Att lägga till ett filtrerat index kan ha överraskande bieffekter på befintliga frågor, även där det verkar som om det nya filtrerade indexet är helt orelaterade. Det här inlägget tittar på ett exempel som påverkar DELETE-satser som resulterar i dålig prestanda och en ökad risk för dödläge.
Testmiljö
Följande tabell kommer att användas i det här inlägget:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Denna nästa sats skapar 499 999 rader med exempeldata:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Som använder en Numbers-tabell som en källa för på varandra följande heltal från 1 till 499 999. Om du inte har en av dessa i din testmiljö, kan följande kod användas för att effektivt skapa en som innehåller heltal från 1 till 1 000 000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); Grunden för de senare testerna kommer att vara att radera rader från testtabellen för ett visst Startdatum. För att göra processen att identifiera rader som ska raderas mer effektiv, lägg till detta icke-klustrade index:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Exempeldata
När dessa steg är slutförda kommer provet att se ut så här:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
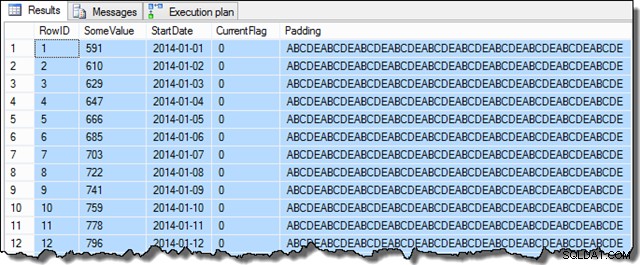
SomeValue-kolumndata kan vara något annorlunda på grund av den pseudo-slumpmässiga genereringen, men denna skillnad är inte viktig. Sammantaget innehåller exempeldatan 16 129 rader för vart och ett av de 31 startdatumen i januari 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
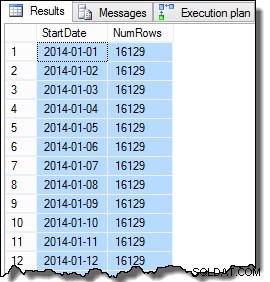
Det sista steget vi behöver utföra för att göra data något realistiskt, är att ställa in CurrentFlag-kolumnen till sant för det högsta rad-ID för varje startdatum. Följande skript utför denna uppgift:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Exekveringsplanen för den här uppdateringen innehåller en Segment-Top-kombination för att effektivt lokalisera det högsta RowID per dag:

Lägg märke till hur exekveringsplanen inte liknar den skrivna formen av frågan. Detta är ett bra exempel på hur optimeraren fungerar utifrån den logiska SQL-specifikationen, snarare än att implementera SQL direkt. Om du undrar så krävs den ivriga bordsspolen i den planen för Halloweenskydd.
Ta bort en dag med data
Ok, så när förberedelserna är klara är uppgiften att ta bort rader för ett visst startdatum. Det här är den typ av fråga du rutinmässigt kan köra på det tidigaste datumet i en tabell, där data har nått slutet av sin livslängd.
Med den 1 januari 2014 som vårt exempel är frågan om testborttagning enkel:
DELETE dbo.Data WHERE StartDate = '20140101';
Utförandeplanen är också ganska enkel, men värd att titta på lite i detalj:

Plananalys
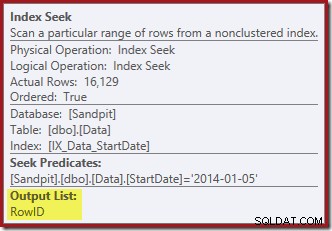
Indexsökningen längst till höger använder det icke-klustrade indexet för att hitta rader för det angivna StartDate-värdet. Den returnerar bara RowID-värdena den hittar, som operatörens verktygstips bekräftar:
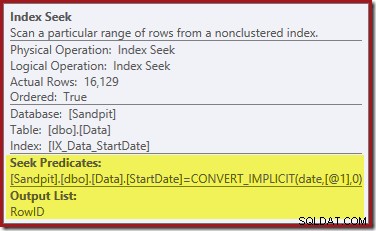
Om du undrar hur StartDate-indexet lyckas returnera RowID, kom ihåg att RowID är det unika klustrade indexet för tabellen, så det inkluderas automatiskt i StartDate-icke-klustrade indexet.
Nästa operatör i planen är Clustered Index Delete. Detta använder RowID-värdet som hittas av Index Seek för att hitta rader att ta bort.
