Att organisera barnkalas är inte ett lätt jobb:allt måste planeras och levereras perfekt. Annars uppstår kaos. Det är upp till de vuxna – närmare bestämt festplanerarna – att ta hand om allt och göra det ordentligt.
Finns det ett bättre sätt att göra detta än att organisera allt i en databas? Vi tror inte det!
Barnkalasen varierar mycket. Vissa är enkla, som födelsedagsfester som bara inkluderar inbjudningar, mat (snacks, drycker och en tårta) och kanske en clown eller en magiker för att underhålla barnen. Andra partier är mycket mer komplexa. De kan behöva en resa utanför stan, sovplatser och många andra aktiviteter. Ju mer komplicerat festen är, desto mindre utrymme för misstag. Även om en clown som är 10 minuter försenad inte är en stor sak, vill ingen vänta med en grupp uttråkade barn på en buss som är två timmar försenad!
Låt oss se vad en datamodell kan göra för att hjälpa festplanerare att hålla ordning.
Vad behöver vi i vår datamodell?
Låt oss anta att vi driver en festplaneringsverksamhet. Vi kommer att ha en lista över tjänster som vi erbjuder kunder. Dessa tjänster kan tillhandahållas av oss, eller så kan vi använda partners (t.ex. vi anlitar clownen).
Vi kombinerar dessa tjänster och erbjuder dem till kunderna som ett festpaket. Varje paket har en start- och slutpunkt eller ett schema. Detta inkluderar inte bara själva festen, utan att sätta upp festen och städa upp efteråt. Vi kan också ha flera platser (t.ex. en fest börjar med pizza på en restaurang och flyttar sedan till stranden för att bada).
Vi kommer också att behöva relatera aktiviteter till anställda, spåra festernas framsteg och ta betalt för våra tjänster. Låt oss se hur detta görs.
Datamodellen för barnfester
Vår datamodell för barnfester består av fyra ämnesområden:
Countries & citiesPartners & servicesEmployees & rolesParty
Vi kommer att presentera varje ämnesområde i samma ordning som det är listat.
Avsnitt 1:Länder och städer
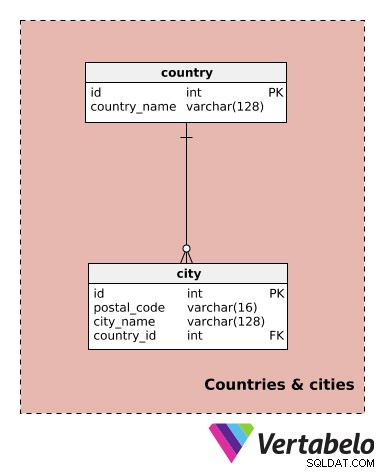
Detta ämnesområde innehåller endast två tabeller. De är inte specifika för den här modellen, men vi kommer att använda dem i andra ämnesområden.
Vi kan förvänta oss att verka i flera städer och kanske till och med i flera länder. Därför måste vi referera till olika städer. Detta kommer att hjälpa oss att spåra var parterna finns och även vilka tjänster vi erbjuder på varje plats.
country ordboken innehåller endast det UNIKA country_name värde. För varje city , lagrar vi den UNIKA kombinationen av postal_code – city_name – country_id .
