Paginering är ett vanligt användningsfall i klient- och webbapplikationer överallt. Google visar dig 10 resultat åt gången, din onlinebank kan visa 20 räkningar per sida, och program för buggspårning och källkontroll kan visa 50 objekt på skärmen.
Jag ville titta på det vanliga sidnumreringssättet på SQL Server 2012 – OFFSET / FETCH (en standard som motsvarar MySQL:s prioprietära LIMIT-klausul) – och föreslå en variant som kommer att leda till mer linjär personsökningsprestanda över hela uppsättningen, istället för att bara vara optimal i början. Vilket tyvärr är allt som många butiker kommer att testa.
Vad är paginering i SQL Server?
Baserat på indexeringen av tabellen, de kolumner som behövs och den valda sorteringsmetoden kan paginering vara relativt smärtfri. Om du letar efter de "första" 20 kunderna och det klustrade indexet stöder den sorteringen (säg ett klustrat index på en IDENTITY-kolumn eller DateCreated-kolumn), så kommer frågan att bli relativt effektiv. Om du behöver stödja sortering som kräver icke-klustrade index, och särskilt om du har kolumner som behövs för utdata som inte täcks av indexet (strålkastar om det inte finns något stödjande index), kan frågorna bli dyrare. Och till och med samma fråga (med en annan @PageNumber-parameter) kan bli mycket dyrare när @PageNumber blir högre – eftersom fler läsningar kan krävas för att komma till den "delen" av data.
Vissa kommer att säga att framsteg mot slutet av uppsättningen är något som du kan lösa genom att kasta mer minne till problemet (så att du eliminerar all fysisk I/O) och/eller använda cachning på applikationsnivå (så att du inte kommer att databasen överhuvudtaget). Låt oss för detta inlägg anta att mer minne inte alltid är möjligt, eftersom inte alla kunder kan lägga till RAM till en server som har slut på minnesplatser eller inte har kontroll över dem, eller bara knäppa med fingrarna och ha nyare, större servrar redo att gå. Speciellt eftersom vissa kunder använder Standard Edition, så de är begränsade till 64 GB (SQL Server 2012) eller 128 GB (SQL Server 2014), eller använder ännu mer begränsade upplagor som Express (1 GB) eller ett av många molnerbjudanden.
Så jag ville titta på den vanliga sökningsmetoden på SQL Server 2012 – OFFSET / FETCH – och föreslå en variant som kommer att leda till mer linjär sökningsprestanda över hela uppsättningen, istället för att bara vara optimal i början. Vilket tyvärr är allt som många butiker kommer att testa.
Sidningsdatainställningar/exempel
Jag ska låna från ett annat inlägg, Dåliga vanor :Fokuserar bara på diskutrymme när jag väljer nycklar, där jag fyllde i följande tabell med 1 000 000 rader med slumpmässiga (men inte helt realistiska) kunddata:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Eftersom jag visste att jag skulle testa I/O här, och skulle testa från både en varm och kall cache, gjorde jag testet åtminstone lite mer rättvist genom att bygga om alla index för att minimera fragmentering (som skulle göras mindre störande, men regelbundet, på de flesta upptagna system som utför alla typer av indexunderhåll):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Efter ombyggnaden kommer fragmenteringen nu in på 0,05 % – 0,17 % för alla index (indexnivå =0), sidor fylls över 99 %, och radantalet/sidantalet för indexen är som följer:
| Index | Sidantal | Radräkning |
|---|---|---|
| C_PK_Customers_I (klustrade index) | 19 210 | 1 000 000 |
| C_Email_Customers_I | 7 344 | 1 000 000 |
| C_Active_Customers_I (filtrerat index) | 13 648 | 815 235 |
| C_Name_Customers_I | 16 824 | 1 000 000 |
Index, antal sidor, antal rader
Det här är uppenbarligen inte ett superbrett bord, och jag har lämnat komprimering utanför bilden den här gången. Jag kanske kommer att utforska fler konfigurationer i ett framtida test.
Hur man effektivt sidnumrerar en SQL-fråga
Konceptet med paginering – att bara visa användaren rader åt gången – är lättare att visualisera än att förklara. Tänk på indexet för en fysisk bok, som kan ha flera sidor med referenser till punkter i boken, men ordnade i alfabetisk ordning. För enkelhetens skull, låt oss säga att tio objekt får plats på varje sida i indexet. Det här kan se ut så här:
Nu, om jag redan har läst sidorna 1 och 2 i indexet, vet jag att jag måste hoppa över 2 sidor för att komma till sida 3. Men eftersom jag vet att det finns 10 artiklar på varje sida kan jag också tänka på detta som att jag hoppar över 2 x 10 artiklar och börjar på den 21:a. Eller, för att uttrycka det på ett annat sätt, jag måste hoppa över de första (10*(3-1)) objekten. För att göra detta mer allmänt kan jag säga att för att börja på sida n måste jag hoppa över de första (10 * (n-1)) objekten. För att komma till första sidan hoppar jag över 10*(1-1) poster, för att avsluta på punkt 1. För att komma till andra sidan hoppar jag över 10*(2-1) poster, för att avsluta på punkt 11. Och så på.
Med den informationen kommer användare att formulera en personsökningsfråga som denna, med tanke på att OFFSET/FETCH-satserna som lagts till i SQL Server 2012 var specifikt utformade för att hoppa över så många rader:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Som jag nämnde ovan fungerar detta bra om det finns ett index som stöder ORDER BY och som täcker alla kolumner i SELECT-satsen (och, för mer komplexa frågor, WHERE- och JOIN-satserna). Sorteringskostnaderna kan dock vara överväldigande utan stödjande index, och om utdatakolumnerna inte täcks kommer du antingen att sluta med en hel massa nyckelsökningar, eller så kan du till och med få en tabellskanning i vissa scenarier.
