Att organisera ett event är mycket jobb! I den här artikeln undersöker vi datamodellen bakom en app för evenemangsorganisation.
Om du någonsin har försökt organisera ett evenemang för mer än tio personer (och räkna inte med fester eller affärsmöten här) vet du hur komplicerat evenemangshantering kan vara! Har vi bjudit in alla? Har de bekräftat om de kommer? Är lokalen bokad och förberedd? Vem är värd för evenemanget? Vilka kommer att delta i de olika delarna? Det finns många andra frågor att besvara, och saker kan lätt gå fel.
Du kan göra all din planering med papper och penna, men varför inte använda en app? Det är bekvämare! Alla appar kommer att behöva en plats för att lagra all nödvändig händelseinformation. Det är här vår datamodell för händelsehantering kommer in i den här historien. Ta en kaffe, sätt dig i din favoritstol, så tittar vi på vad som krävs för att bygga en datamodell för eventhantering.
Vanliga frågor om eventhantering
Innan vi förklarar modellen och beskriver hur vi lagrar data, låt oss först gå igenom några grunder för händelsehantering:
-
Vad kan anses vara en händelse?
I detta sammanhang är ett event ett tillfälle där många människor, som ofta inte känner varandra, samlas för att lära sig om eller delta i något. Några populära evenemang är musikfestivaler eller konserter, IT-konferenser, sportevenemang som fotbollsspel, hälso- och sjukvårdskonferenser, etc.
-
Vad har alla evenemang gemensamt?
De tidigare nämnda evenemangsexemplen är mycket olika vad gäller innehåll, syfte och målgrupp. Ändå delar de många likheter, särskilt i sin organisation.
Tänk först på händelsens innehåll. Vissa evenemang (t.ex. en konsert eller en fotbollsmatch) tillhandahåller endast en typ av innehåll och kommer att hållas på ett ställe. Andra händelser inkluderar många olika men relaterade "delhändelser", som kan inträffa på olika platser.
Ta en IT-konferens som ett exempel på den andra typen av evenemang. Det finns föreläsningar, presentationer, workshops och tävlingar. Deltagarna kommer förmodligen att gå från rum till rum eller kanske till och med resa mellan olika byggnader när de går till olika delevenemang. Vissa av dessa underhändelser kommer att köras samtidigt, men varje underhändelse är fortfarande relaterad till IT och har en eller flera värdar.
-
Vad krävs för att göra ett evenemang framgångsrikt?
Först och främst finns det många evenemangspersonal som arbetar hårt i bakgrunden:ljud- och bildtekniker, biljettförsäljare, vaktmästare, städ- och underhållsarbetare och administrativ personal. Många människor i många olika roller kommer att lägga många timmar på att arbeta hårt för att göra scenen redo för "stjärnorna" och andra deltagare, men ingen av dem kommer att få mycket erkännande.
Det är klart att alla evenemang kräver någon form av infrastruktur. Om vi håller en konferens på en fysisk plats kommer vi att prata om rum och sittplatser, ett ljudsystem, belysning, kanske video etc. Även ett onlineevenemang, som ett webbseminarium, måste ha en plats för att producera innehållet och IT-inställning behövs för att få kontakt med virtuella deltagare.
Evenemang har vanligtvis mediasponsorer och partners som hjälper till att organisera och marknadsföra dem. Dessa sponsorer är mestadels företag och föreningar relaterade till evenemangets ämne; ibland är de andra företag som letar efter bra publicitet; och mer sällan kommer en privatperson att fungera som sponsor eller partner.
-
Vad är event management?
Event management är en process som används för att effektivt hantera händelser och allt relaterat till dem. Det kan ses som en typ av projektledning. Vi diskuterade en datamodell för projektledning i den här artikeln. Att använda ett Gantt-diagram för att visa händelsens framsteg, nuvarande status och framtida åtgärder är ingen dålig idé.
Vi vill förmodligen att vår applikation för eventhantering ska passa på en skärm, om möjligt. De flesta åtgärder – som att skapa en ny show, tilldela anställda och resurser till en uppgift eller uppskatta kostnader – bör dra och släppa.
Datamodellen
Datamodellen består av tre huvudämnesområden:
Events and PartnersShows, Performers and EquipmentEmployees
Vi kommer att titta närmare på varje ämnesområde i den ordning de är listade.
