När SQL Server optimerar en fråga, producerar den under en utforskningsfas kandidatplaner och väljer bland dem den som har lägst kostnad. Den valda planen antas ha den lägsta körtiden bland de utforskade planerna. Saken är den att optimeraren bara kan välja mellan strategier som kodats in i den. Till exempel, när du optimerar gruppering och aggregering, när detta skrivs, kan optimeraren endast välja mellan Stream Aggregate och Hash Aggregate-strategier. Jag täckte de tillgängliga strategierna i tidigare delar i den här serien. I del 1 täckte jag den förbeställda Stream Aggregate-strategin, i Del 2 Sort + Stream Aggregate-strategin, i Del 3 Hash Aggregate-strategin och i Del 4 parallellitetsöverväganden.
Vad SQL Server-optimeraren för närvarande inte stöder är anpassning och artificiell intelligens. Det vill säga, om du kan lista ut en strategi som under vissa förhållanden är mer optimal än de som optimeraren stöder, kan du inte förbättra optimeraren för att stödja den, och optimeraren kan inte lära sig att använda den. Men vad du kan göra är att skriva om frågan med hjälp av alternativa frågeelement som kan optimeras med den strategi du har i åtanke. I den här femte och sista delen i serien demonstrerar jag denna teknik med frågejustering med hjälp av frågeversioner.
Stort tack till Paul White (@SQL_Kiwi) för hjälpen med några av kostnadsberäkningarna som presenteras i den här artikeln!
Liksom i de tidigare delarna i serien kommer jag att använda PerformanceV3-exempeldatabasen. Använd följande kod för att ta bort onödiga index från ordertabellen:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Standard optimeringsstrategi
Tänk på följande grundläggande grupperings- och aggregeringsuppgifter:
Returnera det maximala beställningsdatumet för varje avsändare, anställd och kund.
För optimal prestanda skapar du följande stödjande index:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Följande är de tre frågorna du skulle använda för att hantera dessa uppgifter, tillsammans med uppskattade underträdskostnader, samt statistik för I/O, CPU och förfluten tid:
-- Fråga 1-- Beräknad delträdskostnad:3,5344-- logiska läsningar:2484, CPU-tid:281 ms, förfluten tid:279 ms VÄLJ shipperid, MAX(orderdatum) SOM maxodFROM dbo.OrdersGROUP BY shipperid; -- Fråga 2-- Beräknad delträdskostnad:3,62798-- logiska läsningar:2610, CPU-tid:250 ms, förfluten tid:283 ms SELECT empid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY empid; -- Fråga 3-- Beräknad delträdskostnad:4,27624-- logiska läsningar:3479, CPU-tid:406 ms, förfluten tid:506 ms SELECT custid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY custid;
Figur 1 visar planerna för dessa frågor:
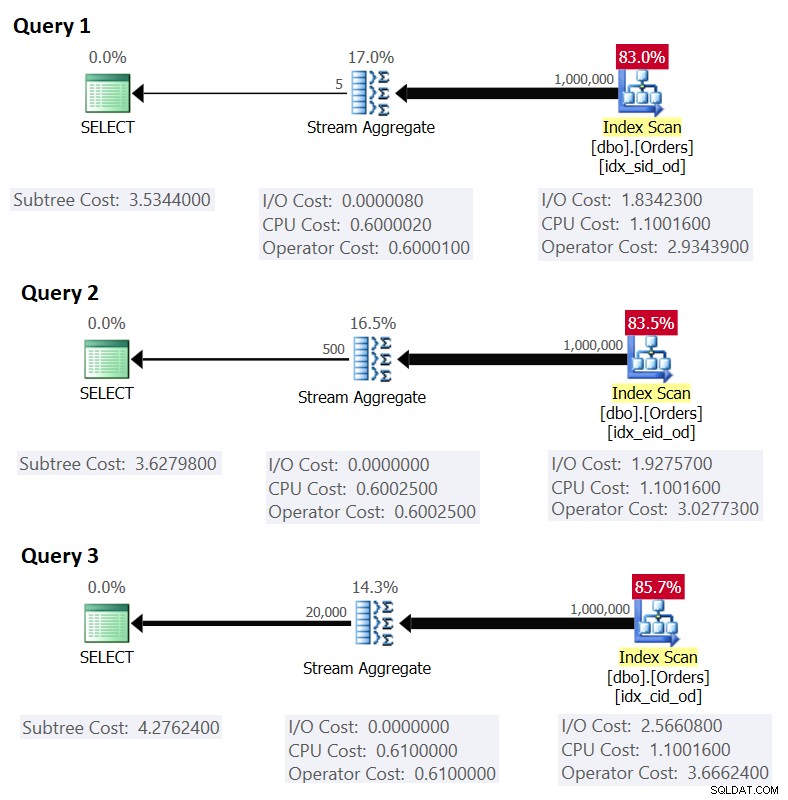 Figur 1:Planer för grupperade frågor
Figur 1:Planer för grupperade frågor
Kom ihåg att om du har ett täckande index på plats, med grupperingsuppsättningens kolumner som de ledande nyckelkolumnerna, följt av aggregeringskolumnen, kommer SQL Server sannolikt att välja en plan som utför en ordnad genomsökning av täckningsindexet som stöder Stream Aggregate-strategin . Som framgår av planerna i figur 1 står Index Scan-operatören för det mesta av plankostnaden, och inom den är I/O-delen den mest framträdande.
