När man tittar på frågeprestanda finns det många bra informationskällor inom SQL Server, och en av mina favoriter är själva frågeplanen. I de senaste utgåvorna, särskilt med början med SQL Server 2012, har varje ny version inkluderat mer detaljer i exekveringsplanerna. Medan listan över förbättringar fortsätter att växa, är här några attribut som jag har funnit värdefulla:
- NonParallelPlanReason (SQL Server 2012)
- Resterande predikat pushdown-diagnostik (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- tempdb spilldiagnostik (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Spårningsflaggor aktiverade (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Statistik för utförande av operatörsfrågor (SQL Server 2014 SP2, SQL Server 2016)
- Maximalt minne aktiverat för en enda fråga (SQL Server 2014 SP2, SQL Server 2016 SP1)
För att se vad som finns för varje version av SQL Server, besök sidan Showplan Schema, där du kan hitta schemat för varje version sedan SQL Server 2005.
Så mycket som jag älskar all denna extra data, är det viktigt att notera att viss information är mer relevant för en verklig utförandeplan, jämfört med en uppskattad sådan (t.ex. tempdb spillinformation). Vissa dagar kan vi fånga och använda den faktiska planen för felsökning, andra gånger måste vi använda den beräknade planen. Mycket ofta får vi den uppskattade planen – planen som har använts för problematiska exekveringar potentiellt – från SQL Servers plancache. Och att dra individuella planer är lämpligt när du ställer in en specifik fråga eller uppsättning eller frågor. Men hur är det när du vill ha idéer om var du ska fokusera dina inställningsinsatser när det gäller mönster?
SQL Server-planens cache är en fantastisk källa till information när det gäller prestandajustering, och jag menar inte bara felsökning och försök att förstå vad som har körts i ett system. I det här fallet talar jag om att bryta information från själva planerna, som finns i sys.dm_exec_query_plan, lagrade som XML i kolumnen query_plan.
När du kombinerar denna data med information från sys.dm_exec_sql_text (så att du enkelt kan se texten i frågan) och sys.dm_exec_query_stats (exekveringsstatistik), kan du plötsligt börja leta efter inte bara de frågorna som är de tunga träffarna eller exekvera oftast, men de planer som innehåller en viss anslutningstyp, eller indexskanning, eller de som har den högsta kostnaden. Detta kallas vanligen för mining av plancachen, och det finns flera blogginlägg som talar om hur man gör detta. Min kollega, Jonathan Kehayias, säger att han hatar att skriva XML men han har flera inlägg med frågor för att bryta plancachen:
- Justera 'kostnadströskel för parallellism' från plancachen
- Hitta implicita kolumnkonverteringar i plancachen
- Hitta vilka frågor i planens cache som använder ett specifikt index
- Gräva in i SQL Plan Cache:Hitta saknade index
- Hitta nyckeluppslag i plancachen
Om du aldrig har utforskat vad som finns i din plancache, är frågorna i dessa inlägg en bra början. Planens cache har dock sina begränsningar. Det är till exempel möjligt att köra en fråga och inte låta planen gå in i cachen. Om du t.ex. har aktiverat alternativet Optimera för adhoc-arbetsbelastningar, lagras den kompilerade planstubben i planens cache vid första exekvering, inte den fullständiga kompilerade planen. Men den största utmaningen är att plancachen är tillfällig. Det finns många händelser i SQL Server som kan rensa planens cache helt eller rensa den för en databas, och planer kan åldras ur cachen om de inte används, eller tas bort efter en omkompilering. För att bekämpa detta måste du vanligtvis antingen fråga i planens cache regelbundet eller en ögonblicksbild av innehållet i en tabell på en schemalagd basis.
Detta ändras i SQL Server 2016 med Query Store.
När en användardatabas har Query Store aktiverat, fångas texten och planerna för frågor som körs mot den databasen och bevaras i interna tabeller. Snarare än en tillfällig syn på vad som för närvarande utförs, har vi en långsiktig bild av vad som tidigare har utförts. Mängden data som lagras bestäms av inställningen CLEANUP_POLICY, som är standard på 30 dagar. Jämfört med en plancache som kan representera bara några timmars frågekörning, är Query Store-data en spelförändring.
