En av de vanligaste termerna som kommer upp i diskussioner om prestandajustering av SQL Server är väntestatistik . Detta går långt tillbaka i tiden, även före detta Microsoft-dokument från 2006, "SQL Server 2005 Waits and Queues."
Väntan är absolut inte allt, och den här metoden är inte det enda sättet att ställa in en instans, strunt i en individuell fråga. I själva verket är väntan ofta värdelösa när allt du har är frågan som drabbat dem, och inget omgivande sammanhang, särskilt långt efter det. Det beror ganska ofta på att det som en fråga väntar på inte är den frågans fel . Precis som med allt, det finns undantag, men om du väljer ett verktyg eller skript bara för att det erbjuder denna mycket specifika funktionalitet, tror jag att du gör dig själv en björntjänst. Jag brukar följa ett råd som Paul Randal gav mig för en tid sedan:
...vanligtvis rekommenderar jag att man börjar med hela instansväntningar. Jag skulle aldrig starta felsökning genom att titta på individuella frågeväntningar.
Ibland, ja, kanske du vill gräva djupare i en individuell fråga och se vad den väntar på; Faktum är att Microsoft nyligen lade till väntestatistik på frågenivå för att visa plan för att hjälpa till med denna analys. Men dessa siffror kommer vanligtvis inte att hjälpa dig att justera prestandan för din instans som helhet, om de inte hjälper till att peka ut något som råkar också påverka hela din arbetsbelastning. Om du ser en fråga från igår som kördes i 5 minuter och märker att dess väntetyp var LCK_M_S , vad ska du göra åt det nu? Hur ska du spåra vad som faktiskt blockerade frågan och orsakade den väntetypen? Det kan ha orsakats av en transaktion som inte genomfördes av någon annan anledning, men du kan inte se det om du inte kan se tillståndet för hela systemet och bara fokuserar på individuella frågor och väntan de upplevt.
Jason Hall (@SQLSaurus) nämnde något i förbigående som också var intressant för mig. Han sa att om väntestatistik på frågenivå var en så viktig del av inställningsarbetet, skulle denna metod ha varit inbakad i Query Store från början. Det har lagts till nyligen (i SQL Server 2017). Men du får fortfarande inte väntastatistik per körning; du får medelvärden över tid, som frågestatistik och procedurstatistik du ser i DMV. Så plötsliga avvikelser kan vara uppenbara baserat på andra mätvärden som fångas per sökningskörning, men inte baserat på genomsnitt av väntetider som dras över alla avrättningar. Du kan anpassa intervallet som väntar samlas över, men på upptagna system kanske detta fortfarande inte är tillräckligt detaljerat för att göra vad du tror att det kommer att göra för dig.
Poängen med det här inlägget är att diskutera några av de vanligaste väntetyperna vi ser i vår kundbas, och vilken typ av åtgärder du kan (och inte bör) vidta när de inträffar. Vi har en databas med anonym väntestatistik som vi har samlat in från våra Cloud Sync-kunder under ganska lång tid, och sedan maj 2017 har vi visat alla hur dessa ser ut på SQLskills Waits Library.
Paul berättar om anledningen bakom biblioteket och även om vår integration med denna gratistjänst. I grund och botten slår du upp en väntetyp du upplever eller är nyfiken på, och han förklarar vad det betyder och vad du kan göra åt det. Vi kompletterar denna kvalitativa information med ett diagram som visar hur utbredd den nuvarande väntan är bland vår användarbas, jämför den med alla andra väntetyper vi ser, så att du snabbt kan se om du har att göra med en vanlig väntetyp eller något lite mer exotisk. (Kom ihåg att SQL Sentry inte inkluderar godartade väntetider, bakgrunds- och köväntningar som motsvarar brus och att de flesta skript där ute filtreras bort, som WAITFOR eller LAZYWRITER_SLEEP – de här är bara inte källor till prestandaproblem.)
