Är SQL DISTINCT bra (eller dåligt) när du behöver ta bort dubbletter i resultat?
Vissa säger att det är bra och lägger till DISTINCT när dubbletter dyker upp. Vissa säger att det är dåligt och föreslår att man använder GROUP BY utan en aggregatfunktion. Andra säger att DISTINCT och GROUP BY är samma när du behöver ta bort dubbletter.
Det här inlägget kommer att dyka ner i detaljerna för att få korrekta svar. Så till slut kommer du att använda det bästa sökordet baserat på behovet. Låt oss börja.
En kort påminnelse om grunderna i SQL SELECT DISTINCT-satsen
Innan vi dyker djupare, låt oss komma ihåg vad SQL SELECT DISTINCT-satsen är. En databastabell kan innehålla dubbletter av värden av många anledningar, men vi kanske bara vill få de unika värdena. I det här fallet kommer SELECT DISTINCT till hands. Denna DISTINCT-sats gör att SELECT-satsen endast hämtar unika poster.
Syntaxen för uttalandet är enkel:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Här är WHERE-villkoret valfritt.
Uttalandet gäller både för en enstaka kolumn och flera kolumner. Syntaxen för denna sats som tillämpas på flera kolumner är följande:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Observera att scenariot med att fråga flera kolumner kommer att föreslå att du använder kombinationen av värden i alla kolumner som definieras av satsen för att bestämma unikheten.
Och nu, låt oss utforska den praktiska användningen och fångsterna för att tillämpa SELECT DISTINCT-satsen.
Hur SQL DISTINCT fungerar för att ta bort dubbletter
Att få svar är inte så svårt att hitta. SQL Server försåg oss med exekveringsplaner för att se hur en fråga kommer att bearbetas för att ge oss de nödvändiga resultaten.
Följande avsnitt fokuserar på utförandeplanen när du använder DISTINCT. Du måste trycka på Ctrl-M i SQL Server Management Studio innan du utför frågorna nedan. Eller klicka på Inkludera faktisk exekveringsplan från verktygsfältet.
Frågeplaner i SQL DISTINCT
Låt oss börja med att jämföra 2 frågor. Den första kommer inte att använda DISTINCT, och den andra frågan.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Här är genomförandeplanen:
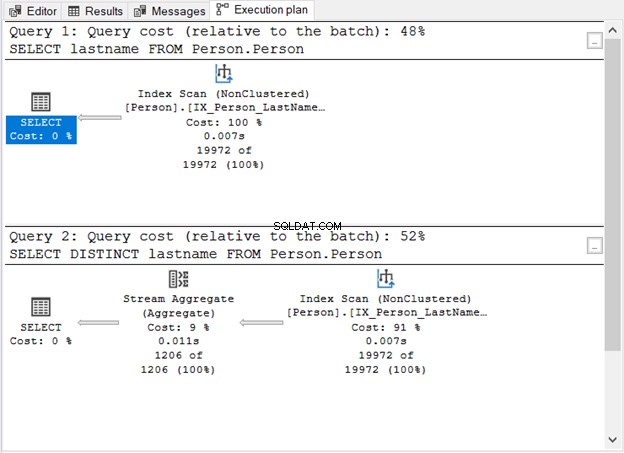
Vad visade bild 1 oss?
- Utan DISTINCT-sökordet är frågan enkel.
- Ett extra steg visas när du har lagt till DISTINCT.
- Frågekostnaden för att använda DISTINCT är högre än utan den.
- Båda har Index Scan-operatorer. Detta är förståeligt eftersom det inte finns någon specifik WHERE-klausul i våra frågor.
- Det extra steget, Stream Aggregate-operatorn, används för att ta bort dubbletterna.
Antalet logiska läsningar är detsamma (107) om du kontrollerar STATISTICS IO. Ändå är antalet rekord väldigt olika. 19 972 rader returneras av den första frågan. Under tiden returneras 1 206 rader av den andra frågan.