Den sista operatören i planen är en Index Delete. Detta tar bort rader från det icke-klustrade indexet IX_Data_StartDate som är relaterade till det rad-ID som tagits bort av raderingen av Clustered Index. För att lokalisera dessa rader i det icke-klustrade indexet behöver frågeprocessorn StartDate (nyckeln för det icke-klustrade indexet).
Kom ihåg att den ursprungliga Indexsökningen inte returnerade startdatumet, bara RowID. Så hur får frågeprocessorn startdatumet för indexraderingen? I det här specifika fallet kan optimeraren ha märkt att StartDate-värdet är en konstant och optimerat bort det, men det är inte vad som hände. Svaret är att operatorn Clustered Index Delete läser StartDate-värdet för den aktuella raden och lägger till det i flödet. Jämför utdatalistan för raderingen av klustrade index som visas nedan, med den för Indexsökningen precis ovanför:
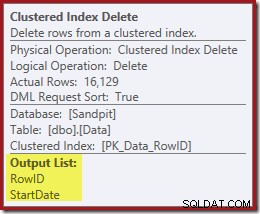
Det kan verka förvånande att se en Delete-operatör läsa data, men det är så här det fungerar. Frågeprocessorn vet att den måste lokalisera raden i det klustrade indexet för att kunna ta bort det, så den kan lika gärna skjuta upp läsningen av kolumner som behövs för att upprätthålla icke-klustrade index till den tidpunkten, om den kan.
Lägga till ett filtrerat index
Föreställ dig nu att någon har en avgörande fråga mot den här tabellen som fungerar dåligt. Den hjälpsamma DBA utför en analys och lägger till följande filtrerade index:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Det nya filtrerade indexet har önskad effekt på den problematiska frågan, och alla är nöjda. Lägg märke till att det nya indexet inte refererar till kolumnen StartDate alls, så vi förväntar oss inte att det kommer att påverka vår dagraderingsfråga alls.
Ta bort en dag med det filtrerade indexet på plats
Vi kan testa den förväntningen genom att radera data en andra gång:
DELETE dbo.Data WHERE StartDate = '20140102';
Plötsligt har exekveringsplanen ändrats till en parallell Clustered Index Scan:

Observera att det inte finns någon separat Index Delete-operator för det nya filtrerade indexet. Optimeraren har valt att behålla detta index i operatorn Clustered Index Delete. Detta är markerat i SQL Sentry Plan Explorer som visas ovan ("+1 icke-klustrade index") med fullständig information i verktygstipset:
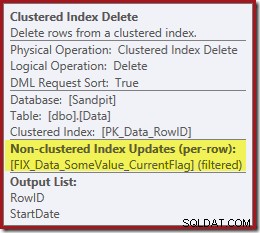
Om tabellen är stor (tänk data warehouse) kan denna förändring till en parallell skanning vara mycket betydande. Vad hände med den trevliga Indexsöken på StartDate, och varför ändrade ett helt orelaterade filtrerat index saker så dramatiskt?
Hitta problemet
Den första ledtråden kommer från att titta på egenskaperna för Clustered Index Scan:
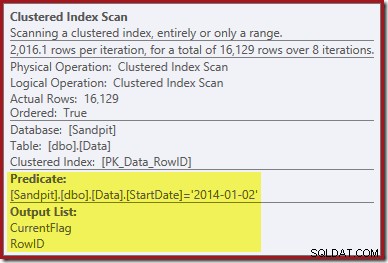
Förutom att hitta RowID-värden för Clustered Index Delete-operatorn att ta bort, läser denna operatör nu CurrentFlag-värden. Behovet av denna kolumn är oklart, men den börjar åtminstone förklara beslutet att skanna:CurrentFlag-kolumnen är inte en del av vårt StartDate-icke-klustrade index.
