SQL Server-frågekörningsmotorn har två sätt att implementera en logisk "union all"-operation, med hjälp av de fysiska operatorerna Concatenation och Merge Join Concatenation. Även om den logiska operationen är densamma, finns det viktiga skillnader mellan de två fysiska operatörerna som kan göra en enorm skillnad för effektiviteten i dina genomförandeplaner.
Frågeoptimeraren gör ett rimligt jobb med att välja mellan de två alternativen i många fall, men det är långt ifrån perfekt på detta område. Den här artikeln beskriver möjligheterna till justering av frågor som presenteras av Merge Join Concatenation, och beskriver de interna beteenden och överväganden du måste vara medveten om för att få ut det mesta av det.
Konkatenering

Sammankopplingsoperatorn är relativt enkel:dess utdata är resultatet av fullständig läsning från var och en av dess ingångar i sekvens. Sammankopplingsoperatorn är en n-är fysisk operatör, vilket betyder att den kan ha '2...n' ingångar. För att illustrera, låt oss återgå till det AdventureWorks-baserade exemplet från min tidigare artikel, "Rewriting Queries to Improve Performance":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Följande fråga listar produkt- och transaktions-ID:n för sex specifika produkter:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Den producerar en exekveringsplan med en sammanlänkningsoperator med sex ingångar, som visas i SQL Sentry Plan Explorer:
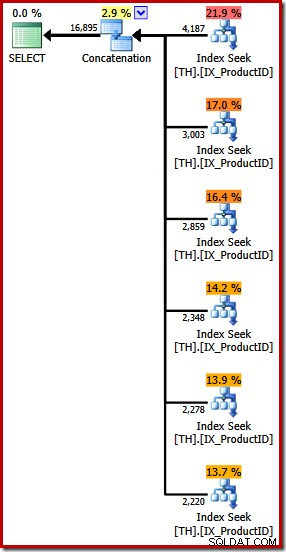
Planen ovan har en separat indexsökning för varje listat produkt-ID, i samma ordning som anges i frågan (läser uppifrån och ner). Den översta indexsökningen är för produkt 870, nästa ned är för produkt 873, sedan 921 och så vidare. Inget av det är givetvis garanterat beteende, det är bara något intressant att observera.
Jag nämnde tidigare att sammanlänkningsoperatorn bildar sin utdata genom att läsa från sina ingångar i sekvens. När denna plan exekveras, finns det en god chans att resultatuppsättningen visar rader för produkt 870 först, sedan 873, 921, 712, 707 och slutligen produkt 711. Återigen, detta är inte garanterat eftersom vi inte angav en BESTÄLLNING BY-klausul, men den visar hur sammankoppling fungerar internt.
En SSIS "Execution Plan"
Av skäl som kommer att vara vettiga inom ett ögonblick, överväg hur vi kan designa ett SSIS-paket för att utföra samma uppgift. Vi skulle säkert också kunna skriva det hela som en enda T-SQL-sats i SSIS, men det mer intressanta alternativet är att skapa en separat datakälla för varje produkt och använda en SSIS "Union All"-komponent i stället för SQL Server Concatenation operatör:
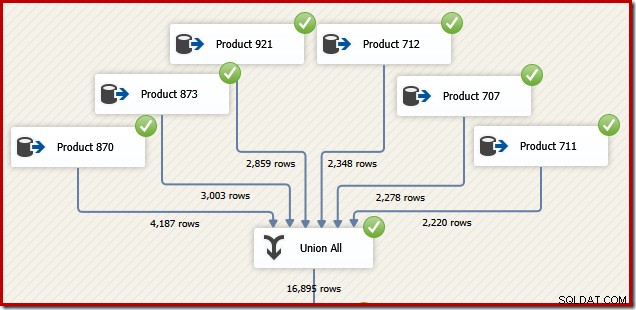
Föreställ dig nu att vi behöver den slutliga utdata från det dataflödet i transaktions-ID-ordning. Ett alternativ skulle vara att lägga till en explicit Sorteringskomponent efter Union All:
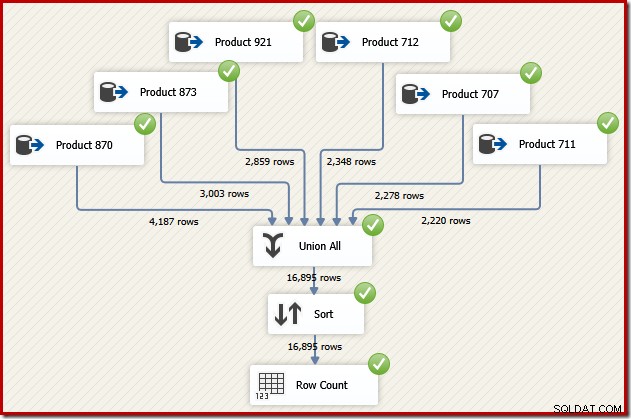
Det skulle säkert göra jobbet, men en skicklig och erfaren SSIS-designer skulle inse att det finns ett bättre alternativ:läs källdata för varje produkt i transaktions-ID-ordning (med hjälp av index), använd sedan en orderbevarande operation för att kombinera uppsättningarna .
