I mitt förra inlägg visade jag några effektiva tillvägagångssätt för grupperad sammankoppling. Den här gången ville jag prata om ett par ytterligare aspekter av det här problemet som vi enkelt kan åstadkomma med FOR XML PATH tillvägagångssätt:sortera listan och ta bort dubbletter.
Det finns några sätt som jag har sett att folk vill att den kommaseparerade listan ska beställas. Ibland vill de att objektet i listan ska ordnas i alfabetisk ordning; Det visade jag redan i mitt förra inlägg. Men ibland vill de att det sorteras efter något annat attribut som faktiskt inte introduceras i utdata; till exempel kanske jag vill beställa listan efter senaste artikel först. Låt oss ta ett enkelt exempel, där vi har ett bord för anställda och ett kaffeorderbord. Låt oss bara fylla i en persons beställningar under några dagar:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Om vi använder den befintliga metoden utan att ange en ORDER BY , får vi en godtycklig ordning (i det här fallet är det mest troligt att du ser raderna i den ordning de infogades, men är inte beroende av det med större datamängder, fler index etc.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultat (kom ihåg att du kan få *annorlunda* resultat om du inte anger en ORDER BY ):
Jack | Stor dubbel dubbel, Medium dubbel dubbel, Large Vanilla Latte, Medium dubbel dubbel
Om vi vill ordna listan alfabetiskt är det enkelt; vi lägger bara till ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultat:
Namn | BeställningarJack | Stor dubbel dubbel, Stor Vanilla Latte, Medium dubbel dubbel, Medium dubbel dubbel
Vi kan också sortera efter en kolumn som inte visas i resultatuppsättningen; till exempel kan vi beställa efter senaste kaffebeställning först:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultat:
Namn | BeställningarJack | Medium dubbel dubbel, Large Vanilla Latte, Medium dubbel dubbel, Stor dubbel dubbel
En annan sak vi ofta vill göra är att ta bort dubbletter; det finns trots allt liten anledning att se "Medium double double" två gånger. Vi kan eliminera det genom att använda GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Nu *händer* detta för att ordna utdata i alfabetisk ordning, men återigen kan du inte lita på detta:
Namn | BeställningarJack | Stor dubbel dubbel, stor vanilj latte, medium dubbel dubbel
Om du vill garantera att du beställer på detta sätt kan du helt enkelt lägga till en BESTÄLLNING AV igen:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultaten är desamma (men jag upprepar, detta är bara en slump i det här fallet; om du vill ha den här ordningen, säg alltid det):
Namn | BeställningarJack | Stor dubbel dubbel, stor vanilj latte, medium dubbel dubbel
Men vad händer om vi vill eliminera dubbletter *och* sortera listan efter senaste kaffebeställning först? Din första böjelse kan vara att behålla GROUP BY och ändra bara ORDER BY , så här:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Det kommer inte att fungera, eftersom OrderDate är inte grupperad eller aggregerad som en del av frågan:
Kolumnen "dbo.CoffeeOrders.OrderDate" är ogiltig i ORDER BY-satsen eftersom den inte finns i vare sig en aggregatfunktion eller GROUP BY-satsen.
En lösning, som visserligen gör frågan lite fulare, är att först gruppera beställningarna separat och sedan bara ta raderna med maxdatum för den kaffebeställningen per anställd:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultat:
Namn | BeställningarJack | Medium dubbel dubbel, stor vanilj latte, stor dubbel dubbel
Detta uppnår båda våra mål:vi har eliminerat dubbletter och vi har sorterat listan efter något som faktiskt inte finns i listan.