Vi kan bekräfta detta genom att skriva om raderingsfrågan för att tvinga fram användningen av StartDate icke-klustrade index:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Utförandeplanen är närmare sin ursprungliga form, men den har nu en nyckelsökning:
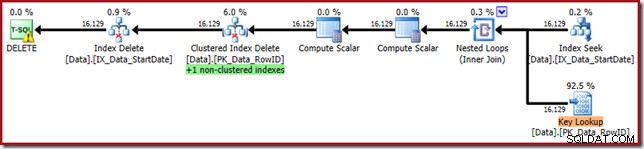
Nyckelsökningsegenskaperna bekräftar att denna operatör hämtar CurrentFlag-värden:
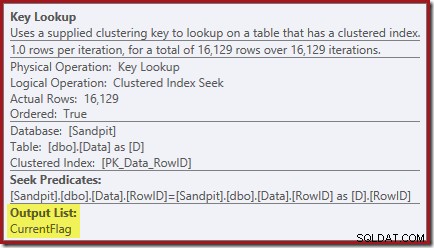
Du kanske också har lagt märke till varningstrianglarna i de två senaste planerna. Dessa saknar indexvarningar:
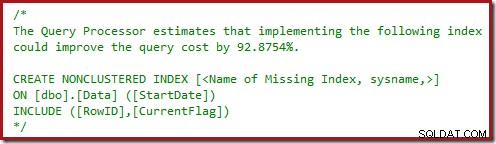
Detta är ytterligare en bekräftelse på att SQL Server skulle vilja se CurrentFlag-kolumnen inkluderad i det icke-klustrade indexet. Anledningen till ändringen till en parallell Clustered Index Scan är nu klar:frågeprocessorn beslutar att genomsökning av tabellen blir billigare än att utföra nyckelsökningar.
Ja, men varför?
Det här är väldigt konstigt. I den ursprungliga exekveringsplanen kunde SQL Server läsa extra kolumndata som behövs för att upprätthålla icke-klustrade index vid Clustered Index Delete-operatorn. Kolumnvärdet CurrentFlag behövs för att behålla det filtrerade indexet, så varför hanterar SQL Server det inte bara på samma sätt?
Det korta svaret är att det kan, men bara om det filtrerade indexet bibehålls i en separat Index Delete-operator. Vi kan tvinga fram detta för den aktuella frågan med odokumenterad spårningsflagga 8790. Utan denna flagga väljer optimeraren om varje index ska behållas i en separat operatör eller som en del av bastabelloperationen.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Exekveringsplanen är tillbaka till att söka efter StartDate icke-klustrade index:
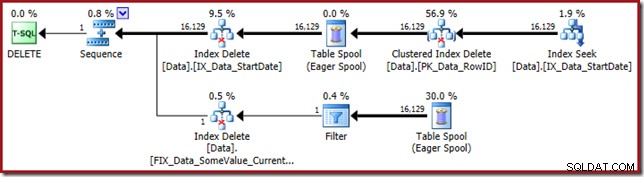
Indexsökningen returnerar bara RowID-värden (ingen CurrentFlag):
Och Clustered Index Delete läser kolumnerna som behövs för att underhålla de icke-klustrade indexen, inklusive CurrentFlag:
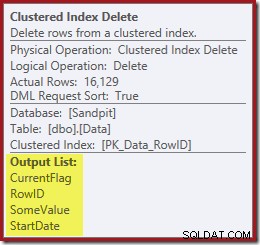
Dessa data skrivs ivrigt till en bordsspole, som är uppspelningen för varje index som behöver underhållas. Lägg också märke till den explicita Filter-operatorn före Index Delete-operatorn för det filtrerade indexet.
Ännu ett mönster att se upp för
Detta problem leder inte alltid till en tabellsökning istället för en indexsökning. För att se ett exempel på detta, lägg till ytterligare ett index i testtabellen:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Observera att detta index är inte filtreras och involverar inte kolumnen StartDate. Försök nu en dag-raderingsfråga igen:
DELETE dbo.Data WHERE StartDate = '20140104';
Optimeraren kommer nu med detta monster:
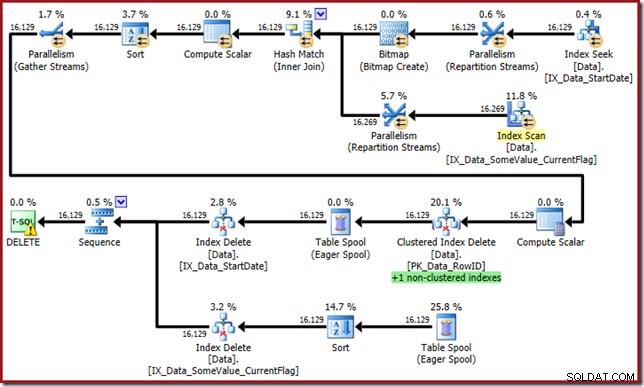
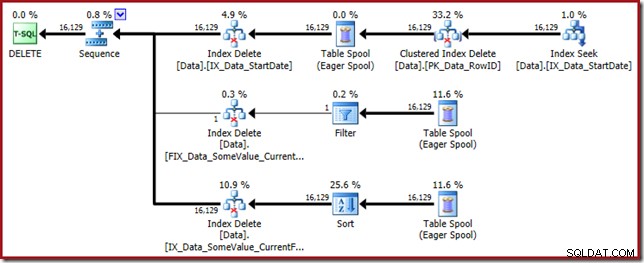