Innan jag presenterar en alternativ strategi och förklarar under vilka omständigheter den är mer optimal än standardstrategin, låt oss utvärdera kostnaden för den befintliga strategin. Eftersom I/O-delen är den mest dominerande för att bestämma plankostnaden för denna standardstrategi, låt oss först bara uppskatta hur många logiska sidläsningar som kommer att krävas. Senare kommer vi också att uppskatta planens kostnad.
För att uppskatta antalet logiska läsningar som Index Scan-operatorn kommer att kräva måste du veta hur många rader du har i tabellen och hur många rader som får plats på en sida baserat på radstorleken. När du väl har dessa två operander är din formel för det nödvändiga antalet sidor i indexets bladnivå CEILING(1e0 * @numrows / @rowsperpage). Om allt du har är bara tabellstrukturen och inga befintliga exempeldata att arbeta med, kan du använda den här artikeln för att uppskatta antalet sidor du skulle ha på bladnivån i det stödjande indexet. Om du har bra representativa exempeldata, även om de inte är i samma skala som i produktionsmiljön, kan du beräkna det genomsnittliga antalet rader som passar på en sida genom att fråga efter katalog och dynamiska hanteringsobjekt, som så:
SELECT I.name, row_count, in_row_data_page_count, CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage FROM sys.indexes AS I INNER JOIN sys.dm_db_partition_stats AS P ON I.object_id =P.object_id AND I.index_id =P.index_id WHERE I.object_id =OBJECT_ID('dbo.Orders') OCH I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Den här frågan genererar följande utdata i vår exempeldatabas:
name row_count in_row_data_page_count avgrowsperpage ---------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Nu när du har antalet rader som får plats på en bladsida i indexet kan du uppskatta det totala antalet bladsidor i indexet baserat på antalet rader du förväntar dig att din produktionstabell ska ha. Detta kommer också att vara det förväntade antalet logiska avläsningar som ska tillämpas av Index Scan-operatören. I praktiken finns det mer i antalet läsningar som kan äga rum än bara antalet sidor i indexets bladnivå, till exempel extra läsningar som produceras av läs framåt-mekanismen, men jag ignorerar dem för att hålla vår diskussion enkel .
Till exempel är det uppskattade antalet logiska läsningar för fråga 1 med avseende på det förväntade antalet rader CEILING(1e0 * @numorws / 404). Med 1 000 000 rader är det förväntade antalet logiska läsningar 2 476. Skillnaden mellan 2 476 och det rapporterade antalet sidor på 2 473 kan tillskrivas den avrundning jag gjorde när jag beräknade det genomsnittliga antalet rader per sida.
När det gäller plankostnaden förklarade jag hur man reverserar strömaggregatsoperatörens kostnad i del 1 i serien. På liknande sätt kan du reverse engineering av kostnaden för Index Scan-operatören. Plankostnaden är då summan av kostnaderna för operatörerna Index Scan och Stream Aggregate.
För att beräkna kostnaden för Index Scan-operatören vill du börja med omvänd konstruktion av några av de viktiga kostnadsmodellkonstanterna:
@randomio =0,003125 -- Slumpmässig I/O-kostnad@seqio =0,000740740740741 -- Sekventiell I/O-kostnad@cpubase =0,000157 -- CPU-baskostnad@cpurow =0,0000011 -- CPU-kostnad per rad
Med ovanstående kostnadsmodellkonstanter utarbetade kan du fortsätta att omvända formlerna för I/O-kostnad, CPU-kostnad och total operatörskostnad för Index Scan-operatören:
I/O-kostnad:@randomio + (@numpages - 1e0) * @seqio =0,003125 + (@numpages - 1e0) * 0,000740740740741CPU-kostnad:@cpubase + @numrows * @cpurow =0,0001s =0,0001s 0,001s. kostnad:0,002541259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000011
Till exempel är operatörskostnaden för Index Scan för fråga 1, med 2 473 sidor och 1 000 000 rader:
0,002541259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000011 =2,93439
Följande är den omvända formeln för Stream Aggregate-operatörskostnaden:
0,000008 + @numrows * 0,0000006 + @numgroups * 0,0000005
Som ett exempel, för fråga 1, har vi 1 000 000 rader och 5 grupper, därför är den uppskattade kostnaden 0,6000105.
