
För denna månads T-SQL-tisdag bad Steve Jones (@way0utwest) oss att prata om våra bästa eller sämsta triggerupplevelser. Även om det är sant att triggers ofta ogillas, och till och med fruktas, har de flera giltiga användningsfall, inklusive:
- Revision (före 2016 SP1, då denna funktion blev gratis i alla utgåvor)
- Upprätthållande av affärsregler och dataintegritet när de inte enkelt kan implementeras i begränsningar och du inte vill att de ska vara beroende av applikationskoden eller själva DML-frågorna
- Underhålla historiska versioner av data (före ändringsdatainsamling, ändringsspårning och tidstabeller)
- Kövarningar eller asynkron bearbetning som svar på en specifik ändring
- Tillåt modifieringar av vyer (via INSTEAD OF triggers)
Det är inte en uttömmande lista, bara en snabb sammanfattning av några scenarier jag har upplevt där triggers var det rätta svaret vid den tiden.
När triggers är nödvändiga, gillar jag alltid att undersöka användningen av Istället för triggers snarare än EFTER-triggers. Ja, de är lite mer i förväg*, men de har några ganska viktiga fördelar. Åtminstone i teorin verkar möjligheten att förhindra en åtgärd (och dess loggkonsekvenser) från att inträffa mycket effektivare än att låta allt hända och sedan ångra det.
*Jag säger detta eftersom du måste koda DML-satsen igen inom triggern; det är därför de inte kallas FÖRE triggers. Skillnaden är viktig här, eftersom vissa system implementerar sanna FÖRE-utlösare, som helt enkelt körs först. I SQL Server avbryter en INSTEAD OF-utlösare satsen som fick den att aktiveras.
Låt oss låtsas att vi har en enkel tabell för att lagra kontonamn. I det här exemplet skapar vi två tabeller, så att vi kan jämföra två olika utlösare och deras inverkan på frågans varaktighet och logganvändning. Konceptet är att vi har en affärsregel:kontonamnet finns inte i en annan tabell, som representerar "dåliga" namn, och utlösaren används för att upprätthålla denna regel. Här är databasen:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO Och tabellerna:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
