management Studio, tryck först på Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analys
De två SELECT-satserna ovan kommer att returnera samma rader. Båda är korrekta när det gäller att returnera produktbeställningar per månad under år 2012. Men den första SELECT tog 136 ms. att köra på min bärbara dator, medan en annan tog 764ms.!
Varför?
Låt oss kontrollera de logiska läsningarna först i figur 1. STATISTICS IO returnerade dessa resultat. Sedan klistrade jag in den i StatisticsParser.com för den formaterade utdata.
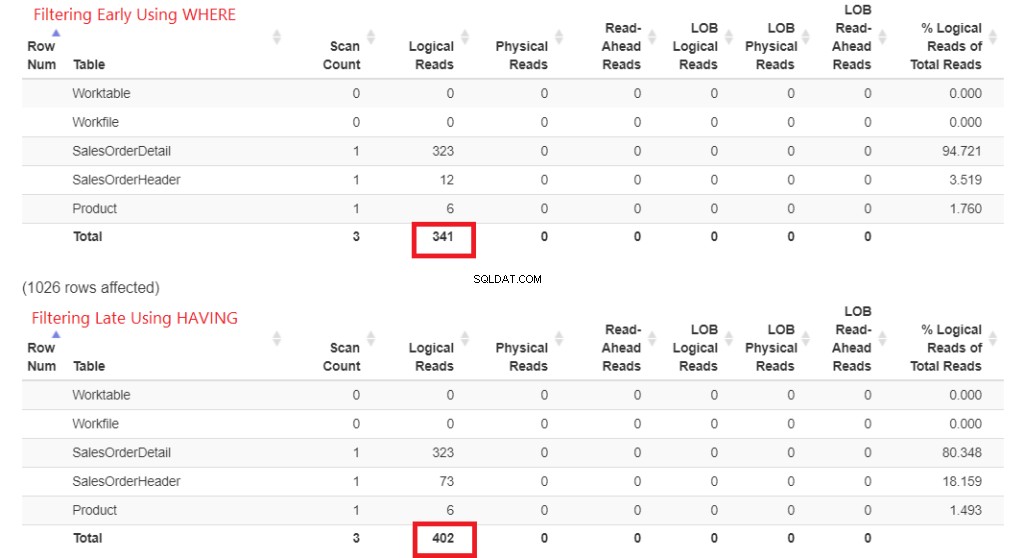
Figur 1 . Logiska läsningar av filtrering tidigt med WHERE kontra sent filtrering med HAVING.
Titta på de totala logiska läsningarna av varje. För att förstå dessa siffror, ju mer logiska läsningar det tog, desto långsammare blir frågan. Så det bevisar att användningen av HAVING är långsammare, och att filtrera tidigt med WHERE är snabbare.
Naturligtvis betyder det inte att HA är värdelöst. Ett undantag är när du använder HAVING med ett aggregat som HAVING SUM(sod.Linetotal)> 100000 . Du kan kombinera en WHERE-sats och en HAVING-sats i en fråga.
Se utförandeplanen i figur 2.
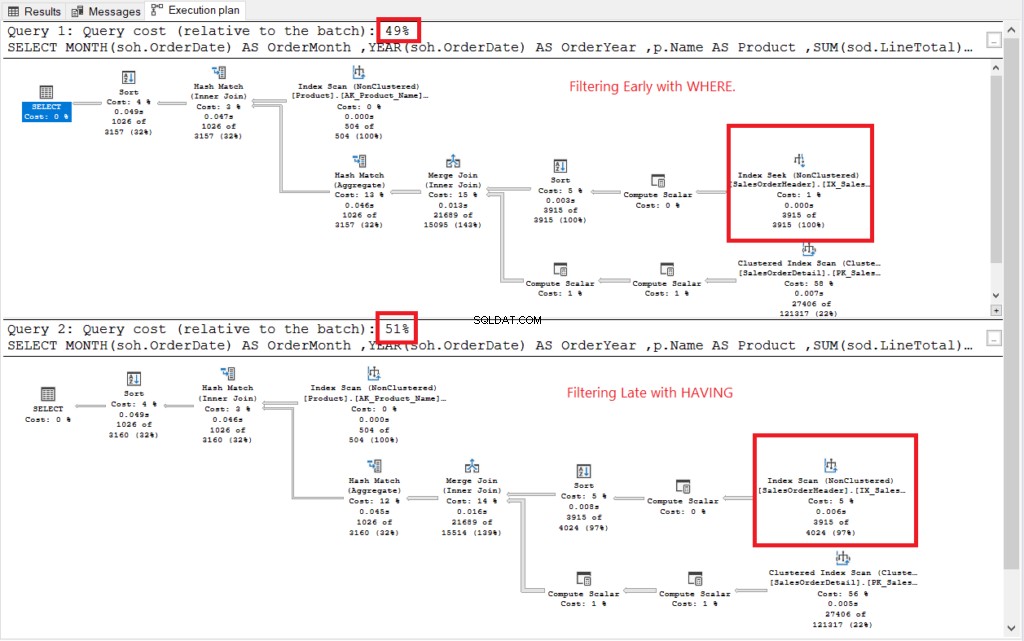
Figur 2 . Utförandeplaner för filtrering tidigt kontra filtrering sent.