Tänk på ett scenario där du gör lite indexanalys – du har några index som inte används och du har några rekommendationer från de saknade index-DMV:erna. De saknade index-DMV:erna ger inga detaljer om vilken fråga som genererade den saknade indexrekommendationen. Du kan fråga i planens cache med hjälp av frågan från Jonathans inlägg Finding Missing Indexes. Om jag kör det mot min lokala SQL Server-instans får jag ett par rader med utdata relaterade till några frågor jag körde tidigare.

Jag kan öppna planen i Plan Explorer, och jag ser att det finns en varning på SELECT-operatören, som är för det saknade indexet:
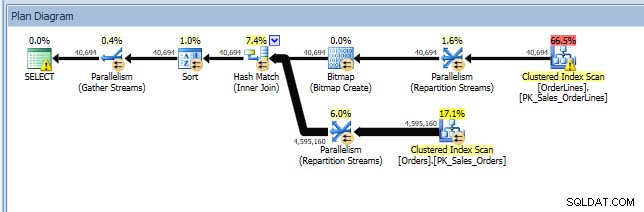
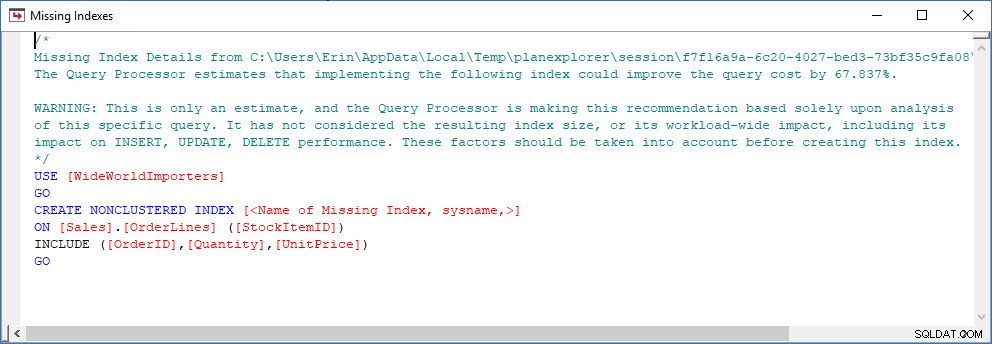
Det här är en bra början, men återigen, min produktion beror på vad som än finns i cachen. Jag kan ta Jonathans fråga och ändra för Query Store och sedan köra den mot min demo WideWorldImporters-databas:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
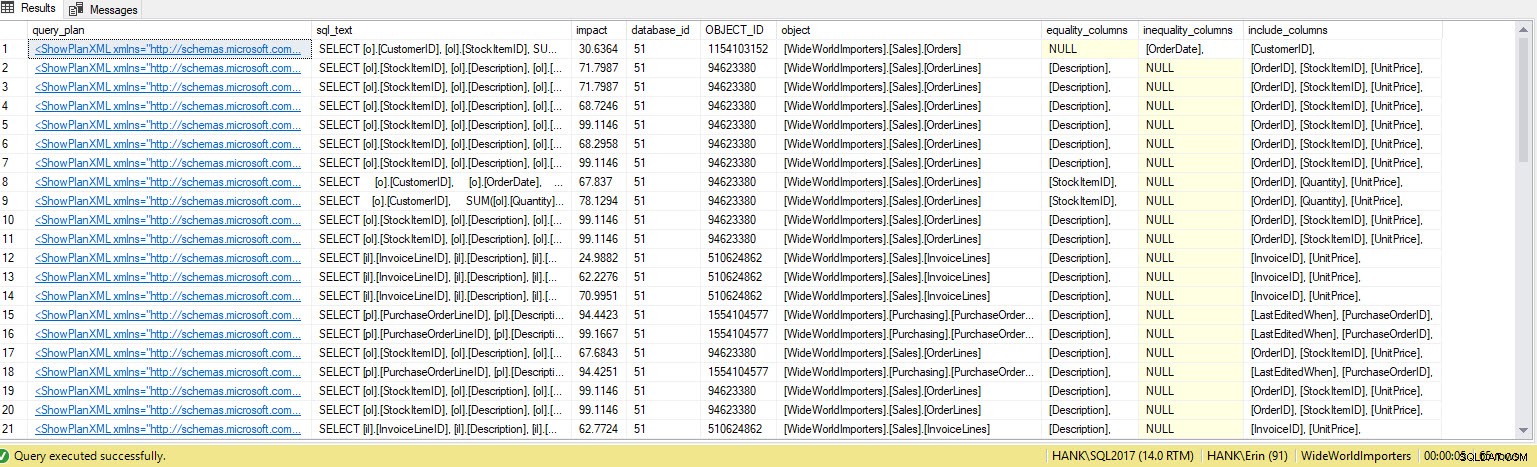
Jag får många fler rader i utgången. Återigen representerar Query Store-data en större vy av frågor som körs mot systemet, och att använda dessa data ger oss en heltäckande metod för att avgöra inte bara vilka index som saknas, utan även vilka frågor dessa index skulle stödja. Härifrån kan vi gräva djupare in i Query Store och titta på prestandamått och exekveringsfrekvens för att förstå effekten av att skapa indexet och avgöra om frågan körs tillräckligt ofta för att motivera indexet.
Om du inte använder Query Store, men du använder SentryOne, kan du hämta samma information från SentryOne-databasen. Frågeplanen lagras i tabellen dbo.PerformanceAnalysisPlan i ett komprimerat format, så frågan vi använder är en liknande variant som den ovan, men du kommer att märka att DECOMPRESS-funktionen också används:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; På ett SentryOne-system hade jag följande utdata (och naturligtvis öppnas den grafiska planen genom att klicka på något av query_plan-värdena):