Bästa metoder för sortering av SQL-paginering
Med tanke på tabellen och indexen ovan ville jag testa dessa scenarier, där vi vill visa 100 rader per sida och mata ut alla kolumner i tabellen:
- Standard –
ORDER BY CustomerID(klustrade index). Detta är den mest bekväma beställningen för databaserna, eftersom den inte kräver ytterligare sortering, och all data från denna tabell som eventuellt kan behövas för visning är inkluderad. Å andra sidan kanske detta inte är det mest effektiva indexet att använda om du visar en delmängd av tabellen. Beställningen kanske inte heller är meningsfull för slutanvändare, särskilt om CustomerID är en surrogatidentifierare utan extern betydelse. - Telefonbok –
ORDER BY LastName, FirstName(stöder icke-klustrade index). Detta är den mest intuitiva beställningen för användare, men skulle kräva ett icke-klustrat index för att stödja både sortering och täckning. Utan ett stödjande index skulle hela tabellen behöva skannas. - Användardefinierad –
ORDER BY FirstName DESC, EMail(inget stödjande index). Detta representerar möjligheten för användaren att välja vilken sorteringsordning de vill, ett mönster Michael J. Swart varnar för i "UI Design Patterns That Don't Scale."
Jag ville testa dessa metoder och jämföra planer och mätvärden när jag tittade på sidan 1, sidan 500, sidan 5 000 och sidan 9 999 under både scenarier för varm cache och kall cache. Jag skapade dessa procedurer (som endast skiljer sig från ORDER BY-satsen):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail I verkligheten har du förmodligen bara en procedur som antingen använder dynamisk SQL (som i mitt "köksvask"-exempel) eller ett CASE-uttryck för att diktera ordningen.
I båda fallen kan du få bästa resultat genom att använda OPTION (OMKOMPILERA) på frågan för att undvika återanvändning av planer som är optimala för ett sorteringsalternativ men inte alla. Jag skapade separata procedurer här för att ta bort dessa variabler; Jag lade till OPTION (OMKOMPILERA) för dessa tester för att hålla mig borta från parametersniffning och andra optimeringsproblem utan att spola hela plancachen upprepade gånger.
En alternativ metod för sidnumrering av SQL Server för bättre prestanda