Genom att kombinera kostnaderna för de två operatörerna, här är formeln för hela plankostnaden:
0,002549259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005
För fråga 1, med 2 473 sidor, 1 000 000 rader och 5 grupper, får du:
0,002549259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,0000005 =3,5344
Detta matchar vad figur 1 visar som den beräknade kostnaden för fråga 1.
Om du förlitade dig på ett uppskattat antal rader per sida skulle din formel vara:
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numrows * 0,0000005
Som ett exempel, för fråga 1, med 1 000 000 rader, 404 rader per sida och 5 grupper, är den uppskattade kostnaden:
0,002549259259259 + CEILING(1e0 * 1000000 / 404) * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,000000 / 404)
Som en övning kan du använda siffrorna för fråga 2 (1 000 000 rader, 385 rader per sida, 500 grupper) och fråga 3 (1 000 000 rader, 289 rader per sida, 20 000 grupper) i vår formel och se att resultaten matchar vad Figur 1 visar.
Frågejustering med frågeomskrivningar
Den förbeställda förbeställda Stream Aggregate-strategin för att beräkna ett MIN/MAX-aggregat per grupp förlitar sig på en beställd skanning av ett stödjande täckande index (eller någon annan preliminär aktivitet som avger de ordnade raderna). En alternativ strategi, med ett stödjande täckande index närvarande, skulle vara att utföra en indexsökning per grupp. Här är en beskrivning av en pseudoplan baserad på en sådan strategi för en fråga som grupperar efter grpcol och tillämpar en MAX(aggcol):
set @curgrpcol =grpcol från första raden erhållen genom en skanning av indexet, beställt framåt; medan slutet av indexet inte nåttbegin set @curagg =aggcol från raden erhållet genom en sökning till den sista punkten där grpcol =@curgrpcol, beställd bakåt; emit row (@curgrpcol, @curagg); ställ in @curgrpcol =grpcol från rad till höger om sista raden för aktuell grupp;slut;
Om du tänker efter är den standardskanningsbaserade strategin optimal när grupperingsuppsättningen har låg densitet (stort antal grupper, med ett litet antal rader per grupp i genomsnitt). Den sökningsbaserade strategin är optimal när grupperingsuppsättningen har hög densitet (litet antal grupper, med ett stort antal rader per grupp i genomsnitt). Figur 2 illustrerar båda strategierna och visar när var och en är optimal.
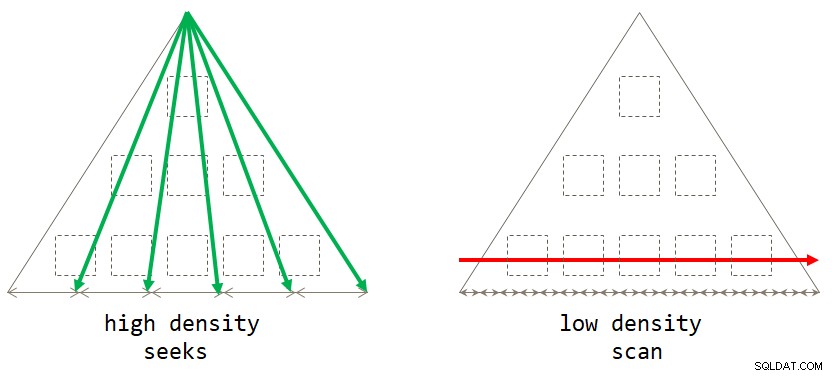 Figur 2:Optimal strategi baserat på grupperingsuppsättningstäthet
Figur 2:Optimal strategi baserat på grupperingsuppsättningstäthet