Båda avrättningsplanerna såg likadana ut förutom de som var inrutade i rött. Tidig filtrering använde Index Seek-operatorn medan en annan använde Index Scan. Sökningar är snabbare än skanningar i stora tabeller.
Nej te: Att filtrera tidigt kostar mindre än att filtrera sent. Så slutsatsen är att filtrera raderna tidigt kan förbättra prestandan.
2. Gruppera först, gå med senare
Att gå med i några av de tabeller du behöver senare kan också förbättra prestandan.
Låt oss säga att du vill ha månatlig produktförsäljning. Du måste också få produktnamn, nummer och underkategori i samma fråga. Dessa kolumner finns i en annan tabell. Och de måste alla läggas till i GROUP BY-satsen för att få en framgångsrik exekvering. Här är koden.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Det här kommer att gå bra. Men det finns ett bättre och snabbare sätt. Detta kräver inte att du lägger till de tre kolumnerna för produktnamn, nummer och underkategori i GROUP BY-satsen. Detta kommer dock att kräva lite fler tangenttryckningar. Här är den.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analys
Varför går det här snabbare? Anslutningarna till Produkt och ProductSubcategory görs senare. Båda är inte involverade i GROUP BY-satsen. Låt oss bevisa detta med siffror i STATISTICS IO. Se figur 4.
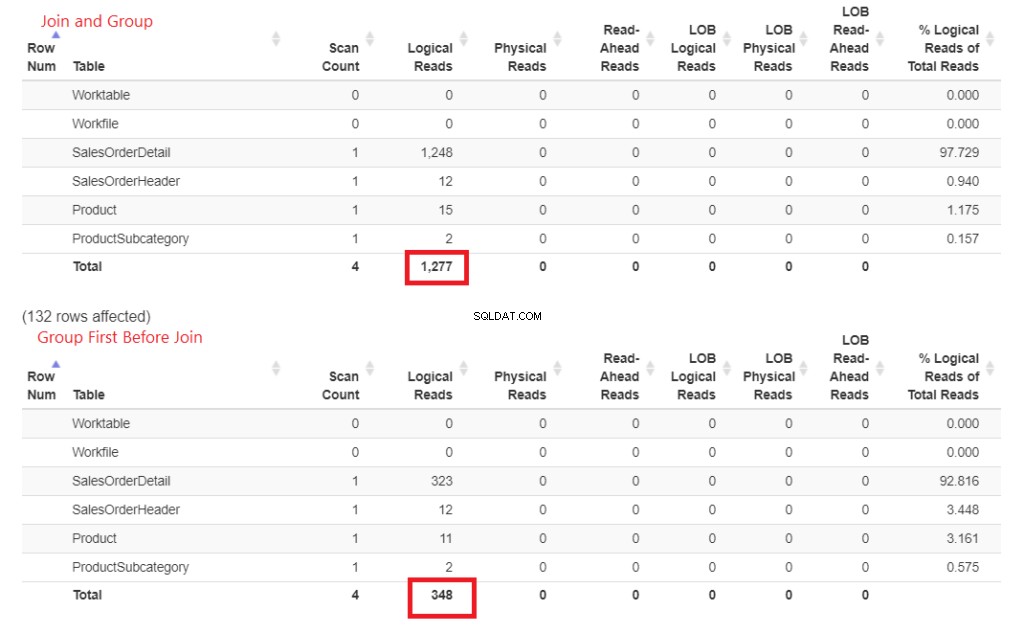
Figur 3 . Att gå med tidigt och sedan gruppera förbrukade mer logiska läsningar än att göra anslutningarna senare.
Ser du de logiska läsningarna? Skillnaden är stor och vinnaren är uppenbar.
Låt oss jämföra genomförandeplanen för de två frågorna för att se orsaken bakom siffrorna ovan. Se först figur 4 för exekveringsplanen för frågan med alla tabeller sammanfogade när de grupperas.
Figur 4 . Utförandeplan när alla bord är sammanfogade.
Och vi har följande observationer:
- GROUP BY och SUM gjordes sent i processen efter att ha gått med i alla tabeller.