Därför kan du inte lägga till DISTINCT när du vill. Men om du behöver unika värden är detta en nödvändig overhead.
Det finns operatorer som används för att mata ut unika värden. Låt oss undersöka några av dem.
STRÖMASAMBALLAT
Det här är operatorn du såg i figur 1. Den accepterar en enda ingång och ger ett aggregerat resultat. I figur 1 kommer indata från Index Scan-operatören. Men Stream Aggregate behöver en sorterad indata.
Som du kan se i figur 1 använder den IX_Person_LastName_FirstName_MiddleName , ett icke-unikt register över namn. Eftersom indexet redan sorterar posterna efter namn, accepterar Stream Aggregate inmatningen. Utan indexet kan frågeoptimeraren välja att använda en extra sorteringsoperator i planen. Och det blir dyrare. Eller så kan den använda en Hash Match.
HASH MATCH (AGGREGAT)
En annan operatör som används av DISTINCT är Hash Match. Denna operator används för kopplingar och aggregering.
När du använder DISTINCT aggregerar Hash Match resultaten för att skapa unika värden. Här är ett exempel.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Och här är genomförandeplanen:
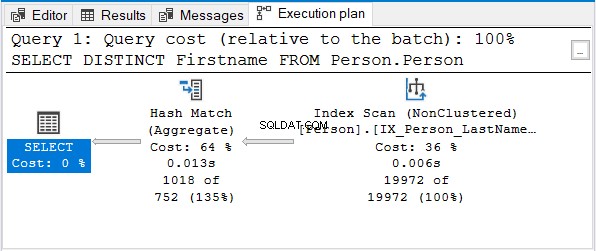
Men varför inte Stream Aggregate?
Observera att samma namnindex används. Det indexet sorteras med Efternamn först. Alltså ett Förnamn endast frågan blir osorterad.
Hash Match (Aggregate) är nästa logiska val för att ta bort dubbletterna.
HASH MATCH (FLÖDE DISTINKT)
Hash Match (Aggregate) är en blockerande operatör. Således kommer den inte att producera utdata som den har bearbetat hela ingångsströmmen. Om vi begränsar antalet rader (som att använda TOP med DISTINCT), kommer det att producera en unik utdata så snart dessa rader är tillgängliga. Det är vad Hash Match (Flow Distinct) handlar om.
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Frågan använder TOP 100 tillsammans med DISTINCT. Här är genomförandeplanen:
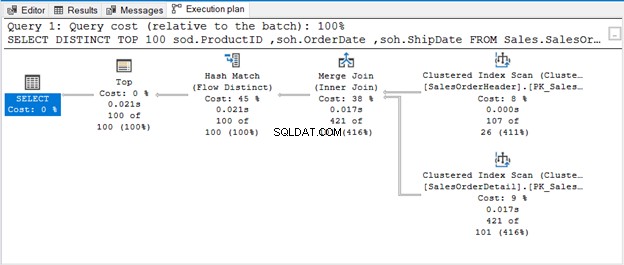
NÄR DET INTE FINNS INGEN OPERATÖR SOM TA BORT DUBLIKATTER
Japp. Detta kan hända. Betrakta exemplet nedan.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Kontrollera sedan genomförandeplanen:
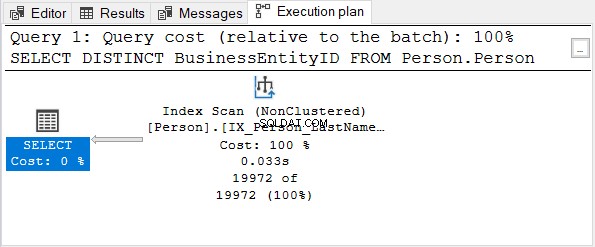
BusinessEntityID kolumn är den primära nyckeln. Eftersom den kolumnen redan är unik, finns det ingen anledning att använda DISTINCT. Försök att ta bort DISTINCT från SELECT-satsen – exekveringsplanen är densamma som i figur 4.