Så länge du skriver lösningen i form av en grupperad fråga, kommer SQL Server för närvarande endast att överväga skanningsstrategin. Detta kommer att fungera bra för dig när grupperingsuppsättningen har låg densitet. När du har hög densitet, för att få sökstrategin, måste du tillämpa en omskrivning av frågan. Ett sätt att uppnå detta är att fråga tabellen som innehåller grupperna och att använda en skalär aggregatunderfråga mot huvudtabellen för att få aggregatet. Till exempel, för att beräkna det maximala beställningsdatumet för varje avsändare, skulle du använda följande kod:
SELECT shipperid, ( SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid BESTÄLLNING BY O.orderdate DESC ) AS maxod FROM dbo.Shippers AS S;
Indexeringsriktlinjerna för huvudtabellen är desamma som de som stöder standardstrategin. Vi har redan dessa index på plats för de tre ovannämnda uppgifterna. Du skulle förmodligen också vilja ha ett stödjande index på grupperingsuppsättningens kolumner i tabellen som innehåller grupperna för att minimera I/O-kostnaden mot den tabellen. Använd följande kod för att skapa sådana stödjande index för våra tre uppgifter:
SKAPA INDEX idx_sid PÅ dbo.Shippers(shipperid);CREATE INDEX idx_eid PÅ dbo.Employees(empid);CREATE INDEX idx_cid PÅ dbo.Customers(custid);
Ett litet problem är dock att lösningen baserad på underfrågan inte är en exakt logisk motsvarighet till lösningen baserad på den grupperade frågan. Om du har en grupp utan närvaro i huvudtabellen kommer den förra att returnera gruppen med en NULL som aggregat, medan den senare inte kommer att returnera gruppen alls. Ett enkelt sätt att uppnå en sann logisk motsvarighet till den grupperade frågan är att anropa underfrågan med CROSS APPLY-operatorn i FROM-satsen istället för att använda en skalär underfråga i SELECT-satsen. Kom ihåg att CROSS APPLY inte returnerar en vänsterrad om den tillämpade frågan returnerar en tom uppsättning. Här är de tre lösningsfrågorna som implementerar denna strategi för våra tre uppgifter, tillsammans med deras resultatstatistik:
-- Fråga 4 -- Beräknad delträdskostnad:0,0072299 -- logiska läsningar:2 + 15, CPU-tid:0 ms, förfluten tid:43 ms SELECT S.shipperid, A.orderdate AS maxod FRÅN dbo.Shippers AS S KORSA TILLÄMP (VÄLJ TOP (1) O.orderdatum FRÅN dbo.Beställningar AS O WHERE O.shipperid =S.shipperid BESTÄLLNING AV O.orderdatum DESC ) SOM A; -- Fråga 5 -- Beräknad delträdskostnad:0,089694 -- logiska läsningar:2 + 1620, CPU-tid:0 ms, förfluten tid:148 ms VÄLJ E.empid, A.orderdate AS maxod FROM dbo.Employees AS E CROSS APPLY ( VÄLJ TOP (1) O.orderdatum FRÅN dbo.Order AS O WHERE O.empid =E.empid ORDER BY O.orderdate DESC ) SOM A; -- Fråga 6 -- Beräknad delträdskostnad:3,5227 -- logiska läsningar:45 + 63777, CPU-tid:171 ms, förfluten tid:306 ms VÄLJ C.custid, A.orderdate AS maxod FRÅN dbo.Customers AS CROSS APPLY ( VÄLJ UPP (1) O.orderdatum FRÅN dbo.Order AS O WHERE O.custid =C.custid BESTÄLLNING AV O.orderdate DESC ) SOM A;