I SSIS kallas komponenten som kombinerar rader från två sorterade dataflöden till ett enda sorterat dataflöde "Merge". Ett omdesignat SSIS-dataflöde som använder Merge för att returnera önskade rader i transaktions-ID-ordning följer:
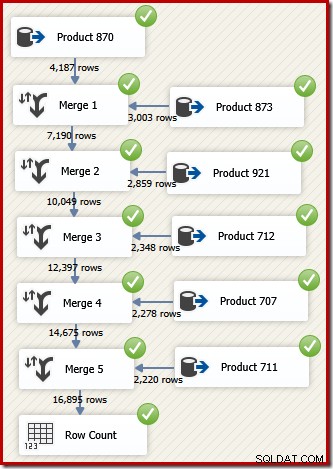
Observera att vi behöver fem separata Merge-komponenter eftersom Merge är en binär komponent, till skillnad från SSIS "Union All"-komponenten, som var n-är . Det nya sammanslagningsflödet ger resultat i transaktions-ID-ordning, utan att kräva en dyr (och blockerande) sorteringskomponent. Faktum är att om vi försöker lägga till ett sortering på transaktions-ID efter den slutliga sammanslagningen, visar SSIS en varning för att låta oss veta att strömmen redan är sorterad på önskat sätt:
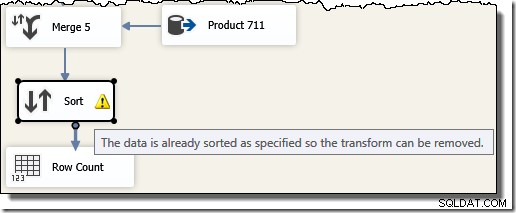
Poängen med SSIS-exemplet kan nu avslöjas. Titta på exekveringsplanen som valts av SQL Server-frågeoptimeraren när vi ber den att returnera de ursprungliga T-SQL-frågeresultaten i transaktions-ID-ordning (genom att lägga till en ORDER BY-sats):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
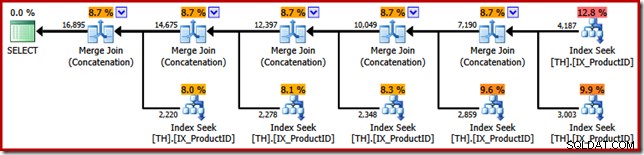
Likheterna med SSIS Merge-paketet är slående; även ner till behovet av fem binära "Merge"-operatorer. Den enda viktiga skillnaden är att SSIS har separata komponenter för "Merge Join" och "Merge", medan SQL Server använder samma kärnoperatör för båda.
För att vara tydlig, är Merge Join (Concatenation)-operatorerna i SQL Server-exekveringsplanen inte utföra en sammanfogning; motorn återanvänder bara samma fysiska operatör för att implementera en ordningsbevarande förening.
Skriva exekveringsplaner i SQL Server
SSIS har inget dataflödesspecifikationsspråk och inte heller en optimerare för att förvandla en sådan specifikation till en körbar dataflödesuppgift. Det är upp till SSIS-paketdesignern att inse att en orderbevarande sammanslagning är möjlig, ställ in komponentegenskaper (som sorteringsnycklar) på lämpligt sätt och jämför sedan prestanda. Detta kräver mer ansträngning (och skicklighet) från designerns sida, men det ger en mycket fin grad av kontroll.
Situationen i SQL Server är den motsatta:vi skriver en fråga specifikation använda T-SQL-språket, lita sedan på frågeoptimeraren för att utforska implementeringsalternativ och välja ett effektivt. Vi har inte möjlighet att konstruera en utförandeplan direkt. För det mesta är detta mycket önskvärt:SQL Server skulle utan tvekan vara mindre populär om varje fråga krävde att vi skrev ett paket i SSIS-stil.