Här är ett exempeldiagram för CXPACKET , den vanligaste väntetypen där ute:
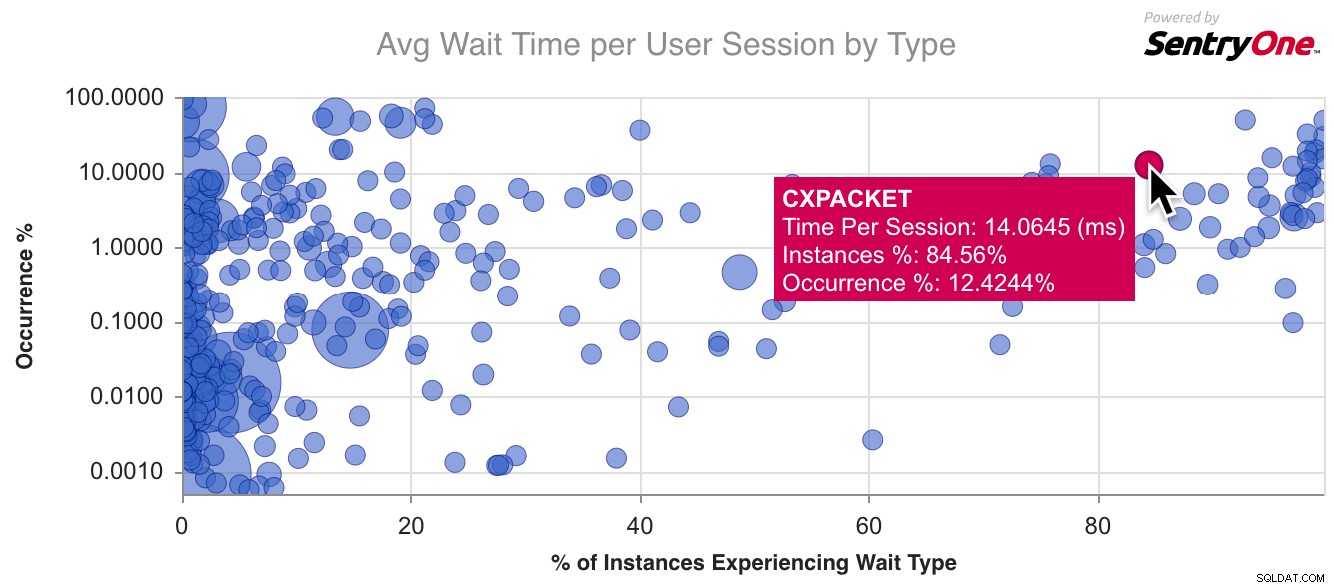
Jag började gå lite längre än så här, kartlade några av de vanligaste väntetyperna och noterade några av egenskaperna de delade. Översatt till frågor som en tuner kan ha om en väntetyp de upplever:
- Kan väntetypen lösas på frågenivå?
- Är det troligt att kärnsymtomet på väntan påverkar andra frågor?
- Är det troligt att du kommer att behöva mer information utanför sammanhanget för en enskild fråga och de väntetyper den upplevde för att "lösa" problemet?
När jag gav mig i kast med att skriva det här inlägget var mitt mål bara att gruppera de vanligaste väntetyperna tillsammans och sedan börja skriva anteckningar om dem angående ovanstående frågor. Jason hämtade de vanligaste från biblioteket och så ritade jag lite kycklingskrapa på en whiteboardtavla som jag senare gjorde i ordning lite. Denna första forskning ledde till ett föredrag som Jason höll på den senaste TechOutbound SQL-kryssningen i Alaska. Jag skäms lite över att han höll ett föredrag månader innan jag kunde avsluta det här inlägget, så låt oss bara fortsätta med det. Här är de vanligaste väntetiderna vi ser (som till stor del matchar Pauls undersökning från 2014), mina svar på ovanstående frågor och några kommentarer till var och en:
Om du vill interagera med länkarna i tabellen nedan, besök den här sidan på en större skärm.
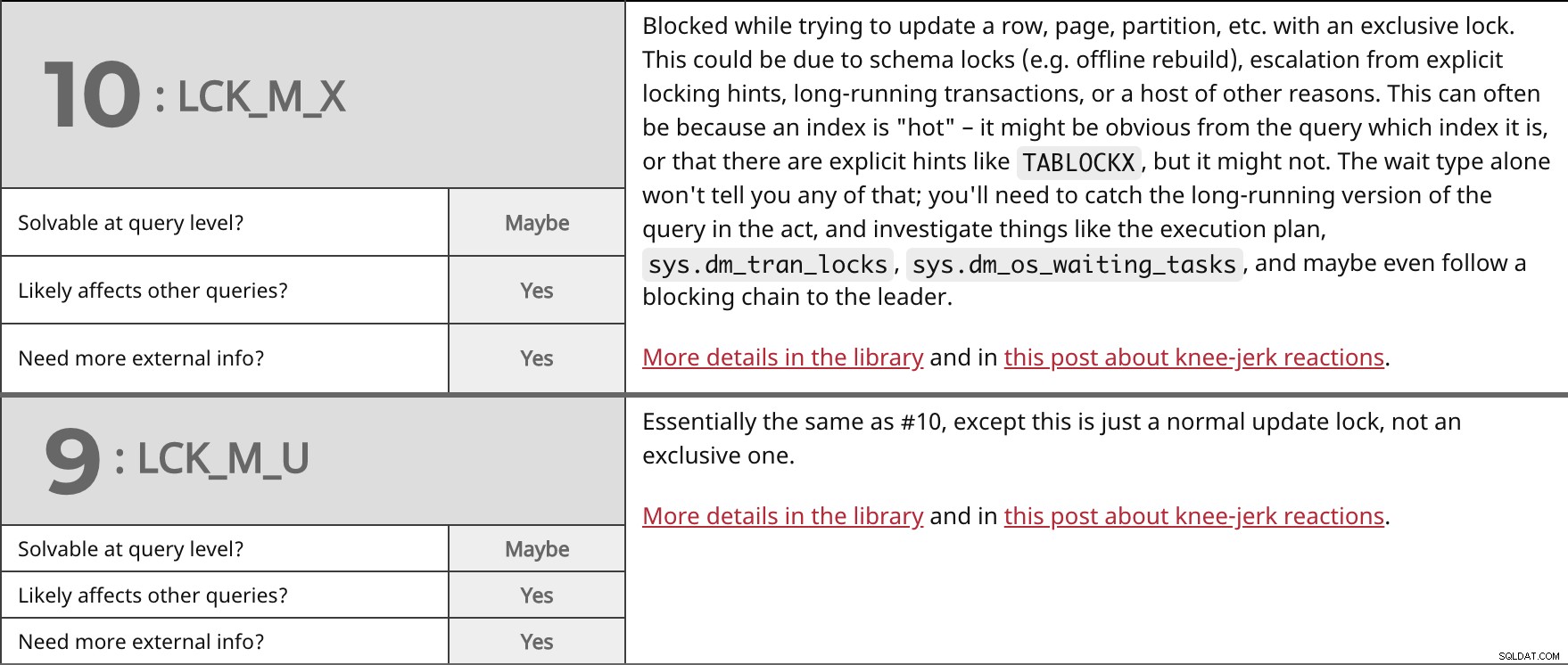
