Introduktion
Det är allmänt känt i databaskretsar att index förbättrar frågeprestanda antingen genom att tillfredsställa den erforderliga resultatuppsättningen helt och hållet (Covering Indexes) eller fungera som uppslag som enkelt dirigerar frågemotorn till den exakta platsen för den nödvändiga datamängden. Men som erfarna DBA:er vet bör man inte vara för entusiastisk över att skapa index i OLTP-miljöer utan att förstå arbetsbelastningens natur. Genom att använda Query Store i SQL Server 2019-instans (Query Store introducerades i SQL Server 2016) är det ganska enkelt att visa effekten av ett index på inlägg.
Infoga utan index
Vi börjar med att återställa WideWorldImporters Sample-databasen och sedan skapa en kopia av försäljningen. Fakturatabell med skriptet i Lista 1. Observera att Query Store redan är aktiverat i exempeldatabasen i läs-skrivläge.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Lägg märke till att det inte finns några index alls i tabellen vi just har skapat. Allt vi har är tabellstrukturen. När det är klart utför vi infogning i den nya tabellen med hjälp av data från dess överordnade som visas i lista 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Under denna operation fångar Query Store exekveringsplanen för frågan. Figur 1 visar kort vad som händer under huven. När vi läser från vänster till höger ser vi att SQL Server exekverar infogningen med Plan ID 563 – en indexsökning på källtabellens primärnyckel för att hämta data och sedan en tabellinfogning på måltabellen. (Läser från vänster till höger). Observera att i det här fallet ligger huvuddelen av kostnaden på tabellinlägget – 99 % av frågekostnaden.
