Tänk på följande AdventureWorks-fråga som returnerar transaktions-ID:n för historiktabeller för produkt-ID 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Frågeoptimeraren hittar snabbt en effektiv exekveringsplan med en uppskattning av kardinalitet (radantal) som är exakt korrekt, som visas i SQL Sentry Plan Explorer:

Säg nu att vi vill hitta historiktransaktions-ID:n för AdventureWorks-produkten med namnet "Metal Plate 2". Det finns många sätt att uttrycka denna fråga i T-SQL. En naturlig formulering är:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Utförandeplanen är följande:
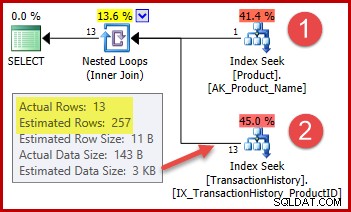
Strategin är:
- Slå upp produkt-ID:t i produkttabellen från det angivna namnet
- Hitta rader för det produkt-ID:t i historiktabellen
Det uppskattade antalet rader för steg 1 är helt rätt eftersom indexet som används är deklarerat som unikt och endast inmatat på produktnamnet. Likhetstestet på "Metal Plate 2" ger därför garanterat exakt en rad (eller noll rader om vi anger ett produktnamn som inte finns).
Den markerade uppskattningen med 257 rader för steg två är mindre exakt:endast 13 rader påträffas faktiskt. Denna diskrepans uppstår eftersom optimeraren inte vet vilket särskilt produkt-ID som är associerat med produkten som heter "Metal Plate 2". Den behandlar värdet som okänt och genererar en kardinalitetsuppskattning med hjälp av information om genomsnittlig densitet. Beräkningen använder element från statistikobjektet som visas nedan:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
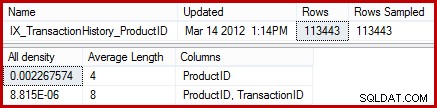
Statistiken visar att tabellen innehåller 113443 rader med 441 unika produkt-ID:n (1 / 0,002267574 =441). Om man antar att fördelningen av rader över produkt-ID:n är enhetlig, förväntar kardinalitetsuppskattningen att ett produkt-ID matchar (113443 / 441) =257,24 rader i genomsnitt. Som det visar sig är fördelningen inte särskilt enhetlig; det finns bara 13 rader för produkten "Metal Plate 2".
En sida
Du kanske tänker att uppskattningen med 257 rader borde vara mer exakt. Till exempel, med tanke på att produkt-ID:n och namn båda är begränsade till att vara unika, kan SQL Server automatiskt upprätthålla information om denna en-till-en-relation. Den skulle då veta att "Metal Plate 2" är associerad med produkt-ID 479, och använda den insikten för att generera en mer exakt uppskattning med hjälp av ProductID-histogrammet:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
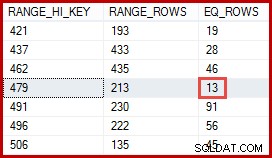
En uppskattning av 13 rader härledda på detta sätt skulle ha varit exakt korrekt. Ändå var uppskattningen av 257 rader inte orimlig, med tanke på tillgänglig statistisk information och de normala förenklade antaganden (som enhetlig fördelning) som tillämpas av kardinalitetsuppskattning idag. Exakta uppskattningar är alltid trevliga, men "rimliga" uppskattningar är också helt acceptabla.
