Uppgifter med luckor och öar är klassiska frågeutmaningar där du måste identifiera intervall av saknade värden och intervall av befintliga värden i en sekvens. Sekvensen är ofta baserad på något datum, eller datum- och tidsvärden, som normalt ska visas med jämna mellanrum, men vissa poster saknas. Uppgiften luckor letar efter de saknade perioderna och öuppgiften letar efter de befintliga perioderna. Jag täckte många lösningar på luckor och öuppgifter i mina böcker och artiklar tidigare. Nyligen presenterades jag för en ny speciell ö-utmaning av min vän, Adam Machanic, och att lösa den krävde lite kreativitet. I den här artikeln presenterar jag utmaningen och lösningen jag kom fram till.
Utmaningen
I din databas håller du reda på tjänster ditt företag stödjer i en tabell som heter CompanyServices, och varje tjänst rapporterar normalt ungefär en gång i minuten att den är online i en tabell som heter EventLog. Följande kod skapar dessa tabeller och fyller dem med små uppsättningar exempeldata:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
EventLog-tabellen är för närvarande fylld med följande data:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Den speciella ö-uppgiften är att identifiera tillgänglighetsperioderna (service, starttid, sluttid). En hake är att det inte finns någon garanti för att en tjänst kommer att rapportera att den är online exakt varje minut; du ska tolerera ett intervall på upp till, till exempel, 66 sekunder från föregående loggpost och fortfarande betrakta det som en del av samma tillgänglighetsperiod (ö). Efter 66 sekunder startar den nya loggposten en ny tillgänglighetsperiod. Så för indataexemplet ovan, är din lösning tänkt att returnera följande resultatuppsättning (inte nödvändigtvis i denna ordning):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Lägg till exempel märke till hur loggpost 5 startar en ny ö eftersom intervallet från föregående loggpost är 120 sekunder (> 66), medan loggpost 6 inte startar en ny ö eftersom intervallet från föregående post är 62 sekunder ( <=66). En annan hake är att Adam ville att lösningen skulle vara kompatibel med pre-SQL Server 2012-miljöer, vilket gör det till en mycket svårare utmaning, eftersom du inte kan använda fönsteraggregationsfunktioner med en ram för att beräkna löpande totaler och offsetfönsterfunktioner som LAG och LEAD. Som vanligt föreslår jag att du försöker lösa utmaningen själv innan du tittar på mina lösningar. Använd de små uppsättningarna med exempeldata för att kontrollera giltigheten av dina lösningar. Använd följande kod för att fylla i dina tabeller med stora uppsättningar exempeldata (500 tjänster, ~10 miljoner loggposter för att testa prestanda för dina lösningar):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; De utdata som jag kommer att tillhandahålla för stegen i mina lösningar kommer att anta de små uppsättningarna av exempeldata, och prestandatalen som jag kommer att tillhandahålla kommer att anta de stora uppsättningarna.
Alla lösningar som jag kommer att presentera drar nytta av följande index:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Lycka till!
Lösning 1 för SQL Server 2012+
Innan jag tar upp en lösning som är kompatibel med pre-SQL Server 2012-miljöer, kommer jag att täcka en som kräver minst SQL Server 2012. Jag kallar den lösning 1.
Det första steget i lösningen är att beräkna en flagga som kallas isstart som är 0 om händelsen inte startar en ny ö, och 1 annars. Detta kan uppnås genom att använda LAG-funktionen för att erhålla loggtiden för föregående händelse och kontrollera om tidsskillnaden i sekunder mellan föregående och aktuella händelser är mindre än eller lika med det tillåtna gapet. Här är koden som implementerar detta steg:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Denna kod genererar följande utdata:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Därefter producerar en enkel löpande summa av isstart-flaggan en ö-identifierare (jag kallar det grp). Här är koden som implementerar detta steg:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Denna kod genererar följande utdata:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Slutligen grupperar du raderna efter tjänst-ID och ö-identifierare och returnerar minsta och maximala loggtider som starttid och sluttid för varje ö. Här är den kompletta lösningen:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Den här lösningen tog 41 sekunder att slutföra på mitt system och producerade planen som visas i figur 1.
 Figur 1:Plan för lösning 1
Figur 1:Plan för lösning 1
Som du kan se beräknas båda fönsterfunktionerna baserat på indexordning, utan behov av explicit sortering.
