Tänker du på något när du skapar en ny databas? Jag antar att de flesta av er skulle säga nej, eftersom vi alla använder standardparametrar, även om de är långt ifrån optimala. Det finns dock ett gäng skivinställningar, och de hjälper verkligen till att öka systemets tillförlitlighet och prestanda.
Vi kommer inte att tala om vikten av NTFS-filsystemet för datatillförlitlighet, även om detta filsystem tillåter MS SQL Server att använda disken på det mest effektiva sättet.
Om du har ont om resurser och något börjar fungera långsamt är det första du tänker på att uppgradera. Men uppgradering krävs inte i alla fall. Du kan komma undan med justering, men det bör inte göras när servern börjar köra långsamt, utan vid design- och installationsstadiet.
Optimering är en komplex process och är ofta relaterad inte bara till ett visst program (i vårt fall till en viss databas) utan också till OS och hårdvara. Även om vi mest kommer att prata om databaser, kan vi inte ignorera de yttre sakerna.
Dataarkitektur
SQL Server lagrar, läser och skriver data i block 8 KB vardera. Dessa block kallas sidor. En databas kan lagra 128 sidor per megabyte (1 megabyte eller 1048576 byte dividerat med 8 kilobyte eller 8192 byte). Alla sidor lagras i en omfattning. En omfattning är de sista 8 sekventiella sidorna eller 64 KB. Således lagrar 1 megabyte 16 omfattningar.
Sidor och omfattningar är grunden för SQL Servers fysiska databasstruktur. MS SQL Server använder olika sidtyper, några av dem spårar tilldelat utrymme, vissa innehåller användardata och index. Sidor som spårar det tilldelade utrymmet innehåller tätt komprimerad data. Det tillåter MS SQL Server att effektivt lagra dem i minnet för enkel läsning.
SQL Server använder två typer av omfattningar:
- Omfattningar som lagrar sidor från två till många objekt kallas blandade omfattningar. Varje bord börjar som en blandad omfattning. Du använder blandad omfattning främst för de sidor som lagrar utrymme och innehåller små föremål.
- Omfattningar som har alla 8 sidor allokerade till ett objekt kallas enhetliga omfattningar. De används när en tabell eller ett index kräver mer än 64 KB.
Den första omfattningen för varje fil är enhetlig och innehåller sidor i filhuvudet, nästa omfattning innehåller 3 tilldelade sidor vardera. Servern tilldelar dessa blandade omfattningar när du skapar en grundläggande datafil och använder dessa sidor för sina interna uppgifter. Filhuvudsidan innehåller filattribut, såsom namnet på databasen som är lagrad i filen, filgrupp, minimistorlek, inkrementstorlek. Detta är den första sidan i varje fil (sida 0).
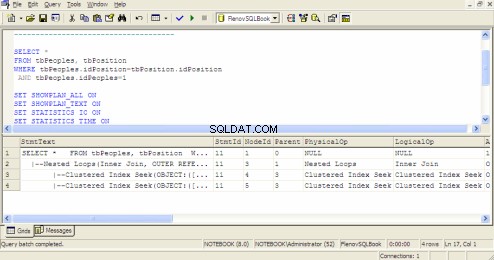
Query Execution Plan i SQL Query Analyzer
Sidfritt utrymme (PFS ) på en tilldelad sida som innehåller information om ledigt utrymme i filen. Denna information lagras på sidan 1. Varje sådan sida kan sträcka sig till 8000 sammanhängande sidor, vilket är cirka 64 Mb data.
Transaktionsloggen samlar all information om de ändringar som sker på servern för att återställa en databas vid ögonblicket för systemfel och för att säkerställa dataintegritet.
Observera att alla siffror är multiplar av 8 eller 16. Detta beror på att hårddiskkontrollern läser data av denna storlek lättare. Data läses från disken efter sidor, dvs med 8 kilobyte, vilket är ett ganska optimalt värde.
Sidskydd
Från och med MS SQL Server 2005 har databasservern ett nytt alternativ – datakontrollen på sidnivå. Om AGE_VERIFY_CHECKSUM parametern är aktiverad (den är aktiverad som standard), kommer servern att kontrollera kontrollsummorna för sidor. Om vi tittar i manualen för den här parametern kommer vi att se att kontrollsumman tillåter spårning av inmatnings-/utgångsfel som OS inte kan spåra. Vad är det för fel? Det verkar vara de interna problemen med databasservern.
Dataintegritetskontrollen går aldrig fel, så det är bättre att aktivera det. För detta måste vi köra följande kommando:
ALTER DATABASE имя базы SET PAGE_VERIFY
Om det finns ett fel på sidan kommer servern att meddela oss om det. Men hur kan vi fixa det snabbt? Det finns ett alternativ att återställa data på sidnivå för detta.