Avsnitt 2:Partners och tjänster
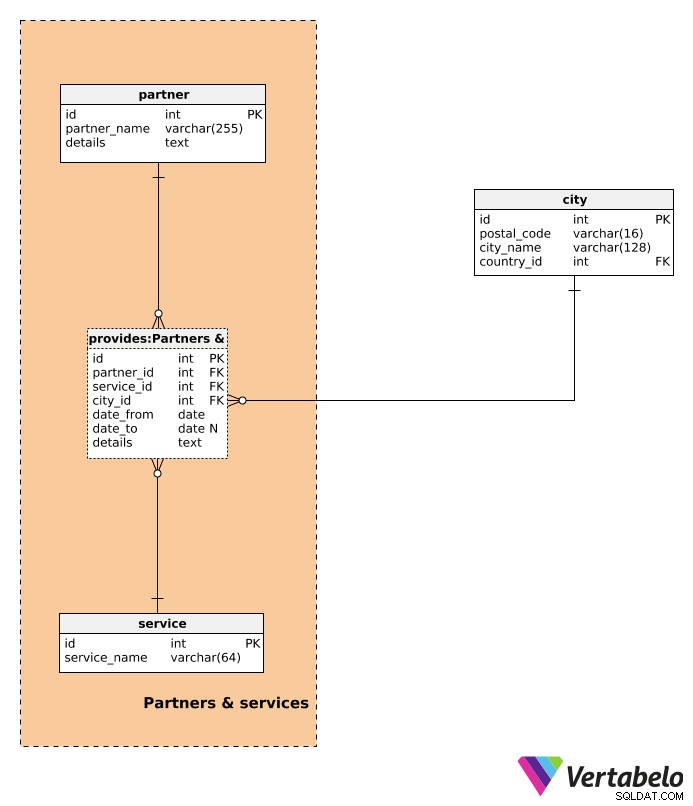
Låt oss sedan beskriva de tjänster vi kommer att tillhandahålla våra kunder.
En lista över alla möjliga tjänster lagras i service lexikon. Den innehåller endast det UNIKA service_name attribut.
I denna datamodell tillhandahålls alla tjänster av partners. Även när vårt företag faktiskt tillhandahåller tjänsten kommer vi att behandla den som en partner service (och vi är partnern). Partnerordboken kommer att lagra alla partners vi arbetar med, inklusive oss. För varje partner lagrar vi ett UNIKT partner_name . details attribut lagrar alla ytterligare detaljer relaterade till den partnern med ett ostrukturerat eller strukturerat format (t.ex. med namn-värdepar separerade med fördefinierad avgränsare).
provides tabellen är den sista och viktigaste tabellen i detta avsnitt. För varje post lagrar vi:
partner_id–partnersom tillhandahåller en tjänst.service_id–servicedenna partner tillhandahåller.city_id– Refererar tillcitydär denna tjänst tillhandahålls av den partnern.date_from– Datumet då partnern började erbjuda den tjänsten.date_to– Datumet då partnern slutade erbjuda den tjänsten. Detta värde kan vara NULL om den service-partner-relationen fortfarande pågår.details– Alla ytterligare detaljer relaterade till den tjänsten, såsom tjänstebeskrivning, pris, etc. Vi kan förvänta oss att alla detaljer kommer att vara i ett strukturerat textformat, med nyckel-värdepar.
Kombinationen av partner_id – service_id – city_id – date_from bildar den UNIKA nyckeln i denna tabell. När vi anger en ny post bör vi kontrollera att den inte överlappar några befintliga poster.
Avsnitt 3:Anställda och roller
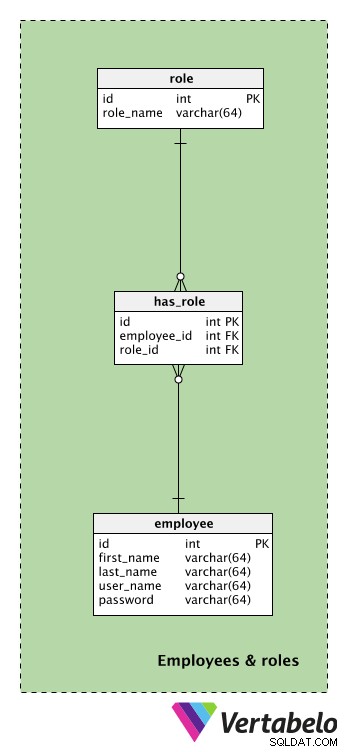
Innan vi går över till den centrala och viktigaste delen av vår modell måste vi titta på tabellerna relaterade till våra anställda och deras roller.