Kombinera de två frågorna
Säg att vi nu vill se alla transaktionshistorik-ID:n där produkt-ID:t är 421 ELLER namnet på produkten är "Metal Plate 2". Ett naturligt sätt att kombinera de två föregående frågorna är:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Utförandeplanen är lite mer komplex nu, men den innehåller fortfarande igenkännbara delar av planerna med enstaka predikat:
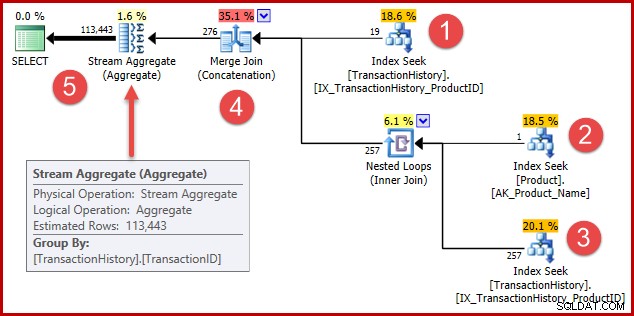
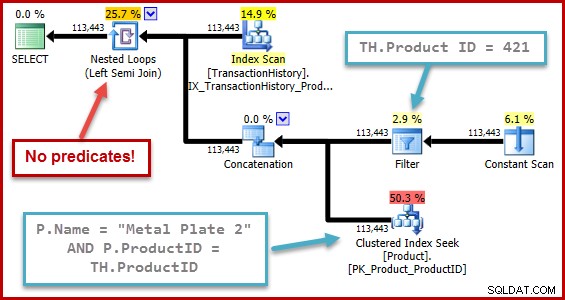
Strategin är:
- Hitta historikposter för produkt 421
- Slå upp produkt-id:t för produkten med namnet "Metal Plate 2"
- Hitta historikposter för produkt-id:t som hittades i steg 2
- Kombinera rader från steg 1 och 3
- Ta bort alla dubbletter (eftersom produkt 421 också kan vara den som heter "Metal Plate 2")
Steg 1 till 3 är exakt desamma som tidigare. Samma uppskattningar görs av samma skäl. Steg 4 är nytt, men väldigt enkelt:det sammanfogar förväntade 19 rader med förväntade 257 rader, för att ge en uppskattning av 276 rader.
Steg 5 är det intressanta. Streamaggregatet som tar bort dubbletter har en uppskattad ingång på 276 rader och en uppskattad utgång på 113443 rader. Ett aggregat som matar ut fler rader än det tar emot verkar omöjligt, eller hur?
* Du kommer att se en uppskattning av 102099 rader här om du använder kardinalitetsuppskattningsmodellen före 2014.
Kardinalitetsuppskattningsfelet
Den omöjliga Stream Aggregate-uppskattningen i vårt exempel orsakas av en bugg i kardinalitetsuppskattningen. Det är ett intressant exempel så vi kommer att utforska det lite i detalj.
Ta bort underfråga
Det kan förvåna dig att lära dig att SQL Server-frågeoptimeraren inte fungerar direkt med underfrågor. De tas bort från det logiska frågeträdet tidigt i kompileringsprocessen och ersätts med en motsvarande konstruktion som optimeraren är inställd för att arbeta med och resonera kring. Optimizern har ett antal regler som tar bort delfrågor. Dessa kan listas efter namn med hjälp av följande fråga (den refererade DMV är minimalt dokumenterad, men stöds inte):
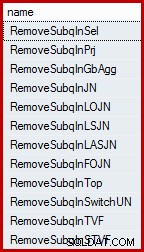
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Resultat (på SQL Server 2014):
Den kombinerade testfrågan har två predikat ("selektioner" i relationella termer) i historiktabellen, kopplade med OR . Ett av dessa predikat inkluderar en underfråga. Hela underträdet (både predikaten och underfrågan) transformeras av den första regeln i listan ("ta bort underfråga i urval") till en semi-join över föreningen av de individuella predikaten. Även om det inte är möjligt att representera resultatet av denna interna transformation exakt med T-SQL-syntax, är det ganska nära att vara:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Det är lite olyckligt att min T-SQL-approximation av det interna trädet efter borttagning av subquery innehåller en subquery, men i frågeprocessorns språk gör det det inte (det är en semi-join). Om du föredrar att se den obearbetade interna formen istället för mitt försök till en T-SQL-motsvarighet, kan du vara säker på att det kommer att vara med ett ögonblick.
Det odokumenterade frågetipset som ingår i T-SQL ovan är till för att förhindra en efterföljande transformation för de av er som vill se den transformerade logiken i exekveringsplanform. Anteckningarna nedan visar positionerna för de två predikaten efter transformation:
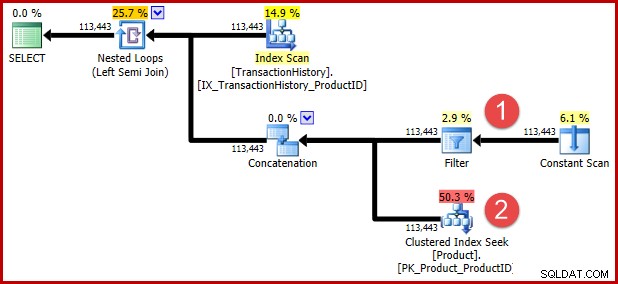
Intuitionen bakom transformationen är att en historierad kvalificerar sig om något av predikaten är uppfyllt. Oavsett hur hjälpsam du tycker att min ungefärliga T-SQL- och exekveringsplanillustration, hoppas jag att det är åtminstone någorlunda tydligt att omskrivningen uttrycker samma krav som den ursprungliga frågan.