Avsnitt 1:Evenemang och partners
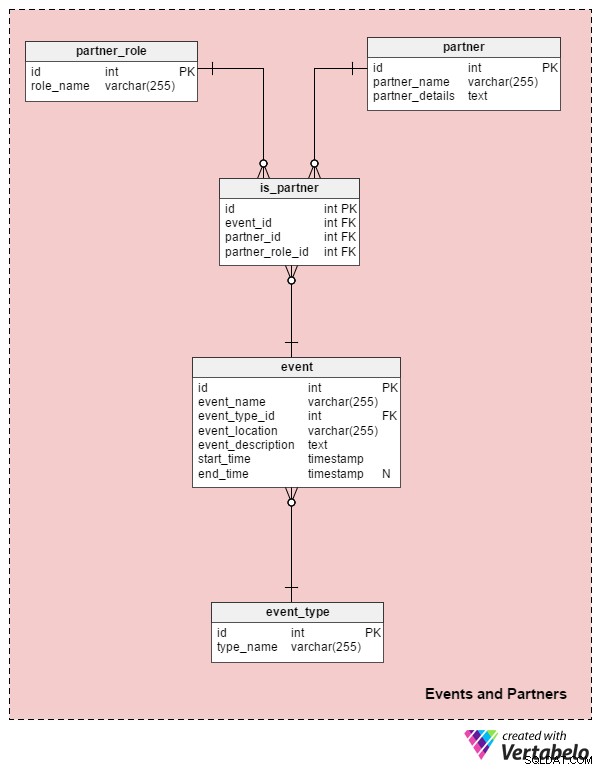
Events and Partners ämnesområde är den centrala delen av vår modell. I dessa fem tabeller kommer vi att lagra de viktigaste detaljerna om våra evenemang. Vi kommer också att relatera evenemang med partners.
Låt oss börja med event tabell. Det här listar alla evenemang vi har organiserat och alla evenemang vi planerar att anordna. Attributen i den här tabellen är:
event_name– Namnet på en händelse. Det är inte UNIKT eftersom vi kan ha två eller flera evenemang med samma namn – t.ex. en konsert av samma band skulle ha samma evenemangsnamn. Menevent_name–start_timeparet ska vara UNIKT.event_type_id– Refererar tillevent_typeordbok.event_location– Beskriver platsen där evenemanget kommer att äga rum. Genom att använda ett beskrivande attribut kan vi undvika att bygga en mer komplex modell med tabeller som "land" och "stad" och attribut som "adress" och "beskrivning".event_description– En detaljerad beskrivning av evenemanget och alla shower eller aktiviteter i samband med det. För en konsert är det här vi skulle lagra information om öppningsakten, huvudakten, eventuella ytterligare underhållare och föreställningsordningen.start_time– När evenemanget startar. Det är obligatoriskt eftersom vi borde veta detta i planeringsfasen.end_time– När evenemanget slutar. Vi skulle kunna använda det här attributet för att lagra den förväntade eller faktiska sluttiden för händelsen. Eftersom vi kanske inte vet den exakta tiden i förväg (t.ex. om en sportmatch går ut på övertid), är det här attributet valfritt.
event_type ordboken klassificerar de händelser vi hanterar. Vi lagrar alla möjliga typer av evenemang efter deras nisch:konsert, fotbollsmatch, basketmatch, IT-konferens, etc. Varje evenemangstyp definieras unikt av dess type_name .
Som vi tidigare nämnt har evenemang oftast partners. De flesta evenemang kommer att ha åtminstone en mediapartner, medan vissa även kommer att ha sponsorer och andra partners. Samma partner kan ha flera olika "partnerroller" på samma evenemang. Ett tv-bolag kan till exempel vara mediapartner och huvudsponsor för evenemanget samtidigt. Det är därför vi kommer att använda tre tabeller för att relatera händelser med partners.
Det är viktigt att kunna lägga till partners i planeringsfasen så att alla evenemangsintressenter kan få tillgång till den informationen i tid. Vi kan också använda tidigare data när vi planerar nya evenemang – t.ex. vi kan kontakta samma partner när vi organiserar ett återkommande evenemang eller ett nytt evenemang av samma typ. Om ett företag var generalsponsor för en teknisk konferens förra året kan de vara intresserade av att göra det igen i år.
Låt oss nu titta på de tre partnerskapstabellerna. Den första är partner katalog. För varje partner lagrar vi partner_name och deras adress, kontaktinformation och andra partner_details . Lägg märke till att partner_name attribut är inte unikt. Vi kan ha två partners med samma namn, till exempel två privatpersoner med samma för- och efternamn eller två företag med samma företagsnamn. I det här fallet kommer vi att skilja mellan dem med hjälp av informationen som lagras i partner_details attribut.
Den andra tabellen är partner_role ordbok, som listar alla olika roller en partner kan ha. role_name attribut kommer endast att innehålla UNIKA värden. Några förväntade rollnamn är "mediapartner", "allmän sponsor" och "sponsor".
Den sista tabellen i detta ämnesområde relaterar partners till evenemang. is_partner Tabellen innehåller endast främmande nycklar som relaterar partner till händelser och definierar roller eller partnerskapstyper. Kombinationen av dessa främmande nycklar bildar tabellens UNIKA nyckel. Om vi ville skulle vi kunna lägga till ett startdatum och ett slutdatum om någon partner bara fyller sin roll under en del av evenemanget. Vi skulle också kunna koppla partners till enstaka delevenemang och snarare än hela evenemang. Ändå är det relativt ovanliga situationer, så vi lämnar den här delen av modellen som den är.
