[ Del 1 | Del 2 | Del 3 ]
I del 1 av den här serien testade jag några sätt att komprimera en 1TB-tabell. Medan jag fick anständiga resultat i mitt första försök, ville jag se om jag kunde förbättra prestandan i del 2. Där beskrev jag några av de saker jag trodde kunde vara prestandaproblem, och lade ut hur jag bättre skulle partitionera måltabellen för optimal columnstore-komprimering. Jag har redan:
- partitionerade tabellen i 8 partitioner (en per kärna);
- lägg varje partitions datafil i sin egen filgrupp; och,
- ställ in arkivkomprimering på alla utom den "aktiva" partitionen.
Jag måste fortfarande göra det så att varje schemaläggare skriver exklusivt till sin egen partition.
Först måste jag göra ändringar i batchtabellen jag skapade. Jag behöver en kolumn för att lagra antalet rader som lagts till per batch (typ av en självrevisionskontroll) och start-/sluttider för att mäta framsteg.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Därefter måste jag skapa en tabell för att ge samhörighet – vi vill aldrig att mer än en process körs på någon schemaläggare, även om det innebär att förlora lite tid på att försöka logik igen. Så vi behöver en tabell som håller reda på alla sessioner på en specifik schemaläggare och förhindrar stapling:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Tanken är att jag skulle ha åtta instanser av en applikation (SQLQueryStress) som var och en skulle köras på en dedikerad schemaläggare och endast hantera data som är avsedda för en specifik partition/filgrupp/datafil, ~100 miljoner rader åt gången (klicka för att förstora) :
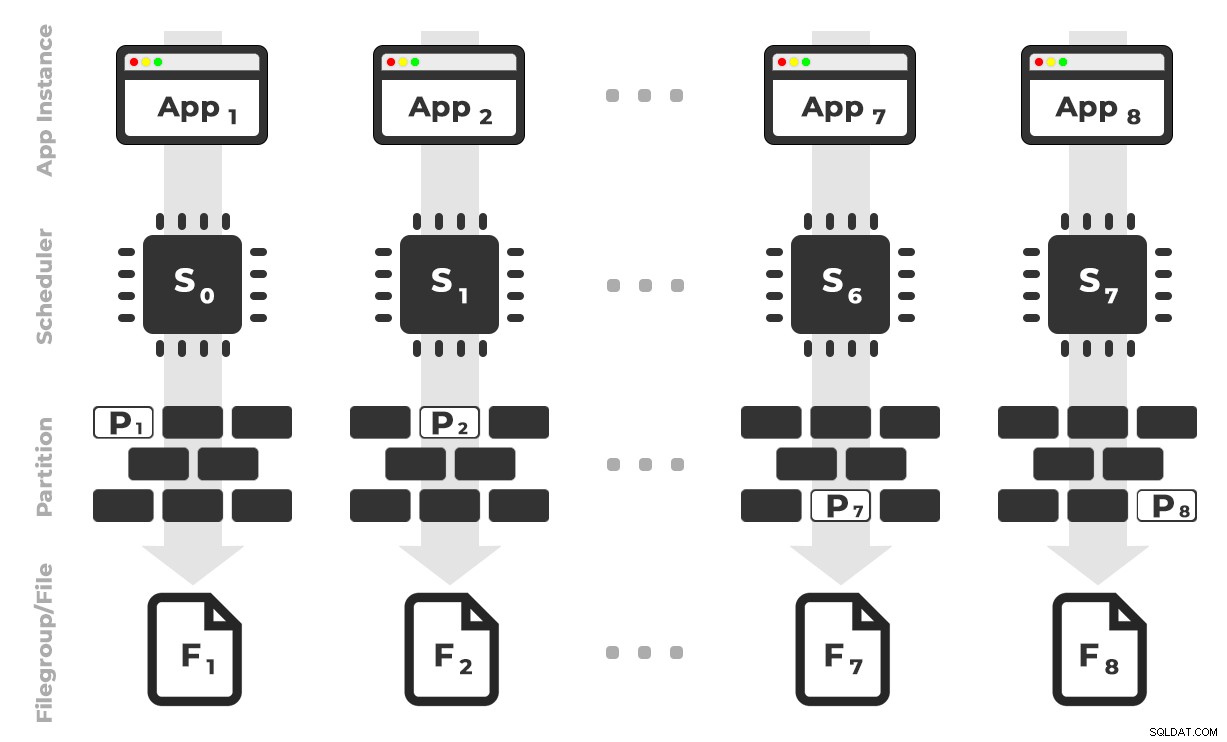 App 1 får schemaläggare 0 och skriver till partition 1 på filgrupp 1, och så vidare …
App 1 får schemaläggare 0 och skriver till partition 1 på filgrupp 1, och så vidare …
Därefter behöver vi en lagrad procedur som gör det möjligt för varje instans av applikationen att reservera tid på en enda schemaläggare. Som jag nämnde i ett tidigare inlägg är detta inte min ursprungliga idé (och jag skulle aldrig ha hittat den i den guiden om inte Joe Obbish hade funnits). Här är proceduren jag skapade i Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Enkelt, eller hur? Starta 8 instanser av SQLQueryStress och lägg denna batch i varje:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Fattig mans parallellism
