Vi lanserade nyligen en ny supportwebbplats där du kan ställa frågor, skicka produktfeedback eller funktionsförfrågningar eller öppna supportbiljetter. En del av målet var att centralisera alla platser där vi erbjöd hjälp till samhället. Detta inkluderade webbplatsen SQLPerformance.com Frågor och Svar, där Paul White, Hugo Kornelis och många andra har hjälpt till att lösa dina mest komplicerade frågor om justering av sökfrågor och exekveringsplaner, som går ända tillbaka till februari 2013. Jag berättar med blandade känslor att Frågor och svar-webbplatsen har stängts.
Det finns dock en uppsida. Du kan nu ställa de svåra frågorna på det nya supportforumet. Om du letar efter det gamla innehållet, ja, det finns fortfarande kvar, men det ser lite annorlunda ut. Av olika anledningar som jag inte kommer in på idag, när vi väl bestämde oss för att ta bort den ursprungliga Q&A-webbplatsen, bestämde vi oss till slut för att helt enkelt vara värd för allt befintligt innehåll på en skrivskyddad WordPress-webbplats, istället för att migrera det till baksidan. av den nya webbplatsen.
Det här inlägget handlar inte om skälen bakom beslutet.
Jag mådde riktigt dåligt över hur snabbt svarssidan var tvungen att bli offline, DNS bytte och innehållet migrerade. Eftersom en varningsbanner implementerades på sajten men AnswerHub faktiskt inte gjorde den synlig var detta en chock för många användare. Så jag ville se till att jag bevarade så mycket av innehållet som möjligt, och jag ville att det skulle vara rätt. Det här inlägget är här för att jag tyckte att det skulle vara intressant att prata om själva processen, hur många olika tekniker som var involverade i att få fram den, och att visa upp resultatet. Jag förväntar mig inte att någon av er kommer att dra nytta av detta från början, eftersom det här är en relativt obskyr migreringsväg, utan mer som ett exempel på att knyta ihop ett gäng tekniker för att utföra en uppgift. Det fungerar också som en bra påminnelse till mig själv om att många saker inte blir så lätta som de låter innan du börjar.
TL;DR är detta:Jag har lagt ner mycket tid och ansträngning på att få det arkiverade innehållet att se bra ut, även om jag fortfarande försöker återställa de senaste inläggen som kom in mot slutet. Jag använde dessa tekniker:
- Perl
- SQL-server
- PowerShell
- Sändning (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Därav titeln. Om du vill ha en stor del av de blodiga detaljerna, här är de. Om du har några frågor eller feedback, vänligen kontakta eller kommentera nedan.
AnswerHub tillhandahöll en 665 MB dumpfil från MySQL-databasen som var värd för Q&A-innehållet. Varje redigerare jag försökte kvävdes i det, så jag var först tvungen att dela upp det i en fil per tabell med det här praktiska Perl-skriptet från Jared Cheney. Tabellerna jag behövde hette network11_nodes (frågor, svar och kommentarer), network11_authoritables (användare) och network11_managed_files (alla bilagor, inklusive planuppladdningar):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Nu var de inte extremt snabba att ladda i SSMS, men där kunde jag åtminstone använda Ctrl +H för att ändra (till exempel) detta:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
Till detta:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Sedan kunde jag ladda data till SQL Server så att jag kunde manipulera den. Och tro mig, jag manipulerade det.
Därefter var jag tvungen att hämta alla bilagor. Se, MySQL-dumpfilen jag fick från leverantören innehöll en gazillion INSERT uttalanden, men ingen av de faktiska planfilerna som användare hade laddat upp - databasen hade bara de relativa sökvägarna till filerna. Jag använde T-SQL för att bygga en serie PowerShell-kommandon som skulle anropa Invoke-WebRequest att hämta alla filer och lagra dem lokalt (många sätt att flå den här katten, men detta var helt enkelt). Från detta:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Det gav den här uppsättningen kommandon (tillsammans med ett förkommando för att lösa detta TLS-problem); det hela gick ganska snabbt, men jag rekommenderar inte detta tillvägagångssätt för någon kombination av {massive set of files} och/eller {low bandwidth}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Detta laddade ner nästan alla bilagor, men vissa missades visserligen på grund av fel på den gamla sidan när de laddades upp först. Så på den nya webbplatsen kan du ibland se en referens till en bilaga som inte finns.
Sedan använde jag Panic Transmit 5 för att ladda upp temp mapp till den nya webbplatsen, och nu när innehållet laddas upp länkar det till /s/temp/1-proc.pesession kommer att fortsätta att fungera.