Ändå (som förklarats i mitt tidigare inlägg) kan planen som väljs av optimeraren vara känslig för den T-SQL som används för att beskriva de önskade resultaten. Genom att upprepa exemplet från den artikeln kunde vi ha skrivit den ursprungliga T-SQL-frågan med en alternativ syntax:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Den här frågan specificerar exakt samma resultatuppsättning som tidigare, men optimeraren tar inte hänsyn till en plan för bevarande av beställning (sammanfogning), utan väljer att skanna det Clustered Index istället (ett mycket mindre effektivt alternativ):
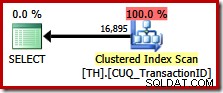
Utnyttja orderbevarande i SQL Server
Att undvika onödig sortering kan leda till betydande effektivitetsvinster, oavsett om vi pratar om SSIS eller SQL Server. Att uppnå detta mål kan vara mer komplicerat och svårare i SQL Server eftersom vi inte har så finkornig kontroll över exekveringsplanen, men det finns fortfarande saker vi kan göra.
Närmare bestämt, att förstå hur SQL Server Merge Join Concatenation-operatören fungerar internt kan hjälpa oss att fortsätta skriva tydlig, relationell T-SQL, samtidigt som det uppmuntrar frågeoptimeraren att överväga orderbevarande (sammanslagning) bearbetningsalternativ där så är lämpligt.
Så fungerar sammanfogning med sammanfogning

En vanlig sammanfogning kräver att båda ingångarna sorteras på sammanfogningsnycklarna. Merge Join Concatenation, å andra sidan, slår helt enkelt samman två redan beställda strömmar till en enda beställd ström – det finns ingen koppling, som sådan.
Detta väcker frågan:vilken exakt är "ordningen" som bevaras?
I SSIS måste vi ställa in sorteringsnyckelegenskaper på Merge-ingångarna för att definiera beställningen. SQL Server har ingen motsvarighet till detta. Svaret på frågan ovan är lite komplicerat, så vi tar det steg för steg.
Tänk på följande exempel, som begär en sammanfogning av två oindexerade heaptabeller (det enklaste fallet):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Dessa två tabeller har inga index, och det finns ingen ORDER BY-sats. Vilken ordning kommer sammanfogningssammansättningen "bevara"? För att ge dig en stund att tänka på det, låt oss först titta på exekveringsplanen som skapades för frågan ovan i SQL Server-versioner före 2012:
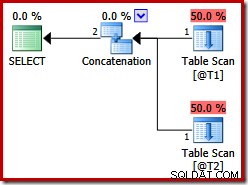
Det finns ingen sammanfogad sammanfogning, trots frågetipset:före SQL Server 2012 fungerar denna ledtråd bara med UNION, inte UNION ALL. För att få en plan med den önskade sammanslagningsoperatören måste vi inaktivera implementeringen av en logisk UNION ALL (UNIA) med den fysiska operatören Concatenation (CON). Observera att följande är odokumenterat och inte stöds för produktionsanvändning:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Den frågan producerar samma plan som SQL Server 2012 och 2014 gör med enbart MERGE UNION-frågetipset:
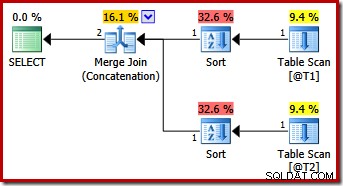
Kanske oväntat har exekveringsplanen explicita sorteringar på båda ingångarna till sammanslagningen. Sorteringsegenskaperna är:
Det är vettigt att en ordningsbevarande sammanslagning kräver en konsekvent ingångsordning, men varför valde den (c1, c2, c3) istället för, säg (c3, c1, c2) eller (c2, c3, c1)? Som en utgångspunkt sorteras sammanfogningssammansättningsingångar på utdataprojektionslistan. Välj-stjärnan i frågan expanderar till (c1, c2, c3) så det är den valda ordningen.