Blockerad vid försök att uppdatera en rad, sida, partition etc. med ett exklusivt lås. Detta kan bero på schemalås (t.ex. ombyggnad offline), eskalering från explicita låstips, långvariga transaktioner eller en mängd andra orsaker. Detta kan ofta bero på att ett index är "hett" – det kan vara uppenbart från frågan vilket index det är, eller att det finns explicita tips som TABLOCKX , men det kanske inte. Väntetypen ensam kommer inte att berätta något om det; du måste fånga den långvariga versionen av frågan på rätt sätt och undersöka saker som exekveringsplanen, sys.dm_tran_locks , sys.dm_os_waiting_tasks , och kanske till och med följa en blockerande kedja till ledaren. Mer information i biblioteket och i det här inlägget om knästötsreaktioner. | ||
| Lösbar på frågenivå? | Kanske | |
| Ja | ||
| Behöver du mer extern information? | Ja | |
|
I huvudsak samma som #10, förutom att detta bara är ett vanligt uppdateringslås, inte ett exklusivt. Mer information i biblioteket och i det här inlägget om knästötsreaktioner. | ||
| Lösbar på frågenivå? | Kanske | |
| Ja | ||
| Behöver du mer extern information? | Ja | |
|
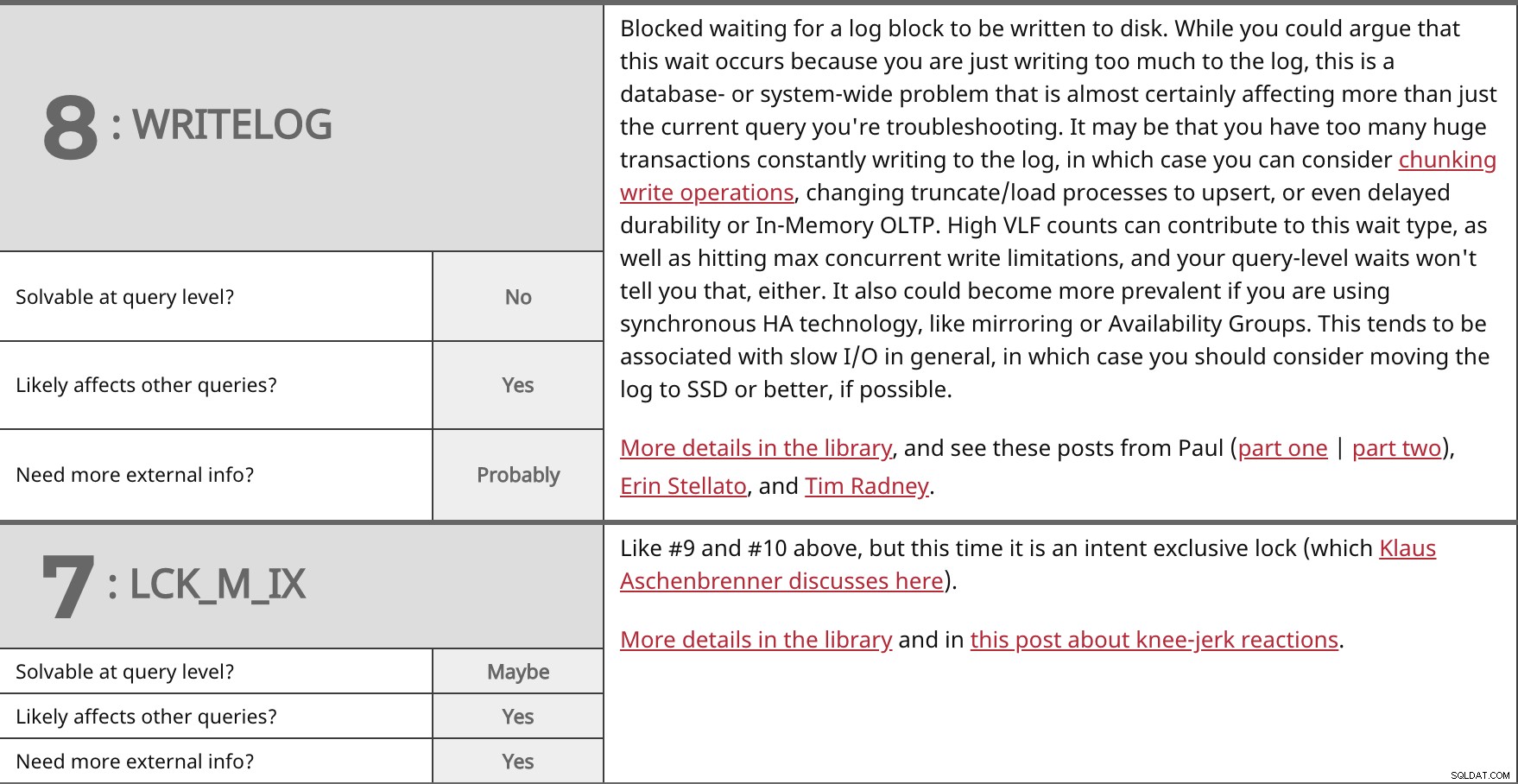
Blockerad väntar på att ett loggblock ska skrivas till disken. Även om du kan hävda att denna väntan uppstår för att du bara skriver för mycket till loggen, är detta ett databas- eller systemomfattande problem som nästan säkert påverkar mer än bara den aktuella frågan du felsöker. Det kan vara så att du har för många enorma transaktioner