Därefter gick jag vidare till SSL. För att begära ett certifikat på den nya WordPress-webbplatsen var vi tvungna att uppdatera DNS för answers.sqlperformance.com för att peka på CNAME på vår WordPress-värd, WPEngine. Det var typ kyckling och ägg här - vi var tvungna att lida av lite driftstopp för https-webbadresser, vilket skulle misslyckas för inget certifikat på den nya webbplatsen. Det här var okej eftersom certifikatet på den gamla sajten hade gått ut, så egentligen hade vi det inte sämre. Jag var också tvungen att vänta med att göra detta tills jag hade laddat ner alla filer från den gamla webbplatsen, för när DNS väl vände över, skulle det inte finnas något sätt att komma åt dem förutom genom en bakdörr.
Medan jag väntade på att DNS skulle spridas började jag arbeta på logiken för att dra alla frågor, svar och kommentarer till något förbrukningsbart i WordPress. Inte bara skilde sig tabellschemana från WordPress, typerna av enheter är också ganska olika. Min vision var att kombinera varje fråga – och eventuella svar och/eller kommentarer – till ett enda inlägg.
Den knepiga delen är att nodtabellen bara innehåller alla de tre innehållstyperna i samma tabell, med överordnade och ursprungliga ("master") överordnade referenser. Deras front-end-kod använder sannolikt någon form av markör för att gå igenom och visa innehållet i hierarkisk och kronologisk ordning. Jag skulle inte ha den lyxen i WordPress, så jag var tvungen att sätta ihop HTML-koden i ett slag. Bara som ett exempel, så här såg data ut:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Jag kunde inte beställa efter id, typ, eller efter förälder, eftersom det ibland kom en kommentar senare på ett tidigare svar, det första svaret skulle inte alltid vara det accepterade svaret, och så vidare. Jag ville ha denna utdata (där ++ representerar en nivå av indrag):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Jag började skriva en rekursiv CTE och
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Resultat:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Geni. Jag kollade på ett dussintal andra och var glad över att gå vidare till nästa steg. Jag har tackat Andy ymnigt flera gånger, men låt mig göra det igen:Tack Andy!
Nu när jag kunde returnera hela uppsättningen i den ordning jag gillade, var jag tvungen att utföra viss manipulation av utdata för att tillämpa HTML-element och klassnamn som skulle låta mig markera frågor, svar, kommentarer och indrag på ett meningsfullt sätt. Slutmålet var utdata som såg ut så här (och kom ihåg att detta är ett av de enklare fallen):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Jag kommer inte att gå igenom det löjliga antal iterationer jag var tvungen att gå igenom för att landa på en tillförlitlig form av den utgången för alla 5 000+ artiklar (vilket översattes till nästan 1 000 inlägg när allt var ihopklistrat). Utöver det behövde jag generera dessa i form av INSERT uttalanden som jag sedan kunde klistra in i phpMyAdmin på WordPress-webbplatsen, vilket innebar att jag skulle följa deras bisarra syntaxdiagram. Dessa uttalanden behövde för att inkludera annan ytterligare information som krävs av WordPress, men som inte finns eller är korrekt i källdata (som post_type ). Och den administratörskonsolen skulle ta slut med för mycket data, så jag var tvungen att dela ut den i ~750 inlägg åt gången. Här är proceduren jag slutade med (detta är egentligen inte att lära sig något specifikt av, bara en demonstration av hur mycket manipulation av den importerade informationen som var nödvändig):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO Utdata från det är inte komplett och inte redo att läggas in i WordPress ännu:
 Exempel på utdata (klicka för att förstora)
Exempel på utdata (klicka för att förstora)
Jag skulle behöva lite extra hjälp från C# för att omvandla det faktiska innehållet (inklusive markdown) till HTML och CSS som jag skulle kunna kontrollera bättre, och skriva utdata (ett gäng INSERT uttalanden som råkade innehålla en massa HTML-kod) till filer på disken som jag kunde öppna och klistra in i phpMyAdmin. För HTML, vanlig text + markdown som började så här:
VÄLJ något från dbo.sometable;
[1]:https://annanstans
Skulle behöva bli detta:
Det finns ett blogginlägg här som talar om det, och även det här inlägget .
