Detta är den tredje i vår flerdelade serie om tillämpning av informationssäkerhetsmetoder för datamodellering. Serien använder en enkel datamodell, något för att hantera sociala klubbar och intressegrupper, för att tillhandahålla det innehåll vi vill säkra. Senare kommer vi att ta upp modellering för auktorisering och användarhantering, såväl som andra delar av en säker databasimplementering.
I sociala situationer är det vanligt att "läsa mellan raderna" - härleda outtalade antaganden och påståenden i en konversation. Detsamma sker när man skapar programvara och lagrar data i en databas. Fakturor räknas upp med kund-ID:t inbäddat, och hur många dataenheter använder en datum-tid som en del av nyckeln? Det är svårt att föreställa sig att noggrant dokumentera eller strukturera allt utan någon typ av utelämnande. Men i vår sista omgång gick vi igenom exakt den övningen. Vi kunde tillskriva känslighet till flera delar av vår sociala klubbdatabas. Men för att kvantifiera och hantera den känsligheten måste vi utöka strukturen i vår datamodell för att göra den känsliga informationen och dess relationer tydliga.
Att stänga datamodellluckor
Datamodellering för säkerhet kräver flera olika varianter av strukturändringar. Vi utforskar dessa i sin tur och använder en (mycket!) enkel datamodell för sociala klubbar som vår bas för den här serien. Allt eftersom vi har gått vidare har vi förbättrat modellen med mer data. I den sista delen analyserade vi modellen för att tillskriva datakänslighet där vi hittade den. Denna analys också avslöjade att det fanns platser där datamodellen indikerade länkar som faktiskt inte fångades explicit i kolumner och nyckelrelationer. Modellören bör förvänta sig detta i en säkerhetsanalys. När vi går vidare från dessa upptäckter kommer vi att göra dessa relationer så konkreta och tydliga som möjligt genom att bygga ut tabellerna och kopplingarna mellan dem. Detta gör att vi kan bifoga säkerhetsattribut längre fram.
Bygga ut datarelationerna i klubben
Alla relationer i datan, såväl som själva dataenheterna, måste ha någon representation för att tillskriva dem värde eller känslighet. Nya kolumner, nya nycklar, nya referenser, till och med nya tabeller kan behövas för att åstadkomma detta. När vi analyserade tabellerna och deras relationer i vårt förra inlägg isolerade vi två huvudtabeller med högkänsliga data:
PersonPhoto
Dessutom hade vi fyra innehållande data som var måttligt känsliga:
MemberClubOfficeClub_Office
Dessa aspekter av känslighet är delvis inneboende för varje tabell, men icke-explicita relationer bär mycket av känsligheten. För att fästa den börjar vi spela in relationerna och ge dem en struktur som innehåller känsligheten.
Relationer inbäddade i foton
Photo innehåller många inbäddade relationer vi behöver fånga. Vi är främst intresserade av relationen med Person . För att fånga relationen person-foto lägger jag till Photo_Content tabell:
Det finns många olika aspekter för en Person kan relatera till ett Photo . Jag bestämde mig för att lägga till en ny tabell, Photo_Content_Role , för att karakterisera förhållandet mellan ett foto och en person. Istället för att ha separata tabeller för varje sorts relation, använder vi en enda anslutningstabell och tabellen Photo_Content_Role. Den här tabellen är en referenslista med standardrelationer som det vi redan har noterat. Här är vår första uppsättning data för Photo_Content_Role :
| Etikett | Max per person | Beskrivning |
|---|---|---|
| Fotograf | 1 | Personen som faktiskt tog fotot |
| Avbildad person | 1 | En person som känns igen på bilden |
| Upphovsrättsägare | 1 | En person som innehar upphovsrätten till fotot |
| Licensgivare | 1 | En part som har licensierat klubbens användning av detta foto |
| Upphovsrättsmäklare | 1 | En part som löste upphovsrättsproblem för detta foto |
| Objekt avbildat | obegränsat | content_headline identifierar objektet, content_detailed utarbetar det |
| Kommentar | obegränsat |
OK, så det här är en bete-och-switch. Jag sa Photo_Content skulle relatera människor till foton, så varför står det något om "objekt avbildat"? Logiskt sett kommer det att finnas bilder där vi skulle beskriva innehållet utan att identifiera en Person . Ska jag lägga till en annan tabell för detta, med en separat uppsättning innehållsroller? Jag bestämde mig för att inte. Istället kommer jag att lägga till en noll personrad till Person tabell som frödata och har icke-personinnehåll hänvisar till den personen. (Ja, programmerare, det är lite mer jobb. Ni är välkomna.) "Null Person" kommer att ha id noll (0).
Nyckelinlärning nr 1:
Minimera tabeller med känslig data genom att lägga över liknande relationsstrukturer i en enda tabell.
