När användare begär data från ett system, gillar de vanligtvis att se dem i en specifik ordning... även när de returnerar tusentals rader. Som många DBA:er och utvecklare vet kan ORDER BY introducera kaos i en frågeplan, eftersom det kräver att data sorteras. Detta kan ibland kräva en SORT-operatör som en del av exekveringen av en fråga, vilket kan vara en kostsam operation, särskilt om uppskattningar är avstängda och det spills till disken. I en idealisk värld sorteras data redan tack vare ett index (index och sorteringar är mycket komplementära). Vi pratar ofta om att skapa ett täckande index för att tillfredsställa en fråga – så att optimeraren inte behöver gå tillbaka till bastabellen eller klustrade index för att få ytterligare kolumner. Och du kanske har hört folk säga att ordningen på kolumnerna i indexet har betydelse. Har du någonsin funderat på hur det påverkar din SORT-verksamhet?
Undersök ORDER BY och sorteringar
Vi börjar med en ny kopia av AdventureWorks2014-databasen på en SQL Server 2014-instans (version 12.0.2000). Om vi kör en enkel SELECT-fråga mot Sales.SalesOrderHeader utan ORDER BY, ser vi en vanlig gammal Clustered Index Scan (med SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Fråga utan ORDER BY, klustrad indexskanning
Fråga utan ORDER BY, klustrad indexskanning
Låt oss nu lägga till en BESTÄLLNING AV för att se hur planen förändras:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
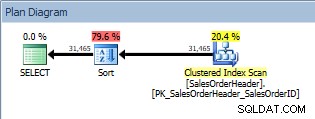 Fråga med en ORDER BY, klustrad indexskanning och en sortering
Fråga med en ORDER BY, klustrad indexskanning och en sortering
Förutom Clustered Index Scan har vi nu en Sortering som introducerats av optimeraren, och dess uppskattade kostnad är betydligt högre än skanningen. Nu är den uppskattade kostnaden bara uppskattad, och vi kan inte säga med absolut säkerhet här att Sort tog 79,6% av kostnaden för frågan. För att verkligen förstå hur dyr sorten är, skulle vi behöva titta på IO STATISTICS också, vilket är bortom dagens mål.
Om detta nu var en fråga som kördes ofta i din miljö, skulle du förmodligen överväga att lägga till ett index för att stödja det. I det här fallet finns det ingen WHERE-sats, vi hämtar bara fyra kolumner och sorterar efter en av dem. Ett logiskt första försök till ett index skulle vara:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Vi kör vår fråga igen efter att ha lagt till indexet som har alla kolumner vi vill ha, och kom ihåg att indexet har gjort jobbet för att sortera data. Vi ser nu en Index Scan mot vårt nya icke-klustrade index:
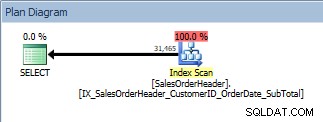 Fråga med en ORDER BY, det nya, icke-klustrade indexet skannas
Fråga med en ORDER BY, det nya, icke-klustrade indexet skannas
Det här är goda nyheter. Men vad händer om någon ändrar den frågan – antingen för att användare kan ange vilka kolumner de vill beställa efter eller för att en utvecklare begärde en ändring? Till exempel kanske användare vill se kund-ID och försäljningsorder-ID i fallande ordning:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
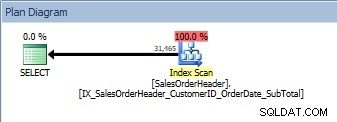 Fråga med två kolumner i ORDER BY, det nya, icke-klustrade indexet skannas