Den här frågeplanen har en hög överraskningsfaktor, men grundorsaken är densamma. Kolumnen CurrentFlag behövs fortfarande, men nu väljer optimeraren en indexskärningsstrategi för att få den istället för en tabellskanning. Att använda spårningsflaggan tvingar fram en underhållsplan per index och förnuftet återställs igen (den enda skillnaden är en extra spoolrepris för att behålla det nya indexet):
Endast filtrerade index orsakar detta
Det här problemet uppstår bara om optimeraren väljer att behålla ett filtrerat index i en Clustered Index Delete-operator. Icke-filtrerade index påverkas inte, vilket följande exempel visar. Det första steget är att ta bort det filtrerade indexet:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Nu måste vi skriva frågan på ett sätt som övertygar optimeraren att behålla alla index i Clustered Index Delete. Mitt val för detta är att använda en variabel och en ledtråd för att sänka optimerarens förväntningar på radantal:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Utförandeplanen är:
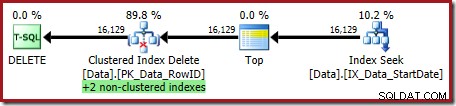
Båda icke-klustrade indexen underhålls av Clustered Index Delete:
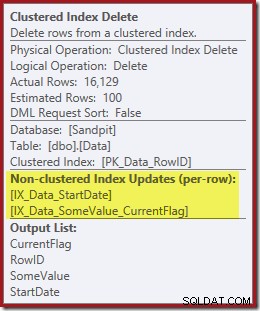
Indexsökningen returnerar endast RowID:
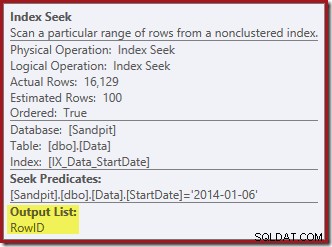
Kolumnerna som behövs för indexunderhållet hämtas internt av raderingsoperatören; dessa detaljer är inte exponerade i visa planutdata (så utdatalistan för raderingsoperatören skulle vara tom). Jag lade till en OUTPUT klausul till frågan för att visa Clustered Index Delete återigen returnera data som den inte tog emot på sin inmatning:
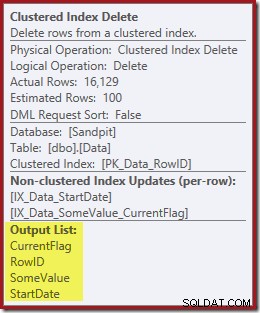
Sluta tankar
Detta är en knepig begränsning att komma runt. Å ena sidan vill vi generellt inte använda odokumenterade spårningsflaggor i produktionssystem.
Den naturliga "fixen" är att lägga till de kolumner som behövs för underhåll av filtrerat index till alla icke-klustrade index som kan användas för att hitta rader att ta bort. Detta är inte ett särskilt tilltalande förslag, ur ett antal synpunkter. Ett annat alternativ är att helt enkelt inte använda filtrerade index, men det är knappast idealiskt heller.
Min känsla är att frågeoptimeraren borde överväga ett underhållsalternativ per index för filtrerade index automatiskt, men dess resonemang verkar vara ofullständig på detta område just nu (och baserat på enkla heuristik snarare än att korrekt kosta per index/per rad alternativ).
För att sätta några siffror runt det påståendet kom den parallella klustrade indexskanningsplanen som valdes av optimeraren in på 5.5 enheter i mina tester. Samma fråga med spårningsflaggan uppskattar en kostnad på 1,4 enheter. Med det tredje indexet på plats hade den parallella index-korsningsplanen som valdes av optimeraren en uppskattad kostnad på 4,9 , medan spårningsflaggan kom in på 2.7 enheter (alla tester på SQL Server 2014 RTM CU1 build 12.0.2342 under 120 kardinalitetsuppskattningsmodellen och med spårningsflagga 4199 aktiverad).
Jag ser detta som ett beteende som borde förbättras. Du kan rösta för att hålla med eller inte hålla med mig om detta Connect-objekt.