som ständigt skrivs till loggen, i vilket fall du kan överväga att chunka skrivoperationer, ändra trunkerings-/laddningsprocesser för att rubba, eller till och med fördröjd hållbarhet eller OLTP i minnet. Höga VLF-antal kan bidra till den här väntetypen, såväl som att du når maximala samtidiga skrivbegränsningar, och dina väntetider på frågenivå kommer inte att berätta det heller. Det kan också bli vanligare om du använder synkron HA-teknik, som spegling eller tillgänglighetsgrupper. Detta tenderar att vara förknippat med långsam I/O i allmänhet, i så fall bör du överväga att flytta loggen till SSD eller bättre, om möjligt. Mer information i biblioteket och se dessa inlägg från Paul (del ett | del två), Erin Stellato och Tim Radney. | ||
| Lösbar på frågenivå? | Nej | |
| Ja | ||
| Behöver du mer extern information? | Förmodligen | |
|
Som #9 och #10 ovan, men den här gången är det ett exklusivt lås (som Klaus Aschenbrenner diskuterar här). Mer information i biblioteket och i det här inlägget om knästötsreaktioner. | ||
| Lösbar på frågenivå? | Kanske | |
| Ja | ||
| Behöver du mer extern information? | Ja | |
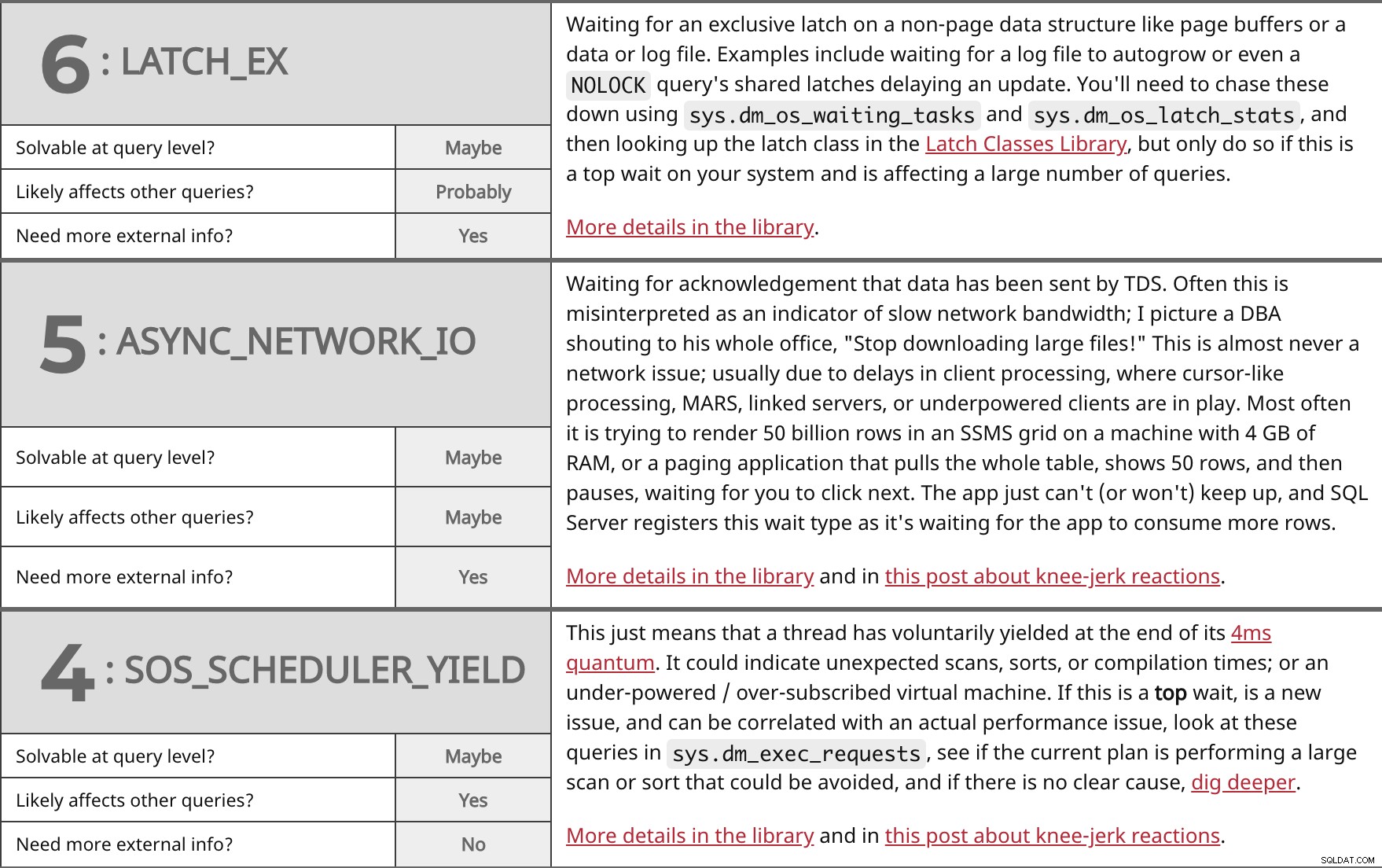
Väntar på en exklusiv spärr på en icke-sidadatastruktur som sidbuffertar eller en data- eller loggfil. Exempel inkluderar att vänta på att en loggfil ska växa automatiskt eller till och med en NOLOCK frågans delade spärrar som fördröjer en uppdatering. Du måste jaga dessa med sys.dm_os_waiting_tasks och sys.dm_os_latch_stats , och leta sedan upp spärrklassen i Latch Classes-biblioteket, men gör det bara om det här är en hög väntan på ditt system och påverkar ett stort antal frågor. Mer information i biblioteket. | ||