Fråga med två kolumner i ORDER BY, det nya, icke-klustrade indexet skannas
Vi har samma plan; ingen sorteringsoperator har lagts till. Om vi tittar på indexet med Kimberly Tripps sp_helpindex (vissa kolumner kollapsade för att spara utrymme), kan vi se varför planen inte ändrades:
 Utdata från sp_helpindex
Utdata från sp_helpindex
Nyckelkolumnen för indexet är CustomerID, men eftersom SalesOrderID är nyckelkolumnen för det klustrade indexet, är det också en del av indexnyckeln, sålunda sorteras data efter CustomerID, sedan SalesOrderID. Frågan begärde uppgifterna sorterade efter dessa två kolumner, i fallande ordning. Indexet skapades med båda kolumnerna stigande, men eftersom det är en dubbellänkad lista kan indexet läsas baklänges. Du kan se detta i fönstret Egenskaper i Management Studio för den icke-klustrade indexskanningsoperatorn:
 Egenskapsrutan för den icke-klustrade indexsökningen, som visar att den var bakåt
Egenskapsrutan för den icke-klustrade indexsökningen, som visar att den var bakåt
Bra, inga problem med den frågan...men vad sägs om den här:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
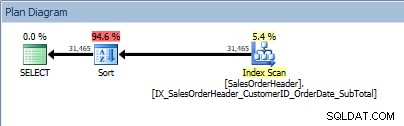 Fråga med två kolumner i ORDER BY, och en sortering läggs till
Fråga med två kolumner i ORDER BY, och en sortering läggs till
Vår SORT-operatör dyker upp igen, eftersom data som kommer från indexet inte sorteras i den ordning som efterfrågas. Vi kommer att se samma beteende om vi sorterar på en av de inkluderade kolumnerna:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
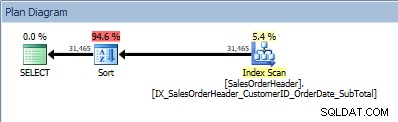 Fråga med två kolumner i ORDER BY och en sortering läggs till
Fråga med två kolumner i ORDER BY och en sortering läggs till
Vad händer om vi (äntligen) lägger till ett predikat och ändrar vår ORDNING MED något?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
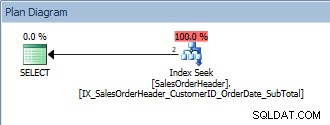 Fråga med ett enda predikat och ett ORDER BY
Fråga med ett enda predikat och ett ORDER BY
Den här frågan är ok eftersom återigen SalesOrderID är en del av indexnyckeln. För detta kund-ID är uppgifterna redan beställda av SalesOrderID. Vad händer om vi frågar efter en rad kund-ID, sorterade efter försäljningsorder-ID?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
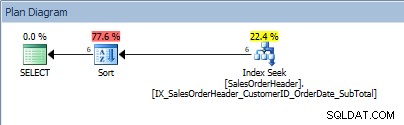 Fråga med ett värdeintervall i predikatet och en ORDER BY
Fråga med ett värdeintervall i predikatet och en ORDER BY
Råttor, vår SORT är tillbaka. Det faktum att data beställs av CustomerID hjälper bara att söka efter indexet för att hitta det värdeintervallet; för ORDER BY SalesOrderID måste optimeraren lägga in sorteringen för att placera data i den begärda ordningen.
Nu kanske du undrar varför jag är fixerad vid sorteringsoperatorn som visas i frågeplaner. Det är för att det är dyrt. Det kan vara dyrt i termer av resurser (minne, IO) och/eller varaktighet.
Frågans varaktighet kan påverkas av en sortering eftersom det är en stop-and-go-operation. Hela datauppsättningen måste sorteras innan nästa operation i planen kan ske. Om bara några rader med data måste beställas är det inte så stor sak. Om det är tusentals eller miljoner rader? Nu väntar vi.