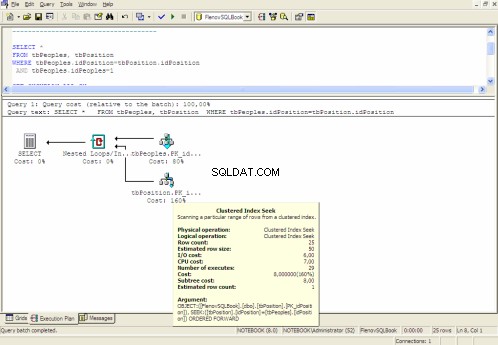
Grafisk genomförandeplan
Filtillväxt
När vi skapar en databas uppmanas vi att välja den ursprungliga storleken och inkrementmetoden. När vi har ont om det aktuella utrymmet utökar servern det i enlighet med den förinställda inkrementmetoden.
Det finns tre inkrementmetoder för filer:
- Tillväxt i megabyte.
- Tillväxt med procent.
- Manuell tillväxt.
De två första metoderna utförs automatiskt, men de rekommenderas endast för testdatabaser eftersom en administratör inte har kontroll över filstorleken.
Om en fil ökas med ett visst antal megabyte, vid någon tidpunkt, kan hastigheten på datainsättningen öka och filtillväxten kan bli för frekvent, vilket är extra kostnader. Filtillväxt i procent är också olönsam. Det rekommenderas att använda en filtillväxt på 10 % och detta är OK för små och medelstora databaser. Men när den når 1000 gigabyte kommer den att kräva 100 gigabyte vid varje tillväxt. Det kommer att leda till meningslöst slöseri med diskutrymme.
Kontrollera alltid ändringar i storleken på filer och transaktionsloggar. Det gör att du kan använda skivresurserna på det mest effektiva sättet.
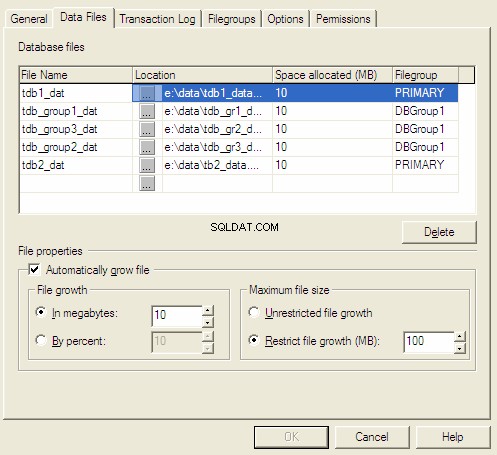
Databasegenskaper för MS SQL Server
Datakomprimering
Hårddisk förblir en vettig plats på en dator. Prestanda hos processorer växer kraftigt, medan hårddiskar inte kan erbjuda något nytt. För att spara antalet in-/utmatningsoperationer och minska data som lagras på hårddisken kan du använda diskar med komprimering. Endast sådana skivor är bra för att lagra skrivskyddade filgrupper. Kanske beror det på att komprimering krävs för att skriva, och det kräver extra processorkostnader.
Datakomprimering och skrivskyddat tillstånd är bra för arkivdata. Till exempel krävs inte bokföringsdata för de senaste åren för att skriva och kan ta för mycket plats. Genom att placera data på diskens arkivdel kommer du att spara mycket utrymme.
Diskar för tillförlitlighet
Följande metod tillåter ökad tillförlitlighet och prestanda på samma gång, och återigen är den relaterad till hårddiskar. Tja, där är det, mekaniken är inte bara den långsammaste utan den mest opålitliga. När det gäller tillförlitlighet så samlade jag inte in statistiken, men både hemma och på jobbet sysslar jag mest med hårddiskar.
Så för att öka prestanda och tillförlitlighet kan du helt enkelt använda två eller flera hårddiskar istället för en. Det blir ännu bättre om de kopplas till separata kontroller. Du kan lagra databasen på en disk och transaktionsloggar på en annan. Om det finns en tredje disk kan den lagra systemet.
Att lagra data och en inloggning på separata diskar gör att du kan öka tillförlitligheten avsevärt. Anta att du har allt på en disk och det går ner. Vad ska man göra? Du kan nå ett företag som kommer att försöka återvinna allt eller försöka göra detsamma på egen hand, men chansen till återhämtning är långt ifrån 100%. Dessutom kan det ta lång tid att återställa servern till jobbet. Snabb återställning kan endast göras till ögonblicket för den sista säkerhetskopian. Resten är tveksamt.
Och nu, anta att du har data och en transaktionslogg på olika diskar. Om disken med loggen stängs av kommer data att finnas kvar. Det enda är att du inte kan lägga till ny data, men om du skapar en ny logg kan du fortsätta arbeta.
Om disken med data slocknar kan vi fortfarande reservera transaktionsloggen för att förhindra minsta dataförlust. Efter det återställer vi data från den fullständiga säkerhetskopian (det bör alltid göras i förväg, en bra administratör gör detta minst en gång om dagen) och lägger till ändringar från säkerhetskopian av loggen.