Planerna för dessa frågor visas i figur 3.
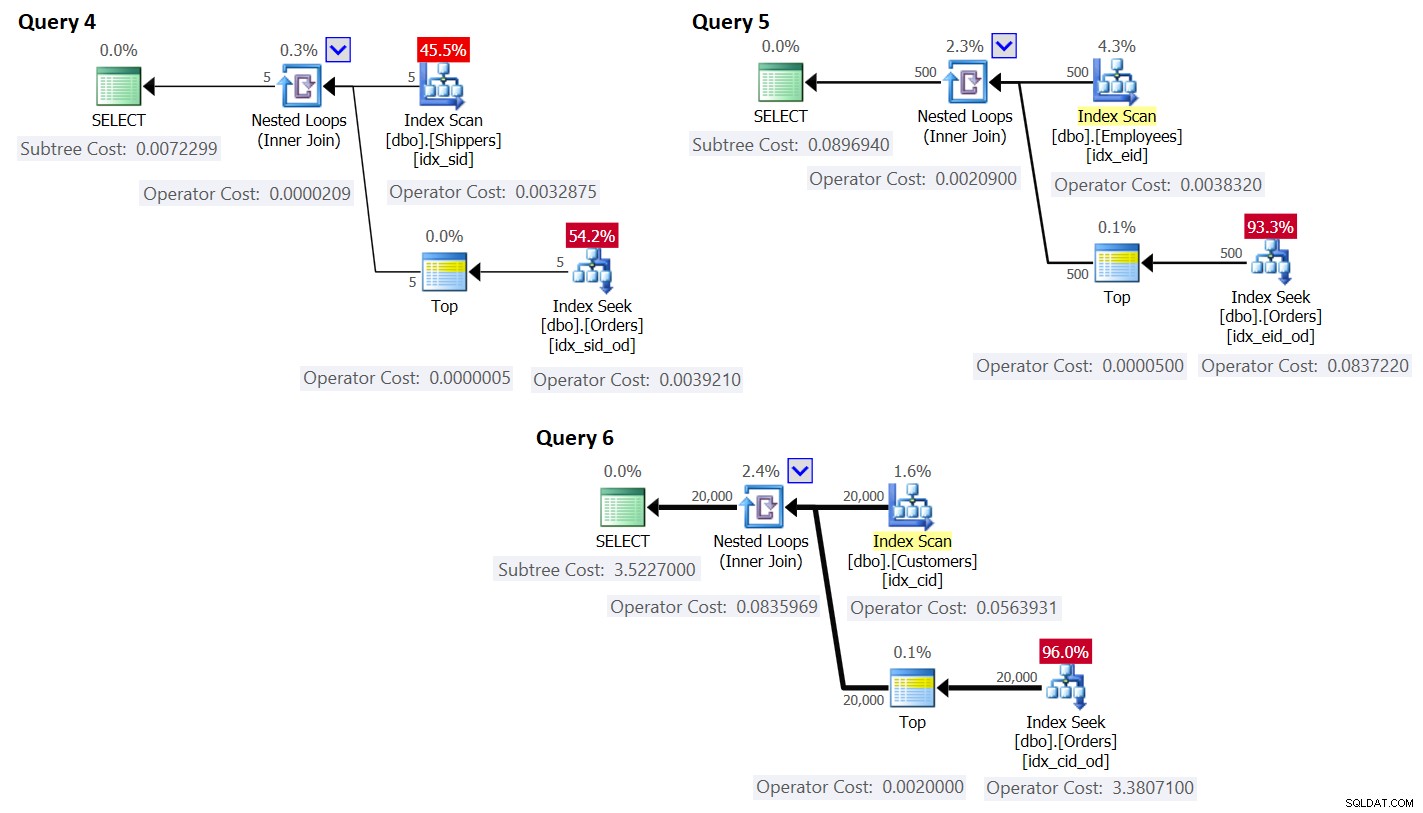 Figur 3:Planer för frågor med omskrivning
Figur 3:Planer för frågor med omskrivning
Som du kan se erhålls grupperna genom att skanna indexet på grupptabellen, och aggregatet erhålls genom att tillämpa en sökning i indexet på huvudtabellen. Ju högre densitet gruppuppsättningen har, desto mer optimal är denna plan jämfört med standardstrategin för den grupperade frågan.
Precis som vi gjorde tidigare för standardskanningsstrategin, låt oss uppskatta antalet logiska läsningar och planera kostnaden för sökstrategin. Det uppskattade antalet logiska läsningar är antalet läsningar för den enstaka exekveringen av Index Scan-operatorn som hämtar grupperna, plus läsningarna för alla exekveringar av Index Seek-operatorn.
Det uppskattade antalet logiska läsningar för Index Scan-operatören är försumbart jämfört med sökningarna; ändå är det CEILING(1e0 * @numgroups / @rowsperpage). Ta fråga 4 som ett exempel; säg att indexet idx_sid passar cirka 600 rader per bladsida (faktiskt antal beror på faktiska shipperid-värden eftersom datatypen är VARCHAR(5)). Med 5 grupper passar alla rader på en enda bladsida. Om du hade 5 000 grupper skulle de rymmas på 9 sidor.
Det uppskattade antalet logiska läsningar för alla körningar av indexsökoperatorn är @numgroups * @indexdepth. Indexets djup kan beräknas som:
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
Med hjälp av fråga 4 som ett exempel, säg att vi får plats med cirka 404 rader per bladsida i indexet idx_sid_od och cirka 352 rader per icke-bladsida. Återigen kommer de faktiska siffrorna att bero på faktiska värden som lagras i shipperid-kolumnen eftersom dess datatyp är VARCHAR(5)). För uppskattningar, kom ihåg att du kan använda de beräkningar som beskrivs här. Med bra representativ exempeldata tillgänglig kan du använda följande fråga för att ta reda på antalet rader som får plats på blad- och icke-bladsidorna i det givna indexet:
SELECT CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype, FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage FROM (SELECT * FROM sys.indexes WHERE object_id =OBJECT_ID =OBJECT_ID =2) ('dbo.Orders') AND name ='idx_sid_od') AS I CROSS APPLY sys.dm_db_index_physical_stats (DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P WHERE P.index_level <=1; Jag fick följande utdata:
pagetype rowsperpage -------- ---------------------------- leaf 404 nonleaf 352
Med dessa siffror är indexets djup med avseende på antalet rader i tabellen:
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
Med 1 000 000 rader i tabellen ger detta ett indexdjup på 3. Vid cirka 50 miljoner rader ökar indexdjupet till 4 nivåer och vid cirka 17,62 miljarder rader ökar det till 5 nivåer.