Sortera efter sammanslagningslista för utdataprojektion
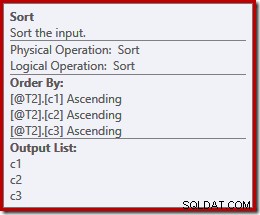
För att ytterligare illustrera poängen kan vi expandera select-stjärnan själva (som vi borde!) genom att välja en annan ordning (c3, c2, c1) medan vi håller på:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Sorteringarna ändras nu till att matcha (c3, c2, c1):
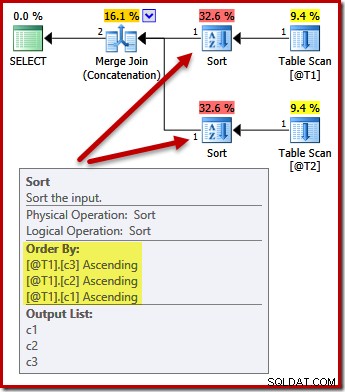
Återigen, frågan utgång order (förutsatt att vi skulle lägga till några data till tabellerna) är inte garanterat sorterad som visas, eftersom vi inte har någon ORDER BY-klausul. Dessa exempel är endast avsedda att visa hur optimeraren väljer en initial sorteringsordning för inmatning, i avsaknad av någon annan anledning att sortera.
Motstridiga sorteringsordningar
Fundera nu på vad som händer om vi lämnar projektionslistan som (c3, c2, c1) och lägger till ett krav för att sortera frågeresultaten efter (c1, c2, c3). Kommer ingångarna till sammanslagningen fortfarande att sorteras på (c3, c2, c1) med en sortering efter sammanslagningen på (c1, c2, c3) för att uppfylla ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Nej. Optimeraren är smart nog att undvika att sortera två gånger:
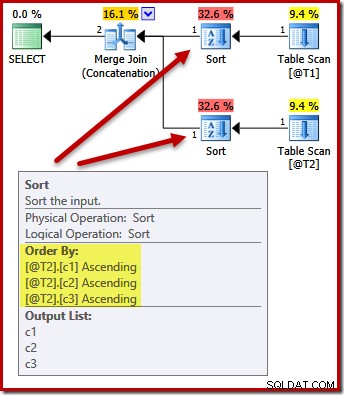
Att sortera båda ingångarna på (c1, c2, c3) är helt acceptabelt för sammanfogningen, så ingen dubbelsortering krävs.
Observera att den här planen gör garantera att resultatordningen kommer att vara (c1, c2, c3). Planen ser likadan ut som de tidigare planerna utan ORDER BY, men inte alla interna detaljer presenteras i användarsynliga utförandeplaner.
Effekten av unikhet
Vid val av sorteringsordning för sammanslagningsingångarna påverkas optimeraren även av eventuella unikhetsgarantier som finns. Tänk på följande exempel, med fem kolumner, men notera de olika kolumnordningarna i UNION ALL-operationen:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Utförandeplanen inkluderar sorteringar på (c5, c1, c2, c4, c3) för tabell @T1 och (c5, c4, c3, c2, c1) för tabell @T2:
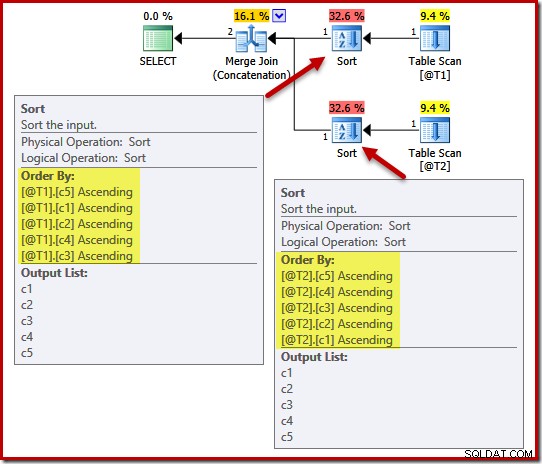
För att demonstrera effekten av unikhet på dessa sorter kommer vi att lägga till en UNIK begränsning till kolumn c1 i tabell T1 och kolumn c4 i tabell T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Poängen med unikhet är att optimeraren vet att den kan sluta sortera så fort den stöter på en kolumn som garanterat är unik. Sortering efter ytterligare kolumner efter att en unik nyckel har påträffats påverkar inte den slutliga sorteringsordningen, per definition.
Med de UNIKA begränsningarna på plats kan optimeraren förenkla (c5, c1, c2, c4, c3) sorteringslistan för T1 till (c5, c1) eftersom c1 är unik. På liknande sätt är (c5, c4, c3, c2, c1) sorteringslistan för T2 förenklad till (c5, c4) eftersom c4 är en nyckel:
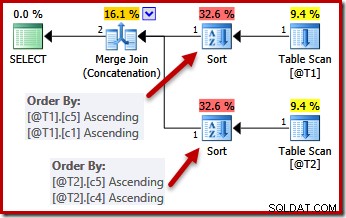
Parallellism
Förenklingen på grund av en unik nyckel är inte perfekt implementerad. I en parallell plan är strömmarna uppdelade så att alla rader för samma instans av sammanslagningen hamnar på samma tråd. Denna datauppsättningspartitionering baseras på sammanslagningskolumnerna och förenklas inte av närvaron av en nyckel.