| Lösbar på frågenivå? | Kanske | |
| Förmodligen | ||
| Behöver du mer extern information? | Ja | |
|
Väntar på bekräftelse på att data har skickats av TDS. Ofta misstolkas detta som en indikator på långsam nätverksbandbredd; Jag föreställer mig en DBA som ropar till hela hans kontor, "Sluta ladda ner stora filer!" Detta är nästan aldrig ett nätverksproblem; vanligtvis på grund av förseningar i klientbearbetning, där markörliknande bearbetning, MARS, länkade servrar eller underdrivna klienter är i spel. Oftast försöker man rendera 50 miljarder rader i ett SSMS-rutnät på en maskin med 4 GB RAM, eller ett personsökningsprogram som drar hela tabellen, visar 50 rader och sedan pausar och väntar på att du ska klicka på nästa. Appen kan helt enkelt inte (eller kommer inte) att hänga med, och SQL Server registrerar denna väntetyp eftersom den väntar på att appen ska konsumera fler rader. Mer information i biblioteket och i det här inlägget om knästötsreaktioner. | ||
| Lösbar på frågenivå? | Kanske | |
| Kanske | ||
| Behöver du mer extern information? | Ja | |
Detta betyder bara att en tråd frivilligt har gett efter i slutet av sitt 4ms-kvantum. Det kan indikera oväntade skanningar, sorteringar eller kompileringstider; eller en underdriven/överprenumererad virtuell maskin. Om detta är en topp vänta, är ett nytt problem och kan korreleras med ett verkligt prestandaproblem, titta på dessa frågor i sys.dm_exec_requests , se om den aktuella planen utför en stor skanning eller sortering som skulle kunna undvikas, och om det inte finns någon tydlig orsak, gräv djupare. Mer information i biblioteket och i det här inlägget om knästötsreaktioner. | ||
| Lösbar på frågenivå? | Kanske | |
| Ja | ||
| Behöver du mer extern information? | Nej | |
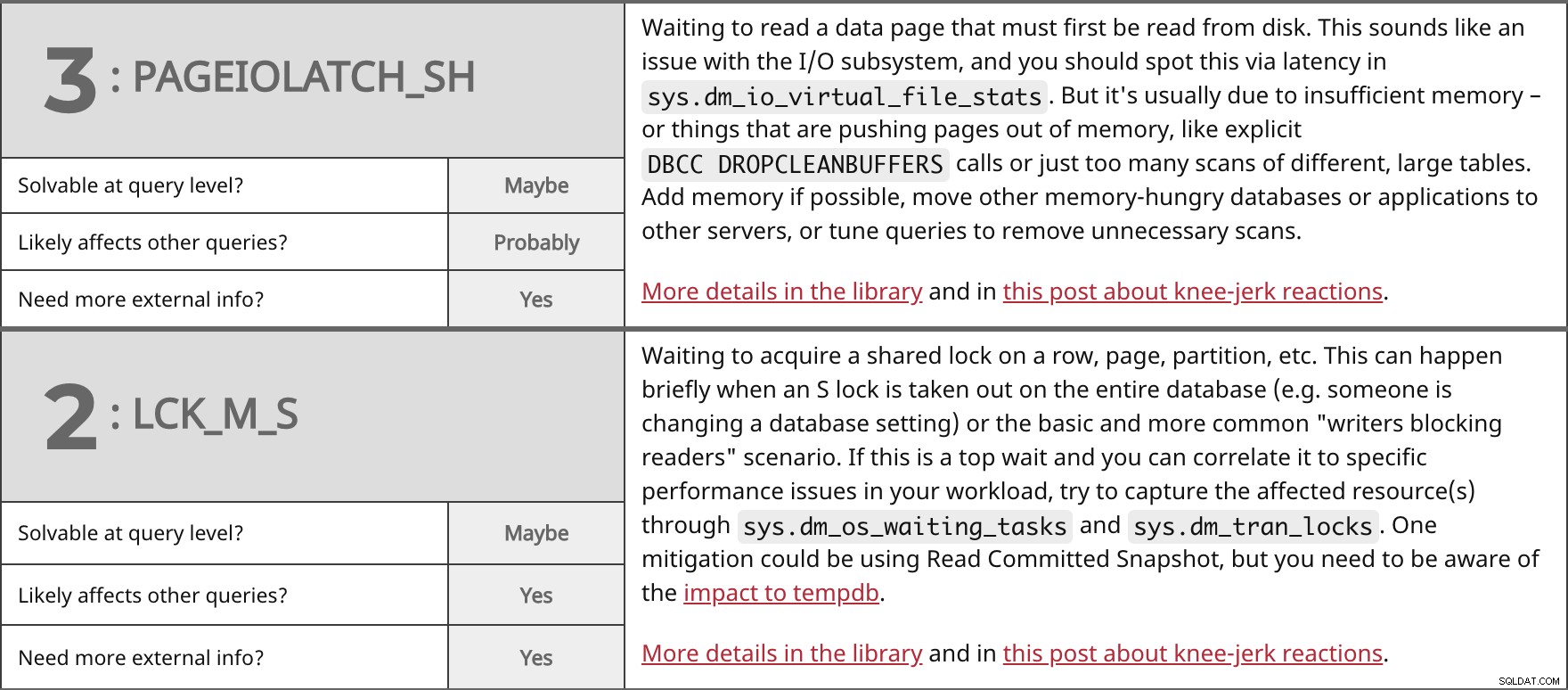
Väntar på att läsa en datasida som först måste läsas från disken. Det här låter som ett problem med I/O-undersystemet, och du bör upptäcka detta via latens i sys.dm_io_virtual_file_stats . Men det beror vanligtvis på otillräckligt minne – eller saker som pressar sidor ur minnet, som explicita DBCC DROPCLEANBUFFERS samtal eller bara för många skanningar av olika, stora tabeller. Lägg till minne om möjligt, flytta andra minneshungriga databaser eller applikationer till andra servrar, eller justera frågor för att ta bort onödiga skanningar. Mer information i biblioteket och i det här inlägget om knästötsreaktioner. | ||
| Lösbar på frågenivå? | Kanske | |
| Förmodligen | ||
| Behöver du mer extern information? | Ja | |
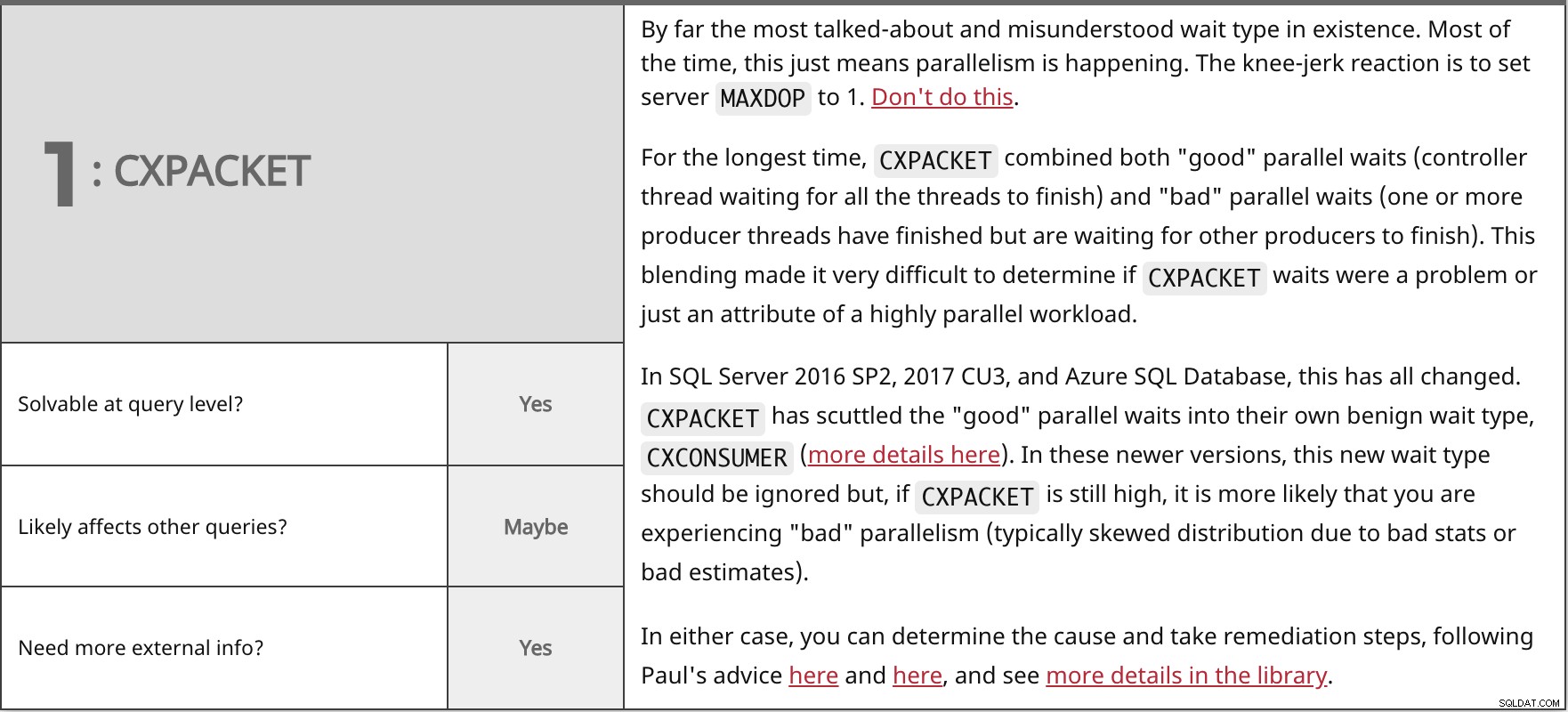