Avsnitt 2:Shower, artister och utrustning
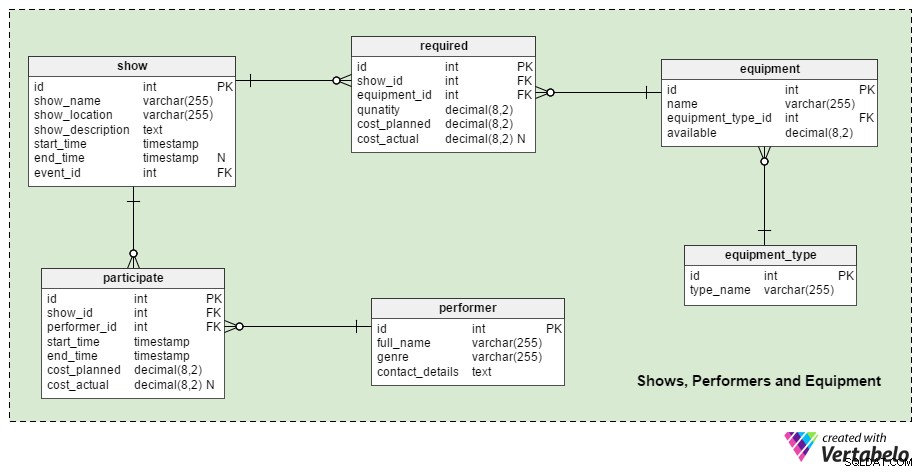
Som nämnts i inledningen kan varje evenemang ha flera delevenemang. I den här modellen har jag bestämt mig för att kalla delevenemangen för "shower". En show är en enskild delhändelse, fokuserad på ett ämne, med minst en artist, etc. I ett IT-konferensevenemang kan en show vara en föreläsning om projektledningsprinciper; en annan show kan vara en paneldiskussion om bästa praxis för datalagring. Båda kan äga rum samtidigt, på olika platser, och vara värdar av olika presentatörer. Vi kommer också att definiera allt som behövs för att köra en show, eftersom showen måste fortsätta (i alla fall ☺ ).
Den centrala tabellen i detta avsnitt är show tabell. Detta kommer att hålla ett register över alla program som är kopplade till tidigare, nuvarande och framtida händelser. När vi planerar ett evenemang måste vi lägga till nya shower så snart artisten (dvs. föreläsare, talare, presentatör, rockstjärna) har gått med på att vara en del av ett evenemang. Att titta på en beskrivning av tabellens attribut hjälper oss att förstå hur det fungerar:
show_name– Namnet på programmet.show_location– Beskriver var föreställningen kommer att äga rum.show_description– En detaljerad beskrivning av den showen.start_time– Den förväntade starttiden.end_time– Den förväntade sluttiden. Den kan vara NULL eftersom vi kan ange den faktiska sluttiden (när föreställningen är över) snarare än den förväntade sluttiden.event_id– Vilket evenemang showen är en del av.
I de flesta fall kommer shower att kräva utrustning och artister. (Teoretiskt sett skulle vi kunna ha en show utan en artist, men vi kommer inte att bry oss om det här.) Eftersom utrustningen är begränsad är det viktigt att reservera allt som behövs i evenemangets planeringsfas. För att göra detta ordentligt måste vi veta vad som kommer att hända vid vilken tidpunkt. Till exempel, om vi har två projektorer och två program som kräver projektorer schemalagda för samma tid, kan vi inte lägga till en tredje projektor-krävande show för den tiden om vi inte skaffar mer utrustning. Det är den här typen av information vi måste ha i planeringsfasen.
Vi går vidare, vi har performer tabell. Det här är en enkel katalog över alla artister som vi har arbetat med eller kommer att arbeta med på alla evenemang. För varje artist lagrar vi deras full_name . Det kan vara namnet på ett band, en föreläsare, etc. genre attribut är här för att skilja mellan de olika typerna av artister – t.ex. rockband från skulptörer. Det sista attributet i den här tabellen lagrar artisternas contact_details . Vi kommer att använda textdatatypen för att lagra partiet, men vi kan också dela upp kontaktuppgifter i några separata fält.
Vi kommer att relatera shower och artister via participate tabell. Attributen i den här tabellen är:
show_idochperformer_id– Referenser till den relaterade showen och artisten. Det här paret kan vara en alternativ (unik) nyckel i tabellen men jag bestämde mig för att inte använda den; vi kanske har en artist att vara med i samma show vid två olika tidpunkter.start_timeochend_time– Exakt tider som definierar när den artisten var en del av den showen.cost_plannedochcost_actual– De kostnader/arvoden vi förväntar oss att betala en artist och vad vi faktiskt betalade dem.