Ett lite annorlunda tillvägagångssätt, som jag inte ser implementerat särskilt ofta, är att hitta "sidan" vi är på med enbart klustringsnyckeln och sedan gå med i det:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Det är förstås mer utförlig kod, men förhoppningsvis är det tydligt vad SQL Server kan tvingas att göra:undvika en genomsökning eller åtminstone skjuta upp uppslagningar tills en mycket mindre resultatuppsättning har förminskats. Paul White (@SQL_Kiwi) undersökte ett liknande tillvägagångssätt redan 2010, innan OFFSET/FETCH introducerades i de tidiga SQL Server 2012-betorna (jag bloggade först om det senare samma år).
Med tanke på scenarierna ovan skapade jag ytterligare tre procedurer, med den enda skillnaden mellan kolumnen/kolumnerna som anges i ORDER BY-satserna (vi behöver nu två, en för själva sidan och en för att beställa resultatet):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Obs:Det här kanske inte fungerar så bra om din primärnyckel inte är klustrad – en del av tricket som gör att detta fungerar bättre, när ett stödjande index kan användas, är att klustringsnyckeln redan finns i indexet, så en uppslagning undviks ofta.
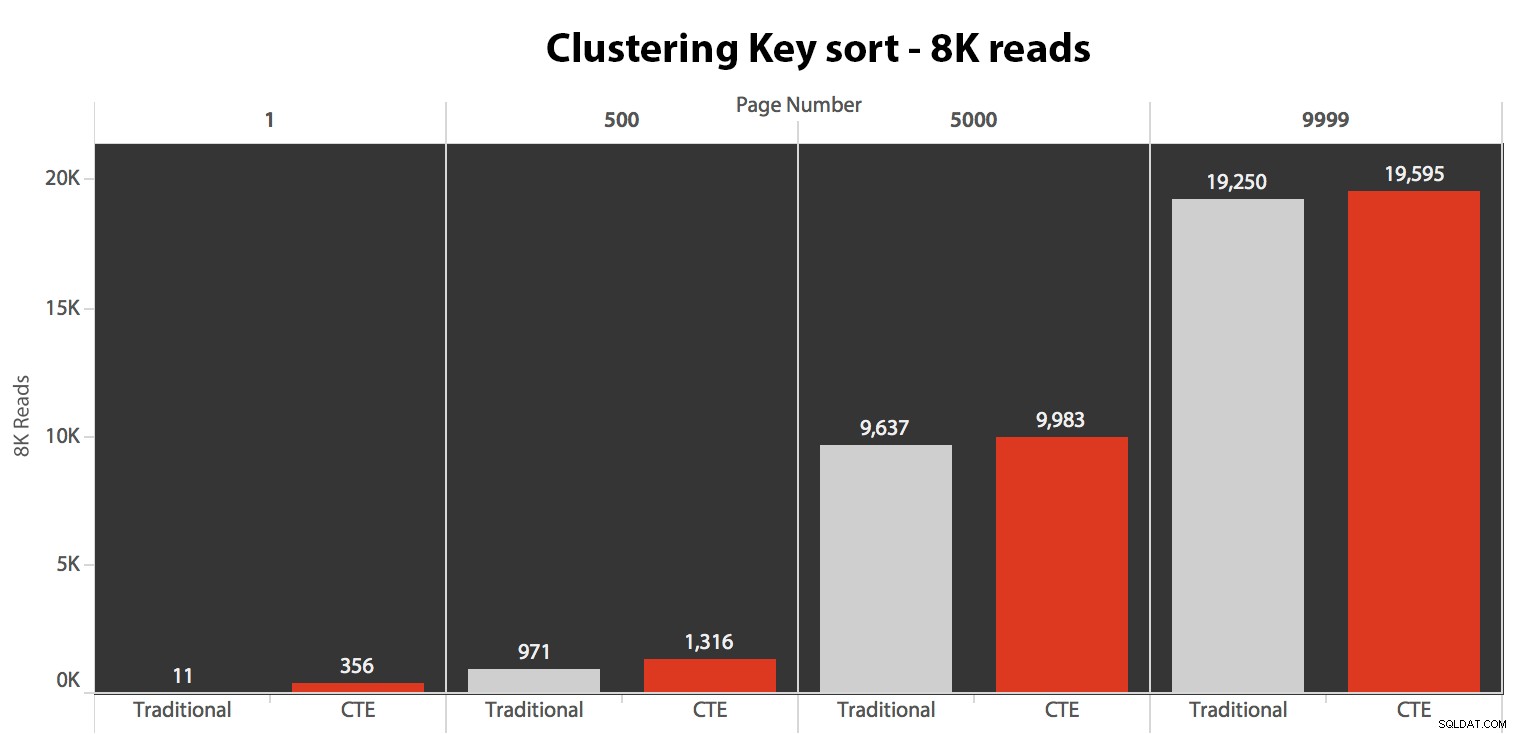
Testar sorteringen av klustringsnyckeln
Först testade jag fallet där jag inte förväntade mig mycket skillnad mellan de två metoderna – sortering efter klustringsnyckeln. Jag körde dessa satser i en batch i SQL Sentry Plan Explorer och observerade varaktighet, läsningar och de grafiska planerna, och såg till att varje fråga startade från en helt kall cache:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
Resultaten här var inte häpnadsväckande. Över 5 körningar visas det genomsnittliga antalet läsningar här, och visar försumbara skillnader mellan de två frågorna, över alla sidnummer, vid sortering efter klustringsnyckeln:
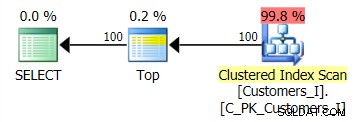
Planen för standardmetoden (som visas i Plan Explorer) var i alla fall följande:
Medan planen för den CTE-baserade metoden såg ut så här:
Nu, medan I/O var densamma oavsett cachelagring (bara mycket mer läser framåt i det kalla cache-scenariot), mätte jag varaktigheten med en kall cache och även med en varm cache (där jag kommenterade DROPCLEANBUFFERS-kommandona och körde frågorna flera gånger innan mätning). Dessa varaktigheter såg ut så här:
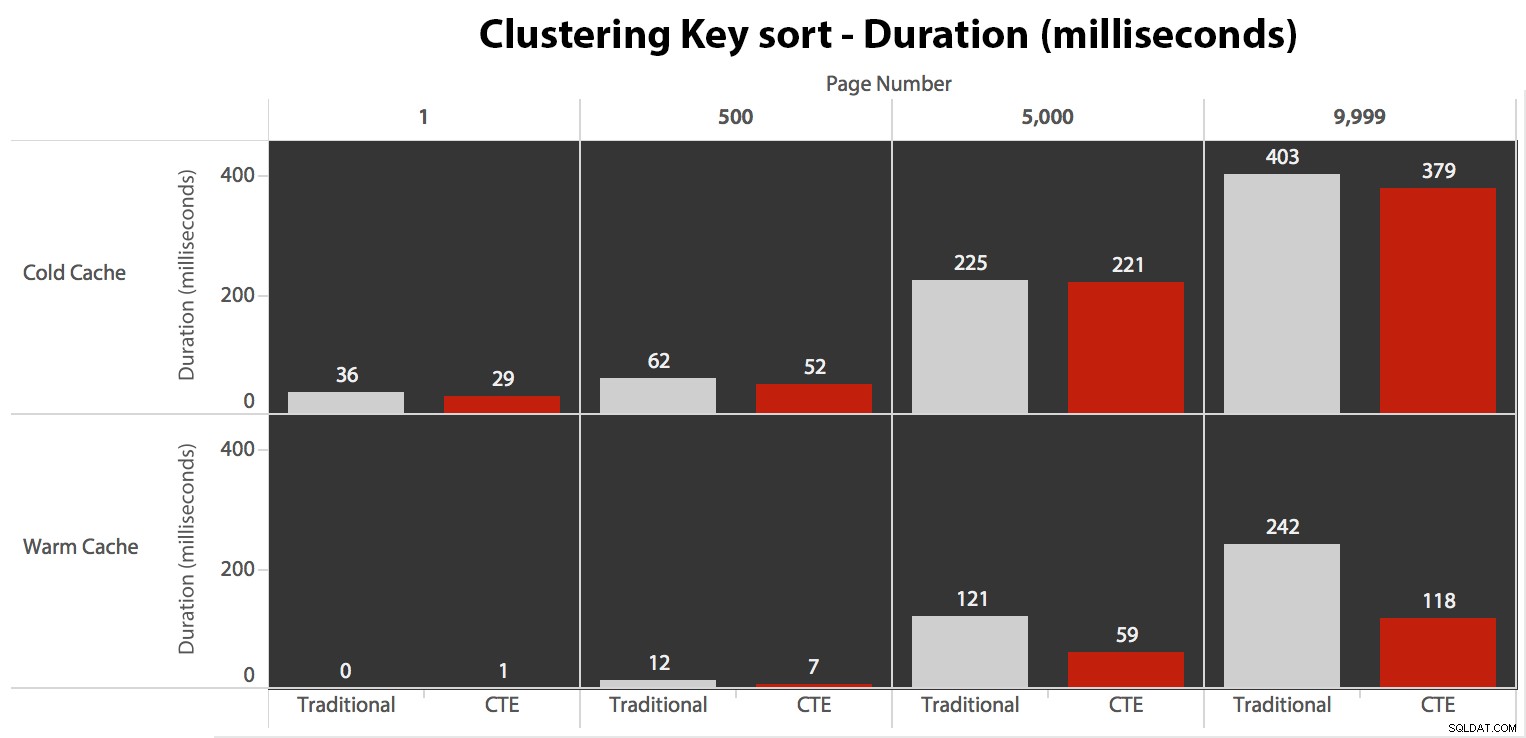
Medan du kan se ett mönster som visar att varaktigheten ökar när sidnumret blir högre, tänk på skalan:för att träffa raderna 999 801 -> 999 900 pratar vi en halv sekund i värsta fall och 118 millisekunder i bästa fall. CTE-metoden vinner, men inte med en hel del.