Fattig mans parallellism
Förutom att det inte är så enkelt, eftersom schemaläggaruppdrag är ungefär som en chokladask. Det tog många försök att få varje instans av appen på den förväntade schemaläggaren; Jag skulle inspektera undantagen för en given instans av appen och ändra PartitionID att matcha. Det är därför jag använde mer än en iteration (men jag ville fortfarande bara ha en tråd per instans). Som ett exempel, den här instansen av appen förväntade sig att vara på schemaläggare 3, men den fick schemaläggare 4:
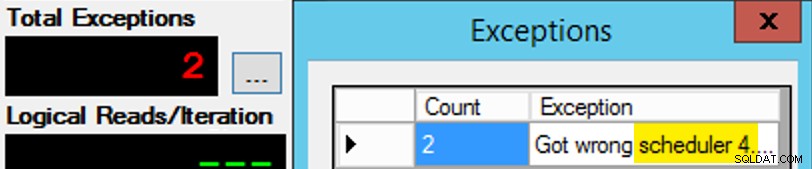 Om du först inte lyckas...
Om du först inte lyckas...
Jag ändrade 3:orna i frågefönstret till 4:or och försökte igen. Om jag var snabb var schemaläggningsuppdraget tillräckligt "klibbigt" för att det skulle plocka upp det direkt och börja tjafsa iväg. Men jag var inte alltid tillräckligt snabb, så det var lite som en mullvad att komma igång. Jag kunde förmodligen ha utarbetat en bättre återförsök/looprutin för att göra arbetet mindre manuellt här, och kortat upp fördröjningen så att jag direkt visste om det fungerade eller inte, men det här var tillräckligt bra för mina behov. Det ledde också till en oavsiktlig förväxling av starttider för varje process, ett annat råd från Mr. Obbish.
Övervakning
Medan den associerade kopian körs kan jag få en ledtråd om aktuell status med följande två frågor:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Om jag gjorde allt rätt skulle båda frågorna returnera 8 rader och visa ökande logiska läsningar och varaktighet. Väntetyper växlar mellan PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , och ibland RESERVED_MEMORY_ALLOCATION_EXT. När en batch var klar (jag kunde granska dessa genom att avkommentera -- AND EndTime IS NULL , skulle jag bekräfta att RowsAdded = RowsInRange .
När alla 8 instanser av SQLQueryStress var klara kunde jag bara utföra en SELECT INTO <newtable> FROM dbo.BatchQueue för att logga de slutliga resultaten för senare analys.