- Många tjockare linjer och pilar – detta förklarar de 1 277 logiska läsningarna.
- De två sökfrågorna tillsammans utgör 100 % av frågekostnaden. Men den här frågans plan har en högre frågekostnad (56%).
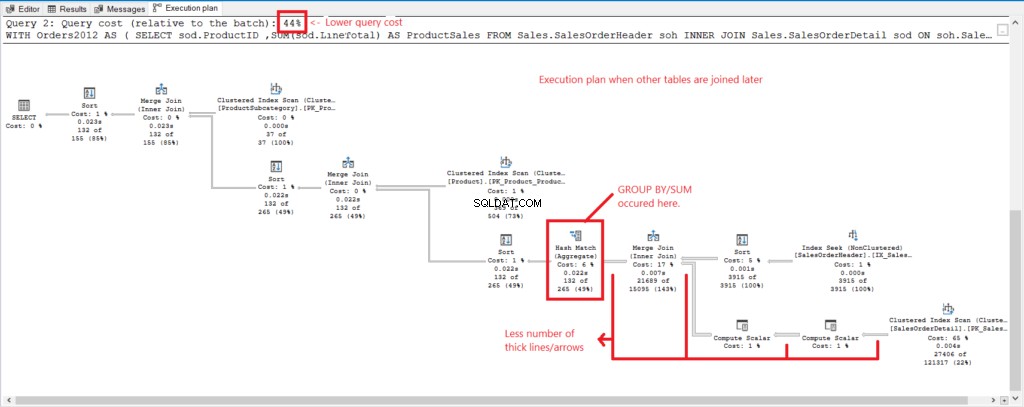
Nu, här är en utförandeplan när vi först grupperade oss och gick med i produkten och ProductSubcategory bord senare. Kolla in figur 5.
Figur 5 . Utförandeplan när gruppen först, gå med senare är klar.
Och vi har följande observationer i figur 5.
- GROUP BY och SUM slutade tidigt.
- Mindre antal tjocka linjer och pilar – detta förklarar endast de 348 logiska läsningarna.
- Lägre frågekostnad (44%).
3. Gruppera en indexerad kolumn
Närhelst SQL GROUP BY görs på en kolumn, bör den kolumnen ha ett index. Du kommer att öka körhastigheten när du grupperar kolumnen med ett index. Låt oss ändra den tidigare frågan och använda leveransdatumet istället för beställningsdatumet. Kolumnen för leveransdatum har inget index i SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Tryck på Ctrl-M och kör sedan frågan ovan i SSMS. Skapa sedan ett icke-klustrat index på ShipDate kolumn. Notera de logiska läsningarna och utförandeplanen. Kör slutligen frågan ovan på en annan frågeflik igen. Notera skillnaderna i logiska läsningar och exekveringsplaner.
Här är jämförelsen av de logiska läsningarna i figur 6.
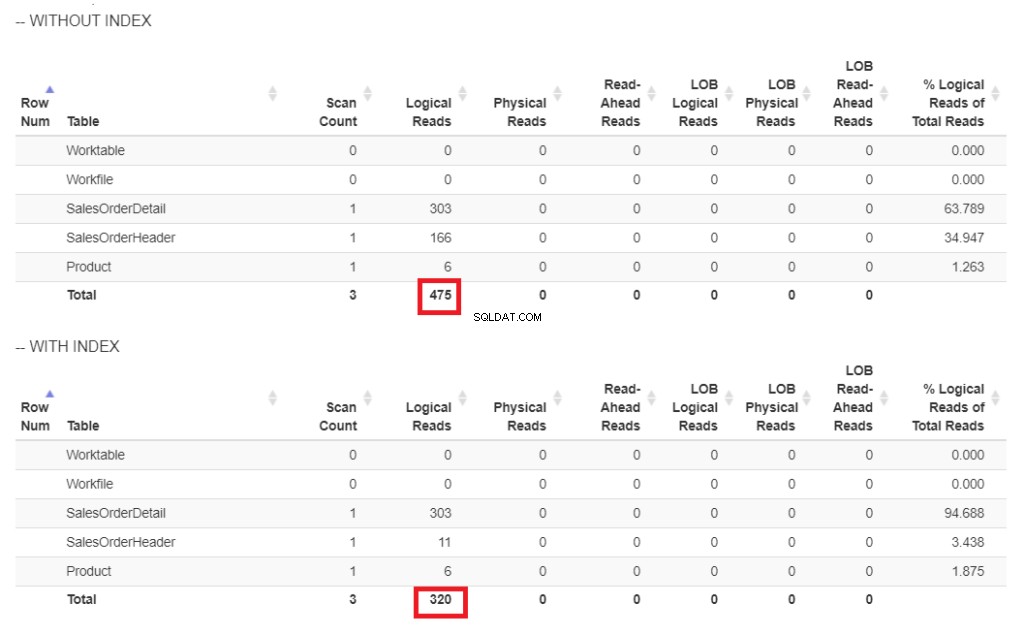
Figur 6 . Logiska läsningar av vårt frågeexempel med och utan ett index på ShipDate.