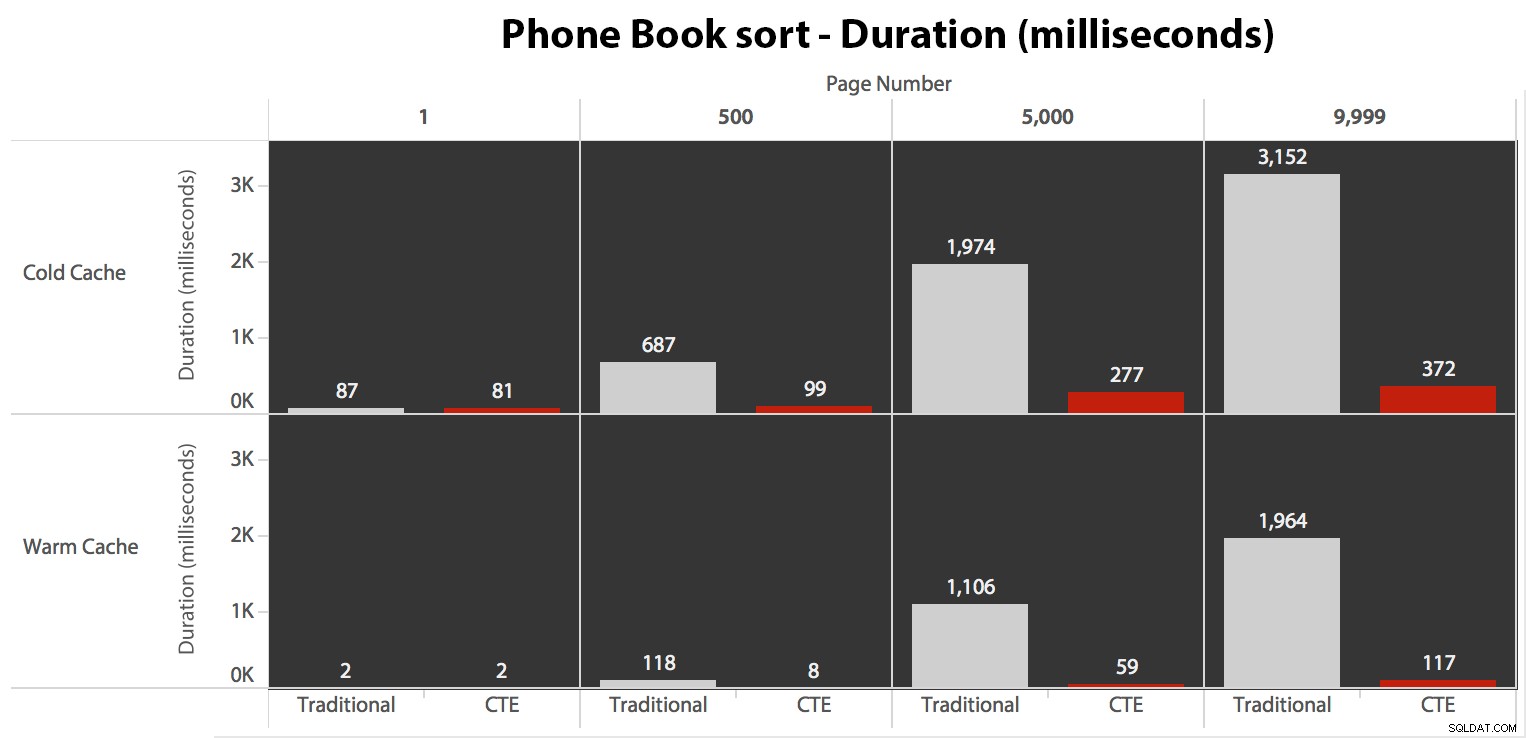
Testar sorteringen i telefonboken
Därefter testade jag det andra fallet, där sorteringen stöddes av ett icke-täckande index på Efternamn, Förnamn. Frågan ovan ändrade precis alla instanser av Test_1 till Test_2 . Här var läsningarna med en kall cache:
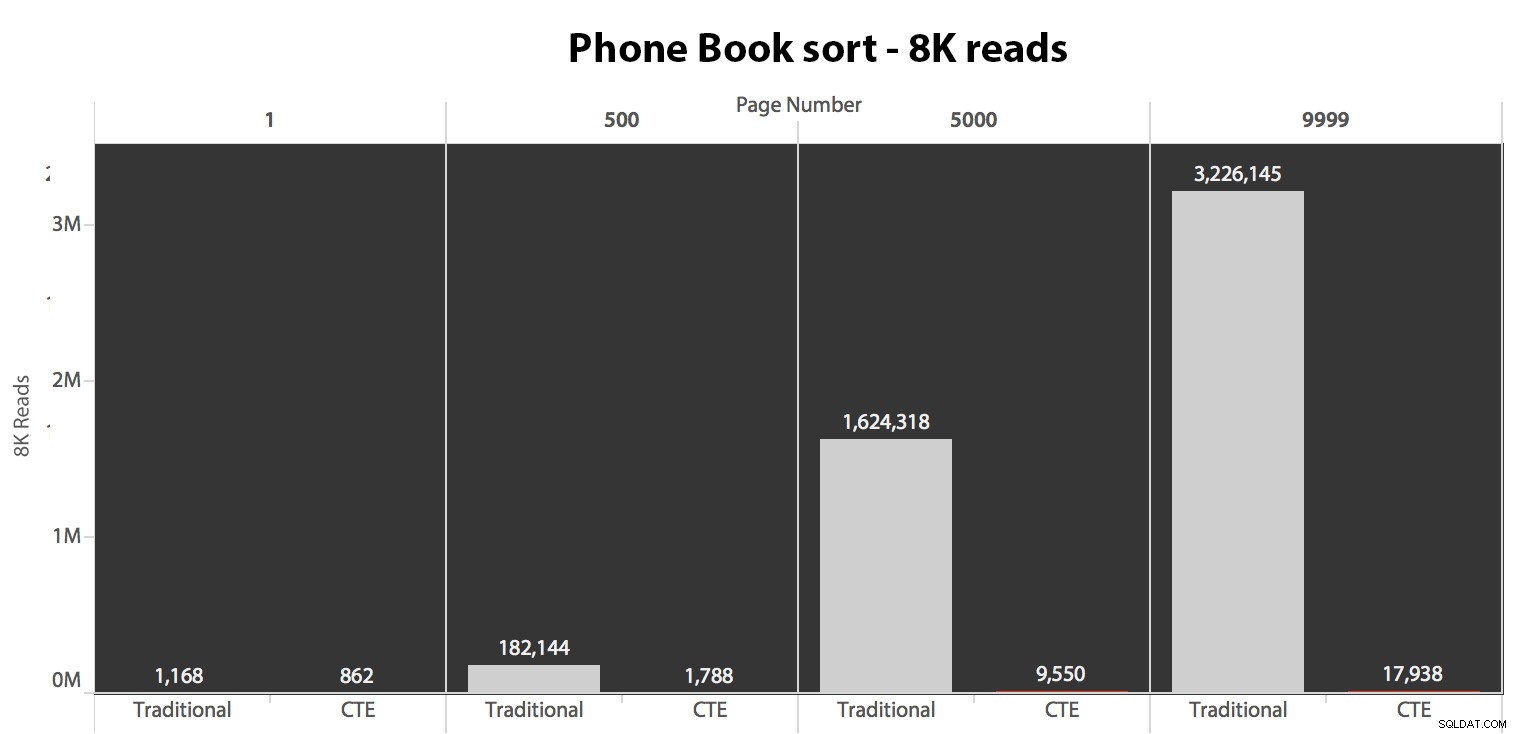
(Läsningarna under en varm cache följde samma mönster – de faktiska siffrorna skilde sig något, men inte tillräckligt för att motivera ett separat diagram.)
När vi inte använder det klustrade indexet för att sortera är det tydligt att I/O-kostnaderna för den traditionella metoden för OFFSET/FETCH är mycket värre än när man identifierar nycklarna först i en CTE och drar resten av kolumnerna bara för den delmängden.