Om du använder SQL Server 2016 eller senare, kan du använda tricket jag tar upp här för att aktivera batchläget Window Aggregate-operator genom att skapa ett tomt filtrerat kolumnlagerindex, som så:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Samma lösning tar nu bara 5 sekunder att slutföra på mitt system, vilket ger planen som visas i figur 2.
 Figur 2:Planera för lösning 1 med batchläget Window Aggregate-operator
Figur 2:Planera för lösning 1 med batchläget Window Aggregate-operator
Det här är bra, men som nämnt letade Adam efter en lösning som kan köras i miljöer före 2012.
Innan du fortsätter, se till att du släpper columnstore-indexet för rensning:
DROP INDEX idx_cs ON dbo.EventLog;
Lösning 2 för pre-SQL Server 2012-miljöer
Tyvärr, före SQL Server 2012, hade vi inte stöd för offset-fönsterfunktioner som LAG, och vi hade inte heller stöd för att beräkna löpande totaler med fönsteraggregatfunktioner med en ram. Det betyder att du måste arbeta mycket hårdare för att komma fram till en rimlig lösning.
Tricket jag använde är att förvandla varje loggpost till ett konstgjort intervall vars starttid är postens loggtid och vars sluttid är postens loggtid plus det tillåtna gapet. Du kan sedan behandla uppgiften som en klassisk intervallpackningsuppgift.
Det första steget i lösningen beräknar de artificiella intervallavgränsarna och radnummer som markerar positionerna för var och en av händelsetyperna (counteach). Här är koden som implementerar detta steg:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Denna kod genererar följande utdata:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Nästa steg är att koppla upp intervallen till en kronologisk sekvens av start- och sluthändelser, identifierade som händelsetyperna 's' respektive 'e'. Observera att valet av bokstäverna s och e är viktigt ('s' > 'e' ). Detta steg beräknar radnummer som markerar den korrekta kronologiska ordningen för båda händelsetyperna, som nu är sammanflätade (räkna båda). Om ett intervall slutar exakt där ett annat börjar, genom att placera startevenemanget före slutevenemanget, packar du ihop dem. Här är koden som implementerar detta steg:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Denna kod genererar följande utdata:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Som nämnts markerar counteach händelsens position bland endast händelser av samma slag, och counteach markerar händelsens position bland de kombinerade, interfolierade händelserna av båda slagen.
Magin hanteras sedan av nästa steg – att beräkna antalet aktiva intervall efter varje händelse baserat på counteach och countboth. Antalet aktiva intervall är antalet starthändelser som hänt hittills minus antalet sluthändelser som hänt hittills. För starthändelser berättar counteach hur många starthändelser som har hänt hittills, och du kan räkna ut hur många som slutat hittills genom att subtrahera counteach från counteach. Så, det fullständiga uttrycket som talar om hur många intervall som är aktiva är då:
counteach - (countboth - counteach)
För sluthändelser berättar counteach hur många sluthändelser som har hänt hittills, och du kan räkna ut hur många som har börjat hittills genom att subtrahera counteach från counteach. Så, det fullständiga uttrycket som talar om hur många intervall som är aktiva är då:
(countboth - counteach) - counteach
Med hjälp av följande CASE-uttryck beräknar du den räknande kolumnen baserat på händelsetypen:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END I samma steg filtrerar du bara händelser som representerar start och slut på packade intervall. Starter av packade intervall har en typ 's' och en countactive 1. Slutar på packade intervall har en typ 'e' och en countactive 0.
Efter filtrering har du ett par start-sluthändelser med packade intervaller, men varje par är uppdelat i två rader – en för starthändelsen och en annan för sluthändelsen. Därför beräknar samma steg paridentifierare genom att använda radnummer, med formeln (rownum – 1) / 2 + 1.
Här är koden som implementerar detta steg:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Denna kod genererar följande utdata:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Det sista steget svänger händelseparen till en rad per intervall och subtraherar det tillåtna gapet från sluttiden för att återskapa den korrekta händelsetiden. Här är den fullständiga lösningens kod:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Den här lösningen tog 43 sekunder att slutföra på mitt system och genererade planen som visas i figur 3.