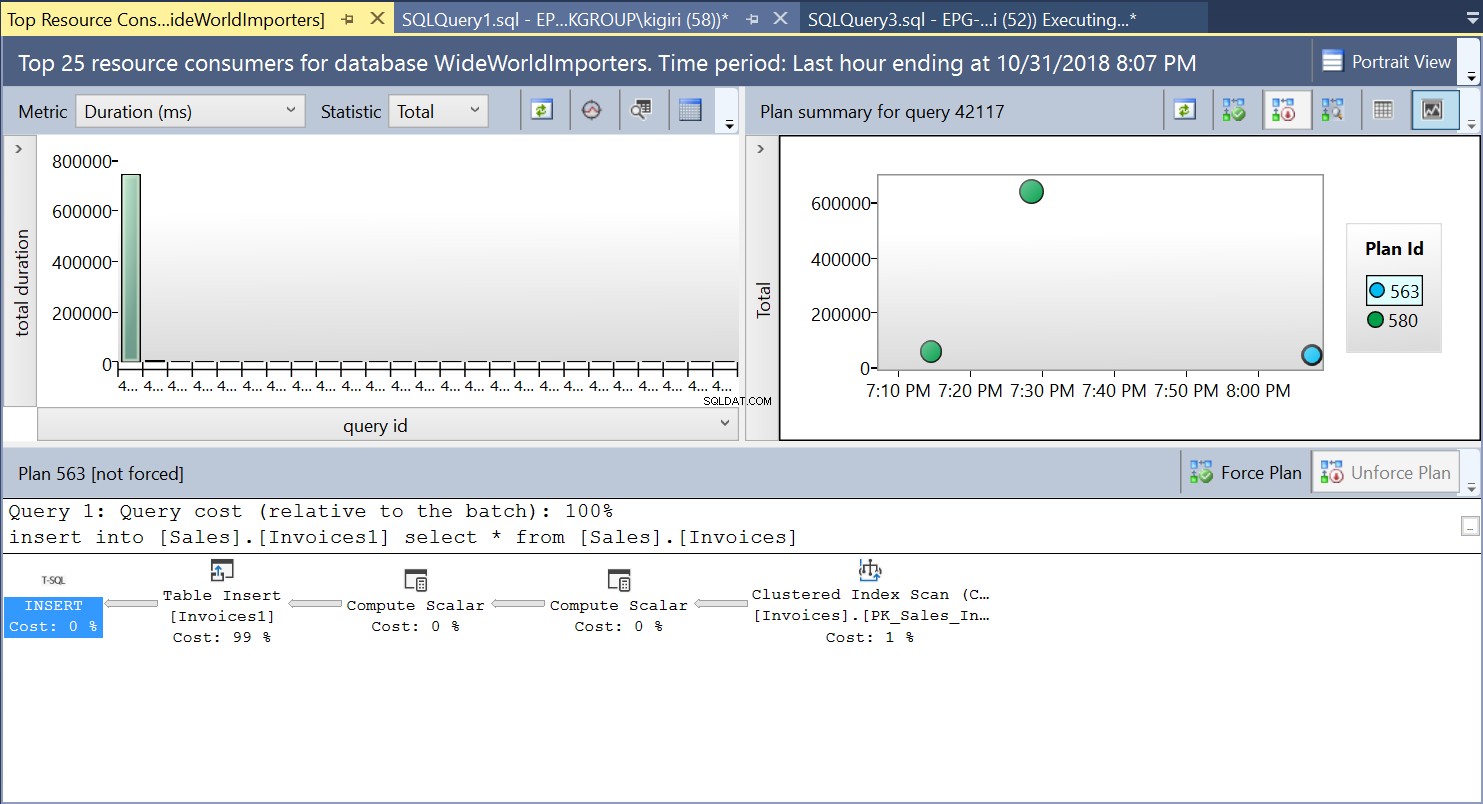
Fig. 1 Utförandeplan 563
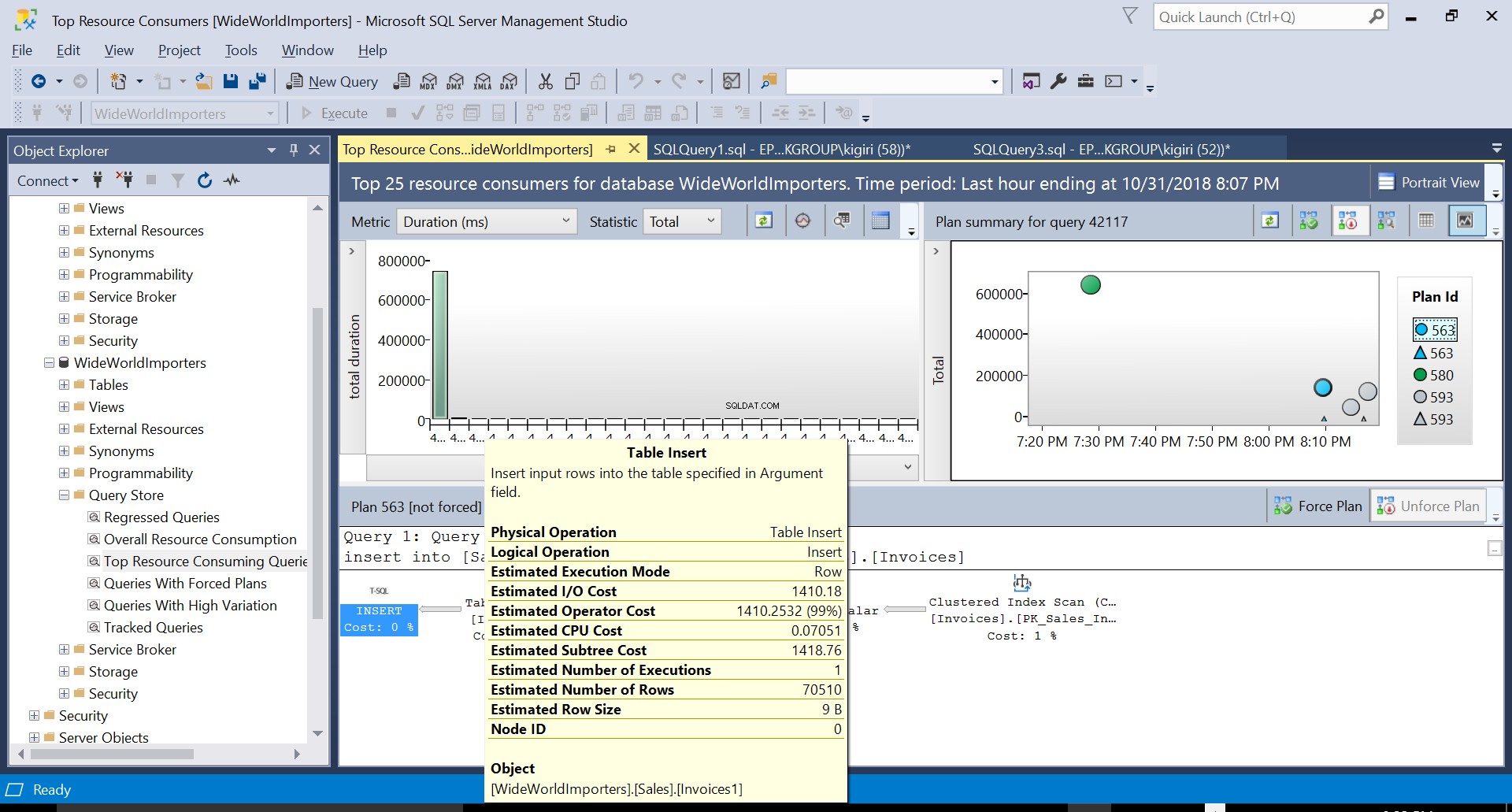
Fig. 2 Tabell Infoga på destination
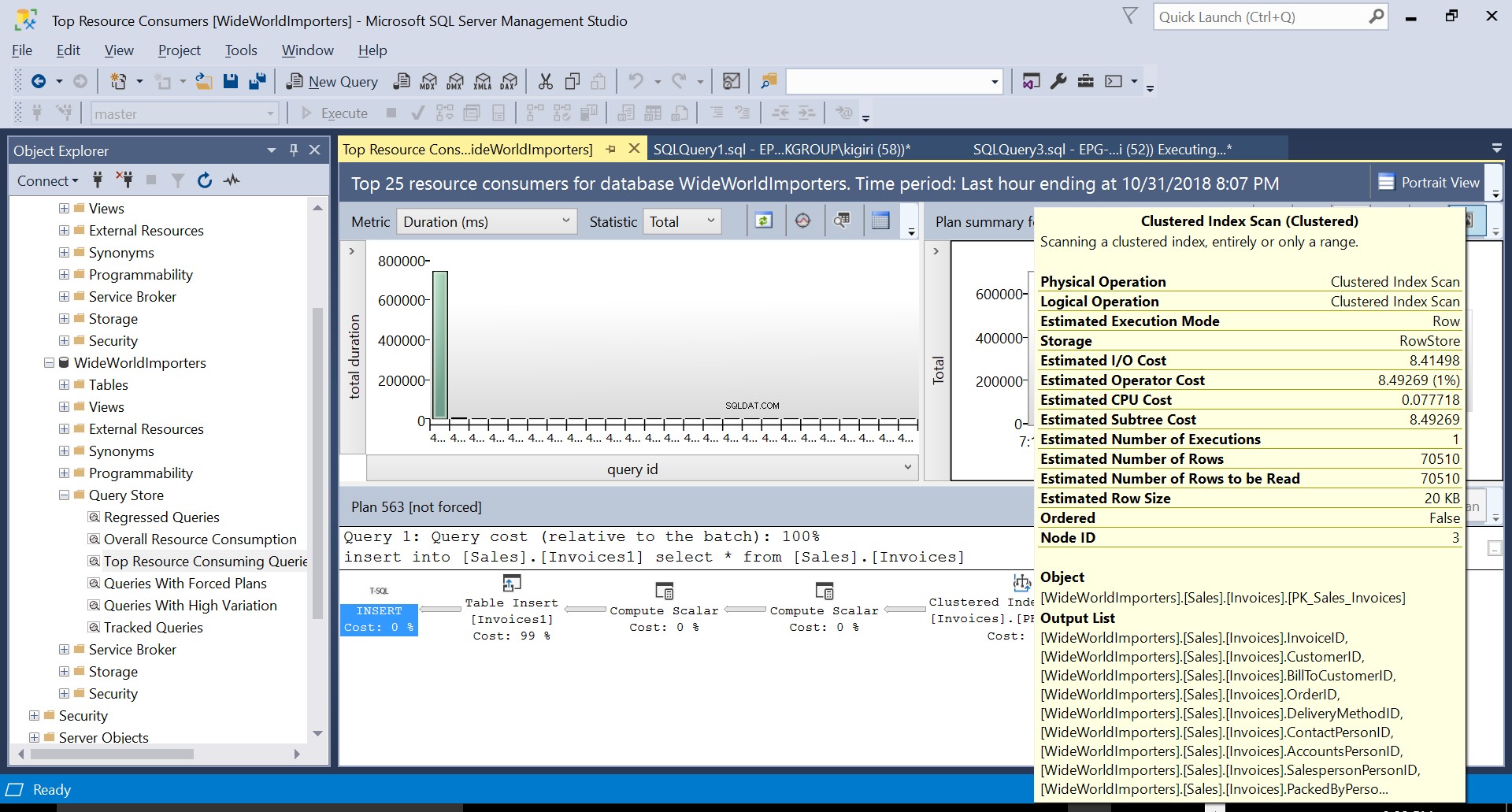
Fig. 3 Clustered Index Scan på källtabell
Infoga med index
Vi skapar sedan ett index på destinationstabellen med hjälp av DDL i Listing 3. När vi upprepar satsen i Listing 2 efter att ha trunkerat destinationstabellen ser vi en något annorlunda exekveringsplan (Plan ID 593 visas i Fig 4). Vi ser fortfarande tabellinlägget men det bidrar bara med 58 % till kostnaden för frågan. Exekveringsdynamiken är lite skev med införandet av en sort och en Index Insert. Vad som i huvudsak händer är att SQL Server måste införa motsvarande rader i indexet när nya poster introduceras i tabellen.