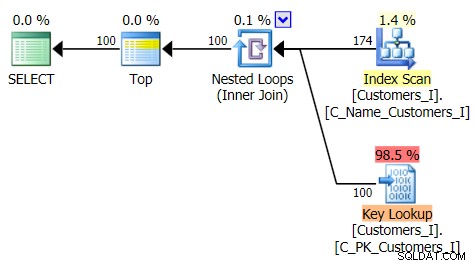
Här är planen för den traditionella frågemetoden:
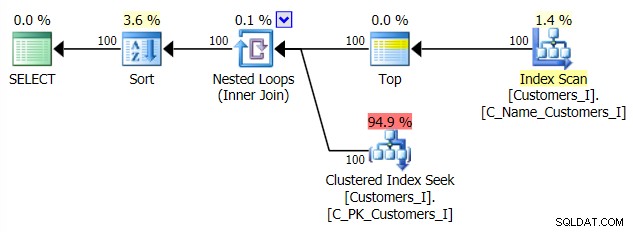
Och planen för min alternativa CTE-strategi:
Slutligen, varaktigheterna:
Det traditionella tillvägagångssättet visar en mycket uppenbar uppgång i varaktighet när du marscherar mot slutet av pagineringen. CTE-metoden visar också ett icke-linjärt mönster, men det är mycket mindre uttalat och ger bättre timing vid varje sidnummer. Vi ser 117 millisekunder för den näst sista sidan, jämfört med den traditionella metoden som kommer in på nästan två sekunder.