Förutom den totala frågelängden måste vi också tänka på resursanvändning. Låt oss ta de 31 465 raderna vi har arbetat med och skjuta in dem i en tabellvariabel och kör sedan den första frågan med ORDER BY på kund-ID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
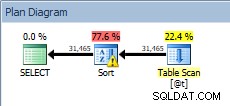 Fråga mot tabellvariabeln, med sorten
Fråga mot tabellvariabeln, med sorten
Vår SORT är tillbaka, och den här gången har den en varning (notera den gula triangeln med utropstecken). Varningar är inte bra. Om vi tittar på egenskaperna för den sorten kan vi se en varning, "Operatören använde tempdb för att spilla data under exekvering med spillnivå 1":
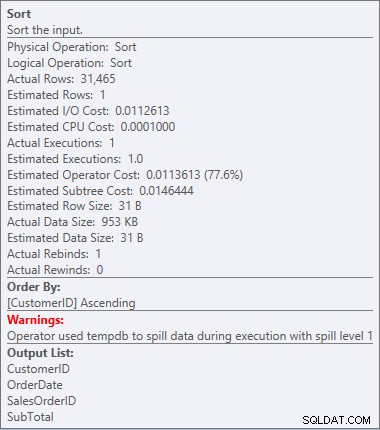 Sorteringsvarning
Sorteringsvarning
Det här är inget jag vill se i en plan. Optimeraren gjorde en uppskattning av hur mycket utrymme den skulle behöva i minnet för att sortera data, och den begärde det minnet. Men när den faktiskt hade all data och gick för att sortera den insåg motorn att det inte fanns tillräckligt med minne (optimeraren bad om för lite!), så sorteringsoperationen rann ut. I vissa fall kan detta spilla ut på disken, vilket innebär att läser och skriver - vilket är långsamt. Vi väntar inte bara på att få ordning på data, det går ännu långsammare eftersom vi inte kan göra allt i minnet. Varför bad inte optimeraren om tillräckligt med minne? Den hade en dålig uppskattning om vilken data den behövde för att sortera:
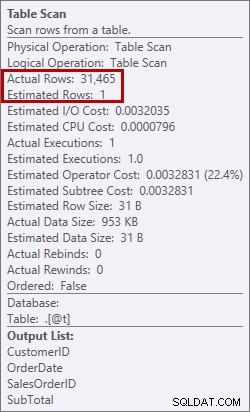 Uppskattning av 1 rad kontra faktiska 31 465 rader
Uppskattning av 1 rad kontra faktiska 31 465 rader
I det här fallet tvingade jag fram en dålig uppskattning genom att använda en tabellvariabel. Det finns kända problem med statistikuppskattningar och tabellvariabler (Aaron Bertrand har ett bra inlägg om alternativ för att försöka lösa detta), och här trodde optimeraren att bara en rad skulle returneras från tabellskanningen, inte 31 465.
Alternativ
Så vad kan du som DBA eller utvecklare göra för att undvika SORTERINGAR i dina frågeplaner? Det snabba svaret är "Beställ inte din data." Men det är inte alltid realistiskt. I vissa fall kan du överföra den sorteringen till klienten eller till ett applikationslager – men användare måste fortfarande vänta med att sortera data på det lager. I de situationer där du inte kan ändra hur programmet fungerar kan du börja med att titta på dina index.
Om du stöder en applikation som låter användare köra ad-hoc-förfrågningar eller ändra sorteringsordningen så att de kan se uppgifterna ordnade som de vill... kommer du att ha det svårast (men det är inte en förlorad sak så sluta inte läsa ännu!). Du kan inte indexera för varje alternativ. Det är ineffektivt och du kommer att skapa fler problem än du löser. Ditt bästa val här är att prata med användarna (jag vet, ibland är det läskigt att lämna ditt hörn av skogen, men ge det ett försök). För de frågor som användarna kör oftast, ta reda på hur de vanligtvis vill se data. Ja, du kan få detta från planens cache också – du kan hämta frågor och planer tills du är nöjd för att se vad de gör. Men det går snabbare att prata med användarna. Den extra fördelen är att du kan förklara varför du frågar, och varför den idén att "sortera på alla kolumner för att jag kan" inte är så bra. Att veta är halva striden. Om du kan lägga lite tid på att utbilda dina avancerade användare och användarna som utbildar nya människor, kanske du kan göra något nytta.
Om du stöder en applikation med begränsade ORDER BY-alternativ kan du göra en riktig analys. Granska vilka ORDER BY-varianter som finns, avgör vilka kombinationer som körs oftast och indexera för att stödja dessa frågor. Du kommer förmodligen inte att träffa alla, men du kan fortfarande påverka. Du kan ta det ett steg längre genom att prata med dina utvecklare och utbilda dem om problemet och hur man åtgärdar det.
Slutligen, när du tittar på frågeplaner med SORT-operationer, fokusera inte bara på att ta bort sorteringen. Titta på var sorteringen sker i planen. Om det händer långt till vänster om planen, och är vanligtvis några rader kan det finnas andra områden med en större förbättringsfaktor att fokusera på. Sorteringen till vänster är mönstret vi fokuserade på idag, men en sortering uppstår inte alltid på grund av en ORDER BY. Om du ser en Sortering längst till höger i planen och det finns många rader som rör sig genom den delen av planen, vet du att du har hittat ett bra ställe att börja ställa in.