Den centrala tabellen i detta ämnesområde är employee tabell. För varje anställd lagrar vi deras first_name , last_name , user_name och password . De kommer att använda dessa två sista attribut för att komma åt vår applikation.
En lista över alla möjliga roller lagras i role lexikon. Varje roll definieras UNIKT av dess role_name . Roller är relaterade till handlingar som varje anställd utför under en fest. Därför kan vi förvänta oss värderingar som "festansvarig" eller "assistent" här.
Roller kan tilldelas anställda med hjälp av has_role tabell. employee_id – role_id par kommer att beteckna de aktiva roller varje anställd har vid det tillfället.
Avsnitt 4:Party
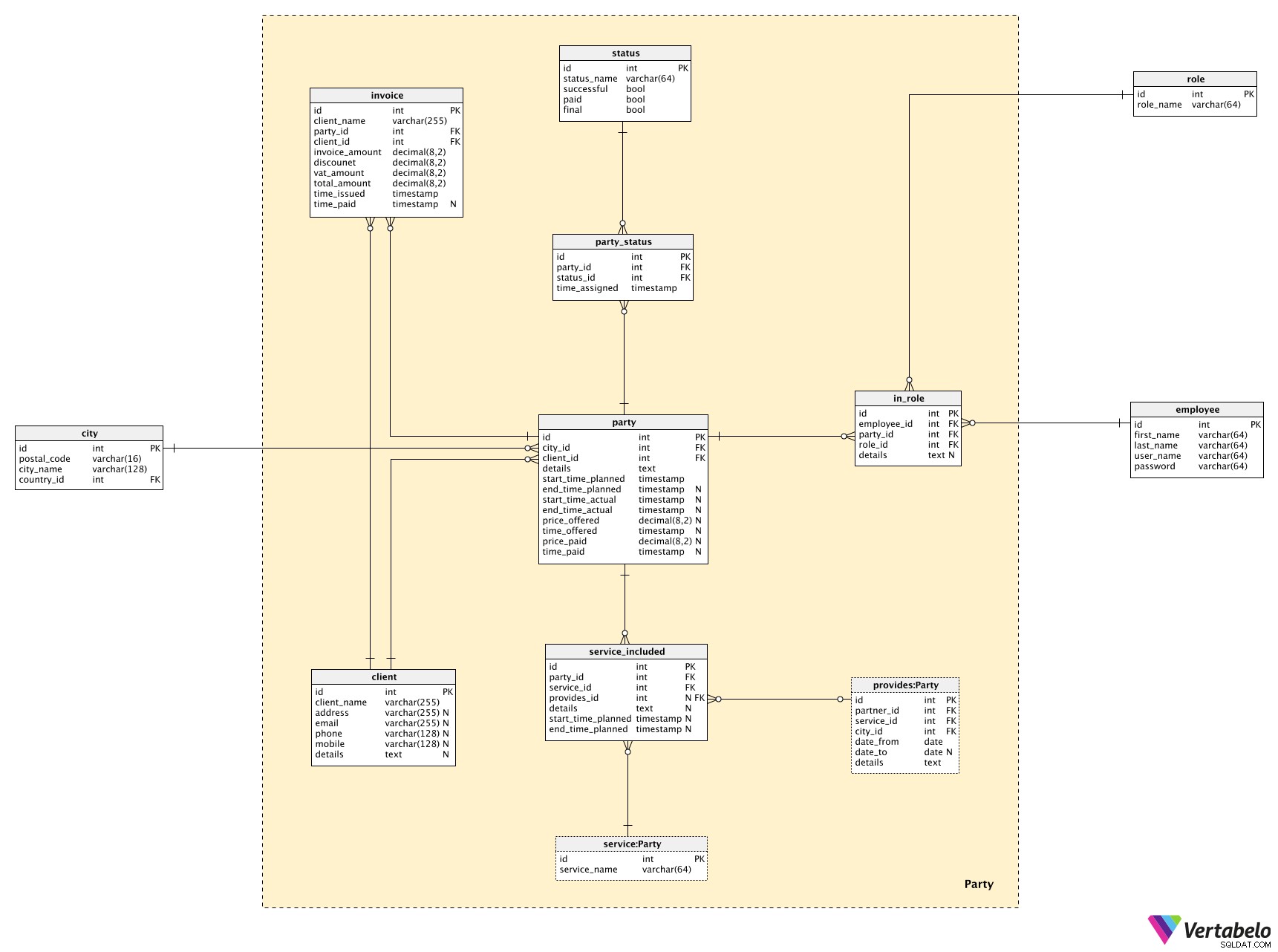
Party ämnesområdet är den centrala delen av denna modell. Vi kommer att använda den för att relatera tabeller från andra ämnesområden, och vi kommer också att ha lite ny information här också.