Andra tester
Förutom att kopiera data till det partitionerade klustrade kolumnlagerindexet som redan fanns, med affinitet, ville jag prova ett par andra saker också:
- Kopierar data till den nya tabellen utan att försöka kontrollera affinitet. Jag tog bort affinitetslogiken ur proceduren och lämnade bara hela "hoppas-du-får-rätt-schemaläggaren" åt slumpen. Detta tog längre tid eftersom, visst, schemaläggaren gjorde det inträffa. Till exempel, vid denna specifika tidpunkt körde schemaläggare 3 två processer, medan schemaläggare 0 inte tog en lunchrast:
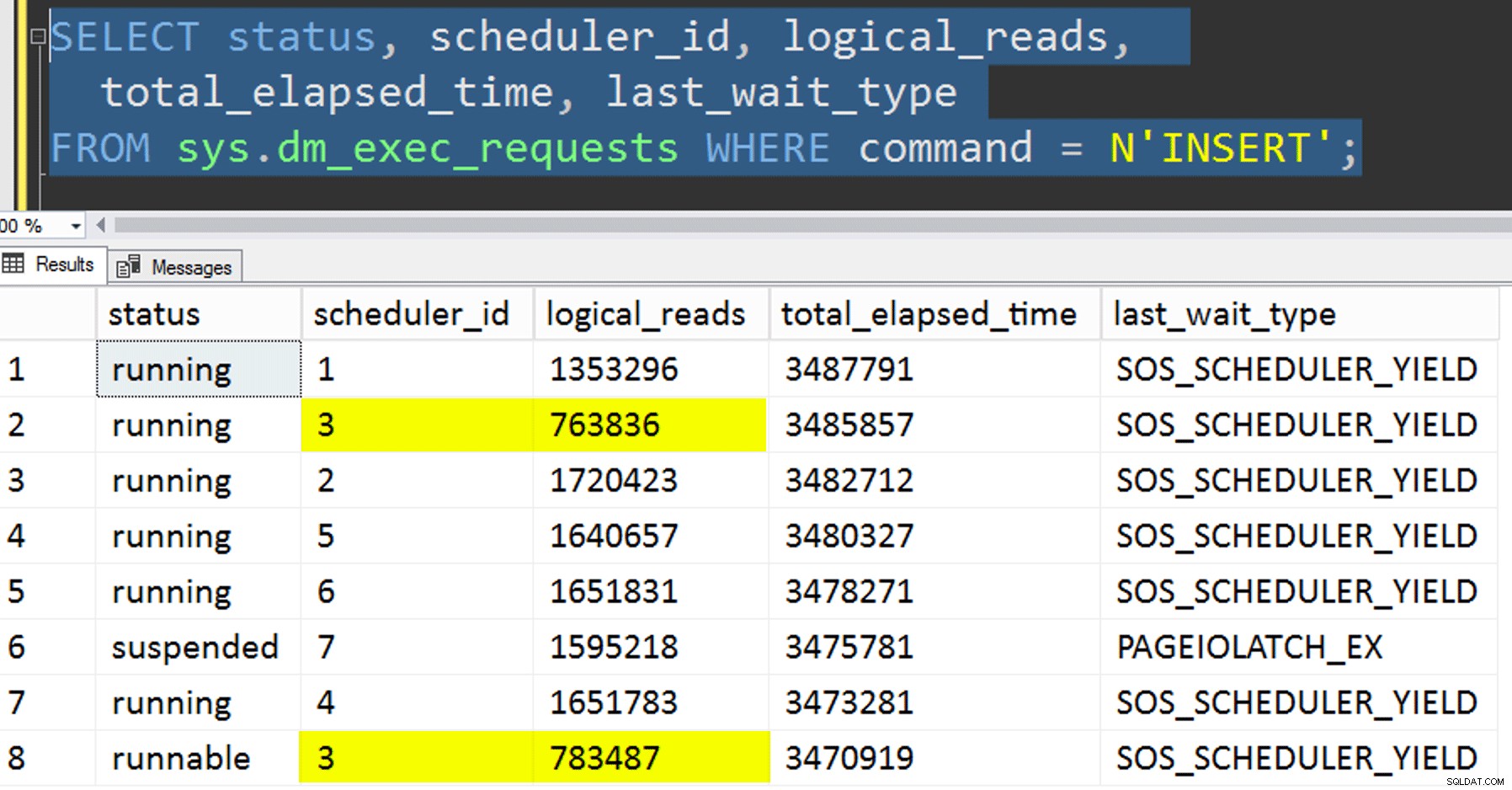 Var är du, schemaläggare nummer 0?