Väntar på att skaffa ett delat lås på en rad, sida, partition, etc. Detta kan inträffa kortvarigt när ett S-lås tas ut på hela databasen (t.ex. någon ändrar sig en databasinställning) eller det grundläggande och vanligare scenariot "författare som blockerar läsare". Om detta är en toppväntning och du kan relatera det till specifika prestandaproblem i din arbetsbelastning, försök att fånga de berörda resurserna genom sys.dm_os_waiting_tasks och sys.dm_tran_locks . En begränsning kan vara att använda Read Committed Snapshot, men du måste vara medveten om effekten av tempdb. Mer information i biblioteket och i det här inlägget om knästötsreaktioner. | ||
| Lösbar på frågenivå? | Kanske | |
| Ja | ||
| Behöver du mer extern information? | Ja | |
Överlägset den mest omtalade och missförstådda väntetypen som finns. För det mesta betyder detta bara att parallellism sker. Reaktionen är att ställa in servern MAXDOP till 1. Gör inte detta.
Under den längsta tiden,
I SQL Server 2016 SP2, 2017 CU3 och Azure SQL Database har allt detta förändrats. I båda fallen kan du fastställa orsaken och vidta åtgärder för att åtgärda, följa Pauls råd här och här, och se mer information i biblioteket. | ||
| Lösbar på frågenivå? | Ja | |
| Kanske | ||
| Behöver du mer extern information? | Ja | |
Sammanfattning
I de flesta av dessa fall är det bättre att titta på väntetider på instansnivå och bara finslipa på väntetider på frågenivå när du felsöker specifika frågor som uppvisar prestandaproblem oavsett väntetyp. Det här är saker som dyker upp av andra skäl, som lång varaktighet, hög CPU eller hög I/O, och som inte kan förklaras av enklare saker (som en klustrad indexskanning när du väntade en sökning).