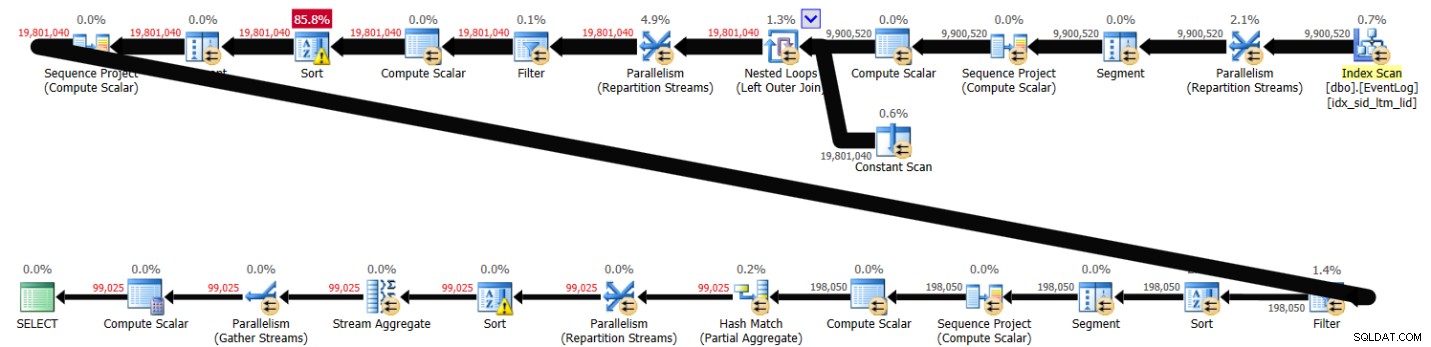 Figur 3:Plan för lösning 2
Figur 3:Plan för lösning 2
Som du kan se beräknas den första radnummerberäkningen baserat på indexordning, men de nästa två involverar explicit sortering. Ändå är prestandan inte så dålig med tanke på att det är cirka 10 000 000 rader inblandade.
Även om poängen med den här lösningen är att använda en pre-SQL Server 2012-miljö, bara för skojs skull, testade jag dess prestanda efter att ha skapat ett filtrerat kolumnlagerindex för att se hur det går med batchbearbetning aktiverad:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Med batchbearbetning aktiverad tog den här lösningen 29 sekunder att slutföra på mitt system, vilket producerade planen som visas i figur 4.
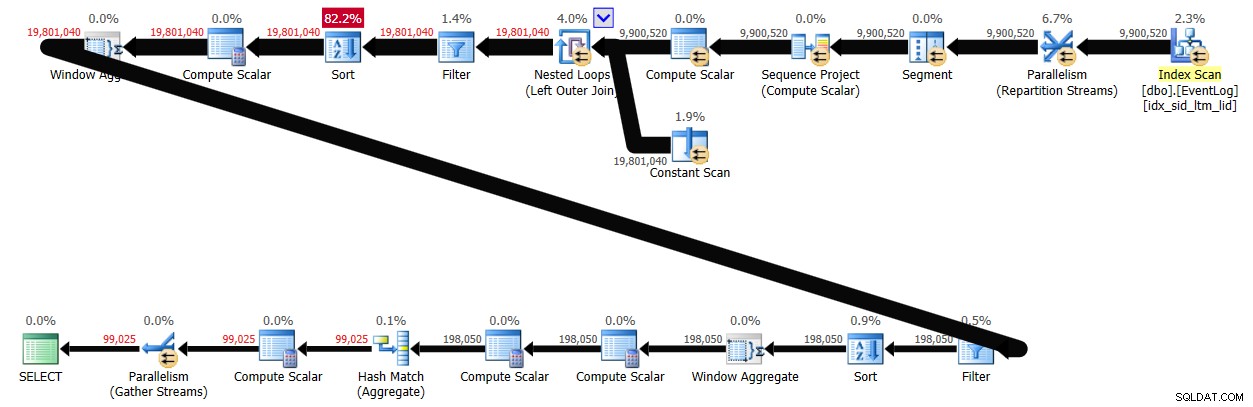
Slutsats
Det är naturligt att ju mer begränsad din miljö är, desto mer utmanande blir det att lösa frågeuppgifter. Adams speciella Islands-utmaning är mycket lättare att lösa på nyare versioner av SQL Server än på äldre. Men sedan tvingar du dig själv att använda mer kreativa tekniker. Så som en övning, för att förbättra dina frågefärdigheter, kan du ta itu med utmaningar som du redan är bekant med, men avsiktligt införa vissa begränsningar. Du vet aldrig vilka typer av intressanta idéer du kan snubbla in i!