De återstående tre tabellerna används för att definiera all utrustning som behövs för en show.
equipment_type ordboken kategoriserar utrustning. För en konsert kan dessa kategorier vara "ljusutrustning", "musikinstrument", "scenkonstruktion" etc. type_name attributet innehåller endast UNIKA värden.
equipment Tabellen beskriver utrustningsartiklar och kvantiteter. Dess name attribut definierar utrustningen mer specifikt än equipment_type .type_name . För en discoboll skulle dess "utrustning"."namn"-värde vara "discoball" men dess "utrustningstyp".."typ_namn" skulle vara "belysningsutrustning". Den available attribut definierar vilken kvantitet av artikeln som är tillgänglig för oss. Det är ett decimaltal eftersom vi kanske kommer att använda några "artiklar" som inte kan räknas upp, som vatten och el.
Den sista tabellen i detta avsnitt relaterar till utrustning och shower. Detta kan hjälpa oss att organisera utrustning i planeringsfasen; det gör det också möjligt för oss att skapa rapporter om utrustningskostnader senare. När vi planerar för utrustningsanvändning och kostnader kan denna information komma till stor nytta, särskilt för återkommande (eller mycket liknande) händelser. Attributen i required tabellen är:
show_idochequipment_id– Avser relaterade show och utrustning. Detta par bildar tabellens UNIKA nyckel.quantity– Mängden av den utrustningen som behövs.cost_plannedochcost_actual– Vad vi förväntar oss att betala för att installera eller hyra utrustning och vad vi faktiskt betalade.
Avsnitt 3:Anställda
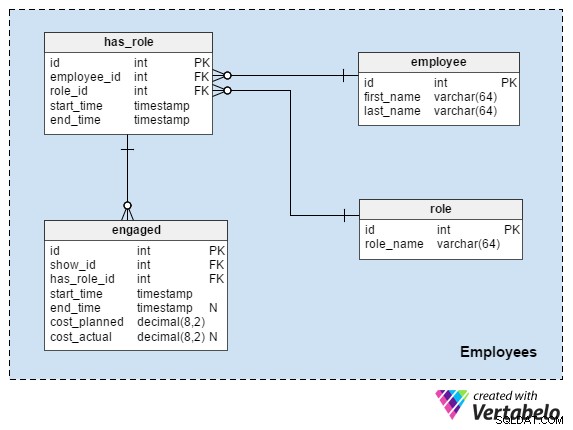
Ämnesområdet för denna modell handlar om anställda och deras roller. Jag älskar alltid att påpeka att människor och deras tid är den viktigaste delen av alla projekt. Allt annat är bara ett verktyg för att göra ett jobb. (Och det verktyget gjordes också av människor som använde sin tid. ☺ )
Jag kommer inte att förklara employee , role och has_role tabeller här. Jag har gjort det många gånger tidigare, till exempel i den här artikeln. Om du behöver, vänligen granska den.
Sluttabellen i vår modell relaterar anställda och roller med shower. Vi kan förvänta oss att ha ett begränsat antal kvalificerade medarbetare och vi måste vara säkra på att de kommer att finnas tillgängliga när det behövs. Uppenbarligen kan inte samma person vara på två olika platser samtidigt. Attributen i engaged tabellen är:
show_idochhas_role_id– Refererar till den relaterade showen och anställdsrollen.start_time– När vi förväntar oss att en anställd ska börja den rollen.end_time– När den rollen tar slut. Detta är nullbart eftersom vi i de flesta fall tilldelar ett värde efter att medarbetaren har avslutat sin roll. Däremot kan vi ange en förväntad sluttid här.cost_plannedochcost_actual– Vad vi förväntar oss att betala en anställd för att hantera den rollen och vad vi faktiskt betalade.
Än en gång vill jag bara påpeka att denna historiska information kan vara till stor hjälp när du organiserar ett upprepat evenemang eller ett som liknar ett tidigare evenemang.
Idag har vi diskuterat en möjlig datamodell för en evenemangshanteringsdatabas. Vi har täckt de riktigt viktiga sakerna, som att beskriva evenemanget, schemalägga artister och tilldela anställda och resurser till evenemanget. Hanteringen av kostnader i denna modell är förenklad, men den ger oss ändå möjlighet att beräkna planerade och faktiska kostnader per kategori, evenemang, show eller utrustningstyp.
Jag är inte evenemangsansvarig. Om du är det, hoppas jag att du har funnit den här artikeln till stor hjälp. Men jag skulle vilja höra din feedback om vilka tillägg eller ändringar som kan vara användbara i verkliga situationer.
Naturligtvis är alla välkomna att lämna in sina förslag och idéer i kommentarsfältet.