Jag räknar med att det kan finnas ytterligare samband som kommer att upptäckas nedströms. Och det är också möjligt att en social klubb kan ha sina egna roller att tillskriva en Person i ett Foto . Av den anledningen har jag använt en "ren" surrogatprimärnyckel för Photo_Content_Role , och lade även till en valfri främmande nyckel till Club . Detta kommer att tillåta oss att stödja särskilda användningar av enskilda klubbar. Jag kallar fältet "exklusivt" för att indikera att det inte borde vara tillgängligt för andra klubbar.
Nyckelinlärning nr. 2:
När slutanvändare kan utöka en inbyggd lista, ge dess tabell en ren surrogatnyckel för att undvika datakollisioner.
Photo_Content_Role.max_per_person kan också vara mystiskt. Du kan inte se det i diagrammet, men Photo_Content_Role.id har sin egen unika begränsning utan max_per_person . I huvudsak är den verkliga primärnyckeln bara id . Genom att lägga till max_per_person till id i primärnyckeln tvingar jag varje refererande tabell att ta upp information genom vilken den kan (borde!) genomdriva en begränsning av kardinalitetskontroll. Här är kontrollbegränsningen i Photo_Content .
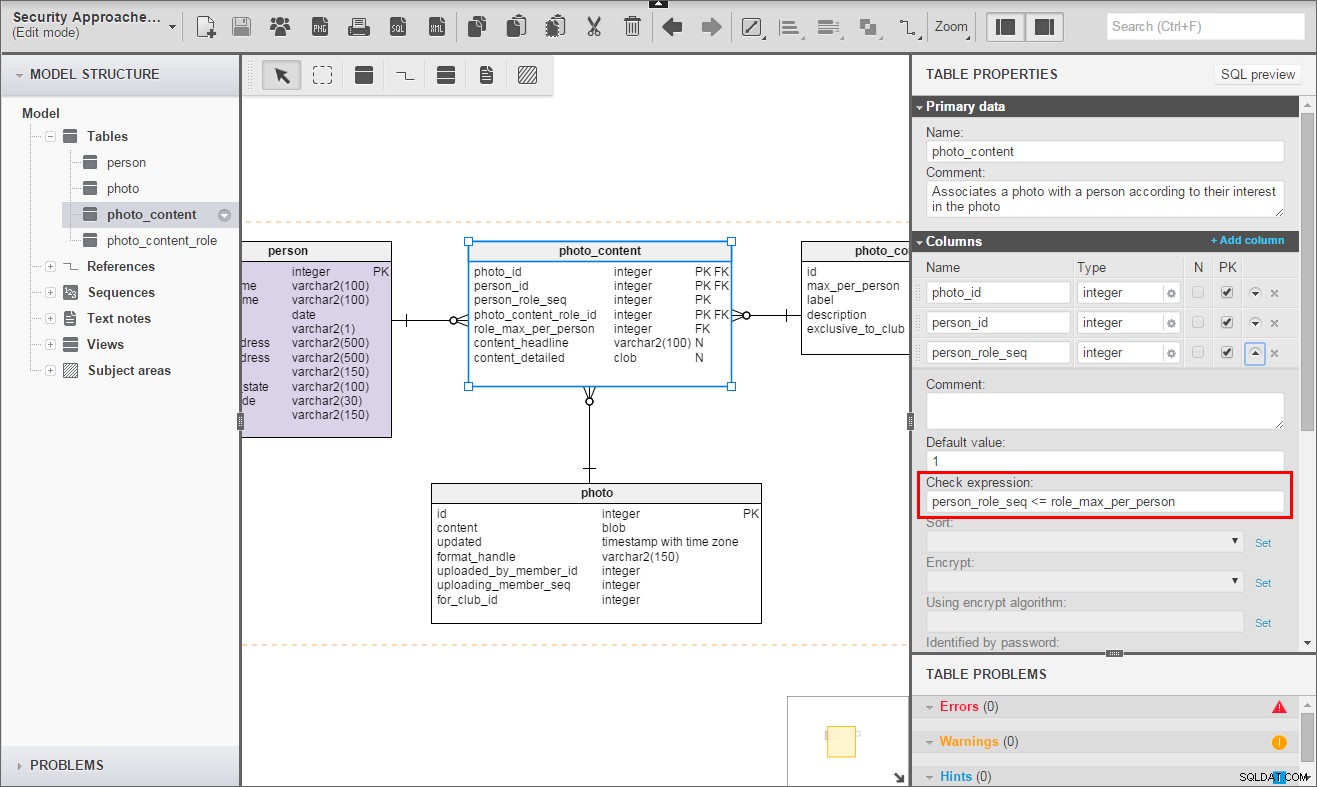
Nyckelinlärning nr. 3:
När varje rad i en tabell har individuella begränsningar måste refererande tabeller lägga till en ny unik begränsning, som utökar en naturlig nyckel med begränsningsfälten. Låt den underordnade tabellen hänvisa till den nyckeln.