Prestanda
Du kanske undrar hur dåligt dessa metoder fungerar mot en mer robust datamängd. Jag kommer att fylla vår tabell med 100 000 rader, se hur de klarar sig utan några ytterligare index och sedan köra samma frågor igen med lite indexjustering för att stödja våra frågor. Så först, få 100 000 rader fördelade på 1 000 anställda:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Låt oss nu bara köra var och en av våra frågor två gånger och se hur tajmingen är vid det andra försöket (vi tar ett steg i tro här och antar att vi – i en idealisk värld – kommer att arbeta med en förberedd cache ). Jag körde dessa i SQL Sentry Plan Explorer, eftersom det är det enklaste sättet jag känner till att tajma och jämföra en massa individuella frågor:
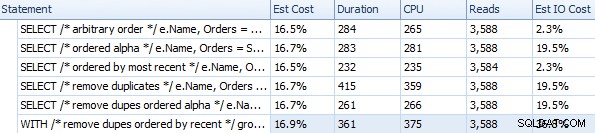 Längd och andra körtidsmått för olika FOR XML PATH-metoder
Längd och andra körtidsmått för olika FOR XML PATH-metoder
Dessa timings (varaktigheten är i millisekunder) är verkligen inte så dåliga alls IMHO, när du tänker på vad som faktiskt görs här. Den mest komplicerade planen, åtminstone visuellt, verkade vara den där vi tog bort dubbletter och sorterade efter senaste ordning:
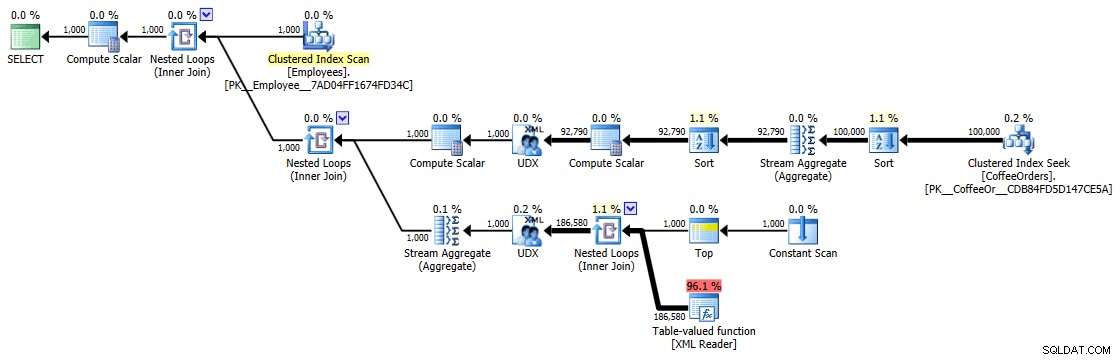 Exekutivplan för grupperad och sorterad fråga
Exekutivplan för grupperad och sorterad fråga
Men även den dyraste operatören här – den XML-tabellvärderade funktionen – verkar vara helt och hållet CPU (även om jag fritt kommer att erkänna att jag inte är säker på hur mycket av det faktiska arbetet som exponeras i frågeplansdetaljerna):
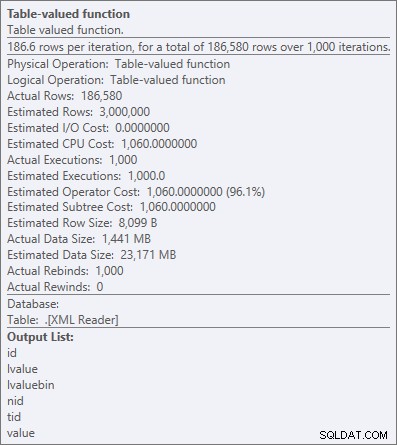 Operatoregenskaper för den XML-tabellvärderade funktionen
Operatoregenskaper för den XML-tabellvärderade funktionen
"All CPU" är vanligtvis okej, eftersom de flesta system är I/O-bundna och/eller minnesbundna, inte CPU-bundna. Som jag säger ganska ofta, i de flesta system kommer jag att byta ut en del av mitt CPU-utrymme mot minne eller disk vilken dag i veckan som helst (en av anledningarna till att jag gillar OPTION (RECOMPILE) som en lösning på genomgripande parametersniffningsproblem).
Som sagt, jag uppmuntrar dig starkt att testa dessa tillvägagångssätt mot liknande resultat som du kan få från GROUP_CONCAT CLR-metoden på CodePlex, såväl som att utföra aggregeringen och sorteringen på presentationsnivån (särskilt om du behåller normaliserade data på något sätt av cachelagret).