I en ny tråd om StackExchange hade en användare följande problem:
Jag vill ha en fråga som returnerar den första personen i tabellen med ett GroupID =2. Om ingen med ett GroupID =2 existerar vill jag ha den första personen med ett RollID =2.
Låt oss för tillfället förkasta det faktum att "först" är fruktansvärt definierat. I själva verket brydde användaren sig inte om vilken person de fick, om det kom slumpmässigt, godtyckligt eller genom någon explicit logik utöver deras huvudkriterier. Om du ignorerar det, låt oss säga att du har en grundläggande tabell:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
I den verkliga världen finns det förmodligen andra kolumner, ytterligare begränsningar, kanske främmande nycklar till andra tabeller och säkert andra index. Men låt oss hålla det här enkelt och komma med en fråga.
Sannolika lösningar
Med den bordsdesignen verkar det enkelt att lösa problemet, eller hur? Det första försöket du förmodligen skulle göra är:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Detta använder TOP och en villkorlig ORDER BY att behandla de användare med ett GroupID =2 som högre prioritet. Planen för den här frågan är ganska enkel, där det mesta av kostnaderna sker i en sorts operation. Här är körtidsstatistik mot en tom tabell:
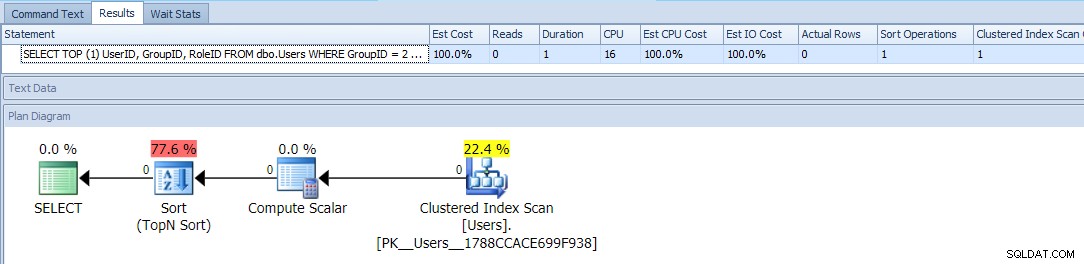
Det här ser ut att vara ungefär så bra som du kan göra – en enkel plan som bara skannar tabellen en gång, och förutom en irriterande sort som du borde kunna leva med, inga problem, eller hur?
Nåväl, ett annat svar i tråden gav denna mer komplexa variant:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Vid första anblicken skulle du förmodligen tro att den här frågan är extremt mindre effektiv, eftersom den kräver två klustrade indexskanningar. Du skulle definitivt ha rätt i det; här är plan- och körtidsmåtten mot en tom tabell:
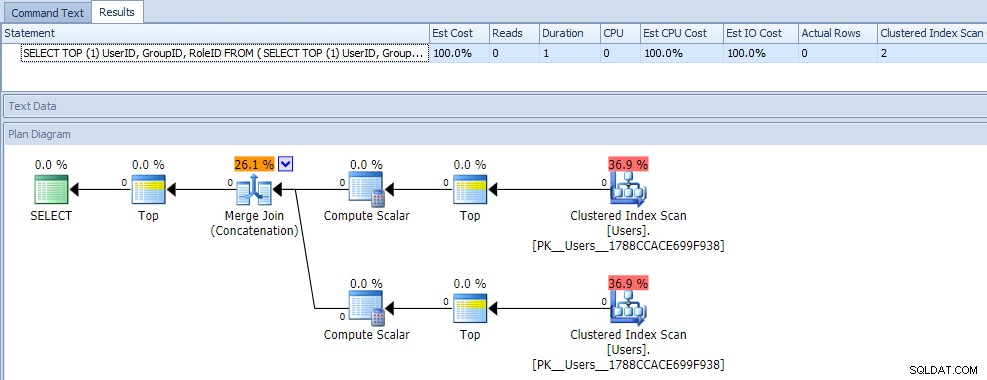
Men nu, låt oss lägga till data
För att testa dessa frågor ville jag använda lite realistisk data. Så först fyllde jag i 1 000 rader från sys.all_objects, med modulo-operationer mot object_id för att få en anständig distribution:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Nu när jag kör de två frågorna, här är körtidsstatistiken:

UNION ALL-versionen kommer in med något mindre I/O (4 gånger jämfört med 5), lägre varaktighet och lägre uppskattad totalkostnad, medan den villkorade ORDER BY-versionen har lägre uppskattad CPU-kostnad. Uppgifterna här är ganska små att dra några slutsatser om; Jag ville bara ha det som en insats i marken. Låt oss nu ändra fördelningen så att de flesta rader uppfyller minst ett av kriterierna (och ibland båda):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Den här gången har den villkorade beställningen de högsta uppskattade kostnaderna för både CPU och I/O:

Men återigen, vid den här datastorleken är det relativt obetydlig påverkan på varaktighet och läsningar, och bortsett från de uppskattade kostnaderna (som i alla fall till stor del består av), är det svårt att utse en vinnare här.
Så, låt oss lägga till mycket mer data
Även om jag hellre njuter av att bygga exempeldata från katalogvyerna, eftersom alla har sådana, tänker jag den här gången rita på bordet Sales.SalesOrderHeaderEnlarged från AdventureWorks2012, utökat med det här skriptet från Jonathan Kehayias. På mitt system har den här tabellen 1 258 600 rader. Följande skript kommer att infoga en miljon av dessa rader i vår dbo.Users-tabell:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Okej, nu när vi kör frågorna ser vi ett problem:ORDER BY-variationen har gått parallellt och har raderat både läsningar och CPU, vilket ger en nästan 120X skillnad i varaktighet:
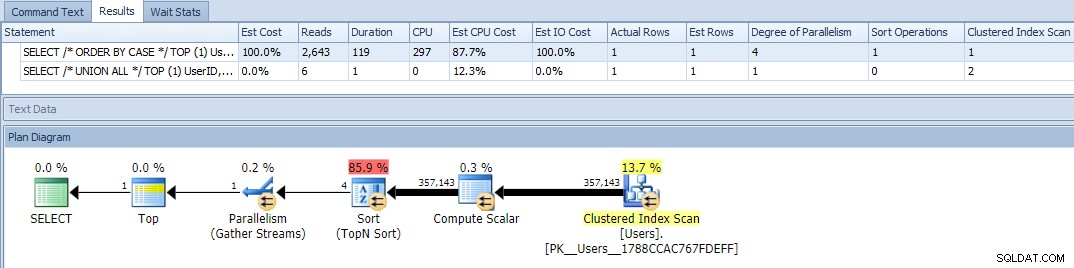
Att eliminera parallellism (med MAXDOP) hjälpte inte:
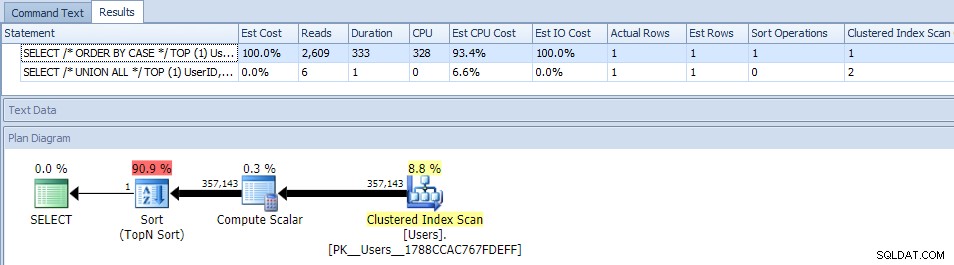
(Union ALLA-planen ser fortfarande likadan ut.)
Och om vi ändrar skevningen till att vara jämn, där 95 % av raderna uppfyller minst ett kriterium:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Frågorna visar fortfarande att sorten är oöverkomligt dyr:

Och med MAXDOP =1 var det mycket värre (se bara på varaktigheten):

Slutligen, vad sägs om 95 % skevhet i endera riktningen (t.ex. de flesta rader uppfyller GroupID-kriterierna, eller de flesta rader uppfyller RollID-kriterierna)? Detta skript säkerställer att minst 95 % av data har GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Resultaten är ganska lika (jag ska bara sluta prova MAXDOP-grejen från och med nu):

Och sedan om vi snedställer åt andra hållet, där minst 95 % av datan har RollID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Resultat:

Slutsats
I inte ett enda fall som jag kunde tillverka överträffade den "enklare" ORDER BY-frågan – även med en mindre klustrad indexskanning – den mer komplexa UNION ALL-frågan. Ibland måste du vara mycket försiktig med vad SQL Server måste göra när du introducerar operationer som sortering i din frågesemantik, och inte förlita dig enbart på enkelheten i planen (kasta inte emot någon fördom du kan ha baserat på tidigare scenarier).
Din första instinkt kan ofta vara korrekt, men jag slår vad om att det finns tillfällen då det finns ett bättre alternativ som på ytan ser ut som att det omöjligt kunde fungera bättre. Som i detta exempel. Jag blir ganska bättre på att ifrågasätta antaganden jag har gjort från observationer och att inte göra generella uttalanden som "skanningar fungerar aldrig bra" och "enklare frågor går alltid snabbare." Om du tar bort orden aldrig och alltid från ditt ordförråd, kan du komma på att du sätter fler av dessa antaganden och allmänna påståenden på prov, och att du hamnar mycket bättre.