Diskar för prestanda
Om data och en logg finns på separata diskar betyder det inte bara säkerhet utan också prestandaökning. Saken är att databasservern samtidigt kan skriva data till loggen och datafilen.
Vi kan gå längre och allokera en hårddisk till transaktionsloggen och flera hårddiskar till data. Servern arbetar med data oftare, därför kräver den flera lagringar som du kan arbeta med samtidigt. Och om dessa lagringar är anslutna till olika kontroller garanteras det samtidiga arbetet.
Den snabbaste och mest pålitliga varianten är att använda RAID . Men inte varje RAID är pålitlig och snabb på samma gång. För filgrupperna rekommenderas att välja RAID10 , eftersom den innehåller välbalanserade funktioner, men beroende på databasdata kan du välja en annan variant.
Du kan använda en mjukvaru- eller hårdvarulösning som RAID . En mjukvarulösning är billigare, men den kräver extra resurser av CPU. Och en processor har inga extra resurser. Det är därför det är bättre att använda hårdvarulösningar där ett dedikerat chip ansvarar för RAID .
Index
Alla vet att index hjälper till att öka datasökningshastigheten. De flesta av oss förstår att index negativt påverkar datainsättning och uppdatering, så ju fler index du har, desto svårare är det för servern att underhålla dem. Då tror inte många ens att index kräver underhåll. Databassidor som innehåller indexdata kan svämma över och så småningom bli obalanserade.
Ja, vi kan ignorera olika parametrar och helt enkelt återskapa index en gång i månaden, vilket liknar underhåll. SQL Server innehåller två parametrar som förhindrar att index blir inaktuella inom en halvtimme efter att de skapats:FILLFACTOR och PAD_INDEX .
Du kan använda alternativet FILLFACTOR för att optimera prestandan för infognings- och uppdateringsoperationerna som innehåller ett klustrat eller icke-klustrat index. Indexdata kan lagras på många datasidor. Som jag nämnde ovan består varje sida av 8 KB. När en indexsida är full skapar servern en ny sida och delar upp sidan för datainfogningen i två.
Servern kräver tid för siddelning och skapande av en ny sida. För att optimera siddelningen, använd FILLFACTOR alternativet för att bestämma procentandelen ledigt utrymme på alla blad på indexsidan. Ju större diskutrymme sidorna på bladnivå har, desto mindre ofta behöver du dela upp indexsidor. Då blir indexträdet för stort och det tar extra tid att förbigå det.
PAD_INDEX alternativet anger fyllnadsprocenten för de icke-bladiga sidorna. Du kan använda PAD_INDEX endast när FILLFACTOR alternativet anges eftersom procentvärdet för PAD_INDEX beror på den procentandel som anges i FILLFACTOR .
Statistik
Statistik gör att servern kan fatta rätt beslut mellan indexanvändning och genomsökning av hela tabellerna. Anta att du har en lista över anställda i en gjuteributik. En sådan lista kommer att göras över cirka 90 % av männen.
Anta nu att vi måste hitta alla kvinnor. Eftersom det inte finns många av dem är det mest effektiva alternativet att använda indexet. Men om vi behöver hitta alla män, saktar indexeffektiviteten ner. Antalet valda poster är för stort och att kringgå indexträdet för var och en av dem kommer att bli en overhead. Det är mycket enklare att skanna hela tabellen – exekveringen blir mycket snabbare eftersom servern kommer att behöva läsa alla lågnivåblad i indexet en gång utan att behöva läsa flera av alla nivåer.
SQL Server samlar in statistik genom att läsa alla fältvärden eller med en mall för att skapa den enhetligt fördelade och sorterade värdelistan. SQL Server upptäcker dynamiskt procentandelen rader som måste testas på basis av antalet rader i tabellen. Vid insamling av statistik kommer frågeoptimeraren att utföra antingen en fullständig genomsökning eller radmallar.
För att få statistik att fungera måste den skapas. Vid omfattande datauppdateringar kan statistiken innehålla felaktig data och servern kommer att fatta ett felaktigt beslut. Men allt kan ställas till rätta, – du måste övervaka statistiken. För mer detaljerad information, se böckerna om Transact-SQL eller MS SQL Server.
Sammanfattning
Standardinställningarna tillåter inte användning av all potential hos hårdvara och fungerar med alla olika servrar. Ansvaret för inställningarna ligger hos administratörer. Att Microsoft-produkterna har enkla installationsprogram, grafiska administrationsverktyg och möjlighet att arbeta offline betyder inte att detta är en optimal variant.
Vi betraktar inte sådana databasjusteringsalternativ som hårdvaruacceleration. Om alla inställningsalternativ är uttömda är det bättre att tänka på uppgraderingen, eftersom hårdvaruacceleration negativt påverkar systemets tillförlitlighet.
Det viktigaste är att optimering av databasserver eller uppgradering inte hjälper om frågorna inte är optimerade.