VÄLJ något från dbo.sometable; För att få till det här tog jag hjälp av MarkdownSharp, ett bibliotek med öppen källkod som kommer från Stack Overflow som hanterar mycket av konverteringen från markdown-till-HTML. Det passade bra för mina behov, men inte perfekt; Jag skulle fortfarande behöva utföra ytterligare manipulation:
- MarkdownSharp tillåter inte saker som
target=_blank, så jag skulle behöva injicera dem själv efter bearbetning; - kod (allt med prefix med fyra blanksteg) ärver
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Ja, det är ett fult gäng kod, men det fick mig till slut till den uppsättning utdata som inte skulle få phpMyAdmin att spy, och som WordPress skulle presentera snyggt (tillräckligt). Jag ringde helt enkelt C#-programmet flera gånger med de olika parameterintervallen:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Sedan öppnade jag var och en av filerna, klistrade in dem i phpMyAdmin och tryckte på GO:
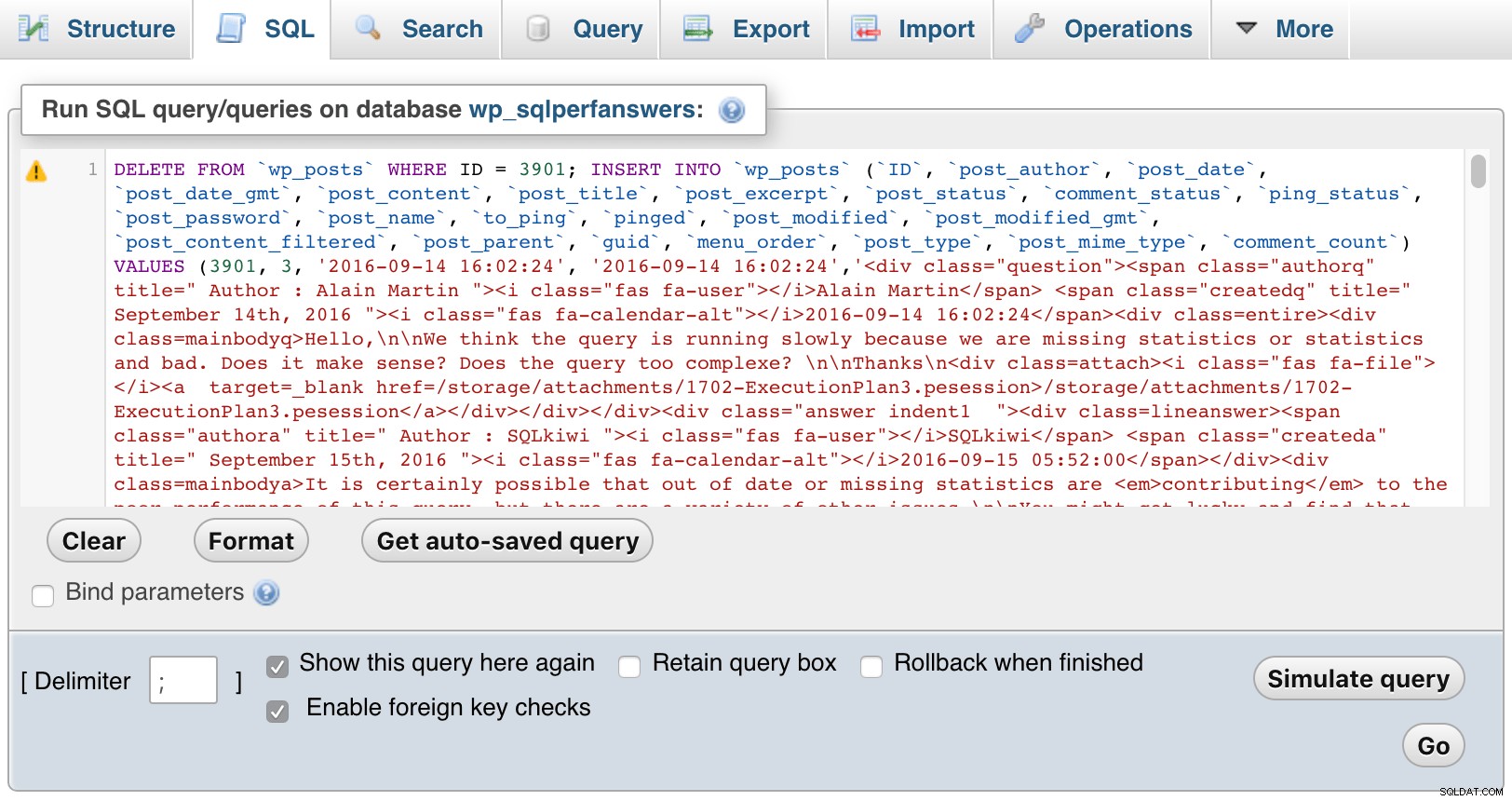 phpMyAdmin (klicka för att förstora)