Testar den användardefinierade sorteringen
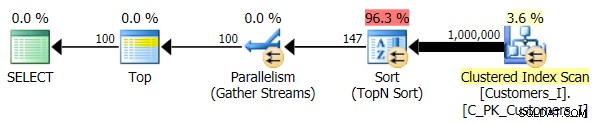
Slutligen ändrade jag frågan till att använda Test_3 lagrade procedurer, testar fallet där sorteringen definierades av användaren och inte hade ett stödjande index. I/O var konsekvent för varje uppsättning tester; grafen är så ointressant, jag ska bara länka till den. Lång historia kort:det var lite över 19 000 läsningar i alla tester. Anledningen är att varje enskild variant var tvungen att utföra en fullständig genomsökning på grund av avsaknaden av ett index för att stödja beställningen. Här är planen för det traditionella tillvägagångssättet:
Och medan planen för CTE-versionen av frågan ser oroväckande mer komplex ut...
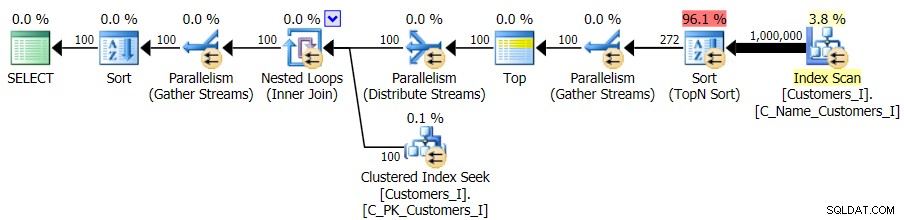
…det leder till lägre varaktigheter i alla fall utom ett. Här är varaktigheterna:
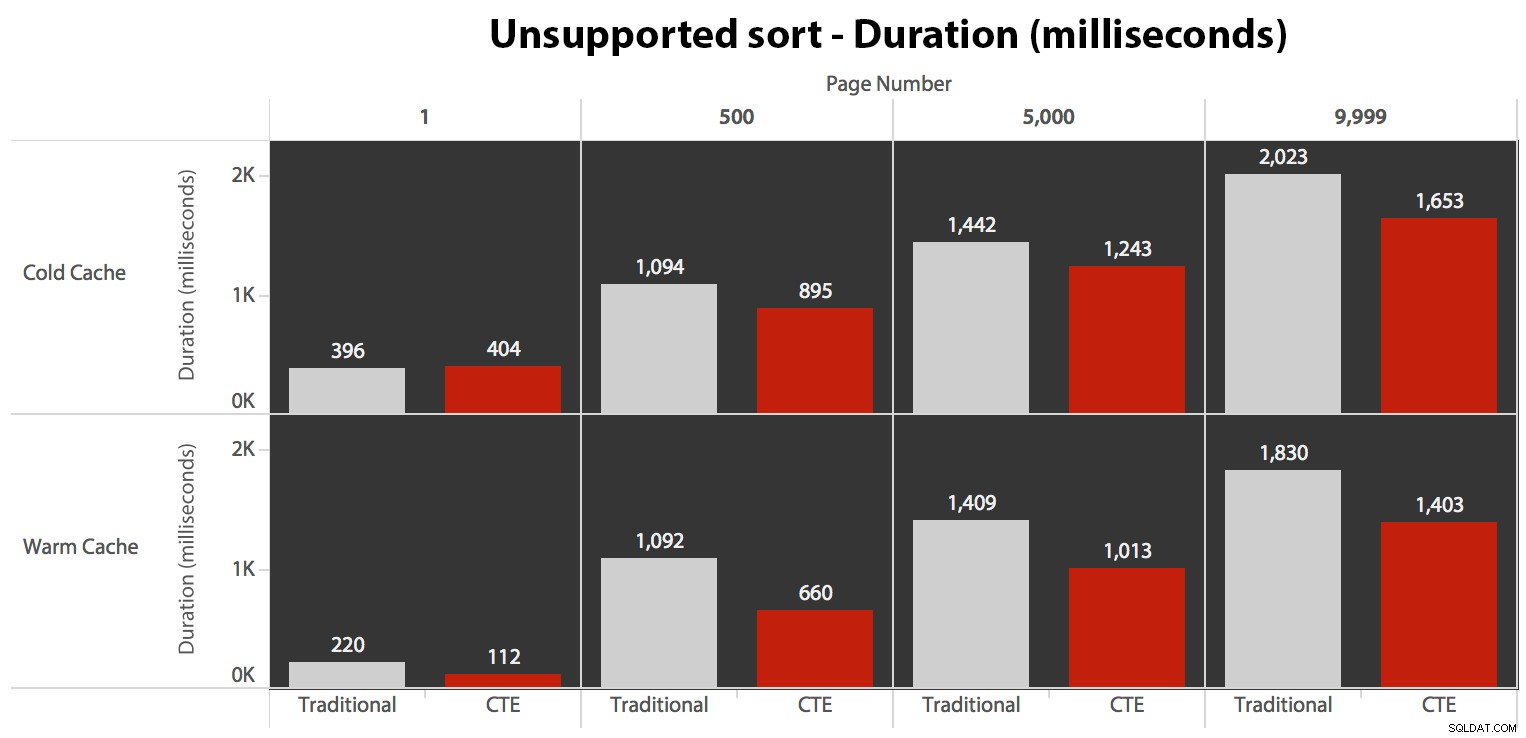
Du kan se att vi inte kan få linjär prestanda här med någon av metoderna, men CTE kommer ut överst med god marginal (allt från 16 % till 65 % bättre) i varje enskilt fall utom den kalla cache-frågan mot den första sida (där den förlorade med hela 8 millisekunder). Intressant också att notera att den traditionella metoden inte alls underlättas av en varm cache i "mitten" (sidorna 500 och 5000); först mot slutet av uppsättningen är någon effektivitet värd att nämna.