Inte ens på instansnivå, jaga ner varje väntan som blir den bästa väntan på ditt system – du kommer ALLTID ha en hög väntan, och du kommer aldrig att kunna sluta jaga den. Se till att du ignorerar godartade väntan (Paul håller en lista) och bara oroa dig för väntan som du kan associera med ett verkligt prestationsproblem som du upplever. Om CXPACKET väntan är långa, så vad? Finns det några andra symtom förutom att siffran är "hög" eller råkar stå överst på listan?
Allt beror på varför du felsöker i första hand. Klager en enskild användare över en enda instans av en oseriös fråga? Är din server på knä? Något mitt emellan? I det första fallet, visst, kan det vara användbart att veta varför en fråga är långsam, men det är ganska dyrt att spåra (strålar inte med på obestämd tid) alla väntan som är förknippade med varje enskild fråga, hela dagen, varje dag, vid en udda chans att du vill komma tillbaka och granska dem senare. Om det är ett genomgripande problem isolerat till den frågan, bör du kunna avgöra vad som gör den frågan långsam genom att köra den igen och samla in exekveringsplanen, kompileringstid och andra körtidsmått. Om det var en engångsgrej som hände i tisdags, oavsett om du har väntan på den enda instansen av frågan eller inte, kanske du inte kan lösa problemet utan mer sammanhang. Kanske fanns det en blockering, men du kommer inte att veta av vad, eller kanske det fanns en I/O-spik, men du måste spåra upp problemet separat. Väntetypen i sig ger vanligtvis inte tillräckligt med information förutom i bästa fall en pekare till något annat.
Naturligtvis måste jag tjäna mitt liv här också. Vår flaggskeppsprodukt, SQL Sentry, har ett holistiskt synsätt på övervakning. Vi samlar in instansomfattande väntestatistik, kategoriserar dem åt dig och ritar upp dem på vår instrumentpanel:
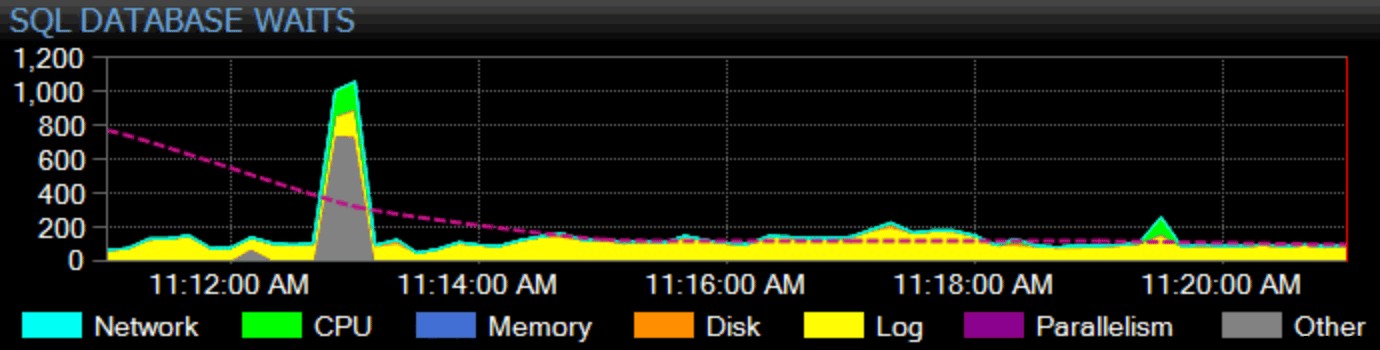
Du kan anpassa hur varje enskild väntetid kategoriseras och om den kategorin ens dyker upp på instrumentpanelen eller inte. Du kan jämföra den aktuella väntestatistiken med inbyggda eller anpassade baslinjer och till och med ställa in varningar eller åtgärder när de överskrider en viss definierad avvikelse från baslinjen. Och, kanske viktigast av allt, du kan titta på en datapunkt från det förflutna och synkronisera hela instrumentpanelen till den tidpunkten, så att du kan fånga hela det omgivande sammanhanget och alla andra situationer som kan ha påverkat problemet. När du hittar mer detaljerade saker att fokusera på, som blockering, hög disklatens eller frågor med hög I/O eller lång varaktighet, kan du borra i dessa mätvärden och komma till roten till problemet ganska snabbt.
För mer information om både allmän väntestatistik och vår lösning specifikt, kan du titta på Kevin Klines white paper, Troubleshooting SQL Server Wait Stats, och du kan ladda ner ett tvådelat webbseminarium presenterat av Paul Randal, Andy Yun (@SQLBek), och Andy Mallon (@AMtwo):
- Del 1:Prestandafelsökning med hjälp av väntestatistik
- Del 2:Snabb analys av väntestatistik med SentryOne
Och om du vill ge SentryOne-plattformen en snurr kan du komma igång här med ett tidsbegränsat erbjudande:
Ladda ner en 15-dagars gratis provperiod