Och slutligen triggers. För enkelhetens skull har vi bara att göra med inlägg, och i både efter- och istället för fallet kommer vi bara att avbryta hela batchen om något enstaka namn bryter mot vår regel:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO För att testa prestandan försöker vi bara infoga 100 000 namn i varje tabell, med en förutsägbar felfrekvens på 10 %. Med andra ord, 90 000 är okej namn, de andra 10 000 misslyckas i testet och gör att triggern antingen återställs eller inte infogas beroende på batch.
Först måste vi göra lite rengöring före varje batch:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Innan vi börjar köttet för varje batch, räknar vi raderna i transaktionsloggen och mäter storleken och ledigt utrymme. Sedan går vi igenom en markör för att bearbeta de 100 000 raderna i slumpmässig ordning, och försöker infoga varje namn i lämplig tabell. När vi är klara mäter vi radantalet och storleken på loggen igen och kontrollerar varaktigheten.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Resultat (i genomsnitt över 5 körningar av varje batch):
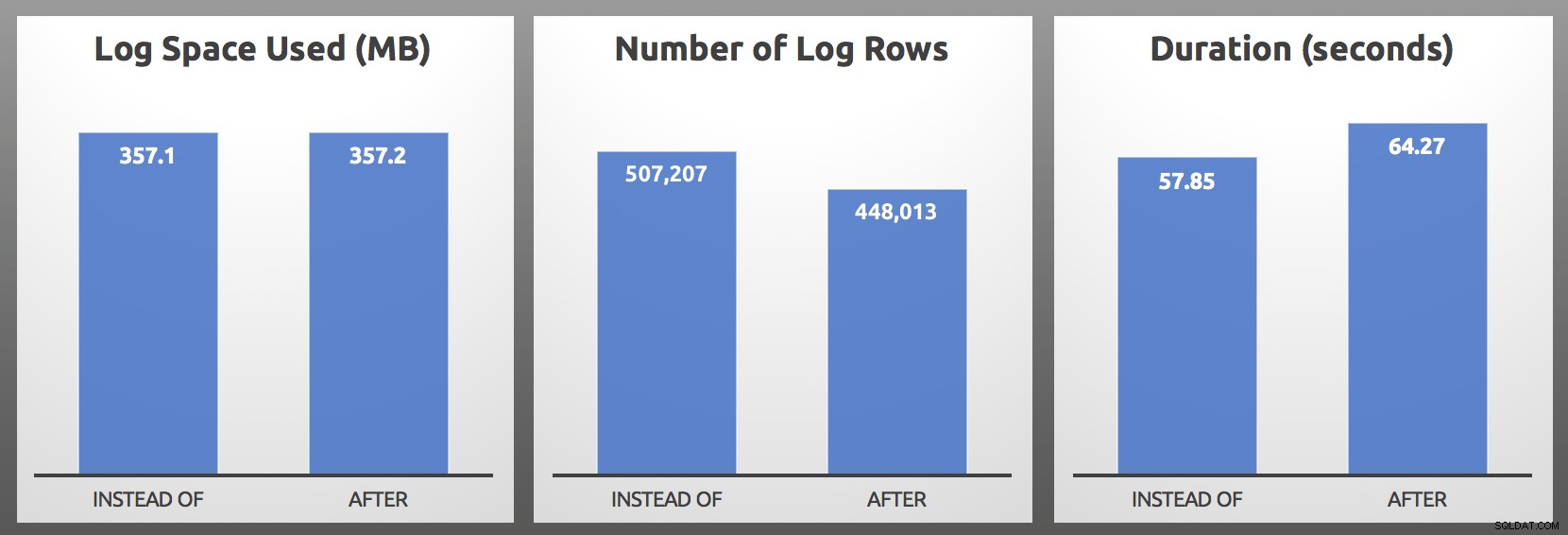 EFTER vs. I STÄLLET FÖR :Resultat
EFTER vs. I STÄLLET FÖR :Resultat
I mina tester var logganvändningen nästan identisk i storlek, med över 10 % fler loggrader som genererades av utlösaren INSTEAD OF. Jag grävde lite i slutet av varje batch:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Och här var ett typiskt resultat (jag markerade de stora deltan):
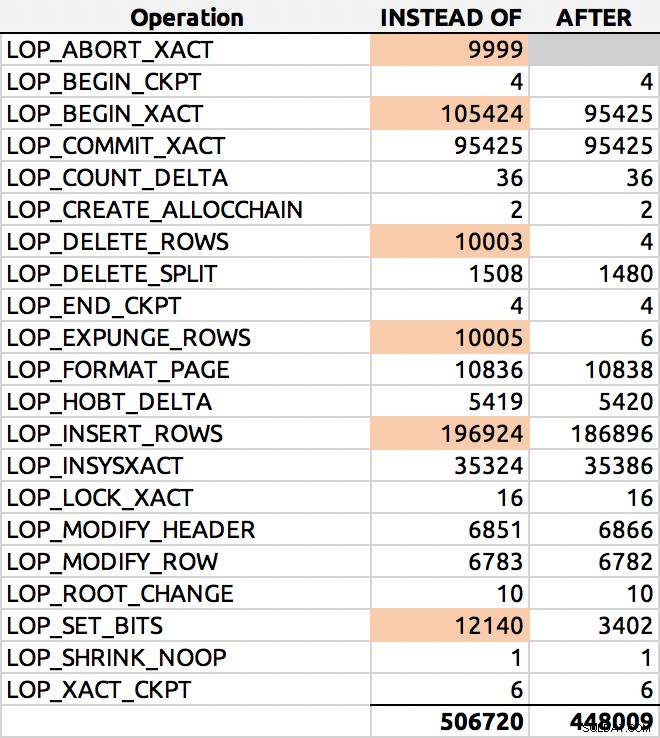 Loggraddistribution
Loggraddistribution
Jag ska fördjupa mig i det en annan gång.
Men när du kommer direkt till det...
…det viktigaste måttet är nästan alltid varaktighet , och i mitt fall utförde triggern INSTEAD OF minst 5 sekunder snabbare i varje enskilt head-to-head-test. Om det här låter bekant, ja, jag har pratat om det förut, men då såg jag inte samma symptom med loggraderna.
Observera att detta kanske inte är ditt exakta schema eller arbetsbelastning, du kan ha väldigt olika hårdvara, din samtidighet kan vara högre och din felfrekvens kan vara mycket högre (eller lägre). Mina tester utfördes på en isolerad maskin med mycket minne och mycket snabba PCIe SSD:er. Om din logg är på en långsammare enhet, kan skillnaderna i logganvändning uppväga de andra mätvärdena och ändra varaktigheterna avsevärt. Alla dessa faktorer (och fler!) kan påverka dina resultat, så du bör testa i din miljö.
Poängen är dock att Istället för triggers kanske passar bättre. Om vi bara kunde få ISTÄLLET FÖR DDL-utlösare...