I figur 6 finns det högre logiska läsningar av frågan utan ett index på ShipDate .
Låt oss nu ha exekveringsplanen när inget index på ShipDate finns i figur 7.
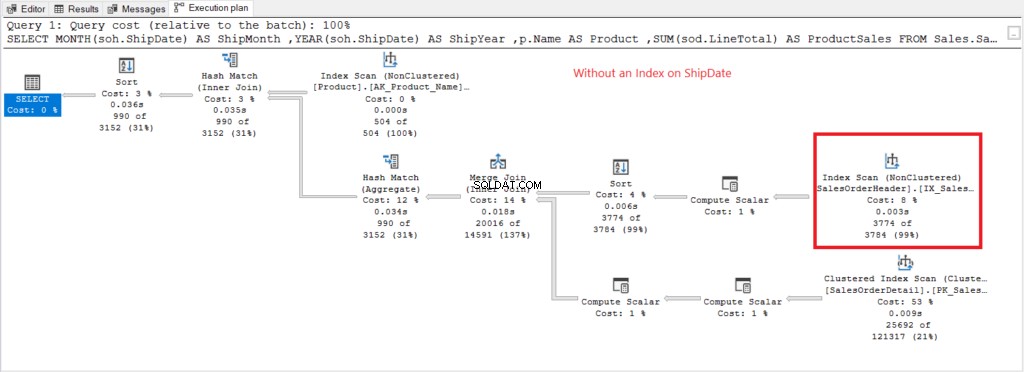
Figur 7 . Exekutivplan vid användning av GROUP BY på ShipDate oindexerad.
Indexsökning operatorn som används i planen i figur 7 förklarar de högre logiska avläsningarna (475). Här är en utförandeplan efter indexering av ShipDate kolumn.
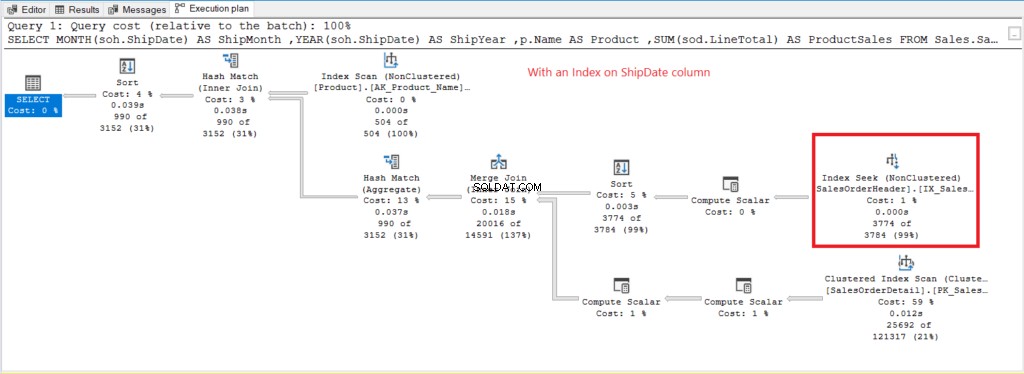
Figur 8 . Exekutivplan när du använder GROUP BY på ShipDate indexerad.
Istället för Index Scan används en Index Seek efter indexering av ShipDate kolumn. Detta förklarar de lägre logiska läsningarna i figur 6.
Så för att förbättra prestandan när du använder GROUP BY, överväg att indexera kolumnerna du använde för att gruppera.
Takeaways i att använda SQL GROUP BY
SQL GROUP BY är lätt att använda. Men du måste ta nästa steg för att gå längre än att sammanfatta data för rapporter. Här är punkterna igen:
- Filtrera tidigt . Ta bort raderna som du inte behöver sammanfatta med hjälp av WHERE-satsen istället för HAVING-satsen.
- Grupp dig först, gå med senare . Ibland kommer det att finnas kolumner du behöver lägga till förutom de kolumner du grupperar. Istället för att inkludera dem i GROUP BY-satsen, dela frågan med en CTE och gå med i andra tabeller senare.
- Använd GROUP BY med indexerade kolumner . Denna grundläggande sak kan vara praktisk när databasen är snabb som en snigel.
Hoppas detta hjälper dig att höja ditt spel i nivå med att gruppera resultat.
Om du gillar det här inlägget, vänligen dela det på dina favoritplattformar för sociala medier.