Högre volym
Efter individuell testning av några få exekveringar och ta medelvärden, tänkte jag att det också skulle vara vettigt att testa en stor volym av transaktioner som något skulle simulera verklig trafik på ett upptaget system. Så jag skapade ett jobb med 6 steg, ett för varje kombination av frågemetod (traditionell personsökning vs. CTE) och sorteringstyp (klustringsnyckel, telefonbok och stöds inte), med en 100-stegssekvens av att träffa de fyra sidnumren ovan. , 10 gånger vardera och 60 andra sidnummer valda slumpmässigt (men samma för varje steg). Så här skapade jag skriptet för att skapa jobb:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Här är den resulterande jobbsteglistan och en av stegets egenskaper:
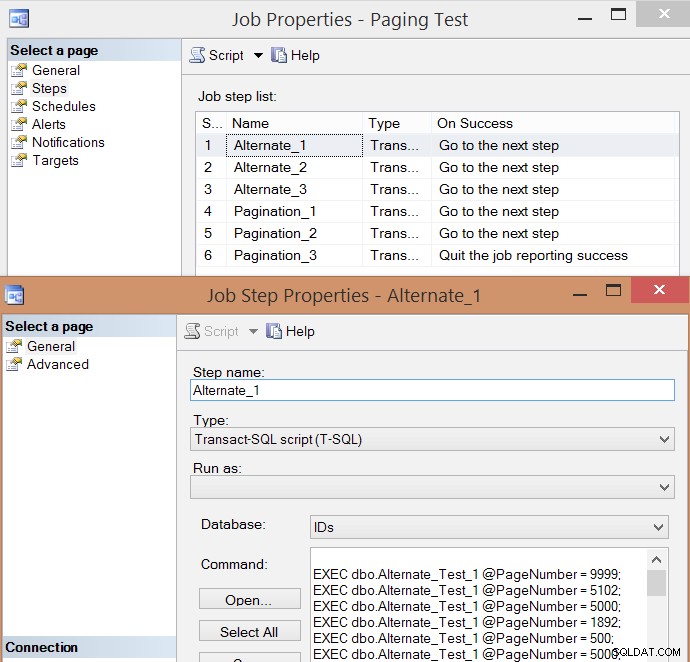
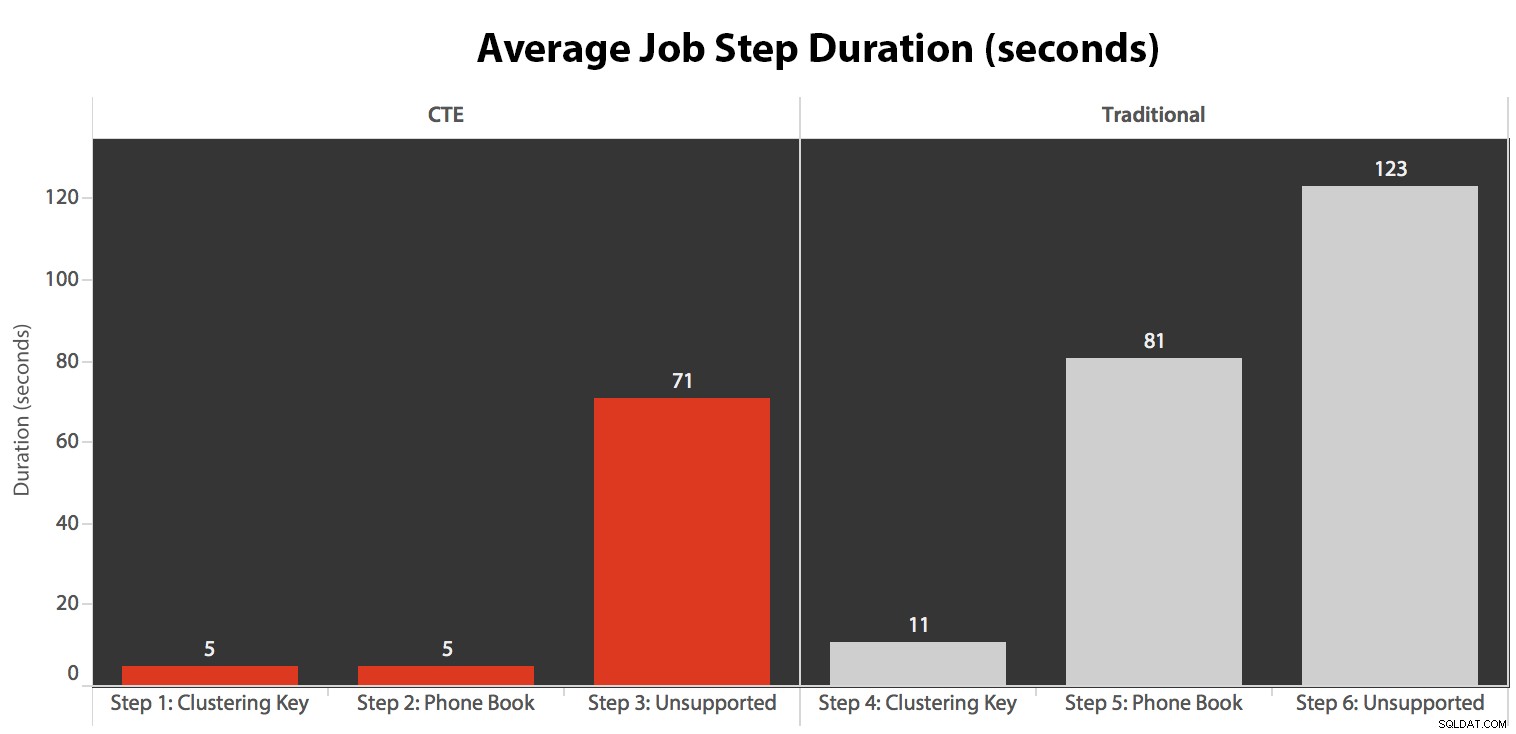
Jag körde jobbet fem gånger, gick sedan igenom jobbhistoriken och här var de genomsnittliga körtiderna för varje steg:
Jag korrelerade också en av körningarna i SQL Sentry Event Manager-kalendern...