Ett par fördelar SentryOne erbjuder jämfört med Query Store är att du inte behöver aktivera den här typen av insamling per databas, och den övervakade databasen behöver inte stödja lagringskraven, eftersom all data lagras i förvaret. Du kan också fånga denna information i alla versioner av SQL Server som stöds, inte bara de som stöder Query Store. Observera dock att SentryOne bara samlar in frågor som överskrider tröskelvärden såsom varaktighet och läsningar. Du kan justera dessa standardtrösklar, men det är ett objekt att vara medveten om när du bryter SentryOne-databasen:alla frågor kanske inte samlas in. Dessutom är funktionen DEKOMPRESSA inte tillgänglig förrän SQL Server 2016; för äldre versioner av SQL Server vill du antingen:
- Säkerhetskopiera SentryOne-databasen och återställ den på SQL Server 2016 eller högre för att köra frågorna;
- bcp data från tabellen dbo.PerformanceAnalysisPlan och importera den till en ny tabell på en SQL Server 2016-instans;
- fråga SentryOne-databasen via en länkad server från en SQL Server 2016-instans; eller,
- fråga databasen från applikationskoden som kan analysera för specifika saker efter dekomprimering.
Med SentryOne har du möjligheten att bryta inte bara plancachen, utan även data som lagras i SentryOne-förvaret. Om du kör SQL Server 2016 eller senare och du har aktiverat Query Store, kan du även hitta denna information i sys.query_store_plan . Du är inte begränsad till bara detta exempel på att hitta saknade index; alla frågor från Jonathans andra plancache-inlägg kan modifieras för att användas för att bryta data från SentryOne eller från Query Store. Vidare, om du är tillräckligt bekant med XQuery (eller villig att lära), kan du använda Showplan Schema för att ta reda på hur du analyserar planen för att hitta den information du vill ha. Detta ger dig möjligheten att hitta mönster och antimönster i dina frågeplaner som ditt team kan fixa innan de blir ett problem.