Var är du, schemaläggare nummer 0? - Använder sida eller rad komprimering (både online/offline) till källan före den affinitiserade kopian (offline), för att se om komprimering av data först skulle kunna påskynda destinationen. Observera att kopian också kan göras online, men som Andy Mallons
inttillbigintomställning kräver det lite gymnastik. Observera att i det här fallet kan vi inte dra fördel av CPU-affinitet (även om vi kunde om källtabellen redan var partitionerad). Jag var smart och tog en säkerhetskopia av den ursprungliga källan och skapade en procedur för att återställa databasen till dess ursprungliga tillstånd. Mycket snabbare och enklare än att försöka återgå till ett specifikt tillstånd manuellt.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- Och slutligen, bygga om det klustrade indexet till partitionsschemat först, och sedan bygga det klustrade kolumnlagerindexet ovanpå det. Nackdelen med det senare är att du i SQL Server 2017 inte kan köra detta online... men du kommer att kunna göra det under 2019.
Här måste vi släppa PK-begränsningen först; du kan inte använda
Msg 1907, Level 16, State 1DROP_EXISTING, eftersom den ursprungliga unika begränsningen inte kan upprätthållas av det klustrade kolumnlagerindexet, och du kan inte ersätta ett unikt klustrat index med ett icke-unikt klustrat index.
Kan inte återskapa index 'pk_tblOriginal'. Den nya indexdefinitionen matchar inte den begränsning som upprätthålls av det befintliga indexet.Alla dessa detaljer gör detta till en trestegsprocess, bara det andra steget online. Det första steget testade jag bara uttryckligen