Detsamma gäller när du använder DISTINCT på kolumner med ett unikt index.
SQL DISTINCT fungerar på ALLA kolumner i SELECT-listan
Hittills har vi bara använt en kolumn i våra exempel. DISTINCT fungerar dock på ALLA kolumner du anger i SELECT-listan.
Här är ett exempel. Den här frågan kommer att se till att värdena för alla tre kolumnerna är unika.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Lägg märke till de första raderna i resultatuppsättningen i figur 5.
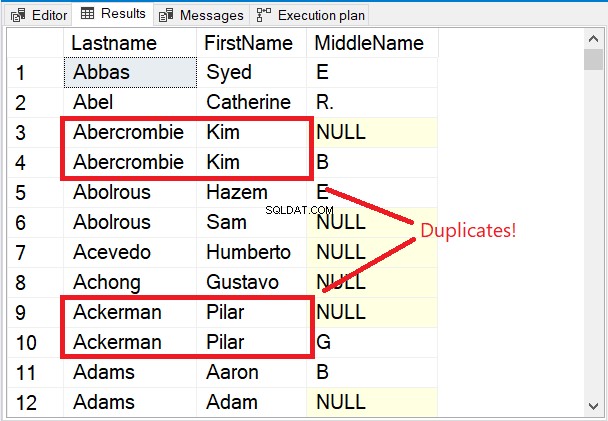
De första raderna är alla unika. Nyckelordet DISTINCT såg till att Mellannamnet kolumn beaktas också. Lägg märke till de två namnen i röd ruta. Med tanke på Efternamn och Förnamn kommer bara att göra dem dubbletter. Men lägger till Mellannamn till mixen förändrade allt.
Vad händer om du vill få unika för- och efternamn men ta med mellannamnet i resultatet?
Du har två alternativ:
- Lägg till en WHERE-sats för att ta bort NULL-mellannamn. Detta tar bort alla namn med ett NULL mellannamn.
- Eller lägg till en GROUP BY-sats på Efternamn och Förnamn kolumner. Använd sedan MIN-aggregationsfunktionen på Mellannamn kolumn. Detta kommer att få 1 mellannamn med samma efter- och förnamn.
SQL DISTINCT vs. GROUP BY
När du använder GROUP BY utan en aggregatfunktion fungerar den som DISTINCT. Hur vet vi? Ett sätt att ta reda på det är att använda ett exempel.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Kör dem och kolla in genomförandeplanen. Är det som skärmdumpen nedan?
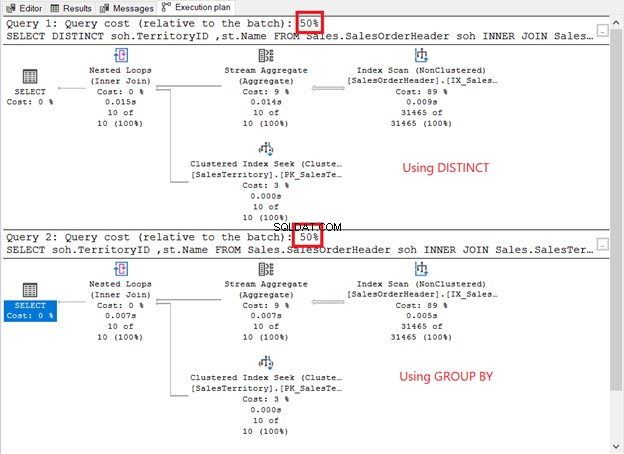
Hur jämför de?
- De har samma planoperatorer och sekvens.
- Operatörskostnaden för var och en och frågekostnaderna är desamma.
Om du markerar QueryPlanHash egenskaperna för de två SELECT-operatorerna är de samma. Därför använde frågeoptimeraren samma process för att returnera samma resultat.