Den centrala tabellen här är party tabell. För varje part lagrar vi:
city_id–citydär festen kommer att äga rum.client_id–clientdenna fest är anordnad för.details– En detaljerad textbeskrivning av festen.start_time_plannedochend_time_planned– Tiden vi har schemalagt för den här festen, inklusive installation och städning.start_time_actualochend_time_actual– De faktiska gånger festen (och dess relaterade tjänster) ägde rum.price_offered– Priset vi angav för att organisera denna fest för den här klienten.time_offered– När erbjudandet gjordes.price_paid– Det faktiska belopp som kunden betalade för denna fest.time_paid– När betalningen gjordes.
Varje part är relaterad till en klient. Vi har redan hänvisat till client tabell, men nu ska vi se vad som finns lagrat där. Jag använde bara grundläggande data:client_name , kontaktuppgifter (address , email , phone , mobile ), och eventuell ytterligare information i textformat.
Varje part kommer också att ha en lista över tjänster kopplade till sig. Den listan lagras i service_included tabell. För varje post behöver vi:
party_id– Refererar till den relateradeparty.service_id– Refererar tillserviceingår i festen.provides_id– Refererar tillproviderav den tjänsten, såväl som själva tjänsten. Det här attributet kan vara NULL, eftersom vi uppdaterar det när vi väljer den specifika leverantören.details– Eventuell ytterligare textinformation relaterade till tjänsten i den parten.start_time_plannedochend_time_planned– De planerade tiderna då service ska tillhandahållas under festen.
Vi måste också följa framstegen för varje parti. Vi använder två tabeller för att göra detta.
status Tabellen kommer att lista alla möjliga statusar som kan tilldelas en part. För varje post lagrar vi ett UNIKT status_name och tre flaggor:
successful– Gick allt bra? Eller var det problem med våra tjänster?paid– Har festen fått betalt?final– Är detta den slutliga statusen för det här partiet?
Vi tilldelar tjänster status genom att lägga till nya poster i party_status tabell. För varje post lagrar vi referenser till party och service tabeller och timestamp när denna status tilldelades.
Den sista tabellen i vår modell är invoice tabell. Det är inte specifikt för denna modell, men vi behöver en grundläggande struktur för att lagra fakturor. För varje faktura kommer vi att registrera:
client_name– Kundens namn vid den tidpunkt då fakturan utfärdades.party_id–partyrelaterad till denna faktura.client_id– ID förclientfaktureras.invoice_amount,discount,vat_amount,total_amount– De ekonomiska uppgifterna för fakturan.time_issued- När denna faktura utfärdades eller lades till i databasen.time_paid- När den här fakturan betalades.
Vad skulle du göra med den här datamodellen?
Den här modellen är ganska enkel, men jag ser flera sätt vi kan förbättra den. Vilka ändringar skulle du föreslå? Finns det något vi skulle kunna organisera annorlunda? Kanske måste vi lägga till eller ta bort en funktion. Berätta för oss i kommentarerna.