OFFLINE; som gick på tre minuter, medanONLINEJag slutade efter 15 minuter. En av de saker som kanske inte borde vara en datastorleksoperation i båda fallen, men jag lämnar det till en annan dag.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Resultat
Tider och komprimeringshastigheter:
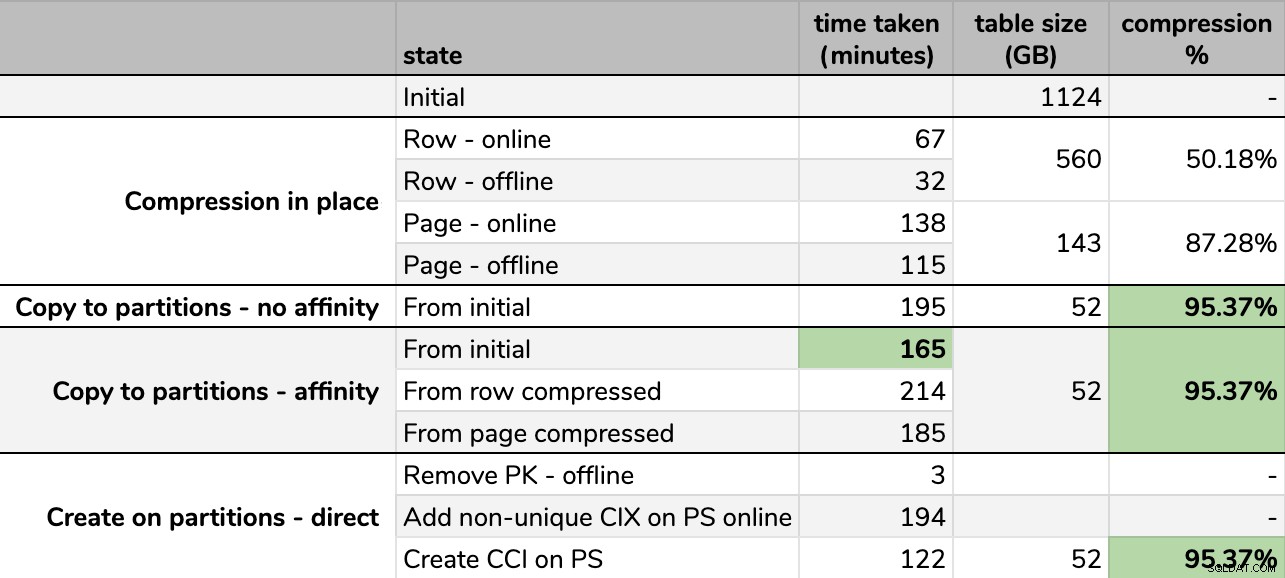 Vissa alternativ är bättre än andra
Vissa alternativ är bättre än andra
Observera att jag avrundade till GB eftersom det skulle finnas mindre skillnader i slutstorlek efter varje körning, även med samma teknik. Tiderna för affinitetsmetoderna baserades också på genomsnittet individuell schemaläggare/batchkörning, eftersom vissa schemaläggare slutade snabbare än andra.
Det är svårt att föreställa sig en exakt bild från kalkylarket som visas, eftersom vissa uppgifter har beroenden, så jag ska försöka visa informationen som en tidslinje och visa hur mycket komprimering du får jämfört med tiden:
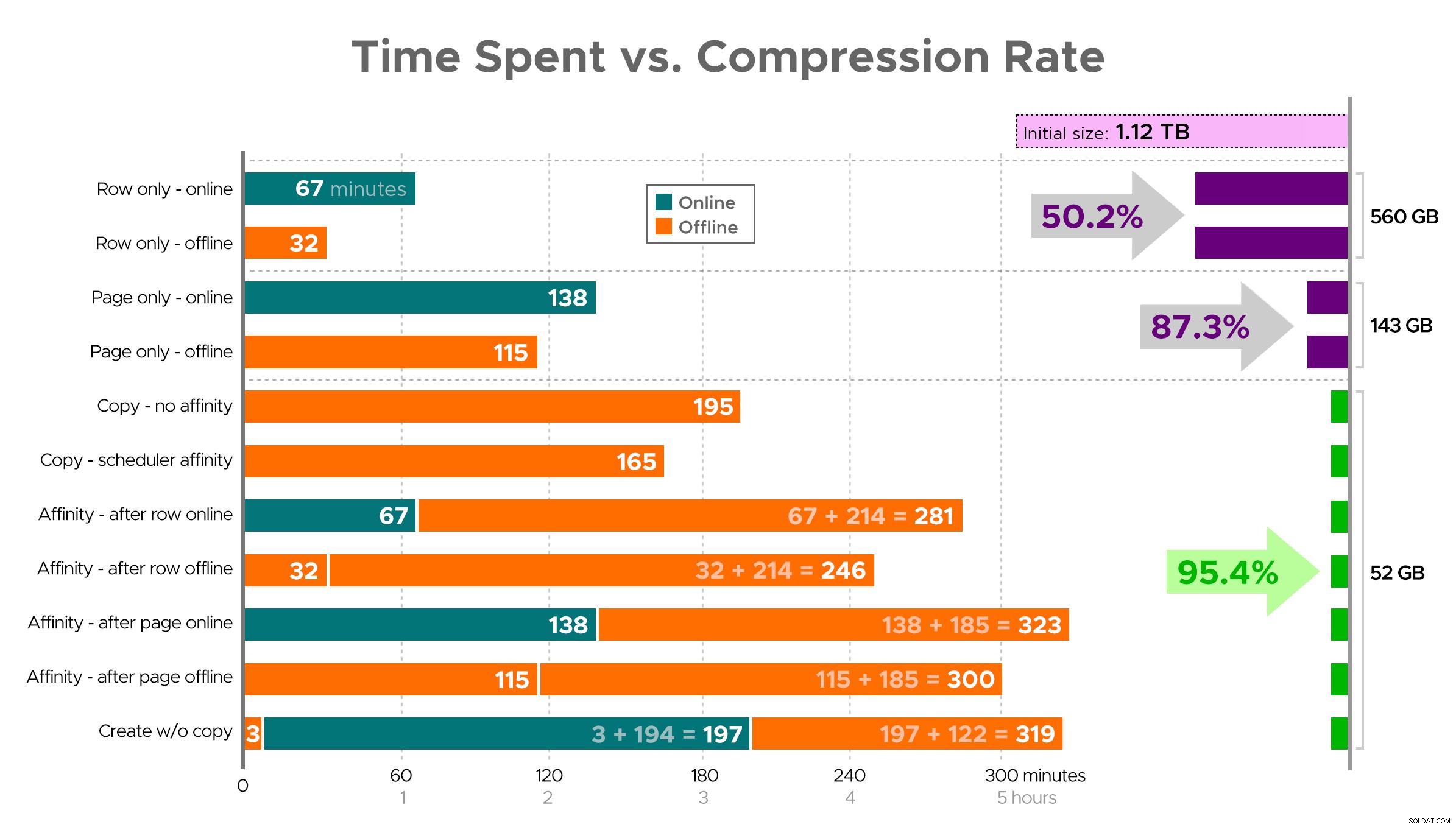 Tid (minuter) kontra komprimeringsgrad
Tid (minuter) kontra komprimeringsgrad
Några observationer från resultaten, med förbehållet att din data kan komprimeras annorlunda (och att onlineoperationer endast gäller dig om du använder Enterprise Edition):
- Om din prioritet är att spara lite utrymme så snabbt som möjligt , det bästa alternativet är att applicera radkompression på plats. Om du vill minimera störningar, använd online; om du vill optimera hastigheten, använd offline.