I slutändan kan vi inte säga att det är bättre att använda GROUP BY än DISTINCT när det gäller att returnera unika värden. Du kan bevisa detta genom att använda exemplen ovan för att ersätta DISTINCT med GROUP BY.
Det är nu en fråga om preferenser vilken du ska använda. Jag föredrar DISTINCT. Det anger uttryckligen avsikten i frågan – att producera unika resultat. Och för mig är GROUP BY för att gruppera resultat med hjälp av en aggregerad funktion. Den avsikten är också tydlig och överensstämmer med själva sökordet. Jag vet inte om någon annan kommer att underhålla mina frågor en dag. Så koden bör vara tydlig.
Men det är inte slutet på historien.
När SQL DISTINCT inte är samma som GROUP BY
Jag uttryckte bara min åsikt, och sedan det här?
Det är sant. De kommer inte att vara desamma hela tiden. Tänk på det här exemplet.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Även om resultatuppsättningen är osorterad, är raderna desamma som i föregående exempel. Den enda skillnaden är användningen av en underfråga:
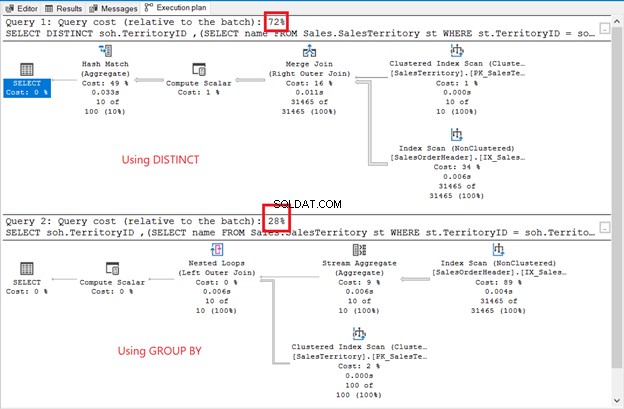
Skillnaderna är uppenbara:operatörer, frågekostnad, övergripande plan. Den här gången vinner GROUP BY med endast 28 % frågekostnad. Men här är grejen.
Syftet är att visa dig att de kan vara olika. Det är allt. Detta är inte på något sätt en rekommendation. Att använda en join har en bättre utförandeplan (se figur 6 igen).
The Bottomline
Här är vad vi har lärt oss hittills:
- DISTINCT lägger till en planoperatör för att ta bort dubbletter.
- DISTINCT och GROUP BY utan en aggregerad funktion resulterar i samma plan. Kort sagt, de är desamma för det mesta.
- Ibland kan DISTINCT och GROUP BY ha olika planer när en underfråga är involverad i SELECT-listan.
Så, är SQL DISTINCT bra eller dåligt för att ta bort dubbletter i resultat?
Resultaten säger att det är bra. Det är inte bättre eller sämre än GROUP BY eftersom planerna är desamma. Men det är en god vana att kontrollera genomförandeplanen. Tänk på optimering från början. På så sätt, om du stöter på några skillnader i DISTINCT och GROUP BY, kommer du att upptäcka dem.
Dessutom gör de moderna verktygen denna uppgift mycket enklare. Till exempel har en populär produkt dbForge SQL Complete från Devart en specifik funktion som beräknar värden i de aggregerade funktionerna i den färdiga resultatuppsättningen i SSMS-resultatrutnätet. DISTINCT-värdena finns också där.
Gilla inlägget? Sprid sedan ordet genom att dela det på dina favoritplattformar för sociala medier.
Relaterade artiklar för mer information
- SQL GROUP BY:3 enkla tips för att gruppera resultat som ett proffs
- SQL INSERT INTO SELECT:5 enkla sätt att hantera dubbletter
- Vad är SQL Aggregate Functions? (Enkla tips för nybörjare)
- SQL-frågeoptimering:5 kärnfakta för att öka frågorna