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
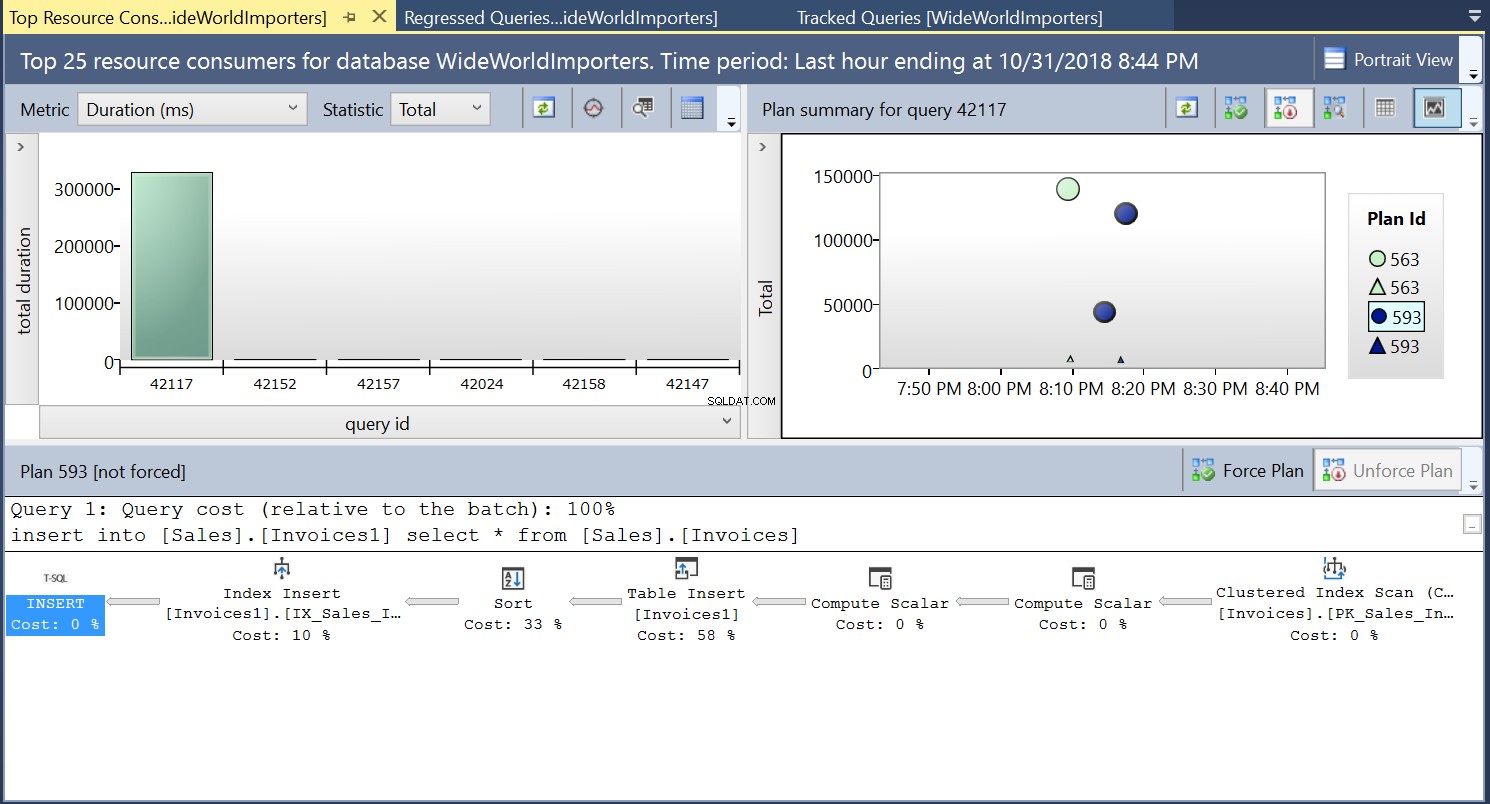
Fig. 4 Utförandeplan 593
Ser djupare
Vi kan undersöka detaljerna i båda planerna och se hur dessa nya faktorer eskalerar genomförandetiden för uttalandet. Plan 593 lägger till ytterligare 300 ms eller så till den genomsnittliga varaktigheten för uttalandet. Under stor arbetsbelastning i en produktionsmiljö kan denna skillnad vara betydande.
Att slå på STATISTICS IO vid exekvering av insert-satsen bara en gång i båda fallen – med Index på destinationstabellen och utan index på Destination-tabellen – visar också att mer arbete görs i termer av logisk IO när man infogar rader i en tabell med index.