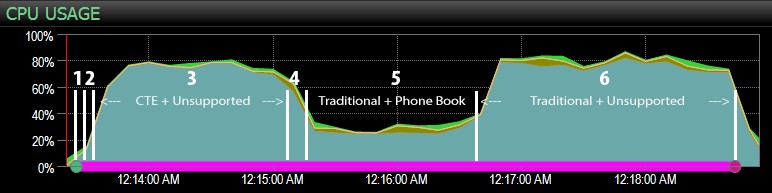
…med SQL Sentry-instrumentpanelen och manuellt markerad ungefär var vart och ett av de sex stegen löpte. Här är diagrammet för CPU-användning från Windows-sidan av instrumentpanelen:
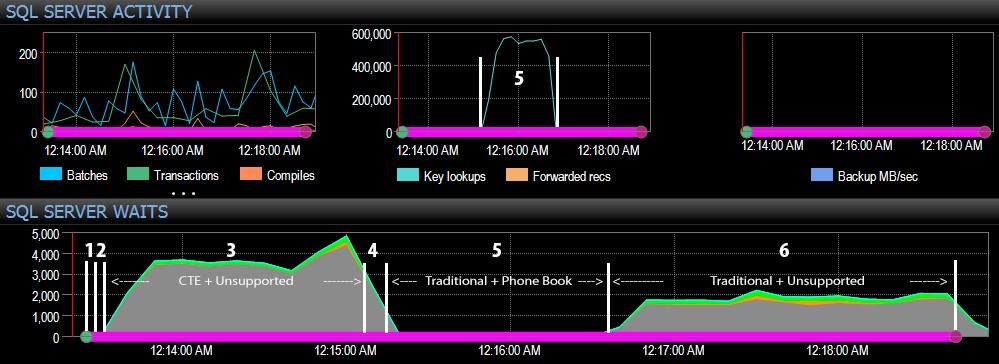
Och från SQL Server-sidan av instrumentpanelen fanns de intressanta mätvärdena i diagrammen för nyckelsökningar och väntan:
De mest intressanta observationerna bara ur ett rent visuellt perspektiv:
- CPU:n är ganska varm, runt 80 %, under steg 3 (CTE + inget stödjande index) och steg 6 (traditionellt + inget stödjande index);
- CXPACKET väntetider är relativt höga under steg 3 och i mindre utsträckning under steg 6;
- du kan se det enorma hopp i nyckeluppslagningar, till nästan 600 000, på ungefär en minuts intervall (sammanhang med steg 5 – det traditionella tillvägagångssättet med ett index i telefonboksstil).
I ett framtida test – som med mitt tidigare inlägg om GUID – skulle jag vilja testa detta på ett system där data inte passar in i minnet (lätt att simulera) och där diskarna är långsamma (inte så lätta att simulera) , eftersom vissa av dessa resultat förmodligen drar nytta av saker som inte alla produktionssystem har – snabba diskar och tillräckligt med RAM. Jag borde också utöka testerna till att inkludera fler varianter (med smala och breda kolumner, smala och breda index, ett telefonboksindex som faktiskt täcker alla utdatakolumner och sortering i båda riktningarna). Scope creep begränsade definitivt omfattningen av mina tester för denna första uppsättning tester.
Hur man förbättrar SQL Server-paginering
Paginering behöver inte alltid vara smärtsamt; SQL Server 2012 gör verkligen syntaxen enklare, men om du bara kopplar in den inbyggda syntaxen kanske du inte alltid ser en stor fördel. Här har jag visat att lite mer utförlig syntax med en CTE kan leda till mycket bättre prestanda i bästa fall, och utan tvekan försumbara prestandaskillnader i värsta fall. Genom att separera dataplacering från datahämtning i två olika steg kan vi se en enorm fördel i vissa scenarier, utanför högre CXPACKET-väntningar i ett fall (och även då avslutades de parallella frågorna snabbare än de andra frågorna som visade få eller inga väntetider, så det var osannolikt att de skulle vara den "dåliga" CXPACKET väntar alla varnar dig för).
Ändå är även den snabbare metoden långsam när det inte finns något stödjande index. Även om du kan vara frestad att implementera ett index för alla möjliga sorteringsalgoritmer som en användare kan välja, kanske du vill överväga att tillhandahålla färre alternativ (eftersom vi alla vet att index inte är gratis). Till exempel, behöver din applikation absolut stödja sortering efter Efternamn stigande *och* Efternamn fallande? Om de vill gå direkt till kunderna vars efternamn börjar på Z, kan de inte gå till *sista* sidan och arbeta baklänges? Det är ett affärs- och användbarhetsbeslut mer än ett tekniskt, behåll det bara som ett alternativ innan du slår index på varje sorteringskolumn, i båda riktningarna, för att få bästa prestanda för även de mest oklara sorteringsalternativen.