Hur som helst, med avseende på antalet grupper och antalet rader, med antagande av ovanstående antal rader per sida, beräknar följande formel det uppskattade antalet logiska läsningar för fråga 4:
CEILING(1e0 * @numrows / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
Till exempel, med 5 grupper och 1 000 000 rader får du bara 16 läsningar totalt! Kom ihåg att den standardskanningsbaserade strategin för den grupperade frågan innefattar lika många logiska läsningar som CEILING(1e0 * @numrows / @rowsperpage). Om du använder fråga 1 som ett exempel och antar cirka 404 rader per bladsida av indexet idx_sid_od, med samma antal rader på 1 000 000, får du cirka 2 476 läsningar. Öka antalet rader i tabellen med en faktor på 1 000 till 1 000 000 000, men håll antalet grupper fast. Antalet läsningar som krävs med sökstrategin ändras mycket lite till 21, medan antalet läsningar som krävs med skanningsstrategin ökar linjärt till 2 475 248.
Det fina med seeks-strategin är att så länge som antalet grupper är litet och fast, har den nästan konstant skalning med avseende på antalet rader i tabellen. Det beror på att antalet sökningar bestäms av antalet grupper, och indexets djup relaterar till antalet rader i tabellen på ett logaritmiskt sätt där loggbasen är antalet rader som får plats på en icke-bladig sida. Omvänt har den skanningsbaserade strategin linjär skalning med avseende på antalet involverade rader.
Figur 4 visar antalet läsningar uppskattat för de två strategierna, tillämpade av fråga 1 och fråga 4, givet ett fast antal grupper om 5, och olika antal rader i huvudtabellen.
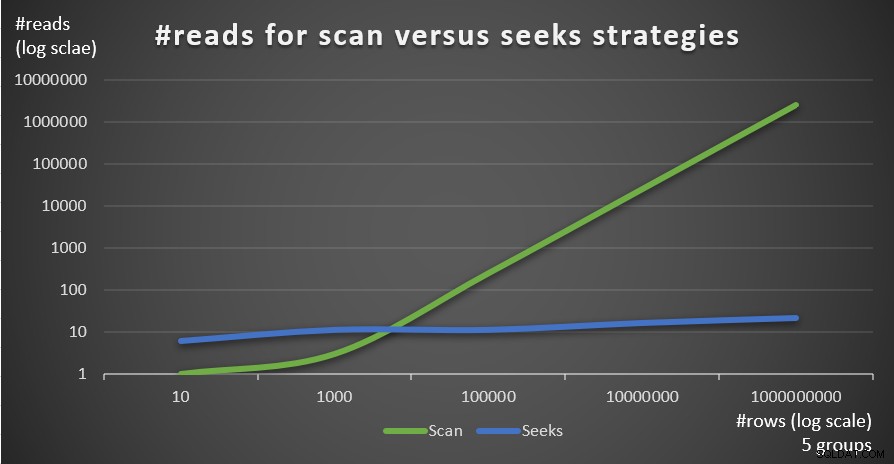 Figur 4:#reads för scan kontra söker strategier (5 grupper)
Figur 4:#reads för scan kontra söker strategier (5 grupper)
Figur 5 visar antalet avläsningar uppskattat för de två strategierna, givet ett fast antal rader på 1 000 000 i huvudtabellen och olika antal grupper.
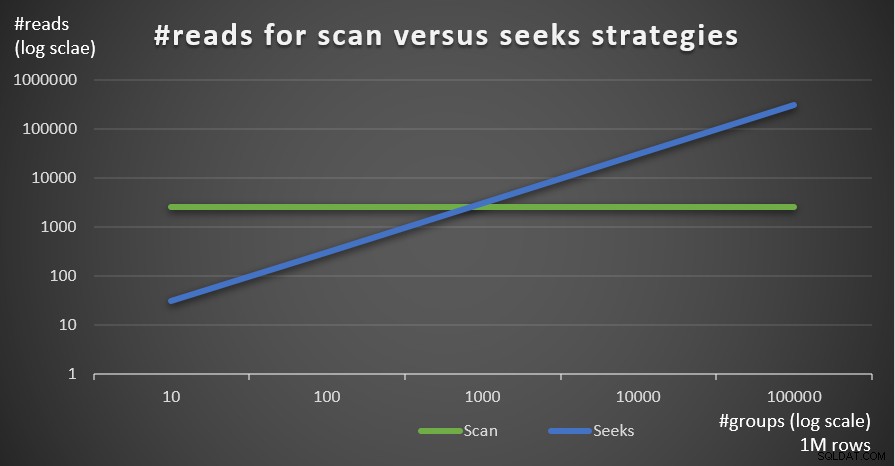 Figur 5:#reads för genomsökning kontra sökstrategier (1 miljoner rader)
Figur 5:#reads för genomsökning kontra sökstrategier (1 miljoner rader)
Du kan mycket tydligt se att ju högre densitet gruppuppsättningen har (mindre antal grupper) och ju större huvudtabellen är, desto mer föredras sökstrategin vad gäller antalet läsningar. Om du undrar över I/O-mönstret som används av varje strategi; visst, indexsökningsoperationer utför slumpmässig I/O, medan en indexavsökning utför sekventiell I/O. Ändå är det ganska tydligt vilken strategi som är mer optimal i de mer extrema fallen.