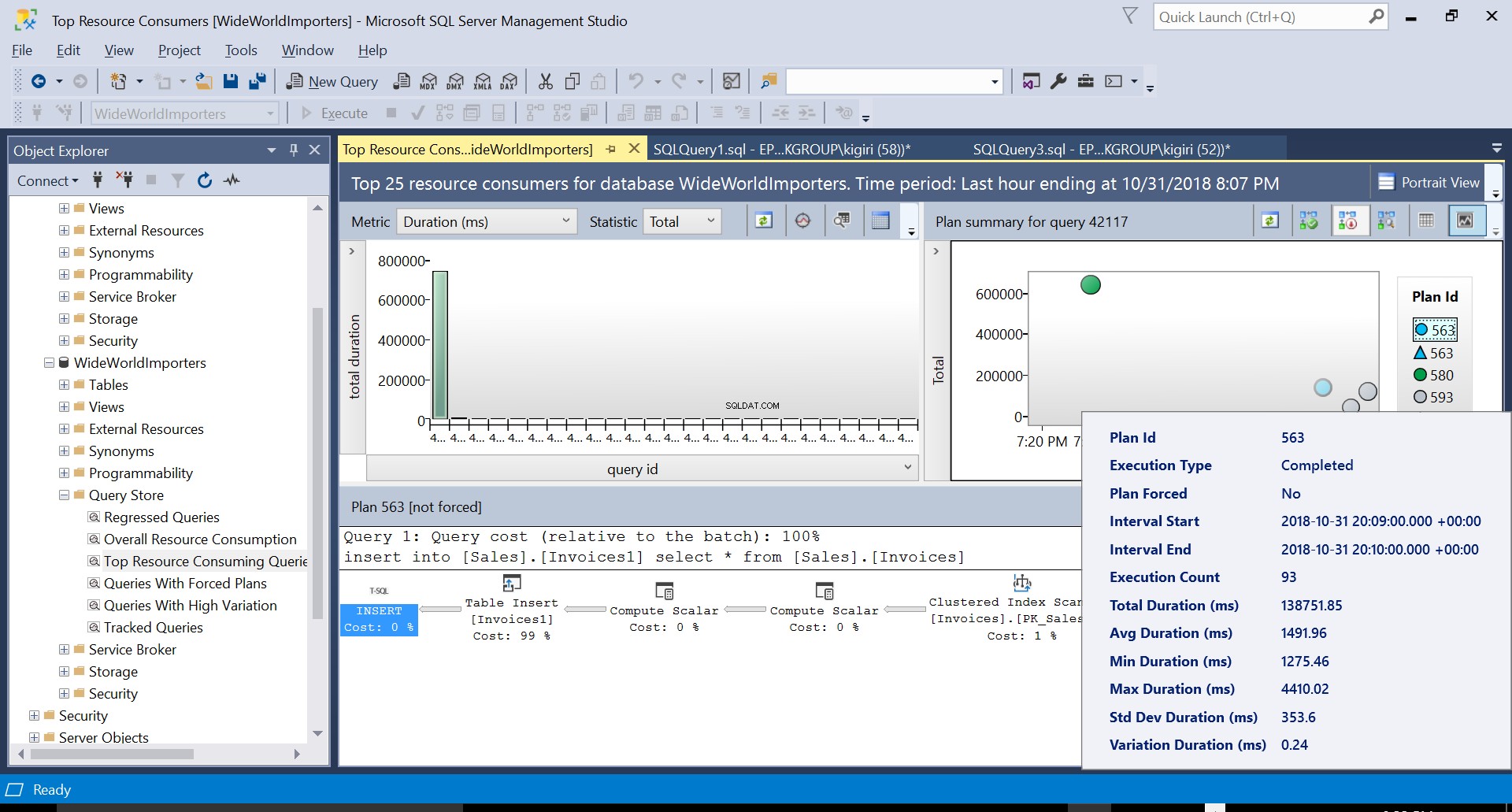
Fig. 5 Detaljer för utförandeplan 563
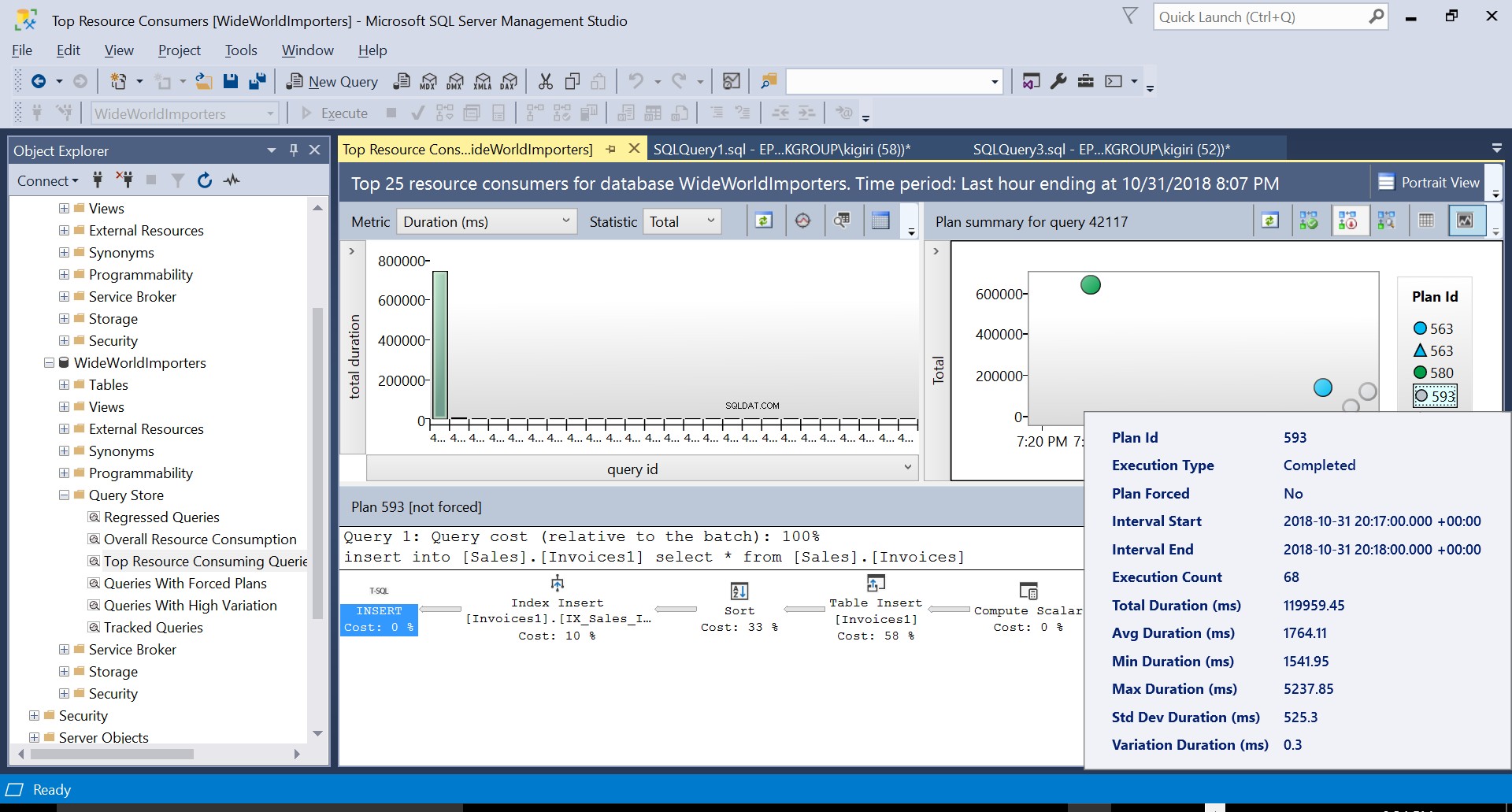
Fig. 4 Detaljer för genomförandeplan 593
Inget index:Utdata med STATISTICS IO påslagen:
Tabell 'Fakturor1'. Scan count 0, logiskt läser 78372 , fysisk läser 0, läs framåt läser 0, lob logisk läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell "Fakturor". Scan count 1, logiskt läser 11400, fysisk läser 0, läs framåt läser 0, lob logisk läser 0, lob fysisk läser 0, lob läser framåt läser 0.
(70510 rader påverkade)
Index:Utdata med STATISTICS IO påslagen:
Tabell 'Fakturor1'. Scan count 0, logiskt läser 81119 , fysisk läser 0, läs framåt läser 0, lob logisk läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'Arbetsbord'. Skanningsantal 