phpMyAdmin (klicka för att förstora) Naturligtvis var jag tvungen att lägga till lite CSS i WordPress för att hjälpa till att skilja mellan frågor, kommentarer och svar, och för att även indraga kommentarer för att visa svar på både frågor och svar, kapa kommentarer som svarar på kommentarer, och så vidare. Så här ser ett utdrag ut när du går igenom en månads frågor:
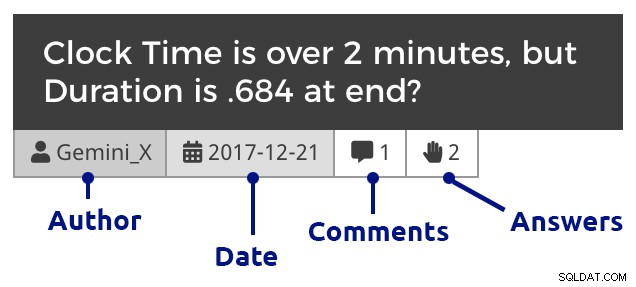 Frågebricka (klicka för att förstora)
Frågebricka (klicka för att förstora) Och sedan ett exempelinlägg som visar inbäddade bilder, flera bilagor, kapslade kommentarer och ett svar:
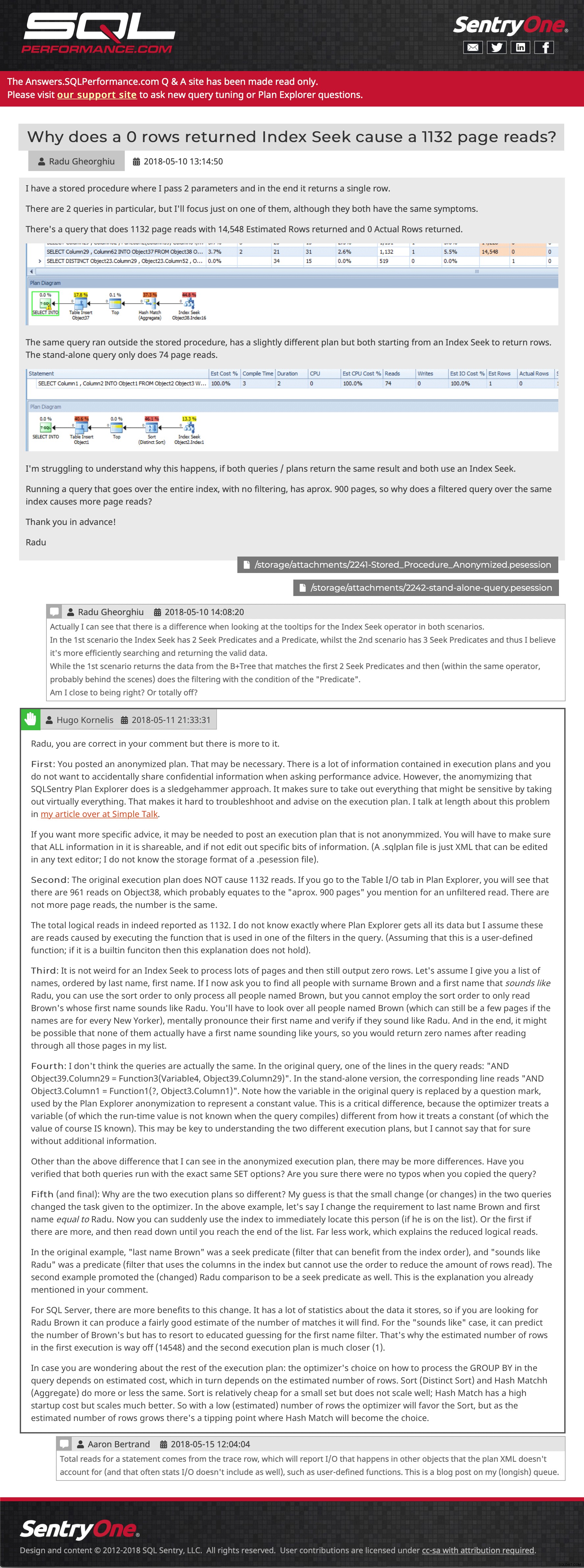 Exempel på fråga och svar (klicka för att gå dit)
Exempel på fråga och svar (klicka för att gå dit) Jag försöker fortfarande återställa några inlägg som skickades till webbplatsen efter att den senaste säkerhetskopian togs, men jag välkomnar dig att surfa runt. Meddela oss om du upptäcker att något saknas eller är fel, eller bara för att berätta att innehållet fortfarande är användbart för dig. Vi hoppas verkligen kunna återinföra planuppladdningsfunktioner från Plan Explorer, men det kommer att kräva lite API-arbete på den nya supportwebbplatsen, så jag har ingen ETA för dig idag.
- Answers.SQLPerformance.com