- Om du vill maximera komprimeringen utan avbrott , kan du närma dig 90 % lagringsminskning utan några störningar alls, med hjälp av sidkomprimering online.
- Om du vill maximera komprimering och störningar är okej , kopiera data till en ny, partitionerad version av tabellen, med ett klustrat kolumnlagerindex, och använd affinitetsprocessen som beskrivs ovan för att migrera data. (Och återigen, du kan eliminera denna störning om du är en bättre planerare än jag.)
Det sista alternativet fungerade bäst för mitt scenario, även om vi fortfarande måste sparka däcken på arbetsbelastningen (ja, plural). Observera också att i SQL Server 2019 kanske den här tekniken inte fungerar så bra, men du kan bygga klustrade kolumnbutiksindex online där, så det kanske inte spelar så stor roll.
Vissa av dessa tillvägagångssätt kan vara mer eller mindre acceptabla för dig, eftersom du kanske föredrar "att vara tillgänglig" framför "avsluta så snabbt som möjligt" eller "minimera diskanvändning" framför "förbli tillgänglig", eller bara balansera läsprestanda och skrivoverhead .
Om du vill ha mer information om någon aspekt av detta, fråga bara. Jag trimmade lite av fettet för att balansera detaljer med smältbarhet, och jag har haft fel om den balansen tidigare. En avskiljande tanke är att jag är nyfiken på hur linjärt detta är – vi har ett annat bord med en liknande struktur som är över 25 TB, och jag är nyfiken på om vi kan göra någon liknande inverkan där. Tills dess, lycklig komprimering!
[ Del 1 | Del 2 | Del 3 ]