När det gäller kostnaden för frågeplanen, återigen, med hjälp av planen för fråga 4 i figur 3 som exempel, låt oss dela upp den till de individuella operatörerna i planen.
Den omvända formeln för kostnaden för Index Scan-operatören är:
0,002541259259259 + @numpages * 0,000740740740741 + @numgroups * 0,0000011
I vårt fall, med 5 grupper, som alla ryms på en sida, är kostnaden:
0,002541259259259 + 1 * 0,000740740740741 + 5 * 0,0000011 =0,0032875
Kostnaden som visas i planen är densamma.
Som tidigare kan du uppskatta antalet sidor i indexets bladnivå baserat på det uppskattade antalet rader per sida med formeln CEILING(1e0 * @numrows / @rowsperpage), som i vårt fall är CEILING(1e0 * @ numgroups / @groupsperpage). Säg att indexet idx_sid passar cirka 600 rader per bladsida, med 5 grupper som du skulle behöva läsa en sida. I vilket fall som helst blir kostnadsformeln för Index Scan-operatören då:
0,002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011
Den omvända kostnadsformeln för Nested Loops-operatören är:
@executions * 0,00000418
I vårt fall översätts detta till:
@numgroups * 0,00000418
För fråga 4, med 5 grupper, får du:
5 * 0,00000418 =0,0000209
Kostnaden som visas i planen är densamma.
Den omvända kostnadsformeln för Top-operatören är:
@executions * @toprows * 0,00000001
I vårt fall översätts detta till:
@numgroups * 1 * 0,00000001
Med 5 grupper får du:
5 * 0,0000001 =0,0000005
Kostnaden som visas i planen är densamma.
När det gäller operatören Index Seek, här fick jag stor hjälp av Paul White; tack min vän! Beräkningen är annorlunda för den första exekveringen och för återbindningarna (icke-första exekveringen som inte återanvänder den tidigare exekveringens resultat). Som vi gjorde med Index Scan-operatorn, låt oss börja med att identifiera kostnadsmodellens konstanter:
@randomio =0,003125 -- Slumpmässig I/O-kostnad @seqio =0,000740740740741 -- Sekventiell I/O-kostnad @cpubase =0,000157 -- CPU-baskostnad @cpurow =0,0000011 -- CPU-kostnad per rad
För en exekvering, utan ett radmål tillämpat, är I/O- och CPU-kostnaderna:
I/O-kostnad:@randomio + (@numpages - 1e0) * @seqio =0,002384259259259 + @numpages * 0,000740740740741CPU-kostnad:@cpubase + @numrows * @cpurow =5,07 +0 s 0,0sEftersom vi använder TOP (1) har vi bara en sida och en rad inblandade, så kostnaderna är:
I/O-kostnad:0,002384259259259 + 1 * 0,000740740740741 =0,003125CPU-kostnad:0,000157 + 1 * 0,0000011 =0,0001581Så kostnaden för den första exekveringen av Index Seek-operatören i vårt fall är:
@firstexecution =0,003125 + 0,0001581 =0,0032831När det gäller kostnaden för återbindningarna, som vanligt, är den gjord av CPU- och I/O-kostnader. Låt oss kalla dem @rebindcpu respektive @rebindio. Med fråga 4, med 5 grupper, har vi 4 rebinds (kalla det @rebinds). @rebindcpu-kostnaden är den enkla delen. Formeln är:
@rebindcpu =@rebinds * (@cpubase + @cpurow)I vårt fall översätts detta till:
@rebindcpu =4 * (0,000157 + 0,0000011) =0,0006324@rebindio-delen är något mer komplex. Här beräknar kostnadsformeln, statistiskt, det förväntade antalet distinkta sidor som återbindningarna förväntas läsa med hjälp av sampling med ersättning. Vi kallar det här elementet @pswr (för distinkta sidor med sampling med ersättning). Tanken är att vi har @indexdatapages antal sidor i indexet (i vårt fall 2 473) och @rebinds antal rebinds (i vårt fall 4). Om vi antar att vi har samma sannolikhet att läsa vilken sida som helst med varje ombindning, hur många distinkta sidor förväntas vi läsa totalt? Detta är som att ha en påse med 2 473 bollar och fyra gånger blint dra en boll från påsen och sedan återföra den till påsen. Statistiskt sett, hur många distinkta bollar förväntas du dra totalt? Formeln för detta, med hjälp av våra operander, är:
@pswr =@indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))Med våra nummer får du:
@pswr =2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) =3,99757445099277Därefter beräknar du antalet rader och sidor du har i genomsnitt per grupp:
@grouprows =@cardinality * @density@grouppages =CEILING(@indexdatapages * @density)I vår fråga 4 är kardinaliteten 1 000 000 och densiteten är 1/5 =0,2. Så du får:
@grouprows =1000000 * 0,2 =200000@numpages =CEILING(2473 * 0,2) =495Sedan beräknar du I/O-kostnaden utan filtrering (kalla det @io) som:
@io =@randomio + (@seqio * (@grouppages - 1e0))I vårt fall får du:
@io =0,003125 + (0,000740740740741 * (495 - 1e0)) =0,369050925926054Och slutligen, eftersom sökningen bara extraherar en rad i varje ombindning, beräknar du @rebindio med följande formel:
@rebindio =(1e0 / @grouprows) * ((@pswr - 1e0) * @io)I vårt fall får du:
@rebindio =(1e0 / 200000) * ((3,99757445099277 - 1e0) * 0,369050925926054) =0,000005531288Slutligen är operatörens kostnad:
Operatorkostnad:@firstexecution + @rebindcpu + @rebindio =0,0032831 + 0,0006324 + 0,000005531288 =0,003921031288Detta är samma som Index Seek-operatörens kostnad som visas i planen för fråga 4.