Jag bör betona att optimeraren inte bokstavligen genererar alternativ T-SQL-syntax eller producerar kompletta exekveringsplaner i mellanstadier. T-SQL-representationerna och exekveringsplanen ovan är endast avsedda att hjälpa dig att förstå. Om du är intresserad av de råa detaljerna är den utlovade interna representationen av det transformerade frågeträdet (något redigerat för tydlighetens skull):
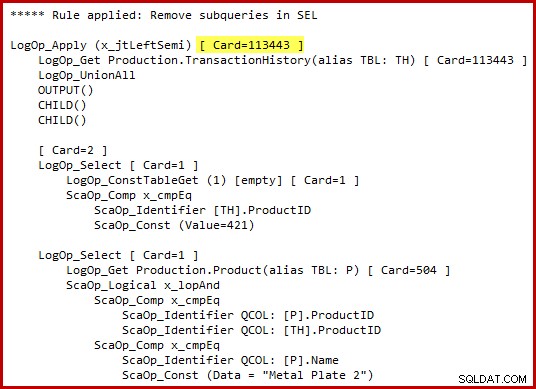
Lägg märke till den markerade uppskattningen av applicera semi join-kardinalitet. Det är 113443 rader när man använder 2014 års kardinalitetsuppskattare (102099 rader om man använder den gamla CE). Tänk på att AdventureWorks-historiktabellen innehåller totalt 113443 rader, så detta representerar 100 % selektivitet (90 % för det gamla CE).
Vi såg tidigare att enbart tillämpning av någon av dessa predikat endast resulterar i ett litet antal matchningar:19 rader för produkt-ID 421 och 13 rader (uppskattningsvis 257) för "Metal Plate 2". Uppskattar att disjunktionen (OR) av de två predikaten kommer att returnera alla rader i bastabellen verkar helt galna.
Bugdetaljer
Detaljerna för selektivitetsberäkningen för semi-join är endast synliga i SQL Server 2014 när man använder den nya kardinalitetsuppskattaren med (odokumenterad) spårflagga 2363. Det är förmodligen möjligt att se något liknande med Extended Events, men spårningsflaggans utdata är bekvämare att använda här. Den relevanta delen av utgången visas nedan:
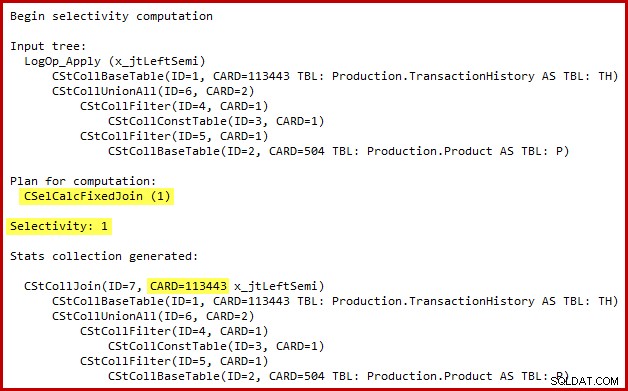
Kardinalitetsuppskattaren använder Fixed Join-kalkylatorn med 100 % selektivitet. Som en konsekvens är den uppskattade utdatakardinaliteten för semi-join den samma som dess indata, vilket innebär att alla 113443 rader från historiktabellen förväntas kvalificera sig.
Den exakta karaktären av felet är att semi-anslutningsselektivitetsberäkningen missar alla predikat som är placerade bortom en union, allt i inmatningsträdet. I illustrationen nedan antas avsaknaden av predikat på själva semi-joinningen innebära att varje rad kommer att kvalificera sig; den ignorerar effekten av predikat under sammanlänkningen (union all).
Detta beteende är desto mer överraskande när man betänker att selektivitetsberäkningen fungerar på en trädrepresentation som optimeraren genererade själv (formen på trädet och placeringen av predikaten är resultatet av att den tar bort underfrågan).