Låt oss titta lite mer på Photo_Content . Detta är främst ett förhållande mellan Photo och Person , med den relation som anges av den bifogade innehållsrollen. Som jag noterade tidigare är det dock här vi lagrar allt beskrivande information om fotot. För att tillgodose denna typ av öppenhet har vi den valfria content_headline och content_detailed kolumner. Dessa kommer sällan att behövas för en vanlig association mellan en person och ett foto. Men en rubrik som "Bob Januskis får det årliga prestationspriset" är lätt att förutse. Också om det inte finns någon person — 'objekt avbildat', Person 0 — vi måste kräva något i content_headline , till exempel 'Northwest Slope of Mt. Ararat.'
The Last Missing Photo Relationship:Album
Hittills har vi inte lagt till något som relaterar Photo s till Photo s. Det är en stor sak för sociala nätverk och fototjänster:Album s. Och du skulle inte vilja ha dem i den ökända skokartongen, eller hur? Så låt oss fylla i denna uppenbara lucka – men låt oss också tänka på det.
Album bifogar Photo är på ett annat sätt än de andra relationerna vi har täckt. Photo s kan vara associerade med samma klubb, ett liknande datum, närliggande GPS-koordinater, samma fotograf och så vidare. Men Album anger tydligt att den bifogade Photo s är en del av ett enda ämne eller en berättelse. Som sådan är de säkerhetsrelevanta aspekterna av ett Photo kan härledas från en annan i Album . Ordningen kan också förstärka eller minska dessa slutsatser. Så tänk inte bara på Album som en ofarlig samling. Relaterande Photo s är allt annat än.
Även om det inte är ofarligt ur säkerhetssynpunkt, Album är en enkel enhet med ett rent Id surrogatnyckel som ägs av en Club (inte en Person ). Album_Photo ger oss en uppsättning Photo s sekvenseras av Photo_Order . Du kommer att märka att jag har skapat Album id och order den primära nyckeln. Relationen är egentligen mellan Photo och Album , så varför inte göra dessa till den primära nyckeln? Eftersom udda fall kräver ett Photo för att upprepa i ett Album är säkert möjliga. Så jag lade Photo_Order in i primärnyckeln, och efter lite funderande bestämde jag sig för att lägga till en alternativ unik nyckel med album och foto för att förhindra ett Photo från att upprepas i ett Album . Om tillräckligt många gråter för att upprepa ett Photo i ett Album uppstår är en unik nyckel lättare att ta bort än en primärnyckel.
Nyckelinlärning nr 4:
För primärnyckeln, välj en kandidatnyckel med minsta risk att kasseras senare.
Fotometadata
Den sista potentiellt känsliga informationen att lägga till är metadata (vanligtvis skapad av vilken enhet som än har tagit bilderna). Denna data är inte del av ett förhållande, men det är inneboende i fotot. Den primära definitionen av information som en kamera lagrar med ett foto är EXIF, en industristandard från Japan (JEITA). EXIF är utbyggbart och kan stödja dussintals eller hundratals fält, varav inget kan krävas från våra uppladdade bilder. Denna icke-obligatoriska status beror på att dessa fält inte är gemensamma för alla fotoformat och kan raderas före uppladdning. Jag har byggt ut Photo med många vanliga fält, inklusive:
- camera_mfr
- kamera_modell
- camera_software_version
- image_x_resolution
- image_y_resolution
- image_resolution_unit
- image_exposure_time
- camera_aperture_f
- GPSLatitude
- GPSLongitud
- GPSAltitude
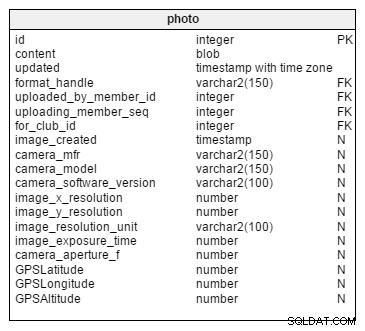
GPS-fälten är, naturligt nog, de som ger den högsta känsligheten till ett Photo .
Vår modell, med alla känsliga och värdefulla data definierade
Vi slutför den här fasen av att säkra klubbdatabasen med dessa ändringar. Alla anslutningar och ytterligare data som behövs finns, som visas nedan. Jag har gjort Photo information röd och Album ljus turkos för att förmedla min idé om logiska grupperingar. Förstärkningen av dataelement är verklig, men mycket minimerad.
Slutsats
Att sätta vilken datamodell som helst på en bra säkerhetsfot kräver en ordnad och systematisk tillämpning av säkerhetsprinciper såväl som relationsdatabaspraxis. I den här delen har vi granskat datamodellen och noggrant fyllt i saknad struktur som antyddes, men inte uttryckts i schemat. Vi kunde inte tilldela värde eller tillhandahålla skydd för den befintliga informationen utan att lägga till de uppgifter som fyller i och binder ihop dem korrekt. Med detta på plats kommer vi att fortsätta att bifoga delarna av datavärdering och datakänslighet som gör att vi tydligt kan se all data från ett fullständigt säkerhetsperspektiv. Men det är i vår nästa artikel.