Typiska frågor i tabellformatet SELECT * FROM räcker ibland inte. När data för en fråga inte finns i en tabell, utan i flera, eller när det är nödvändigt att ange flera urvalsparametrar samtidigt, behöver du mer sofistikerade frågor.
Den här artikeln kommer att förklara hur man bygger sådana frågor och ger exempel på komplexa SQL-frågor.
Hur ser en komplex fråga ut?
Låt oss först definiera villkoren för att skapa SQL-frågan. I synnerhet måste du använda följande urvalsparametrar:
- namnen på tabellerna som du vill extrahera data från;
- värdena för fält som måste returneras till de ursprungliga efter att ha gjort ändringar i databasen;
- relationerna mellan tabeller;
- provtagningsförhållandena;
- de extra urvalskriterierna (begränsningar, sätt att presentera information, typ av sortering).
För att bättre förstå ämnet, låt oss överväga ett exempel som använder följande fyra enkla tabeller. Den första raden är namnet på tabellen som i komplexa frågor fungerar som en främmande nyckel. Vi kommer att överväga detta i detalj med ett exempel:
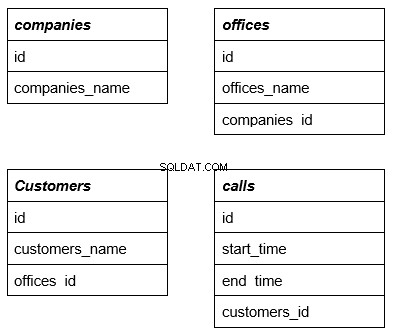
Varje tabell har rader relaterade till några andra tabeller. Vi kommer att förklara varför det är nödvändigt ytterligare.
Låt oss nu titta på den grundläggande SQL-frågan:
SELECT * FROM companies WHERE companies_name %STARTSWITH 'P';%STARTSWITH predikat väljer rader som börjar med det/de angivna tecknet/tecken.
Resultatet ser ut så här:

Låt oss nu överväga en komplex SQL-fråga:
SELECT
companies.companies_name,
SUM(CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
HAVING AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) > (SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls)
ORDER BY calls DESC, companies.id ASC;
Resultatet är följande tabell:

Tabellen visar företagen, motsvarande antal telefonsamtal och deras ungefärliga varaktighet.
Dessutom listar den bara de företagsnamn där den genomsnittliga samtalslängden är längre än den genomsnittliga samtalslängden i andra företag.
Vilka är huvudreglerna för att skapa komplexa SQL-frågor?
Låt oss försöka skapa en mångsidig algoritm för att komponera komplexa frågor.
Först och främst måste du bestämma tabellerna som består av de data som deltar i frågan.
Exemplet ovan involverar företagen och samtal tabeller. Om tabellerna med de nödvändiga uppgifterna inte är direkt relaterade till varandra måste du även inkludera mellantabellerna som förenar dem.
Av den anledningen kopplar vi även ihop tabeller, såsom kontor och kunder , med hjälp av främmande nycklar. Därför kommer alla resultat av frågan med tabeller från detta exempel alltid att inkludera nedanstående rader:
SELECT
...
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
...;
After that, you must test the correctness of the behavior in the following part of the query:
SELECT * FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id;
En kombinerad tabell föreslår de tre viktigaste punkterna:
- Var uppmärksam på listan med fält efter SELECT. Operationen för att läsa data från sammanfogade tabeller kräver att du anger namnet på tabellen som ska sammanfogas i namnet fältet.
- Din komplexa fråga kommer alltid att ha huvudtabellen (företag ). De flesta fälten läses från den. Den bifogade tabellen, i vårt exempel, använder tre tabeller – kontor , kunder och samtal . Namnet bestäms efter JOIN-operatören.
- Förutom att ange namnet på den andra tabellen, se till att ange villkoret för att utföra kopplingen. Vi kommer att diskutera detta villkor ytterligare.
- Frågan visar en tabell med ett stort antal rader. Det finns ingen anledning att publicera den här, eftersom den visar mellanliggande resultat. Du kan dock alltid kontrollera dess utdata själv. Detta är mycket viktigt, eftersom det hjälper till att undvika misstag i slutresultatet.
Låt oss nu titta på den del av frågan som jämför samtalslängd inom varje företag och mellan alla företag. Vi måste beräkna den genomsnittliga varaktigheten för alla samtal. Använd följande fråga:
SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls
Observera att vi använde DATEDIFF funktion som matar ut skillnaden mellan de angivna perioderna. I vårt fall är den genomsnittliga samtalslängden lika med 335 sekunder.
Låt oss nu lägga till data om samtal från alla företag i frågan.
SELECT
companies.companies_name,
SUM(CASE WHEN calls.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
ORDER BY calls DESC, companies.id ASC;
I den här frågan,
- SUMMA (FALL NÄR calls.id INTE ÄR NULL DÅ 1 ANNAT 0 SLUT) – för att undvika onödiga operationer sammanfattar vi endast befintliga samtal – när antalet samtal i ett företag inte är noll. Detta är mycket viktigt i stora tabeller med möjliga nollvärden.
- AVG (ISNULL (DATEDIFF (SECOND, calls.start_time, calls.end_time), 0)) – frågan är identisk med AVG-frågan ovan. Men här använder vi ISNULL operatör som ersätter NULL med 0. Det är nödvändigt för företag som inte har några samtal alls.
Våra resultat:
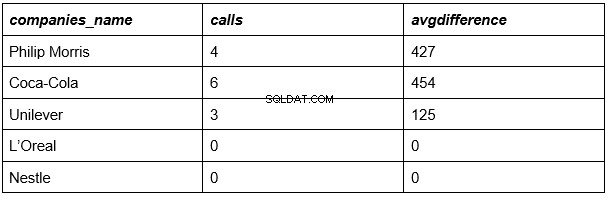
Vi är nästan klara. Tabellen ovan visar listan över företag, motsvarande antal samtal för vart och ett av dem och den genomsnittliga samtalslängden i vart och ett av dem.
Det enda som återstår är att jämföra siffrorna från den sista kolumnen med den genomsnittliga varaktigheten för alla samtal från alla företag (335 sekunder).
Om du anger frågan som vi presenterade i början, lägg bara till HA del, kommer du att få det du behöver.
Vi rekommenderar starkt att du lägger till kommentarer på varje rad så att du inte blir förvirrad i framtiden när du behöver korrigera några befintliga komplexa SQL-frågor.
Sluta tankar
Även om varje komplex SQL-fråga kräver ett individuellt tillvägagångssätt, är vissa rekommendationer lämpliga för att förbereda de flesta sådana frågor.
- bestäm vilka tabeller som ska delta i frågan;
- skapa komplexa frågor från enklare delar;
- kontrollera noggrannheten av frågor sekventiellt, i delar;
- testa riktigheten av din fråga med mindre tabeller;
- skriv detaljerade kommentarer på varje rad som innehåller operanden, med hjälp av symbolerna '-'.
Specialiserade verktyg gör det här jobbet mycket enklare. Bland dem rekommenderar vi att du använder Query Builder – ett visuellt verktyg som gör det möjligt att konstruera även de mest komplexa frågorna mycket snabbare i ett visuellt läge. Det här verktyget är tillgängligt som en fristående lösning eller som en del av dbForge Studio för SQL Server med flera funktioner.
Vi hoppas att den här artikeln har hjälpt dig att klargöra detta specifika problem.