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell "Fakturor". Scan count 1, logiskt läser 11400 , fysisk läser 0, läs framåt läser 0, lob logisk läser 0, lob fysisk läser 0, lob läser framåt läser 0.
(70510 rader påverkade)
Ytterligare information
Microsoft och andra källor tillhandahåller skript för att undersöka produktionsmiljön för index och identifiera sådana situationer som:
- Redundanta index – Index som är duplicerade
- Saknade index – Index som kan förbättra prestanda baserat på arbetsbelastning
- Högar – Tabeller utan klustrade index
- Överindexerade tabeller – Tabeller med fler index än kolumner
- Indexanvändning – Antal sökningar, skanningar och uppslagningar på index
Punkterna 2, 3 och 5 är mer relaterade till prestandapåverkan med avseende på läsningar, medan punkterna 1 och 4 är relaterade till prestandapåverkan med avseende på skrivningar. Listorna 4 och 5 är två exempel på dessa allmänt tillgängliga frågor.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Slutsats
Vi har visat, med hjälp av Query Store, att ytterligare arbetsbelastning med ett index kan införa i exekveringsplanen för en exempelinsättningssats. I produktionen kan överdrivna och redundanta index ha en negativ inverkan på prestanda, särskilt i databaser avsedda för OLTP-arbetsbelastningar. Det är viktigt att använda tillgängliga skript och verktyg för att undersöka index och avgöra om de faktiskt hjälper eller skadar prestandan.
Användbart verktyg:
dbForge Index Manager – praktiskt SSMS-tillägg för att analysera status för SQL-index och åtgärda problem med indexfragmentering.