Ett liknande problem uppstår med kardinalitetskalkylatorn före 2014, men den slutliga uppskattningen är istället fixerad till 90 % av den uppskattade semi-anslutningsinmatningen (av underhållande skäl relaterade till en omvänd fast predikatuppskattning på 10 % som är för mycket av en avledning för att få in).
Exempel
Som nämnts ovan manifesteras denna bugg när uppskattning utförs för en semi-join med relaterade predikat placerade bortom en union allt. Huruvida detta interna arrangemang inträffar under frågeoptimering beror på den ursprungliga T-SQL-syntaxen och den exakta sekvensen av interna optimeringsoperationer. Följande exempel visar några fall där buggen inträffar och inte inträffar:
Exempel 1
Det här första exemplet innehåller en trivial ändring av testfrågan:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Den beräknade genomförandeplanen är:
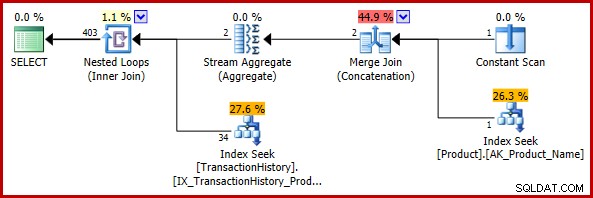
Den slutliga uppskattningen på 403 rader är oförenlig med de kapslade loops-joinernas ingångsuppskattningar, men det är fortfarande en rimlig sådan (i den mening som diskuterades tidigare). Om felet hade påträffats skulle den slutliga uppskattningen vara 113443 rader (eller 102099 rader när man använder CE-modellen före 2014).
Exempel 2
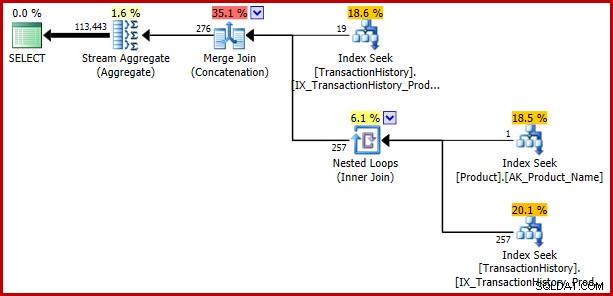
Om du var på väg att rusa ut och skriva om alla dina ständiga jämförelser som triviala delfrågor för att undvika denna bugg, se vad som händer om vi gör ytterligare en trivial förändring, den här gången ersätter likhetstestet i det andra predikatet med IN. Innebörden av frågan förblir oförändrad:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Felet returnerar:
Exempel 3
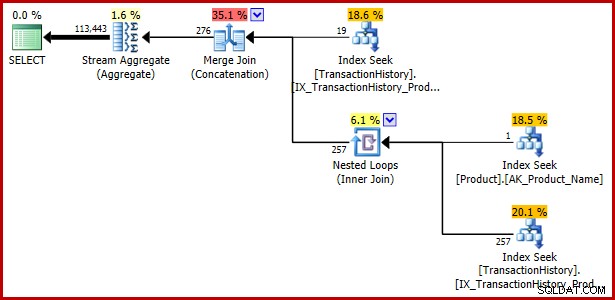
Även om den här artikeln hittills har koncentrerat sig på ett disjunktivt predikat som innehåller en underfråga, visar följande exempel att samma frågespecifikation som uttrycks med EXISTS och UNION ALL också är sårbar:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Utförandeplan:
Exempel 4
Här är ytterligare två sätt att uttrycka samma logiska fråga i T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Ingen av frågorna stöter på felet, och båda producerar samma exekveringsplan:
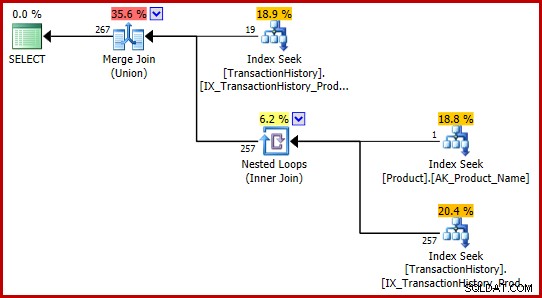
Dessa T-SQL-formuleringar råkar producera en utförandeplan med helt konsekventa (och rimliga) uppskattningar.