Följande skript använder spårningsflagga 8649 som inte stöds för att generera en parallell plan för den tidigare frågan (som annars är oförändrad):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
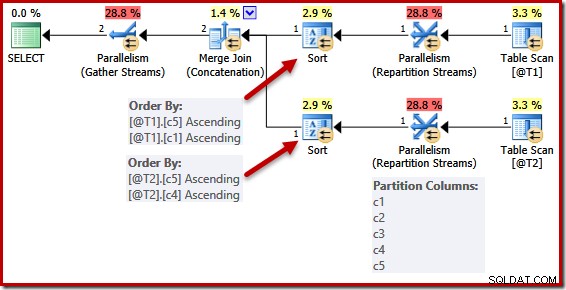
Sorteringslistorna är förenklade som tidigare, men operatörerna för ompartitionsströmmar partitionerar fortfarande över alla kolumner. Om denna förenkling implementerades konsekvent skulle de ompartitionerande operatörerna också arbeta på (c5, c1) och (c5, c4) ensamma.
Problem med icke-unika index
Det sätt som optimeraren resonerar kring sorteringskraven för sammanfogning kan resultera i onödiga sorteringsproblem, som nästa exempel visar:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
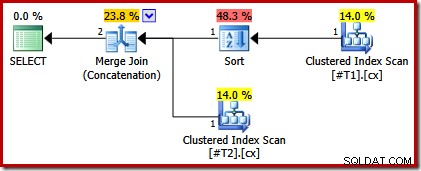
Om vi tittar på frågan och tillgängliga index, förväntar vi oss en exekveringsplan som utför en beordrad skanning av de klustrade indexen, med hjälp av merge join-sammansättning för att undvika behovet av någon sortering. Denna förväntning är helt berättigad, eftersom de klustrade indexen ger den ordning som anges i ORDER BY-satsen. Tyvärr innehåller planen vi faktiskt får två sorters:
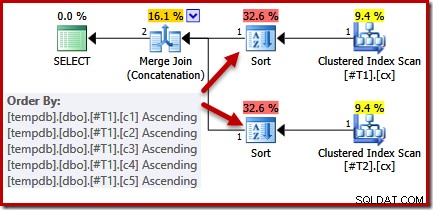
Det finns ingen bra anledning till dessa sorter, de visas bara för att frågeoptimerarens logik är ofullkomlig. Den sammanslagna utdatakolumnlistan (c1, c2, c3, c4, c5) är en superuppsättning av ORDER BY, men det finns ingen unik för att förenkla listan. Som ett resultat av denna lucka i optimerarens resonemang drar den slutsatsen att sammanslagningen kräver att dess input sorteras på (c1, c2, c3, c4, c5).
Vi kan verifiera denna analys genom att modifiera skriptet för att göra ett av de klustrade indexen unikt:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Utförandeplanen har nu bara en sortering ovanför tabellen med det icke-unika indexet:
Om vi nu gör båda klustrade index unika, inga sorter visas:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Med båda indexen unika kan de initiala sammanslagningsindatasorteringslistorna förenklas till enbart kolumn c1. Den förenklade listan matchar sedan ORDER BY-satsen exakt, så inga sorteringar behövs i den slutliga planen:
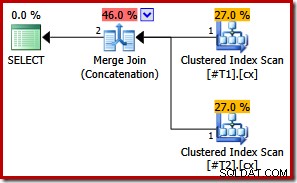
Observera att vi inte ens behöver frågetipset i det här sista exemplet för att få den optimala exekveringsplanen.
Sluta tankar
Det kan vara svårt att eliminera sorteringar i en genomförandeplan. I vissa fall kan det vara så enkelt som att ändra ett befintligt index (eller tillhandahålla ett nytt) för att leverera rader i önskad ordning. Frågeoptimeraren gör ett rimligt jobb överlag när lämpliga index finns tillgängliga.
I (många) andra fall kan dock undvika sortering kräva en mycket djupare förståelse av exekveringsmotorn, frågeoptimeraren och planoperatörerna själva. Att undvika sortering är utan tvekan ett ämne för avancerad frågejustering, men också ett otroligt givande när allt kommer rätt.