Du kan nu aggregera kostnaderna för alla operatörer för att få den fullständiga kostnaden för frågeplanen. Du får:
Query Plan Kostnad:0.002541259259259 + Tak (1E0 * @NumGroups / @GroupSperPage) * 0.000740740740741 + @numgroups * 0.0000011 + @numgroups * 0.00000418 + @NumGroups * @numgroups * 0.0000011 + @numgroups * 0.00000418 + @NumGroups * @numgroups * 0.0000011 + @numgroups * 0.00000418 + @numgrupper * / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage) * (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @ rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0,000740740740741 * (CEILING((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))Efter förenkling får du följande kompletta kostnadsformel för vår Seeks-strategi:
0,005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @numgroups * 0,000016229 + (groupsrow @numerrows) /sidad @numer/s) (groups/s) @numerrows) ) * (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0,0007407407 (4007407) * CEILING((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))Som ett exempel, med T-SQL, här är beräkningen av frågeplanskostnaden med vår Seeks-strategi för fråga 4:
DEKLARE @numrows AS FLOAT =1000000, @numgroups AS FLOAT =5, @rowsperpage AS FLOAT =404, @groupsperpage AS FLOAT =600; VÄLJ 0,005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @numgroups * 0,00016229 + (rader @numer/s) /sid @0016229 + (rader @01s) /sid(rad) @numerier) (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0,0007407407407ING(407407) (@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0))) AS seeksplancost;Denna beräkning beräknar kostnaden 0,0072295 för fråga 4. Den uppskattade kostnaden som visas i figur 3 är 0,0072299. Det är ganska nära! Som en övning, beräkna kostnaderna för fråga 5 och fråga 6 med den här formeln och verifiera att du får siffror nära de som visas i figur 3.
Kom ihåg att kostnadsformeln för den standardskanningsbaserade strategin är (kalla den Scan strategi):
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numrows * 0,0000005Med hjälp av fråga 1 som ett exempel, och om man antar 1 000 000 rader i tabellen, 404 rader per sida och 5 grupper, är den uppskattade frågeplanskostnaden för skanningsstrategin 3,5366.
Figur 6 visar de beräknade frågeplanskostnaderna för de två strategierna, tillämpade av fråga 1 (skanning) och fråga 4 (söker), givet ett fast antal grupper om 5 och olika antal rader i huvudtabellen.
Figur 6:kostnad för scan kontra sökstrategier (5 grupper)
Figur 7 visar de uppskattade frågeplanskostnaderna för de två strategierna, givet ett fast antal rader i huvudtabellen på 1 000 000 och olika antal grupper.
Figur 7:kostnad för scan kontra sökstrategier (1M rader)
Som framgår av dessa fynd, ju högre gruppuppsättningstätheten och ju fler rader i huvudtabellen är, desto mer optimal är sökstrategin jämfört med skanningsstrategin. Så, i scenarier med hög densitet, se till att du provar den APPLY-baserade lösningen. Under tiden kan vi hoppas att Microsoft lägger till denna strategi som ett inbyggt alternativ för grupperade frågor.
Slutsats
Den här artikeln avslutar en serie i fem delar om frågeoptimeringströsklar för frågor som grupperar och samlar data. Ett mål med serien var att diskutera detaljerna för de olika algoritmerna som optimeraren kan använda, villkoren under vilka varje algoritm är att föredra och när du bör ingripa med dina egna frågeomskrivningar. Ett annat mål var att förklara processen för att upptäcka de olika alternativen och jämföra dem. Uppenbarligen kan samma analysprocess tillämpas på filtrering, sammanfogning, fönsterbildning och många andra aspekter av frågeoptimering. Förhoppningsvis känner du dig nu mer rustad för att hantera sökfrågor än tidigare.