Exempel 5
Du kanske undrar om den felaktiga uppskattningen är viktig. I de fall som presenterats hittills är det inte det, åtminstone inte direkt. Problem uppstår när buggen uppstår i en större fråga, och den felaktiga uppskattningen påverkar optimerarbeslut på andra ställen. Som ett minimalt utökat exempel, överväg att returnera resultaten av vår testfråga i slumpmässig ordning:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Utförandeplanen visar att den felaktiga uppskattningen påverkar senare verksamhet. Det är till exempel grunden för minnesanslaget reserverat för sorten:
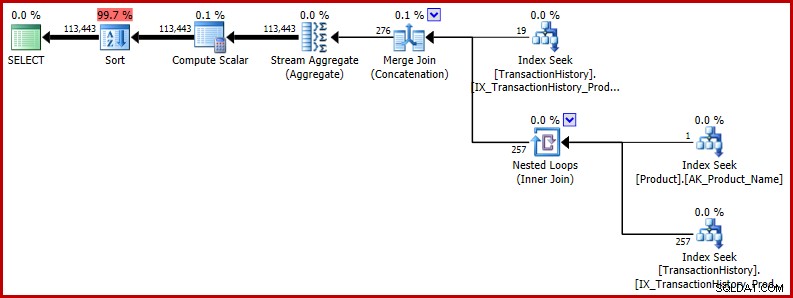
Om du vill se ett mer verkligt exempel på den här buggens potentiella inverkan, ta en titt på den här frågan från Richard Mansell nyligen på webbplatsen SQLPerformance.com Q &A, answers.SQLPerformance.com.
Sammanfattning och sista tankar
Denna bugg utlöses när optimeraren utför kardinalitetsuppskattning för en semi-join, under specifika omständigheter. Det är en utmanande bugg att upptäcka och komma runt av flera anledningar:
- Det finns ingen explicit T-SQL-syntax för att ange en semi-join, så det är svårt att i förväg veta om en viss fråga kommer att vara sårbar för detta fel.
- Optimeraren kan introducera en semi-anslutning i en mängd olika omständigheter, som inte alla är uppenbara semi-anslutningskandidater.
- Den problematiska semi-anslutningen omvandlas ofta till något annat av senare optimeraraktivitet, så vi kan inte ens lita på att det finns en semi-join-operation i den slutliga exekveringsplanen.
- Inte alla konstiga kardinalitetsuppskattningar orsakas av denna bugg. Faktum är att många exempel av denna typ är en förväntad och ofarlig bieffekt av normal optimerardrift.
- Selektivitetsuppskattningen av felaktiga semi-anslutningar kommer alltid att vara 90 % eller 100 % av dess input, men detta kommer vanligtvis inte att motsvara kardinaliteten för en tabell som används i planen. Dessutom kanske den semi-anslutna ingångskardinalitet som används i beräkningen inte ens syns i den slutliga utförandeplanen.
- Det finns vanligtvis många sätt att uttrycka samma logiska fråga i T-SQL. Vissa av dessa kommer att utlösa buggen, medan andra inte gör det.
Dessa överväganden gör det svårt att ge praktiska råd för att upptäcka eller komma runt denna bugg. Det är verkligen värt besväret att kontrollera exekveringsplaner för "upprörande" uppskattningar, och undersöka frågor med prestanda som är mycket sämre än förväntat, men båda dessa kan ha orsaker som inte relaterar till denna bugg. Som sagt, det är särskilt värt att kontrollera frågor som innehåller en disjunktion av predikat och en underfråga. Som exemplen i den här artikeln visar är detta inte det enda sättet att stöta på felet, men jag förväntar mig att det är vanligt.
Om du har turen att köra SQL Server 2014, med den nya kardinalitetskalkylatorn aktiverad, kanske du kan bekräfta felet genom att manuellt kontrollera spårningsflagga 2363-utdata för en fast 100 % selektivitetsuppskattning på en semi-join, men detta är knappast bekvämt. Du kommer naturligtvis inte att vilja använda odokumenterade spårningsflaggor på ett produktionssystem.
User Voice-felrapporten för detta problem finns här. Rösta och kommentera om du vill se det här problemet undersökt (och eventuellt åtgärdat).